Serving ML Models in Production with FastAPI and Celery
Bài đăng này đã không được cập nhật trong 2 năm
English version can be read at Eng-ver
Overview
Bài này nói về cách triển khai Machine Learning trong dự án thực tế . Một ví dụ để deploy Machine Learning model bằng cách sử dụng Celery và FastAPI. Tất cả mã có thể được tìm thấy trong kho lưu trữ ở đây. Github
Trong bài này sử dụng model object-detection được train bằng Tensorflow dựa trên bộ dữ liệu Coco Dataset. Nói chung là nó là mô hình nhận dạng đối tượng có khoảng 80 class như chó, mèo, chim (bird), gà, vịt heo ... Hướng dẩn train model không được đề cập trong bài viết này nhé.
Asynchronous
Mục tiêu là xây dựng service không đồng bộ: thay vì trực tiếp trả về một dự đoán (Client gọi tới ML Service và đợi đến khi service trả lại kết quả) thì ML Service sẽ trả về một định danh duy nhất (task_id) cho một nhiệm vụ. Trong khi nhiệm vụ dự đoán đang được hoàn thành bởi ML Service (Worker Node), Client có thể tự do tiếp tục xử lý các tác vụ khác ví dụ gửi tiếp một yêu cầu dự đoán khác. Các bước dưới đây mô tả các hành động được thực hiện để xử lý một dự đoán (hình nguồn internet):
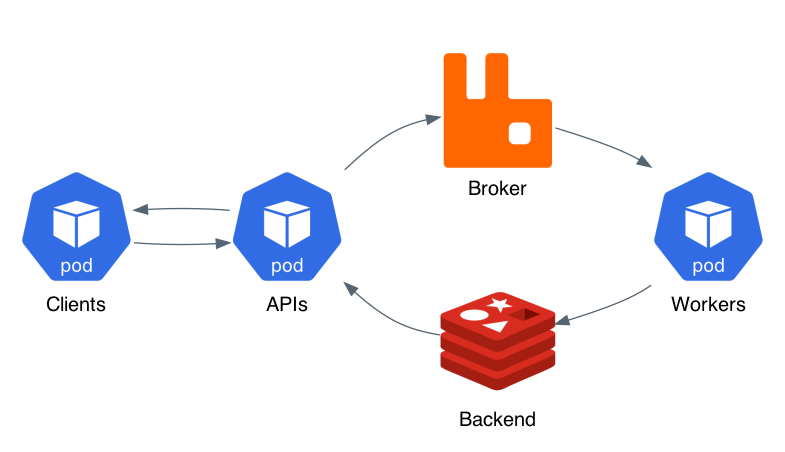
- Ứng dụng khách gửi yêu cầu POST tới FastAPI endpoint, tuỳ thuộc yêu cầu mà gửi đến API service nội dung khác nhau trong trường hợp này là upload lên một hình ảnh cần dự đoán.
- FastAPI xác thực thông tin và lưu hình vào kho lưu trữ (vd: Nas, HDFS ...). Nếu xác thực thành công thì tác vụ dự đoán sẽ được tạo và chuyển đến Broker - Message queue (ví dụ: RabbitMQ).
- Đồng thời API service cũng tạo một task_id duy nhất và trả về client nếu tạo tác vụ Celery thành công.
- Nhiệm vụ dự đoán được Broker giao cho một trong những Worker Node (ở đây bạn có thể có nhiều worker node). Sau khi được phân phối nhiệm vụ, worker sẽ tạo ra một dự đoán bằng cách sử dụng mô hình ML được đào tạo trước đó.
- Khi một dự đoán đã được tạo, kết quả sẽ được lưu trữ vào Celery backend (ví dụ: Redis).
- Tại bất kỳ thời điểm nào sau bước 3, Client có thể bắt đầu kiểm tra kết quả từ endpoint FastAPI khác bằng cách sử dụng task_id duy nhất nhận từ API service trước đó. Sau khi dự đoán sẵn sàng, nó sẽ được trả lại cho Client.
Bắt tay vào làm thoi!
Mình lại tiếp tục sử dụng Docker để phát triển ứng dụng này nhé.
Đầu tiên tiến hành sao chép repo về:
git clone https://github.com/dnguyenngoc/ml-models-in-production.git
cd ml-models-in-production
Cấu trúc của dự án gồm:
├── ml-api -> Chứa code của FastAPI service config tại ml-api/app/environment.env
├── ml-celery -> Chứa code của Celery Worker service config tại ml-celery/app/environment.env
├── ml-client -> Chứa code của Client
├── ml-storages -> Tạo một share storages chứa file upload và file object-detection result
├── upload
├── object-detection
├── docker-compose.yaml -> run service bằng cái này!!!
...
Tiếp theo, chúng ta cần build toàn bộ service với docker-compose:
docker-compose build && docker-compose up
Vì xây dựng hình ảnh từ đầu, nên việc này có thể mất một lúc. Sau khi thực hiện lệnh docker-compose up, các dịch vụ sẽ khởi động. Có thể mất một khoảng thời gian trước khi mọi thứ bắt đầu và chạy.
| Service | URL | User/Password |
|---|---|---|
| Client | http://localhost | ml_user/CBSy3NaBMxLF |
| API | http://localhost/api/docs | None |
Cuối cùng là login vào http://localhost với user "ml_user" và pass "CBSy3NaBMxLF" chọn file bạn cần dự đoán và xem thành quả.

Lưu ý là hình ảnh đầu tiên dự đoán sẻ mất một khoảng thời gian vì Celery cần thời gian để load ML model vào bộ nhớ. Từ hình ảnh thứ 2 trở đi dịch vụ chạy khá nhanh.
Đây chỉ là một ví dụ tham khảo về cách tiếp cận để triển khai một mô hình ML. Trong thực tế đòi hỏi nhiều thứ hơn. Hi vọng bài viết này có thể giúp các bạn một điều gì đó. Chào thân ái và quyết thắng ...
All rights reserved
