Sidekiq, how to reliability?
Bài đăng này đã không được cập nhật trong 7 năm
Thông thường, khi xây dựng một ứng dụng web, quy trình đơn giản sẽ như sau:
- Người dùng gửi yêu cầu, request tới web application.
- Web application nhận request, xử lý (hoặc giao tiếp với service khác như database để xử lý).
- Cuối cùng trả về kết quả cho user.
Ví dụ trong thực tế, bạn đăng ký user ở một website nào đó, sau khi nhập đầy đủ thông tin, submit -> request sẽ được gửi lên server và người dùng sẽ chờ cho tới khi server xử lý xong và trả về kết quả (thành công hoặc thất bại). Do người dùng phải chờ nên ta gọi đó là synchronous task.
Tuy nhiên trong thực tế, không phải lúc nào web app cũng xử lý nhanh hoặc không phải lúc nào chúng ta cũng cần phản hồi ngay lập tức kết quả cho người dùng. Ví dụ sau khi đăng ký ta có gửi email thông báo tới cho người dùng, nhưng không nhất thiết phải gửi email ngay lập tức cho người dùng, có thể chậm 1-2 phút cũng chấp nhận được hoặc ví dụ các tác vụ resize, optimize ảnh do người dùng upload thường tốn nhiều thời gian, nếu để user chờ ở màn hình upload cũng không phải là cách hay.
Những tác vụ như vậy ta có thể đưa vào chạy nền hay còn gọi là backgroud job/asynchronous job. Giúp tránh bắt người dùng phải chờ đợi lâu mà vẫn đảm bảo là sẽ xử lý tác vụ đó cho người dùng.
Mô hình chung sẽ như sau:

- Broker là một queue ví dụ như redis, RabbitMQ.
- App sẽ enqueue các tác vụ cần xử lý background tùy vào từng request.
- CRON sẽ enqueue các bg job định kỳ vào những thời điểm cụ thể.
- Worker sẽ dequeue và xử lý các tác vụ đó.
Sidekiq là một background processing framework cho ngôn ngữ Ruby để giải quyết các bài toán tương tự như trên. Xử lý background không phải là bài toán mới, bất kỳ ngôn ngữ lập trình nào cũng có những cách giải quyết tương tự, về job queue cũng có rất nhiều lựa chọn khác nhau ví dụ Gearmand, Celery, rq.
Các xử lý mà sẽ phù hợp để đưa vào chạy nền bao gồm:
- Các xử lý nặng về CPU, ví dụ các phép tính toán học hoặc phân tích cấu trúc.
- Các xử lý nặng về I/O ví dụ load data tính toán report, ETL.
- Batch job ví dụ như update/processing report về đêm.
- ...
1. Sidekiq Architecture
Sidekiq gồm 3 phần chính:
- Sidekiq client chạy trên bất kỳ Ruby process nào đó ví dụ như puma hoặc passsenger cho phép tạo job để xử lý sau.
- Redis là data storage cho sidekiq, dùng để lưu trữ các job được đẩy xuống từ sidekiq client.
- Sidekiq server là một process độc lập, pull job từ queue trong Redis và xử lý.
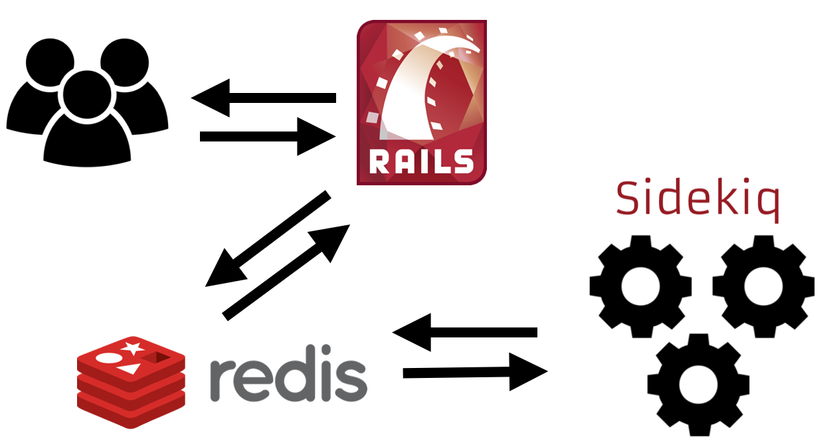
Đứng ở góc độ vận hành hệ thống, mình chỉ quan tâm chuyện gì xảy ra khi bất cứ thành phần trên fail và làm cách nào để đảm bảo hệ thống có khả năng fail-over. Để trả lời câu hỏi đó thì cần phải hiểu cách hoạt động, implement của sidekiq.
