
Simple Node classification GNN
Bài đăng này đã không được cập nhật trong 5 năm
Graphical Neural Net là một chủ đề rất hay, nhưng với các bạn mới học thì phần implementatiọn có thể sẽ hơi khó hiểu, vì nó khá khác so với các dạng bài về ảnh hay ngôn ngữ mà nhiều bạn quen làm. Trong bài viblo này, mình muốn chia sẻ về cách implement một bài node classification sử dụng thư viện dgl. Lý do mình chọn dgl vì ban đầu mình học pytorch geometric nhưng tutorial của thư viện này có vài chỗ khó hiểu với mình nên mình chuyển sang dgl.
Bài viết này lấy cảm hứng từ một bài viblo rất đáng đọc Graph Neural Network - A literature review and applications. Nếu bạn nào là beginners về GNN, mình khuyên các bạn nên xem qua bài viết này trước khi đọc tiếp bài của mình.
1. Các thành phần của một Graph
Theo các bạn một Graph như trong hình sau sẽ được tạo ra như thế nào:
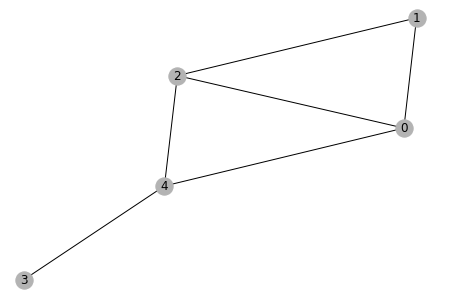
Đây là một graph vô hướng nhưng object graph được khởi tạo trong dgl sẽ có hướng(bằng object dgl.DGLGraph hoặc dgl.graph), xác định bằng cách tạo một list gồm các node source và một list là các node destination tương ứng với các node source đó. có hai cách để tạo một graph vô hướng như sau:
- mỗi một edge trong graph phải tương ứng với 2 cặp
source, destination. Ví dụ: (0, 1) và (1, 0)
import dgl
#các nodes nguồn (source)
scr = np.array([0, 0, 0, 1, 1, 2, 2, 2, 3, 4, 4, 4])
#các nodes tới (destination)
dst = np.array([1, 2, 4, 0, 2, 1, 0, 4, 4, 0, 2, 3])
# tạo instance của object graph trong DGL
gd = dgl.graph((scr, dst))
print(dg)
>>> output:
Graph(num_nodes=5, num_edges=12,
ndata_schemes={}
edata_schemes={})
- Mối edge chỉ tương ứng với 1 cặp (source, destination) và dùng function
dgl.to_bidirected(gd)để đưa về graph vô hướng
#các nodes nguồn (source)
scr = np.array([0, 0, 0, 1, 2, 3])
#các nodes tới (destination)
dst = np.array([1, 2, 4, 2, 4, 4])
# tạo instance của object graph trong DGL
gd = dgl.graph((scr, dst))
print(gd.num_edges())
>>>6
# convert sang undirected graph
gd = dgl.to_bidirected(gd)
print(gd.num_edges())
>>>12
Bây giờ, sau khi đã có một graph đơn giản, ta có thể visualize nó như sau : (đoạn code này mình tham khảo từ dgl tutorial, và mình rất lười hiểu các code visualization nên đoạn này mình không giải thích gì thêm). Output sẽ là hình như trên
import networkx as nx
nxgd = gd.to_networkx().to_undirected()
pos = nx.kamada_kawai_layout(nxgd)
nx.draw(nxgd, pos, with_labels=True, node_color=[[.7, .7, .7]])
Các bạn sẽ thắc mắc, thế còn các features của các nodes và edges thì sao, như degree của từng node chẳng hạn. Cái này mình hoàn toàn có thể thêm vào như phần hướng dẫn dưới đây.
