
ShuffleNet - Deep Network dành cho thiết bị Mobile
Bài đăng này đã không được cập nhật trong 6 năm
1. Lời mở đầu
Trong những năm gần đây, việc ứng dụng các model deep learning sâu hơn, lớn hơn để giải quyết những bài toán trong computer vision ngày càng trở nên phổ biến. Tuy nhiên một số mô hình đạt độ chính xác cao nhưng lại đòi hỏi số lượng tham số lớn, yêu cầu khả năng tính toán nhiều do đó khó ứng dụng trên các thiết bị nhỏ, bị hạn chế về năng lực tính toán như các thiết bị di động. Vậy nên để có thể vẫn duy trì độ chính xác tương đối mà vẫn gọn nhẹ, một số mô hình đã ra đời và được sử dụng khá phổ biến như MobileNetV2, NASNETMobile,... Ngoài những model được đề cập bên trên, hôm nay mình xin giới thiệu model ShuffleNet, một mô hình deep learning khá gọn nhẹ cho mobile dùng cho bài toán phân loại giới tính và tuổi con người.
2. Một số khái niệm cơ bản
Trước khi tìm hiểu về mạng ShuffleNet, chúng ta cần tìm hiểu về một số khái niệm cơ bản về pointwise convolution, grouped convolution, channel shuffle, depthwise separable convolution.
2.1 Pointwise Convolution
 Ảnh 1: Pointwise Convolution
Ảnh 1: Pointwise Convolution
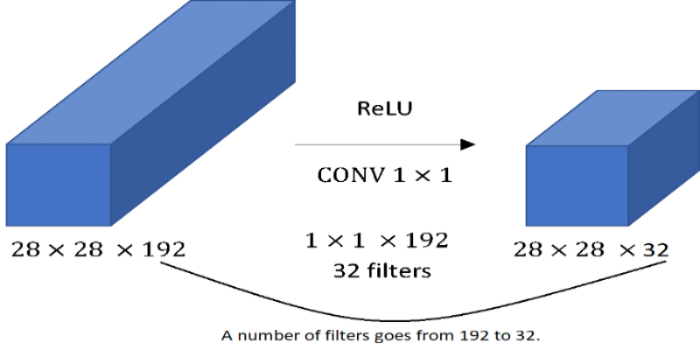
Pointwise convolution hay có cách gọi khác là 1x1 convolution. Khi xây dựng một một mô hình học sâu, một vấn đề chúng ta gặp phải đó là số lượng channel của các features map tăng theo chiều sâu của mạng, điều đó dẫn tới số lượng tham số quá lớn nên dễ overfitting hay độ phức tạp tính toán tăng lên. Một trong các phương pháp tương tự giúp giảm kích thước của feature map là các lớp pooling như max pooling, avg pooling,... giúp chúng ta giảm kích thước chiều rộng (width) và cao (height) của một feature map nhưng vẫn giữ được tính đặc trưng cần có. Tuy nhiên các lớp pooling như vậy lại không thể giúp chúng ta tăng hay giảm số channel nhưng mà với pointwise convolution thì có thể. 
Pointwise convolution là một conv có hai chiều đầu tiên bằng 1, chiều thứ ba có kích thước bằng với số channel ở input.
Một ví dụ để cho bạn dễ hình dung: ta có input là một ma trận có kích thước 28x28x192, ta sẽ có pointwise convolution có kích thước 1x1x192. Ta nhân input với pointwise convolution với số filter chính là số channel ở output mong muốn ở đây là 32, ta sẽ ra được output là ma trận có kích thước 28x28x32. Kích thước chiều rộng và cao không thay đổi, chỉ thay đổi mỗi channel điều này giúp điều khiển kích thước channel theo ý muốn. Thật đơn giản đúng không nào ?
