So sánh JOINS trong MongoDB và PostgreSQL
Bài đăng này đã không được cập nhật trong 6 năm
JOINS trong MongoDB rất dễ bị vỡ (khi mọi thứ thay đổi, các chương trình ứng dụng phải được mã hóa lại) và thường thì MongoDB có hiệu suất kém hơn nhiều so với Postgres. Bài viết sẽ chia thành từng phần giúp chúng ta có cái nhìn tổng quan nhất về MongoDB và PostgreSQL hỗ trợ JOINS như thế nào và giải thích tại sao JOINS trong MongoDB lại sẽ bị vỡ, cuối cùng là xem xét hiệu suất của JOINS trong cả hai hệ thống.
Xuyên suốt bài viết, chúng ta sẽ sử dụng ví dụ phổ biến: employees (nhân viên) và departments (bộ phận) với lược đồ quan hệ như sau:
 Quan hệ giữa employees và department ở đây là 1-N (1-nhiều).
Quan hệ giữa employees và department ở đây là 1-N (1-nhiều).
Nhưng sẽ có thời điểm nào đó, người quản lý có thể phân nhân viên Bill tới để làm việc giữa nhiều bộ phận. Quan hệ giữa employees và department bây giờ là N-N (nhiều-nhiều). Như vậy, lược đồ quan hệ bên trên không còn hợp lệ và data phải được thay đổi.
 Thêm một bảng mới works_in với trường dedication_pct để chỉ ra thời gian phân chia của Bill giữa các bộ phận.
Thêm một bảng mới works_in với trường dedication_pct để chỉ ra thời gian phân chia của Bill giữa các bộ phận.
JOINS trong MongoDB
Trong MongoDB, có hai cách chính để thể hiện mối quan hệ là "embedded" và "reference". Sử dụng "embedded", phải quyết định document nào là "outer", document nào là "inner". Thông thường, những document được ưa thích sẽ được đặt là "outer". Trong ngữ cảnh bài viết, employee được set làm "outer".
{
"_id": "1",
"ename": "Bill",
"age": 36,
"salary": 10000,
"department": {
"dname": "Shoe",
"floor": 1,
"budget": 1200
}
}
Nói cách khác, thông tin của department được lưu bên trong mỗi document của employee. Về cơ bản, đây là một biểu diễn "inline". Trong các ứng dụng document, biểu diễn này có thể có ý nghĩa, những trong data có cấu trúc, nó có hai nhược điểm lớn.
- Thứ nhất, thông tin department được lặp lại cho mỗi employee trong department.
Vì Bill và Fred đều ở bộ phận Shoe, thông tin bộ phận này sẽ bị lặp lại. Khi thông tin Shoe được cập nhật, giả sử budget được điều chỉnh, tất cả các bản sao phải được tìm thấy và cập nhật chính xác. Nếu thậm chí một bản sao bị bỏ qua, thì kết quả cơ sở dữ liệu sẽ không nhất quán (bị hỏng). Và tệ hơn, hoạt động cập nhật nhiều bản ghi này là non-atomic (theo mặc định của MongoDB); hoặc yêu cầu MongoDB 4.0+ multi-document transactions, nhưng điều này có một số hạn chế và phải chịu áp lực về hiệu suất. Trường hợp đầu tiên, có khả năng cơ sở dữ liệu sẽ bị hỏng, còn trường hợp thứ hai, hiệu suất sẽ kém hơn. Và chắc chắn một trong hai trường hợp này sẽ xảy ra.
- Thứ hai, không có chỗ nào để đặt thông tin của Candy, vì hiện tại không có nhân viên nào trong bộ phận này.
Do hai hạn chế này, chúng ta sẽ không xem xét biểu diễn này trong bài viết.
Các biểu diễn thay thế là “reference”. Trong trường hợp này, bản ghi của Bill sẽ được lưu trữ dưới dạng:
{
"_id": "1",
"ename": "Bill",
"age": 36,
"salary": 10000,
"department": "1001"
}
và sẽ có một document bộ phận riêng biệt để lưu trữ các thuộc tính của các bộ phận:
{
"_id": "1001",
"dname": "Shoe",
"floor": 1,
"budget": 1200
}
Về hiệu quả, biểu diễn này trông rất giống với biểu diễn quan hệ trong lược đồ đầu tiên. Tuy nhiên, dev phải biết trường department tham chiếu đến một document trong department collection. Nói cách khác, không có khái niệm về khóa ngoại để hỗ trợ trong việc chỉ định JOIN.
