
Sinh dữ liệu với mô hình dựa trên score
Bài đăng này đã không được cập nhật trong 4 năm
Chúng ta đã tìm hiểu về cách huấn luyện mô hình score và cách lấy mẫu với Langevin dynamics. Tuy nhiên cách làm trực tiếp đó chưa đủ để sinh ra dữ liệu tốt. Trong bài này chúng ta sẽ tìm hiểu về cách để xây dựng một mô hình score mạnh.
Ước lượng score của biến ngẫu nhiên ẩn
Thay vì ước lượng trực tiếp score của dữ liệu ban đầu, ta có thể áp dụng score matching cho biến ẩn của mô hình sinh. Ví dụ với mô hình variational autoencoder, ta sẽ cực đại ELBO thay vì likelihood
Việc tính ELBO gặp vấn đề ở entropy do ta cần biết chính xác hàm mật độ. Cách làm quen thuộc là xấp xỉ bởi một phân bố chuẩn, với hàm mật độ có công thức cho trước. Một cách giải quyết khác là biến đổi entropy theo score của , cách làm này giúp đa dạng hơn thay vì chỉ là phân bố chuẩn như trong VAE.
Ta sẽ áp dụng reparameterization trick, đặt , hàm sẽ đóng vai trò như encoder, nhận dữ liệu và nhiễu và sinh ra
Như vậy gradient của entropy có thể tính được thông qua score của , mô hình bởi một hàm , và Jacobian của . Để việc cài đặt thuận tiện hơn, ta sẽ không tính trực tiếp gradient của entropy mà sẽ tính trước mà không có gradient, sau đó tối ưu , gradient của đại lượng này chính là gradient của entropy, và lúc này có thể kết hợp với các bộ tối ưu có sẵn.
Đại lượng còn lại có thể tách thành như thông thường, với giả sử prior tuân theo phân bố chuẩn.
Tổng hợp lại, mô hình VAE huấn luyện với score sẽ gồm một autoencoder như trong VAE thông thường, và ELBO được ước lượng bởi một hàm score xấp xỉ score của , huấn luyện bởi score matching.
Các bạn có thể tham khảo code của tác giả tại đây
Sinh dữ liệu với mô hình score
Như đã nói ở phần mở đầu, phương pháp score matching cơ bản cùng với Langevin dynamics không đủ để sinh ra dữ liệu đủ tốt. Trước hết hãy xem ví dụ sau: Sử dụng Langevin dynamics để lấy mẫu từ phân bố tổng hợp của 2 phân bố chuẩn và với trọng số là như hình bên dưới
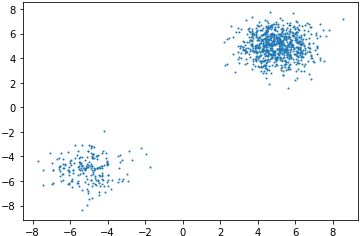
Ta có thể thấy phân bố này có 2 mode với xác suất cao nhưng cách xa nhau. Thuật toán SGLD do đó sẽ khó có thể di chuyển giữa 2 mode này. Lấy mẫu điểm với Langevin dynamics 100 bước, step size , ta được như hình dưới
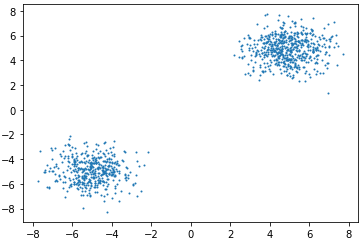
Code minh họa có thể xem ở đây
Điều này có thể giải thích như sau: Với phân bố tổng hợp , tại những điểm có tỉ lệ xác suất của hai phân bố lớn thì score gần như không ảnh hưởng bởi trọng số. Giả sử xác suất tại theo gần bằng , , score tại sẽ là
Ngoài ra, còn một vấn đề nữa nằm ở phương pháp score matching. Nhắc lại, mục tiêu của score matching là cực tiểu khoảng cách giữa hàm score mô phỏng và score thực tế của phân bố
Tuy nhiên nhưng điểm có xác suất thấp rất khó xuất hiện trong tập dữ liệu, do đó hàm mục tiêu sẽ không thể tối ưu tại các điểm này. Một ví dụ với bộ MNIST sử dụng denoise score matching, hàm score là mạng ResNet cho kết quả sau 200 epochs như sau

Để giải quyết điều này, ta có thể thêm nhiễu vào dữ liệu ban đầu. Lúc này, phân bố của nhiễu sẽ giúp tăng xác suất tại các vùng có mật độ xác suất thấp, giúp Langevin dynamics có thể hoạt động đúng.
Một vấn đề đặt ra là thêm nhiễu như thế nào mới phù hợp. Chú ý rằng denoise score matching cũng hoạt động bằng cách thêm nhiễu vào dữ liệu, tuy nhiên vẫn chưa thể học phân bố của bộ MNIST. Giả sử nhiễu có phân bố chuẩn, nếu phương sai của nhiễu lớn thì dữ liệu sẽ bị sai lệch đi nhiều, ngược lại nếu phương sai nhỏ, các vùng có xác suất thấp vẫn chưa thể tăng lên đáng kể để Langevin dynamics hoạt động (denoise score matching rơi vào trường hợp 2).
Thay vì chỉ thêm một loại nhiễu, ta có thể dùng một chuỗi gồm nhiễu với phương sai , lần lượt thêm từng nhiễu vào trong quá trình lấy mẫu. Ở các bước đầu, ta muốn nhiễu có độ phủ lớn để SGLD dễ dàng di chuyển giữa các mode, sau đó phương sai giảm dần để phân bố gần với phân bố gốc của dữ liệu. Do đó, phương sai sẽ có tính chất với . Chuỗi sẽ được chọn là chuỗi hình học , với đủ lớn để phủ các vùng mật độ thấp và đủ nhỏ để tránh sai lệch với phân bố gốc.
Hàm score lúc này cũng sẽ phụ thuộc vào phương sai để nhận biết SGLD đang ở bước nào. Thay vì dùng 1 hàm score , ta sẽ dùng hàm score .
Mục tiêu lúc này trở thành cực tiểu Fisher divergence trên tất cả các mức độ nhiễu, với ta sẽ cực tiểu
Cách đơn giản nhất để làm điều này là đặt , điều này đến từ quan sát sau: Cực tiểu tương đương với cực tiểu khoảng cách giữa và score của như phân tích ở bài trước, và .
Mô hình này được gọi là Noise conditional score network (NSCN). Hàm mục tiêu sẽ là tổng của loss trên tất cả mức độ nhiễu, với trọng số là
Ta cũng cần một thuật toán lấy mẫu mới phù hợp với cách mô hình này. Thay vì dùng Langevin dynamics với một phân bố duy nhất, ta chia quá trình lấy mẫu thành bước lần lượt, bước thứ sẽ bắt đầu Langevin dynamics ở bước và lấy mẫu với phân bố mục tiêu là . Phân bố sẽ có nhiễu lớn hơn với , do đó step size cũng sẽ lớn hơn. Tỉ lệ step size thường dùng là tại bước . Đây là thuật toán annealed Langevin dynamics.
Thử huấn luyện mô hình NCSN với score là mạng ResNet giống như trên cho ra kết quả chấp nhận được sau 200 epochs

Các bạn có thể tham khảo code của tác giả tại đây hoặc code mình cài đặt lại cho bài này tại đây
Kết
Bài này đã giới thiệu về các cách cải tiến và áp dụng mô hình sinh dựa trên score. Trong bài tiếp theo, chúng ta sẽ tìm hiểu về mô hình tổng quát hơn của score based model.
Tham khảo
All rights reserved