2. Karate club graph
Karate là một dataset gồm 34 người , chắc là họ cùng tập võ với nhau. Nhưng một ngày xấu trời, có hai người cãi vã là ông John và ông Hi. Hai ông này muốn tách nhóm và ai thân với ông nào hoặc thân với người mà thân với ông nào, so on.. thì thuộc vào nhóm ông đấy. (Câu chuyện này được mình thêm mắm muối từ nguồn wiki thôi chứ chuyện thật thì mình không biết). Và bài toán đặt ra là semi-supervised learning, biết một số người trong nhóm, hãy đoán labels của những người còn lại
Phần này, mình sẽ dùng một graph có sẵn trong thư viện dgl. (Cách tạo graph này không khác gì cách mình vừa miêu tả ở trên, chỉ là đoạn liệt kê lists của source node và destination nodes dài nên mình dùng của thư viện luôn cho nhanh. Lần tới, mình sẽ hướng dẫn các bạn cách tạo graph từ các file ngoài như json hay csv).
## lấy data từ dgl.data
karate = dgl.data.KarateClub()
# graph được lưu trong attribute data.
# data chứa list của các graph (phần này mình sẽ nói thêm ở các bài viết sau).
# nhưng trong trường hợp này chỉ có một graph thôi
g = karate.data[0]
>>> g
Graph(num_nodes=34, num_edges=156,
ndata_schemes={'label': Scheme(shape=(), dtype=torch.int64)}
edata_schemes={})
g chứa 34 nodes, index từ 0 đến 33; 156 edges, mỗi edge là một cặp source, destination, và 34 true labels cho mỗi node.
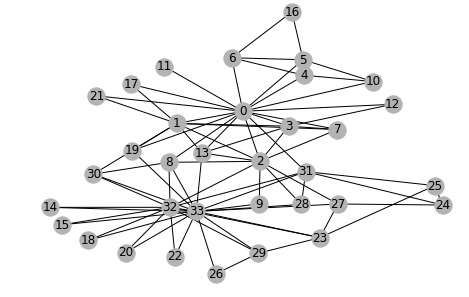
Đầu tiên, để thử tìm hiểu degree của từng node, ta dùng g.in_degrees(index_node) để biết số node có links tới node đó, là g.out_degrees(index_node) để biết số links ra khỏi node đó. Vì đây là un_directed graph nên links ra sẽ bằng links vào.
Lưu ý các attributes thêm vào cho nodes hoặc edges phải có attr.shape[0] bằng số nodes hoặc edges.
# thêm attributes degrees cho các nodes dùng cho normalize representation
g.ndata['degrees'] = torch.cat([g.in_degrees(node) for node in g.nodes()])
>>> degrees tương ứng với các node index từ 0 đến 33
tensor([16, 9, 10, 6, 3, 4, 4, 4, 5, 2, 3, 1, 2, 5, 2, 2, 2, 2,
2, 3, 2, 2, 2, 5, 3, 3, 2, 4, 3, 4, 4, 6, 12, 17])
Degree có thể được dùng làm node features nhưng trong bài này mình sẽ sử dụng learnable node features. Cách thêm features cho nodes như sau:
g.ndata['node_features'] = nn.Parameter(torch.randn(g.num_nodes(), 10))
object graph của dgl có rất nhiều attributes, các bạn có thể khám phá thêm.
Ở đây, g.ndata, g.edata là dictionaries chứa node data và edge data. node features còn có thể được lưu ở g.srcdata (dictionary), hoặc g.dstdata (dictionary ) tùy mục đích sử dụng. Hãy xem những gì được lưu trong các attributes này:
g.ndata: dict_keys(['label', 'node_features'])
g.srcdata: dict_keys(['label', 'node_features'])
g.dstdata: dict_keys(['label', 'node_features'])
g.edata: dict_keys([])
Tiếp đến , mình sẽ dùng tất cả thông tin của graph để train, nhưng label thì chỉ biết cho vài node. Hợp lí nhất là chỉ biết label của ông John (label: 0) và ông Hi (label:1) nhưng để không làm mất tính tổng quát mình sẽ randomly cho biết label của một lượng node nhất định. Số còn lại để làm validation và test.