Bây giờ giả sử quản lý quyết định nhân viên có thể phân chia thời gian làm việc của họ giữa nhiều bộ phận. Không có chuẩn để biểu diễn ngữ cảnh này, nhưng thông thường, một mảng các tham chiếu sẽ được sử dụng.
Để ghi lại thông tin về dedication_pct trong một bộ phận nhất định, chúng ta có thể chuyển đổi trường department thành một mảng (collection) các đối tượng, chứa cả tham chiếu đến department collection và dedication_pct. Ví dụ, employee Bill:
Collection department:
{
"_id": "1001",
"dname": "Shoe",
"floor": 1,
"budget": 1200
},
{
"_id": "1002",
"dname": "Toy",
"floor": 2,
"budget": 1400
}
Collection employee:
{
"_id": "1",
"ename": "Bill",
"age": 36,
"salary": 10000,
"departments": [
{ "dept": "1002", "dedication_pct": 60 },
{ "dept": "1001", "dedication_pct": 40 }
]
}
Khi muốn có được các thông tin liên quan, quản lý có thể JOIN thủ công trong ứng dụng (dễ bị lỗi và khó cho dev) hoặc sử dụng $lookup (có giới hạn riêng, ví dụ: không thể $lookup từ sharded collection hoặc không hỗ trợ các phép nối RIGHT hoặc FULL OUTER JOINS).
JOINS trong Postgres
Về lý thuyết, có thể sử dụng một biểu diễn embedded trong Postgres và kiểu dữ liệu jsonb Postgres cho phép điều này. Tuy nhiên, rất hiếm khi thấy trong thực tế vì những nhược điểm đã nêu ở trên. Thay vào đó, thường sử dụng biểu diễn trong lược đồ đầu tiên, tương ứng với "reference" trong MongoDB.
Sử dụng chuẩn SQL, có thể tìm thấy danh sách tất cả các department và tổng salary của nhân viên của họ theo mô hình dữ liệu của lược đồ đầu tiên như:
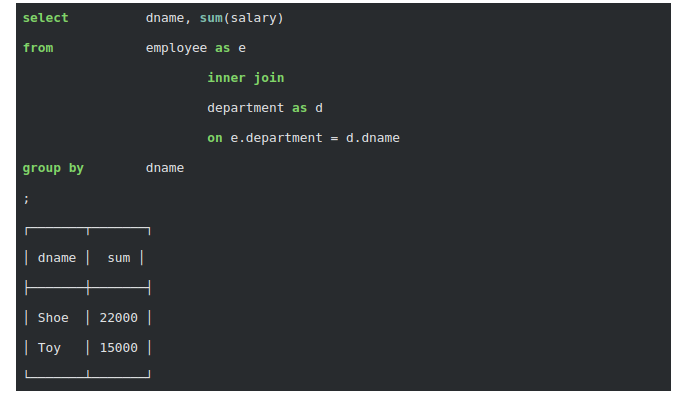
Khi nhân viên có thể làm việc trong nhiều bộ phận, người ta thường sử dụng biểu diễn trong lược đồ thứ 2. Truy vấn trên có thể dễ dàng chuyển đổi thành:
 Lưu ý rằng chỉ cần thêm dedication_pct vào mệnh đề tổng hợp và thay thế nhân viên bằng works_in thay đổi thuộc tính trong điều kiện JOIN để chuyển từ JOIN đầu tiên sang thứ hai.
Lưu ý rằng chỉ cần thêm dedication_pct vào mệnh đề tổng hợp và thay thế nhân viên bằng works_in thay đổi thuộc tính trong điều kiện JOIN để chuyển từ JOIN đầu tiên sang thứ hai.