2.2 Grouped Convolution
 Ảnh 2: Grouped Convolution
Ảnh 2: Grouped Convolution
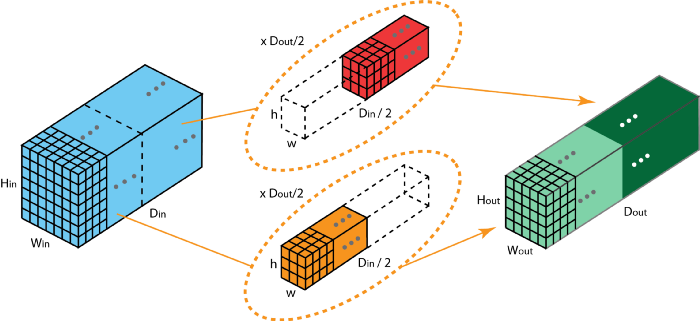
Grouped Convolution có ý tưởng thay vì nhân tích chập với toàn bộ channel như convolution truyền thống thì sẽ chia feature map ra thành nhiều group nhỏ, mỗi group sẽ có số channel cố định, tống số channel các group bằng channel của feature map ban đầu. Sau đó ta thực hiện nhân tích chập với từng group nhỏ, mỗi group sẽ có một kernel riêng, sau đó có một lớp concatenate nối chúng lại với nhau. Nhờ vậy số channel ở output không khác gì với nhân tích chập truyền thống.
Ví dụ ở ảnh 2 ta có Din chính là số channel ở input. Ta chia input ra thành 2 group, mỗi group có số channel là Din / 2. Rồi ta thực hiện nhân tích chập với từng group, ta thu về hai ma trận có kích thước h x w x Dout/2. Sau đó chúng ta sử dụng layer concatenate chồng hai ma trận bên trên lại với nhau, ta sẽ thu được ma trận kết quả có kích thước h x w x Dout. Bạn có thể ý thấy đối với tích chập truyền thống ta cần số lượng tham số là h x w x Din x Dout trong khi đó đối với grouped convolution ta chỉ cần h x w x Din / 2 x Dout / 2 x 2. Số lượng tham số giảm đi một nửa mà kết quả tương đương khiến mô hình trở nên nhẹ nhàng hơn rất nhiều.
2.3 Channel Shuffle cho Grouped Convolution
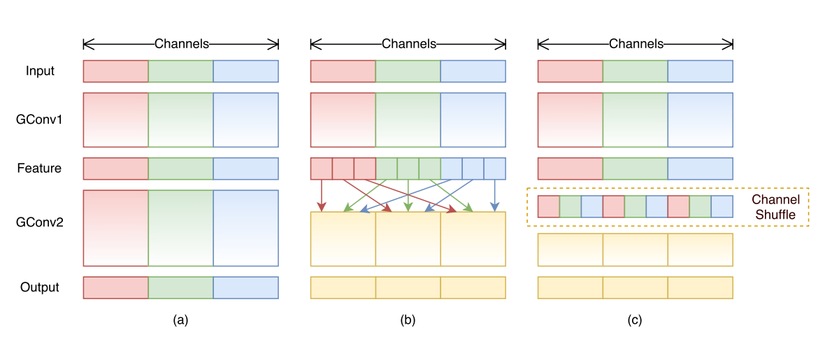
Như phần bên trên giới thiệu, Grouped Convolution cho phép chúng ta thu được kết quả như tích chập truyền thống nhưng giảm đi số lượng tham số trong filters. Tuy nhiên nó lại có một nhược điểm đó chính là một convolution chỉ nhận một đầu vào có channel cố định thay vì toàn bộ channel do đó nó chỉ học được một phần nhỏ của input channel, làm giảm đi hiệu suất. Do đó Channel Shuffle được sinh ra để giải quyết vấn đề này.
 Ảnh 3: Channel Shuffle cho Grouped Convolution
Ảnh 3: Channel Shuffle cho Grouped Convolution
Channel Shuffle giúp cho group convolution có thể nhận đầu vào chứa nhiều dữ liệu ngẫu nhiên từ những group khác nhau nên một group sẽ học được toàn bộ đặc trưng từ input - giải quyết hạn chế của group convolution.
2.4 Depthwise Separable Convolution
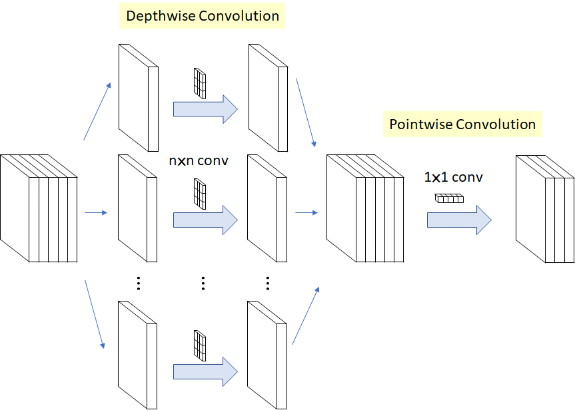
ShuffleNet ngoài việc sử dụng grouped convolution để giảm tham số, bên cạnh đó cũng dùng một dạng convolution khác đó chính là Depthwise Separable Convolution.