Đoạn code này chỉ để chia nodes thành train , val, test, tạo ra các mask dùng trong tính loss (lưu ý chỉ là dùng cho loss thì vì thông tin của cả graph sẽ dùng để train (khác với khi làm việc với ảnh và ngôn ngữ thông thường)). phần này đơn giản và không quan trọng nên mình để phần giải thích trong code luôn.
def masks(split_pct, num_nodes):
"""1 - split_pct: bao nhiêu % cho training
num_nodes: số lượng nodes trong cả graph"""
# chuyển từ % nodes tách là train thành số nodes tách
split_point = int(split_pct*num_nodes)
# shuffle các indices của các node trong graph
indices = np.random.permutation(range(num_nodes))
# indices của training
train_idx = indices[split_point:]
# như trên nhưng cho val và test
val_idx = indices[:split_point//2]
test_idx = indices[split_point//2: split_point]
return train_idx, val_idx, test_idx
train_idx, val_idx, test_idx =[ torch.LongTensor(idx) for idx in masks(.8, g.num_nodes())]
print(train_idx)
>>> tensor([ 6, 25, 16, 11, 13, 5, 14])
Tổng kết lại, ta đã có các thông tin cho training như sau: các node_fetaures (learnable), mối quan hệ binary: ai liên kết với ai, ai thuộc nhóm nào (labels: cho training). Đây mới chỉ là một setting rất đơn giản vì:
- Các node đều cùng một type: hội viên hội karate
- Các edge cùng một type: ai hay đánh nhau với ai
- Các edge không có trọng số, chỉ binary
Hay nói cách khác, graph này là homogeneous (đơn thành phần). Bài toán node classification đơn giản này có thể trở nên phức tạp hơn nhiều bằng cách thay đổi các yếu tố trên, biến graph heterogeneous (đa thành phần).
3. Graph Conv
Phần này, mong các bạn đọc bài viblo Graph Neural Network - A literature review and applications trước khi đọc tiếp bài mình.
Bài toán đặt ra là: làm thế nào để learn representation của một node dựa vào mối liên hệ với các node còn lại và chính các thuộc tính ban đầu của node đó (deterministic: như node’s degree hoặc learnable). Như sau:
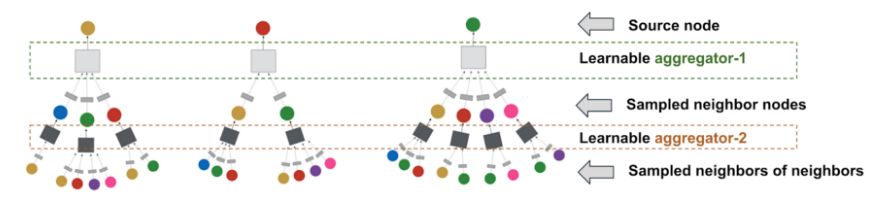
Source: PinSage
Lưu ý, trong paper PinSage, embedding của một node ở layer -th được tổng hợp bởi sampled neighbors của node đó, trong khi ở paper GraphConv thì full neighbors sẽ được sử dụng.
Có hai khái niệm về depth ta cần để ý ở đây. Một là relationship depth và transforming network depth (đây không hẳn là thuật ngữ, mình gọi tên vì không biết có thuật ngữ cho cái này hay không). Chiều sâu mối quan hệ. Để biết về ai đó các bạn chỉ cần tìm hiểu bố mẹ anh chị , bạn bè là đủ hay còn cần biết cả ông anh họ xa 9 đời của người đó. Depth còn lại là chiều sâu của mạng network mà bạn dùng để transform thông tin, features của các nodes.
Trong GraphConv layer paper, thì công thức tổ hợp thông tin cho một node ở một layer đơn giản là:
Trong đó: là representation của nodes ở layer , là linear transformed matrix, , là ma trận liền kề, cộng thêm được coi các nodes có link với chính chúng, là diagonal matrix, chứa degrees của từng node trong graph, là activation function
Công thức trên đã được ma trận hóa, nên việc code rất đơn giản. Tuy nhiên khi số nodes không phải là 34 như bài này mà là 34,000,000 nodes chẳng hạn thì không thể implement dạng matrix này được. Công thức này rất đơn giản:
- Feature/information của các node lân cận được linearly projected đến embedding space của destination node của layer này.
- Information của các node lân cận được tổng hợp đơn giản bằng cách cộng lại với nhau sau khi được linearly transformed
- không có features nào của edge được sử dụng
- Embedding của node destination được tổ hợp từ infomation của chính node đó ở layers trước với information của các node lân cận bằng phép cộng. (có thể hiểu đơn giản là tạo thêm liên kết cho node đó với chính nó)
- Cuối cùng embedding đó được normalize lại bằng số lượng liên kết (
degrees) mà nó có (un_directly). Làm thế để tránh magnitude của representation bị ảnh hưởng bởi số lượng liên kết.