2. How to Reliability?
2.1 Sidekiq client
Khi sidekiq client push một job tới redis, giả định rằng network không hoạt động tốt, dẫn tới job không thể lưu trữ vào redis, vậy làm sao đảm bảo độ tin cậy cho sidekiq client? Một hướng tiếp cận đó là implement một local queue để lưu trữ các job nếu gọi network fail và sẽ delivery khi network kết nối thành công. fluentd cũng có một cách tương tự gọi là buffer, logstash cũng có cách giải quyết tương tự là persistent queue. Tuy nhiên nó cũng có một số nhược điểm:
- local queue per-process và in-memory, nếu client process bị restart thì job vẫn bị mất.
- sidekiq chỉ lưu 1000 job cuối cùng để tránh lưu quá nhiều dẫn tới full mem.
2.2 Redis
Redis được dùng để lưu trữ các job cần xử lý, nếu storage fail ta mất tất cả các job chưa kịp xử lý và người dùng sẽ không nhận được thứ mà họ cần.
Câu hỏi là tại sao lại là redis chứ không phải cái gì khác? Và làm sao đảm bảo dù fail cũng phải đảm bảo tác vụ của người dùng được xử lý.
- Redis có tốc độ read/write operation rất tốt so với các storage khác như MySQL nên dùng redis lợi hơn về mặt tốc độ (Gearman có hỗ trợ persistent vào MySQL và memcached)
- Nếu so với memcached thì redis hỗ trợ nhiều kiểu dữ liệu hơn và vẫn có cơ chế persistent dữ liệu xuống đĩa cứng định kỳ, tất nhiên nếu redis fail mà chưa kịp persistent dữ liệu xuống thì vẫn mất job tuy nhiên vùng dữ liệu bị mất sẽ nhỏ hơn.
- Tuy nhiên nếu redis server chết hẳn thì sidekiq client sẽ không thể đẩy job vào redis được, có nghĩa là người dùng vẫn bị stuck. Lúc này ta có thể sử dụng redis sentinel (master-slave) vừa đảm bảo việc persistent job vừa đảm bảo failover nếu 1 server chết.
- Redis chạy ổn khi tất cả data fit vừa với memory, nếu full mem redis sẽ evict data theo policy mà ta cấu hình, ví dụ LRU -> mất các job cũ chưa kịp xử lý nên để đảm bảo không evict nhầm nên cấu hình redis maxmemory-policy noeviction.
- Redis thường được xài để cache dữ liệu, tuy nhiên bản chất của việc cache và storage job là khác nhau (cache có thể invalidate nhưng job thì không được mất), nên tốt nhất là xài tách rời 2 server redis cho việc cache và lưu job sidekiq.
- Một lý do nữa nên tách redis dùng cho cache và redis dùng để storage backgroud job cho sidekiq là timeout. Khi full mem, để không bị OOM redis sẽ xài tới swap -> disk swapping -> tăng độ trễ khi đọc dữ liệu. Hoặc nếu có các command latency trên redis mà tốn thời gian cũng gây ra độ trễ khi pull job.
2.3 Sidekiq server
Câu hỏi đặt ra là:
- Nếu sidekiq xử lý liên tục thì làm sao để restart sidekiq khi một job đang được sidekiq xử lý?
- Nếu job bị lỗi, exception thì cơ chế nào để retry?
- Nếu sidekiq server đang xử lý một job, nhưng bị segfault hoặc crash hoặc force kill (kill -9) thì làm sao đảm bảo job vẫn sẽ được xử lý.
Về câu hỏi đầu tiên, đây là một điểm khá thú ví về cách thiết kế, nếu ai quen với nginx sẽ thấy một cơ chế tương tự. Phần giải thích này thực chất là phần Signals trong wiki của Sidekiq.
- Khi ta gửi TSTP signal tới sidekiq (kill -TSTP [sidekiq_pid]), Sidekiq sẽ hiểu là nó sẽ bị shutdown trong tương lai gần, sidekiq sẽ chuyển sang trạng thái "quiet" nghĩa là nó sẽ dừng việc fetch new job từ redis nhưng vẫn tiếp tục xử lý các job mà nó đang giữ, khi tất cả các current job được xử lý xong thì sidekiq sẽ shutdown.