 Ảnh 4: Depthwise Separable Convolution
Ảnh 4: Depthwise Separable Convolution
Depthwise Separable Convolution bao gồm hai phần theo thứ tự là:
- Depthwise Convolution:
Depthwise Convolution có ý tưởng tương tự grouped convolution, nhưng khác ở chỗ nó chia features map đầu vào thành các group có số channel cố định bằng 1. Ví dụ ảnh dưới đây, theo conv truyền thống ta có đầu vào có kích thước 7 x 7 x3 nhân với một kernel có kích thước 3 x 3 x 3 sẽ cho output có kích thước 5 x 5 x 3. Depthwise Convolution sẽ chia kernel ra thành 3 kernel nhỏ có kích thước 3 x 3 x1 và nhân tích chập từng kernel nhỏ này tương ứng với 3 group, mỗi group nhỏ có kích thước 7 x 7 x 1 cho ra 3 output có kích thước 5 x 5 x 1. Bạn có thể thấy khi chúng ta chồng ba output đó lên nhau ta sẽ thu được output có kích thước 5 x 5 x 3, giống y hệt cách truyền thống nhưng chúng ta có thể biểu diễn tốt hơn vì sử dụng 3 kernel riêng biệt đồng thời số lượng tham số trong filtes cũng giảm đáng kể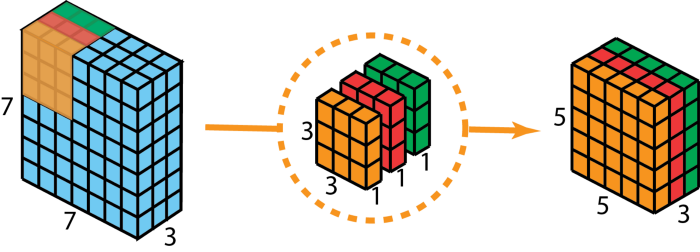 Ảnh 3: Depthwise Separable Convolution
Ảnh 3: Depthwise Separable Convolution
- Pointwise Convolution
Sau khi thực hiện Depthwise Convolution, thì ta nhân tích chập tiếp với Pointwise Convolution có thể tùy chỉnh số lượng channel theo mong muốn. Nếu các bạn chưa nắm rõ về Pointwise Convolution có thể xem lại tại Phần 1 của bài này.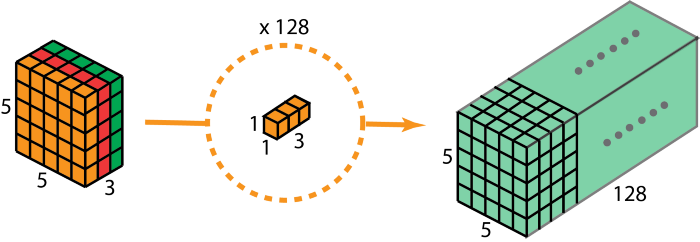 Ảnh 4 : Pointwise Convolution - Step 2 của Depthwise Separable Convolution
Ảnh 4 : Pointwise Convolution - Step 2 của Depthwise Separable Convolution
3. ShuffleNet - Mạng tối ưu dùng cho các thiết bị mobile
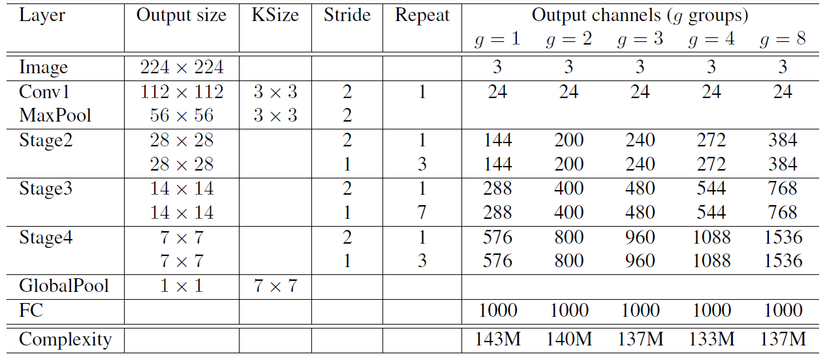 Ảnh 5 : Kiến trúc của mạng ShuffleNet
Ảnh 5 : Kiến trúc của mạng ShuffleNet
Kiến trúc của ShuffleNet tối ưu hơn so với các mạng CNN thông thường nhờ chủ yếu vào 3 stage: Stage2, Stage3, Stage4. Mỗi stage bao gốm nhiều Shuffle Unit được lặp lại số stride khác nhau và số lần khác nhau:
- Stage 2 bao gồm:
- 1 Shuffle Unit có input size: 56 x 56, output size: 28 x 28, ksize: 3 x 3, stride 2
- 3 Shuffle Unit có input size: 56 x 56, output size: 28 x 28, ksize: 3 x 3, stride 1
- Stage 3 bao gồm:
- 1 Shuffle Unit có input size: 28 x 28, output size: 14 x 14, ksize: 3 x 3, stride 2
- 7 Shuffle Unit có input size: 28 x 56, output size: 14 x 14, ksize: 3 x 3, stride 1
- Stage 4 bao gồm:
- 1 Shuffle Unit có input size: 14 x 14, output size: 7 x 7, ksize: 3 x 3, stride 2
- 3 Shuffle Unit có input size: 14 x 14, output size: 7 x 7, ksize: 3 x 3, stride 1
Vậy Shuffle Unit có kiến trúc như thế nào để có thể tối ưu tính toán như vậy ?
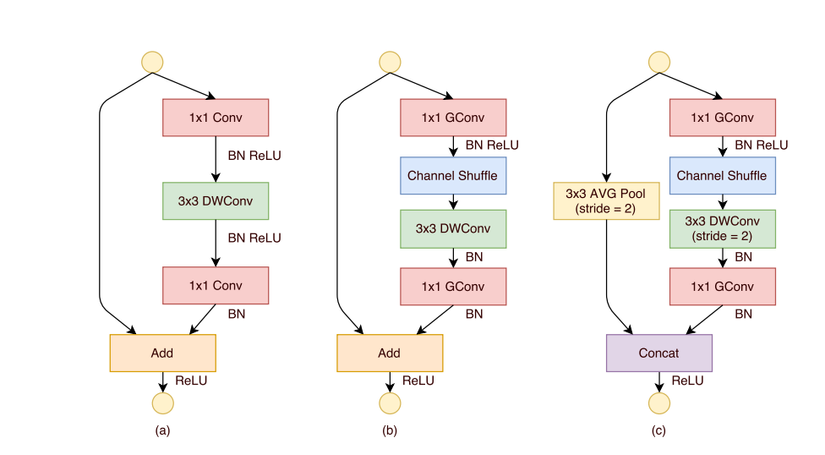 Ảnh 5 : Kiến trúc của Shuffle Unit
Ảnh 5 : Kiến trúc của Shuffle Unit
Ban đầu Shuffle Unit được thiết kế như ảnh 5a, tuy nhiên để làm giảm số lượng tham số của lớp pointwise convolution(1x1 conv), ở hình 5b ta thay thế lớp đó bằng lớp 1x1 Grouped Convolution (1x1 GConv) có ý nghĩa tương đương. Sau đó để hạn chế nhược điểm của grouped convolution(phần này mình đã giải thích ở trên), tác giả đã bổ sung thêm lớp Chanannel Shuffle. Ở lớp 1x1 GConv thứ hai, mục đích là dùng để điều chỉnh lớp số lượng channel phù hợp để dễ dàng cộng với input(lớp Add) nên ta không dùng thêm lớp Channel Shuffle ở đây. Trong trường hợp ta muốn sử dụng thêm stride ở Depthwise Convolution(DWConv) để giảm đi kích thước feature map (ảnh 5c), thì ở shortcut path ta thêm lớp 3x3 AVG Pool để giảm kích thước tương ứng. Và ta thay lớp Add bằng lớp Concat để có thể chồng hai đầu ra của hai nhánh với nhau giúp giữ nguyên kích thước lớp channel so với khi không sử dụng stride.
Trong paper ShuffleNet, để thiết kế mạng tùy theo độ phức tạp của bài toán xử lý, tác giả có dùng một tham số s là scale factor để tăng giảm channel dimension theo ý muốn có dạng "ShuffleNet sx". Ví dụ ta có "ShuffleNet 1x", "ShuffleNet 0.25x", .....