JOINS dễ vỡ trong MongoDB
Bây giờ hãy xem xét lại trường hợp của dữ liệu trong lược đồ đầu tiên, JOIN giữa nhân viên và các bộ phận là 1-N. Để xây dựng một document chứa tổng salary cho mỗi bộ phận, trong MongoDB là:
db.employee.aggregate([
{
$lookup: {
from: "department",
localField: "department",
foreignField: "_id",
as: "dept"
}
},
{
$unwind: "$dept"
},
{
$group: {
"_id": "$dept.dname",
"salary": { "$sum": "$salary" },
}
}
]);
Kết quả,
{ "_id" : "Shoe", "totalsalary" : 22000 }
{ "_id" : "Toy", "totalsalary" : 15000 }
Chúng ta có thể thấy code này phức tạp hơn nhiều so với code trong Postgres, vì MongoDB không có các khái niệm JOIN quan hệ và là một ngôn ngữ cấp thấp hơn SQL. Ngoài ra, nó yêu cầu dev phải xây dựng một thuật toán cho việc truy vấn JOIN
Trong trường hợp này, kết hợp $unwind, $lookup và $group để truy vấn thông tin mong muốn. Đáng ngại hơn, khi chúng ta chuyển sang ngữ cảnh của lược đồ thứ hai, (thêm trường dedication_pct), code truy vấn JOIN trong MongoDB phải viết lại khá nhiều.
db.employee.aggregate([
{
$unwind: "$departments"
},
{
$project: {
"_id": 0,
"salary": 1,
"department": "$departments.dept",
"dedication_pct": "$departments.dedication_pct"
}
},
{
$lookup:
{
from: "department",
localField: "department",
foreignField: "_id",
as: "dept"
}
},
{
$unwind: "$dept"
},
{
$group:
{
_id: "$dept.dname",
totalsalary: { $sum: { $multiply: [ "$salary", "$dedication_pct", 0.01 ] } }
}
}
]);
Kết quả,
{ "_id" : "Shoe", "totalSalary" : 16000 }
{ "_id" : "Toy", "totalSalary" : 21000 }
Do đó, khi thay đổi ngữ cảnh của JOIN từ 1-N sang N-N, ứng dụng phải được viết lại đáng kể. Ngược lại, trong Postgres, các truy vấn vẫn gần như không thay đổi và đơn giản.
Tuy nhiên, tất cả các kết quả trước đây là một chút sai lệch, bởi vì bộ phận Candy không có nhân viên và không xuất hiện trong JOIN.
Giả sử , quản lý thực sự muốn xem cả ba bộ phận với tổng salary của họ. Nói cách khác, quản lý mong muốn được nhìn thấy bộ phận Candy với tổng salary bằng 0 ngoài hai bộ phận còn lại. Trong Postgres, điều này chỉ cần một thay đổi đơn giản cho truy vấn, cụ thể là thêm một RIGHT OUTER JOIN vào bảng bộ phận:
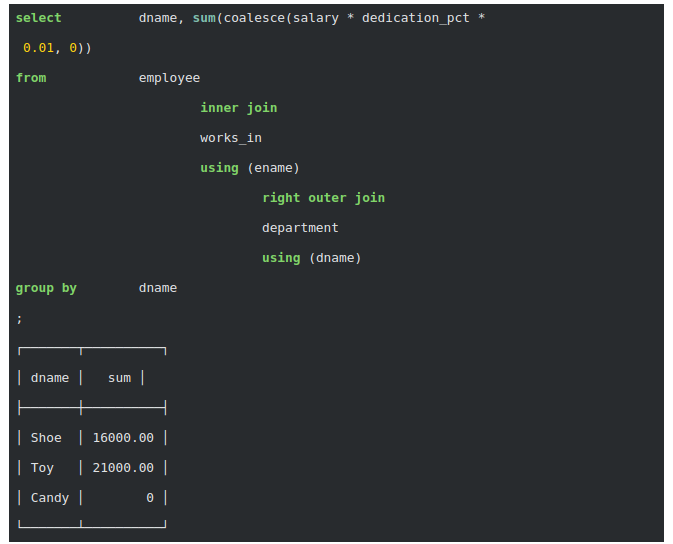
Tuy nhiên, trong MongoDB không hỗ trợ cho các phép nối RIGHT OUTER JOIN. Do đó, cần phải thêm "0" thủ công. Tất nhiên, đây là một gánh nặng cho các nhà phát triển và cồng kềnh dễ bị lỗi.