- TERM signal nghĩa là Sidekiq nên shutdown sau khoảng thời thời gian -t timeout. Tương tự như TSTP sidekiq cũng sẽ không fetch job mới nhưng vẫn tiếp tục xử lý các job cũ cho xong. Điểm khác biệt là sau timeout nếu job không được hoàn thành thì sẽ bị force terminated và message đó sẽ được push back lại vào redis, để lần sau khi sidekiq được start job đó sẽ được fetch lại và được xử lý.
=> Best practice là ta sẽ gửi signal TSTP lúc bắt đầu deploy và TERM lúc kết thúc deploy. Và lúc này có thể thoải mái restart mà không sợ bị miss bất cứ job nào.
Sidekiq có built-in một chơ chế để retry, sẽ catch các exception và tự động retry thường xuyên dựa trên công thức (retry_count ** 4) + 15 + (rand(30) * (retry_count + 1)) (tương đương 15, 16, 31, 96, 271, ... giây + một lượng random time), với giá trị default retry là 25 nghĩa là để thực hiện 25 lần retry sẽ vào khoảng 21 ngày, trong 21 ngày này ta có thể fix bug, deploy và job sẽ được xử lý thành công ở lần retry tiếp theo.
Nếu sau 25 lần retry và job vẫn không thành công thì sidekiq sẽ chuyển job đó và Dead Job queue và phải can thiệp thủ công để chạy lại job đó. Và nếu sau 6 tháng, job đó không được xử lý thì sidekiq sẽ discard job đó.
Về câu hỏi cuối, làm thế nào để đảm bảo tính tin cậy cho một job khi được fetch bởi sidekiq server, và sidekiq server bị crash thì job đó vẫn có thể được xử lý. Đây là một bài toán rất thú vị để tìm hiểu và qua đó ta sẽ thấy sức mạnh của redis.
Trước tiên ta sẽ nói 1 chút xíu về list và queue trong redis. Trong redis thì list là một tập hợp của các phần tử có kiểu dữ liệu là string đã được sắp xếp bằng thuật toán insertion sort. List trong redis được implement bằng cấu trúc dữ liệu là linked list.
Redis hỗ trợ một số lệnh trên list như LPUSH, RPUSH, LPOP, RPOP, LLEN, LINSERT, LINDEX, với tập lệnh này ta có thể dùng list trong redis như queue (FIFO với tập lệnh LPUSH, RPOP, phần tử thêm vào đầu tiên sẽ được lấy ra đầu tiên) hoặc stack (LIFO với tập lệnh RPUSH, LPOP, phần tử thêm vào đầu tiên sẽ được lấy ra sau cùng).
Bằng cách sử dụng list như queue ta có thể implement producer để đẩy dữ liệu và consumer để lấy dữ liệu từ trong queue ra với 2 step đơn giản:
- push item vào list, producer gọi LPUSH.
- lấy item trong list, đem ra xử lý, consumer gọi RPOP.
Vấn đề là không phải lúc nào list của chúng ta cũng có phần tử, và khi list không có phần tử thì sẽ consumer sẽ không có gì để xử lý cả, lệnh RPOP trả về nil.
127.0.0.1:6379> LPUSH sidekiq a b c
(integer) 3
127.0.0.1:6379> LLEN sidekiq
(integer) 3
127.0.0.1:6379> RPOP sidekiq
"a"
127.0.0.1:6379> RPOP sidekiq
"b"
127.0.0.1:6379> RPOP sidekiq
"c"
127.0.0.1:6379> RPOP sidekiq
(nil)
Để giải quyết vấn đề trên, ta có thể bắt consumer đợi trong một khoảng thời gian nào đó và sau đó sẽ gọi lại LPOP để lấy dữ liệu, kỹ thuật này gọi là polling. Tuy nhiên kỹ thuật này vẫn có nhược điểm:
- Nếu lần gọi lại RPOP để lấy dữ liệu mà list vẫn rỗng nghĩa là consumer tốn công xử lý một lệnh vô nghĩa và redis server cũng tốn công xử lý mà không đạt được kết quả gì.
- Tăng thời gian để gọi lại RPOP lấy dữ liệu, nghĩa là sau khi consumer nhận về nil thì sẽ đợi một khoảng thời gian rồi mới RPOP lại. Tuy nhiên delay-time mà cao thì có thể sẽ có một lượng lớn item được push vào list rồi mà delay-time mà quá ngắn thì lại quay về vấn đề số 1, gọi lệnh vô nghĩa.
Do đó redis implement một số lệnh gọi là blocking operation đó là BLPOP và BRPOP. Nghĩa là nếu list rỗng, thay vì trả về nil thì consumer sẽ block connection và chờ với một khoảng thời gian timeout (ta có thể chờ vô tận bằng cách set timeout = 0), khi có một item mới được thêm vào list thì POP ra và xử lý. Điểm khác biệt là không cần phải định kỳ quay trở lại kiểm tra -> tránh thực hiện các lệnh vô nghĩa.