Nếu công thức trở nên phức tạp hơn (phức tạp hóa các bước trên) thì việc implement bằng full ma trận sẽ rất vất vả.
Để hiểu cách implement bằng thư viện dgl, đầu tiên ta cần hiểu một số khái niệm:
Message function: đầu vào là object edges, chứa thông tin về source nodes, destination nodes, features của links ở dictionaries edges.src, edges.dst, edges.data. Output là một tensor (num_nodes, dim của output) gồm các thông điệp (message từ các neighbors gửi sang)
# message đơn giản chính là copy lại của feature source nodes
def message_func(edges):
return {'m': edges.src['node_features']}
## builtin : nên sử dụng hàm builtin khi có thể vì các hàm này được implement tối ưu trong dgl
import dgl.function as gf
# argument 'node_features' là key để retrive data trong edges.src,
# argument 'm' là key lưu output vào nodes.mailbox (đoạn sau)
fg.copy_src('node_features', 'm')
Reduce function: ta sẽ tổ hợp các thông điệp từ node lân cận như thế nào. có thể sum, mean, max…
Ở đây, input sẽ là objects nodes, attributes mailbox và data là các dictionaries. message được chứa trong nodes.mailbox. message không còn là tensor nữa mà là các tensor dạng (batch_size, degrees, dim) : các message của các node có cùng degrees (số liên kết) sẽ được đưa vào cùng một batch để tính toán.
def reduce_func(nodes):
# print để các bạn thấy rõ khi áp dụng g.update_all(dưới đây),
# các message sẽ được gom vào các batch như thế nào
print(nodes.mailbox['m'].shape)
return {'agg': (nodes.mailbox['m']).sum(1)}
## builtin
fg.sum('m', 'agg')
Update_function: đầu vào là message hoặc info của chính node destination của layer trước và aggregated message của các node lân cận, tổ hợp ra embedding của node destination ở layer hiện tại. (function này có hoặc không cũng được, vì việc update node embedding có thể được thực hiện ở ngoài g.update_all())
g.update_all(): function giúp ta thực hiện toàn bộ quá trình gộp node vào batch, tìm các node lân cận, tính toán các phép tính tron các functions ở trên dựa trên các liên kết của các nodes. đầu ra sẽ được đưa vào g.ndata và g.dstdata.
g.update_all(message_func, reduce_func)
>>> output của print(nodes.mailbox['m'].shape)
torch.Size([1, 1, 10])
torch.Size([11, 2, 10])
torch.Size([6, 3, 10])
torch.Size([6, 4, 10])
torch.Size([3, 5, 10])
torch.Size([2, 6, 10])
torch.Size([1, 9, 10])
torch.Size([1, 10, 10])
torch.Size([1, 12, 10])
torch.Size([1, 16, 10])
torch.Size([1, 17, 10])
#sau khi update_all, g.ndata sẽ chứa gì ?
g.ndata.keys()
>>>
dict_keys(['label', 'node_features', 'agg'])
Đến đây thì ta đã có đủ mọi yếu tố để viết class GraphConv như công thức :
Công thức này chỉ là cách viết dưới dạng component cho công thức trên.
class GraphConv(nn.Module):
def __init__(self, num_ins, num_outs, activation = True):
super().__init__()
# linear để transform node features từ layer trước
self.linear1 = nn.Linear(num_ins, num_outs)
# layer cuối để predict và tính loss sẽ output ra logits,
# không dùng activation/ hoặc là dùng Identity activation
# còn ở các layer khác sẽ dùng relu activation
self.activation = nn.ReLU() if activation else Identity()
reset_param(self)
def forward(self, g, feats):
#lưu features các nodes của layer trước vào source data,
# như vậy object edges ở message fucntion có thể access các features này
g.srcdata.update({'h': feats})
def message_func(edges):
#message là linear transformed features của node lân cận
return {'m': self.linear1(edges.src['h'])}
def update_func(nodes):
# thêm infomation từ chính node đó, normalize bằng degrees
out = (nodes.data['agg']+ self.linear1(nodes.data['h']))/nodes.data['degrees']
return {'out': self.activation(out)}
g.update_all(message_func, fg.sum('m', 'agg'), update_func)
# output của g.update_all() được lưu vào g.ndata
return g.ndata['out']
Viết lại layet Identity đơn giản trong bài:
class Identity(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
Vì nn.Linear() initializing weights với nn.init.kaiming_uniform_(a=math.sqrt(5))). Số 5 này mình không hiểu họ lấy từ đâu ra vì paper về kaiming_initialization (paper) không suggest nó. Nên mình đã init lại các linear layer trong bài code như sau:
def reset_params(net):
for child in net.children():
if isinstance(child, nn.Linear):
nn.init.kaiming_uniform_(child.weight)
4. Network
Bây giờ, chúng ta có thể implement network architecture sau:
Node sẽ được tổng hợp từ các node lân cận với node và chính node . các node lân cận này sẽ được tổng hợp từ các node lân cận của chúng và chính chúng.