ShuffleNet sử dụng metric là MFLOPS để đánh giá tốc độ của mạng so với các loại mô hình khác :
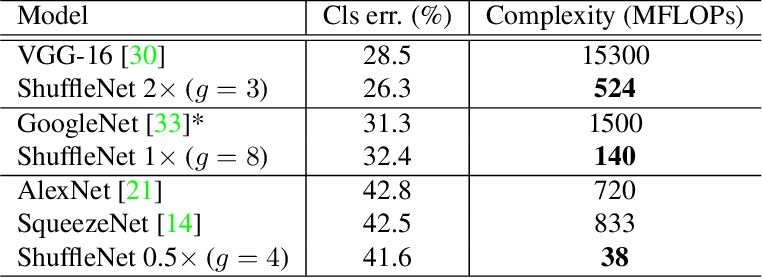 Ảnh 6 : ShuffleNet với các mô hình khác
Ảnh 6 : ShuffleNet với các mô hình khác
Các bạn có thể thấy ShuffleNet nhỏ nhẹ hơn gấp nhiều lần so với các mô hình như VGG-16, GoogleNet trong khi vẫn giữ được thậm chí vượt trội hơn về độ chính xác (Cls err). Tuy nhiên bản thân mình vẫn thấy để đánh giá tốc độ của một mô hình thì metric MFLOPs thôi là chưa đủ vì đó chỉ là yếu tố gián tiếp. Tốc độ của một mô hình khi triển khai thực tế còn tùy vào độ thích ứng với platform cũng như nhiều điều kiện khác nhưng ShuffleNet với kiến trúc grouped convolution và channel shuffle nói đi cũng phải nói lại rất tuyệt vời cho các thiết bị giới hạn năng lực tính toán như mobile.
4. Ứng dụng của ShufflelNet trong giải quyết bài toán phân loại tuổi và giới tính
4.1 Chuẩn bị dữ liệu
Bạn có thể dowload giới và tuổi từ bộ dữ liệu UTKFace. Mình chia tuổi thành 5 class: 1-13, 14-23, 24-39, 40-55, 56-80 và giới tính thành 2 class: male và female. Do mình chọn bộ dữ liệu đã được crop từng khuôn mặt do đó không cần bước này nữa. Nếu như dữ liệu chưa được crop thì để tăng độ chính xác mọi người không nên bỏ qua bước này. Sau đó toàn bộ dữ liệu sẽ được lưu về dạng npy.
Sau đó mình xây dựng một class Data Generator để giúp tiền xử lý dữ liệu như normalize các dữ liệu hay đưa các label về dạng one-hot vector. Ngoài ra việc truyền dữ liệu theo từng batch size vào sẽ giúp dễ dàng train model hơn.
import tensorflow.keras as tk
import config as cf
import os
import numpy as np
class Datasets(object):
def __init__(self, trainable=True):
self.all_data = []
self.convert_data_format(trainable)
self.trainable = trainable
def gen(self):
images = []
age_labels = []
gender_labels = []
while True:
np.random.shuffle(self.all_data)
for i in range(len(self.all_data)):
image, age_label, gender_label = self.all_data[i]
age_label = tk.utils.to_categorical(age_label, num_classes=cf.NUM_AGE_CLASSES)
gender_label = tk.utils.to_categorical(gender_label, num_classes=cf.NUM_GENDER_CLASSES)
images.append(image)
age_labels.append(age_label)
gender_labels.append(gender_label)
if len(images) == cf.BATCH_SIZE:
images = np.array(images) / 255.0
age_labels = np.array(age_labels)
gender_labels = np.array(gender_labels)
yield images, {"age_output": age_labels, "gender_output": gender_labels}
images = []
age_labels = []
gender_labels = []
if len(images):
images = np.array(images) / 255.0
age_labels = np.array(age_labels)
gender_labels = np.array(gender_labels)
yield images, {"age_output": age_labels, "gender_output": gender_labels}
images = []
age_labels = []
gender_labels = []
def convert_data_format(self, trainable):
if trainable:
data = np.load(os.path.join(os.getcwd(), 'data/train_224x224.npy'), allow_pickle=True)
else:
data = np.load(os.path.join(os.getcwd(), 'data/test_224x224.npy'), allow_pickle=True)
self.all_data = data
if trainable:
print('Number of train data data:', str(len(self.all_data)))
else:
print('Number of the test data', str(len(self.all_data)))
4.2 Xây dựng mô hình
Ở đây mình chỉ đưa ra code phần chung còn bạn có thể xem code chi tiết tại github của mình. Do ở bài toán này đầu ra của mình có hai label nên mình xem mạng ShuffleNet như là một mạng backbone dùng để trích xuất đặc trưng của ảnh đầu vào xong đó ở gần cuối sẽ ra thành hai nhánh tương ứng với hai hàm build_age_branch và build_gender_branch thực hiện cùng lúc hai task là phân loại tuổi và phân loại giới tính. Ở đây cả hai hàm loss mình đều dùng "categorical_crossentropy" do hàm phân loại là softmax.