Quay trở lại vấn đề của sidekiq server, sidekiq dùng lệnh BRPOP để fetch một job từ trong queue redis ra và xử lý, không có gì phải bàn cãi về việc tại sao lại dùng BRPOP nữa, tuy nhiên việc dùng BRPOP hay RPOP bị một vấn đề là sau khi sidekiq fetch job thì job đó không còn tồn tại trong redis. Và bây giờ, nếu sidekiq crash, job vừa được fetch ra, chưa kịp xử lý sẽ biến mất hoàn toàn.
Tóm lại, đen thôi, đỏ quên đi, nếu quay trở lại vấn đề restart, sidekiq có shutdown thì vẫn có thể push-back job lại về redis chứ đã crash giữa đường job sẽ không có cách nào cứu chữa.
Vậy thử nghĩ xem có cách nào để đảm bảo tính tin cậy khi xử lý job, theo cách suy nghĩ thông thường thì ĐƠN GIẢN là khi fetch job thì đừng XÓA job đó ra khỏi queue của redis. Tuy nhiên nó dẫn tới một vấn đề khác đó là một sidekiq server khác có thể nhìn thấy job đó, fetch ra và xử lý job đó. Hệ quả là job được xử lý 2 lần, nếu bạn gửi mail thì có nghĩa là người dùng sẽ nhận được 2 email có cùng nội dung.
Một cách tiếp cận khác là thay vì giữ job đó trong queue thì ta vẫn cứ fetch job đó ra nhưng sau đó sẽ push job đó vào một queue khác gọi là queue_đang_xử_lý. Đây chính xác là cách lệnh RPOPLPUSH trong redis hoạt động, reliable queue pattern. Lệnh này:
- Fetch và xóa last-item (tail) từ queue cũ và cùng thời điểm đó thêm item đó đầu một queue khác -> gọi là processing_queue (head).
- Atomically return nghĩa là hoạt động như transaction trong database, 1 là thành công thì commit (xóa từ queue cũ và thêm vào queue mới), 2 là fail thì rollback, trả job về lại queue cũ.
- Dùng lệnh LREM theo thứ tự để xóa item trong processing_queue một khi item đó đã được xử lý xong
127.0.0.1:6379> LPUSH sidekiq a b c
(integer) 3
127.0.0.1:6379> RPOPLPUSH sidekiq sidekiq_current_processing
"a"
127.0.0.1:6379> LRANGE sidekiq 0 -1
1) "c"
2) "b"
127.0.0.1:6379> LRANGE sidekiq_current_processing 0 -1
1) "a"
Với Sidekiq Pro, để đảm bảo tính tin cậy thì thay vì dùng fetch ta có hàm super_fetch sử dụng RPOPLPUSH như cách ở trên.
2.4 Others
Mặc định, sidekiq sử dụng duy nhất một queue là default trong redis. Nếu muốn sử dụng nhiều queue thì chỉ việc định nghĩa thêm queue, và vấn đề tiếp theo là làm thế nào để biết queue nào được ưu tiên xử lý.
Ví dụ ta có 2 queue sau:
sidekiq -q critical,2 -q default
Chỉ số phía sau queue gọi là weight của queue, queue critical sẽ được check/fetch 2 lần so với queue default có weight là 1.
Hoặc nếu muốn xử lý job theo thứ tự khai báo, đơn giản là định nghĩa queue không có trọng số
sidekiq -q critical -q default -q low
=> Nghĩa là job trong default queue chỉ được xử lý khi critical queue rỗng.
Một số vấn đề khác về bao nhiêu queue là đủ, concurrent của sidekiq bao nhiêu là hợp lý có thể tìm thấy trong wiki sidekiq
3 Cần lưu ý
- Ở phía client phải alert trong trường hợp network fail không thể connect tới queue.
- Ở redis queue phải đảm bảo rằng redis luôn availability, ngoài ra cần monitor thêm về số lượng job in queue, nếu số lượng job trong queue vượt ngưỡng nào đó có nghĩa là worker đang bị stuck hoặc số worker không đủ để xử lý đủ lượng job enqueue hoặc tất cả worker đều đang chết.
- Ở Worker cần phải monitor worker sống hay chết, và phải monitor thêm về thời gian xử lý các job, từ đây sẽ biết cách để tăng số worker hay tối ưu lại xử lý.
4 Ref
Tham khảo tại:
All rights reserved