class Net(nn.Module):
def __init__(self, num_ins, num_hids, num_outs):
super().__init__()
# network gồm 2 layer graphconv
self.gconv1 = GraphConv(num_ins, num_hids)
self.gconv2 = GraphConv(num_hids, num_outs, activation= False, norm= False)
def forward(self, g, node_features):
out = node_features
## tổ hợp infomation cho từng node của từng layer
for gconv in [self.gconv1, self.gconv2]:
out = gconv(g, out)
return out
5. Training
Chúng ta sẽ tiến hành training như bài toán Computer vision hay NLP bình thường. Chỉ khác là cụ thể trong bài này, khi tính loss, loss sẽ chỉ được tính cho các node dùng trong training, nhưng cả graph, với tất cả các node sẽ được dùng trong training.
net = Net(10, 15, 2)
# đừng quên parameter của node features
optimizer = optim.Adam(itertools.chain(net.parameters(), [g.ndata['node_features']]), lr= 0.01)
# lưu logits cho visualizing
all_logits = []
for epoch in range(50):
logits = net(g, g.ndata['node_features'])
all_logits.append(logits)
log_softmax = F.log_softmax(logits, dim = -1)
# loss chỉ được tính cho các nodes dùng trong training
loss = F.nll_loss(log_softmax[train_idx], g.ndata['label'][train_idx])
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch %d | Loss: %.4f' % (epoch, loss.item()))
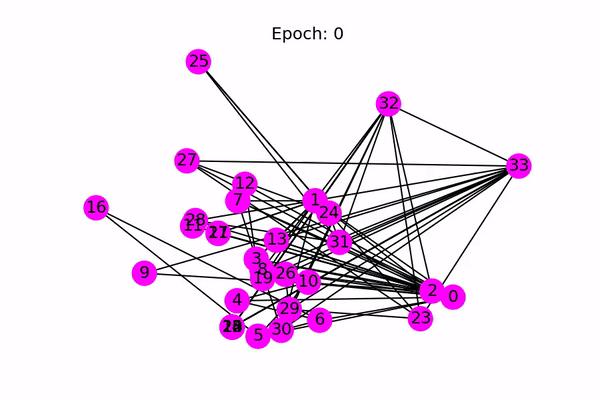
Sau khi train, ta có thể visualize quá trình trạining bằng code sau (again, các code visualize mình đều chỉ lấy từ nguồn áp vào, và mình không cố hiểu thêm chúng).
lưu ý: hình gif dưới đây là kết quả khi mình dùng cả tập dataset để train, không có val và test set.
import matplotlib.animation as animation
import matplotlib.pyplot as plt
from IPython.display import HTML
ani = animation.FuncAnimation(fig, draw, frames=len(all_logits), interval=200)
HTML(ani.to_html5_video())
Ở các bài sau mình sẽ:
-
Thay vì sử dụng
GraphConv, mình sẽ dùng các công thức phức tạp hơn để tổng hợp thông tin trong một layer:GraphSAGE,Graph Attention,residual graph layer -
Ở bài này mình đã không nói đến một phần quan trọng là stochastic training. Phần này sẽ có ở các bài tiếp theo
-
Dạng bài node classification cho homogeneous graph là dạng toán rất đơn giản, dễ implement. Các dạng phức tạp hơn, giống với các real-life graph hơn sẽ được đề cập sau.
Reference:
All rights reserved