@staticmethod
def build_age_branch(x):
# Output age branch
predictions_age = layers.Dense(cf.NUM_AGE_CLASSES, activation="softmax", name='age_output')(x)
return predictions_age
@staticmethod
def build_gender_branch(x):
# Output gender branch
predictions_gender = layers.Dense(cf.NUM_GENDER_CLASSES, activation="softmax", name='gender_output')(x)
return predictions_gender
def build_model(self, input_img):
x = layers.Conv2D(filters=self.out_channels_in_stage[0], kernel_size=(3, 3), padding='same', use_bias=False,
strides=(2, 2), activation='relu', name='conv1')(input_img)
x = layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same', name='max_pool1')(x)
# create stages containing shuffle-net units beginning at stage 2
for stage in range(len(self.num_shuffle_units)):
repeat = self.num_shuffle_units[stage]
x = _block(x, self.out_channels_in_stage, repeat=repeat, bottleneck_ratio=self.bottleneck_ratio,
groups=self.groups, stage=stage + 2)
if self.pooling == 'avg':
x = layers.GlobalAveragePooling2D(name='global_pool')(x)
elif self.pooling == 'max':
x = layers.GlobalMaxPooling2D(name='global_pool')(x)
# Output layer
predictions_age = self.build_age_branch(x)
predictions_gender = self.build_gender_branch(x)
model = Model(inputs=input_img, outputs=[predictions_age, predictions_gender], name="ShuffleNet")
if self.load_model is not None:
model.load_weights(self.load_model, by_name=True)
return model
4.3 Trainning
Toàn bộ tham số dùng trong quá trình training, mình đều để trong file config. Mọi người có thể vào github của mình để xem cụ thể hơn.
def train(self):
# reduce learning rate
reduce_lr = ReduceLROnPlateau(monitor='val_age_output_acc', factor=0.9, patience=5, verbose=1, )
# Model Checkpoint
cpt_save = ModelCheckpoint('./weight.h5', save_best_only=True, monitor='val_age_output_acc', mode='max', save_weights_only=True)
learn_rates = [0.02, 0.005, 0.001, 0.0005]
lr_scheduler = LearningRateScheduler(lambda epoch: learn_rates[epoch // 30])
print("Training......")
step_val = len(self.test_data.all_data) // cf.BATCH_SIZE
step_train = len(self.train_data.all_data) // cf.BATCH_SIZE // 2
self.model.fit(self.train_data.gen(), batch_size=cf.BATCH_SIZE, steps_per_epoch=step_train,
callbacks=[cpt_save, reduce_lr, lr_scheduler], validation_data=self.test_data.gen(), validation_steps=step_val,
verbose=1, epochs=cf.NUM_EPOCHS, shuffle=True)
4.5 Kết quả
Và đây là một số kết quả demo:
Với mỗi ảnh có kích thước là 224 x 224 x 3, để dự đoán xong một ảnh cả phần import thư viện, detect khuôn mặt từ ảnh, dự đoán phân loại mình chỉ mất tầm 0.7s cho mỗi ảnh. Tương đối nhanh đúng không các bạn ? 
Các bạn có thể thử bằng cách clone git của mình về, thay thế link-to-image bằng đường dẫn tới file ảnh của bạn và chạy câu lệnh:
python demo.py --image_path = link-to-image

Có một số lưu ý rằng bài này mình tạo ra để hiểu rõ hơn về mạng ShuffleNet nên weight mình train hiện tại vẫn chưa được làm tốt lắm(chỉ đạt 60% trên validate age, 95% trên validate gender trong tống số hơn 5k ảnh ), các bạn có thể clone về và cải tiến theo cách của mình. Cảm ơn các bạn đã theo dõi bài đọc này.
References
All rights reserved