Các RDBMS thể hiện tính độc lập dữ liệu vượt trội so với các giải pháp cấp thấp hơn như MongoDB. Bởi vì cơ sở dữ liệu tồn tại trong một thời gian rất dài và ngữ cảnh có thể được thay đổi theo thời gian, tính độc lập dữ liệu vượt trội là một tính năng rất đáng mong đợi, có trong Postgres nhưng không có trong MongoDB. Vì vậy, JOIN trong MongoDB rất dễ vỡ.
So sánh hiệu năng của PostgreSQL với MongoDB
Trong phần này, chúng ta xem xét hiệu suất của hai truy vấn trong phần trước, cụ thể là tìm tổng salary của từng bộ phận, có hoặc không có bộ phận không có nhân viên.
Tất cả các mã nguồn trong phần này có ở đây, bạn đọc quan tâm có thể tìm thấy dữ liệu tổng hợp trong Postgres, sau đó sử dụng các hàm JSON của Postgres để xuất dữ liệu theo định dạng phù hợp để nhập vào Mongo. Sau đó, chúng ta chạy hai truy vấn trên cả hai tập dữ liệu và so sánh thời gian thực hiện.
Benchmark được thử nghiệm trên AWS, sử dụng instance EC2 i3.xlarge (4 cores, RAM 32GB), trên disk NVMe cục bộ được định dạng bằng XFS. Tuning cơ bản được thực hiện trên instance Postgres và các thực hiện tốt nhất về Mongo production đã được tuân thủ. Benchmark được thực hiện bằng cách sử dụng 4000 bản ghi department và 20 triệu employees, với một employee nhất định làm việc giữa một và ba departments. Kích thước dữ liệu là 6,1 GB ở Postgres và 1,6 GB ở Mongo (sử dụng nén mặc định). Tổng thời gian thực hiện được hiển thị trong các bảng dưới đây.
 MongoDB chậm hơn 130 lần so với Postgres vì cách JOIN duy nhất là lặp lại employee cho mỗi lần thực hiện tra cứu trong bảng department. Ngược lại, Postgres có thể sử dụng cách này (được gọi là thay thế lặp) cũng như merge JOIN và hash JOIN, và trình tối ưu hóa truy vấn Postgres sẽ chọn cách tốt nhất. MongoDB bị hạn chế trong một cách duy nhất. Bất cứ khi nào (và hầu như luôn luôn như vậy) cách duy nhất này kém hơn thì sẽ dẫn tới hiệu suất kém.
MongoDB chậm hơn 130 lần so với Postgres vì cách JOIN duy nhất là lặp lại employee cho mỗi lần thực hiện tra cứu trong bảng department. Ngược lại, Postgres có thể sử dụng cách này (được gọi là thay thế lặp) cũng như merge JOIN và hash JOIN, và trình tối ưu hóa truy vấn Postgres sẽ chọn cách tốt nhất. MongoDB bị hạn chế trong một cách duy nhất. Bất cứ khi nào (và hầu như luôn luôn như vậy) cách duy nhất này kém hơn thì sẽ dẫn tới hiệu suất kém.
Thay đổi cách thực hiện truy vấn MongoDB hoặc cơ cấu lại cơ sở dữ liệu (và do đó yêu cầu phải viết lại tất cả các truy vấn) hoặc implement trình tối ưu hóa truy vấn trong ứng dụng (đây là một công việc rất lớn).
Tương tự cho trường hợp N-N. Một lần nữa, MongoDB chỉ có một cách duy nhất, được mã hóa cứng vào ứng dụng. Ngược lại, Postgres có thể chọn từ tất cả các tùy chọn khả thi.

Kết luận
- JOINS trong MongoDB dễ vỡ như đã nói. Nếu bất cứ điều gì thay đổi trong suốt lifetime của cơ sở dữ liệu, thì MongoDB yêu cầu mã hóa lại đáng kể, trong khi Postgres yêu cầu thay đổi đơn giản hơn.
- MongoDB có hiệu năng kém hơn PostgreSQL. MongoDB không có trình tối ưu hóa truy vấn và chỉ có một cách thực thi được mã hóa cứng vào ứng dụng, do vậy hiệu suất Mongo sẽ bị ảnh hưởng.
All rights reserved
