Server monitoring với combo thần thánh Grafana, Prometheus, Cavisor, Node-exporter và Docker
Bài đăng này đã không được cập nhật trong 3 năm
Nếu bạn đang ở một level trung trung và đang bắt đầu tập tành chạy các app của mình trên vps/server thì với số lượng nhỏ nhỏ có thể chưa có vấn đề gì. Tuy nhiên khi số lượng lớn có thể là chạy nhiều app hoặc nhiều container thì server sẽ bắt đầu có những hiện tượng quá tải về tài nguyên(cpu, ram, storage, network,…). Thường thì ta sẽ ước chừng thủ công với lưu lượng sử dụng của từng app hoặc tính toán xem app nào đang đông người dùng để có biện pháp(nâng cấp server hay gắn load balance).
Tuy nhiên việc theo dõi hay ước tính những dữ liệu về cpu, ram,… thủ công như vậy khá tốn thời gian và không trực quan trong dài hạn. Và tada sau một thời gian vọc vạch thì mình đã tìm ra được một bộ combo thần thánh giúp chúng ta thực hiện được việc theo dõi các chỉ số của vps/server rất chi tiết và view thì phải gọi là bá đạo.
Ví dụ về "Server monitoring các chỉ số cơ bản"
 Ví dụ về "Docker container monitor"
Ví dụ về "Docker container monitor"
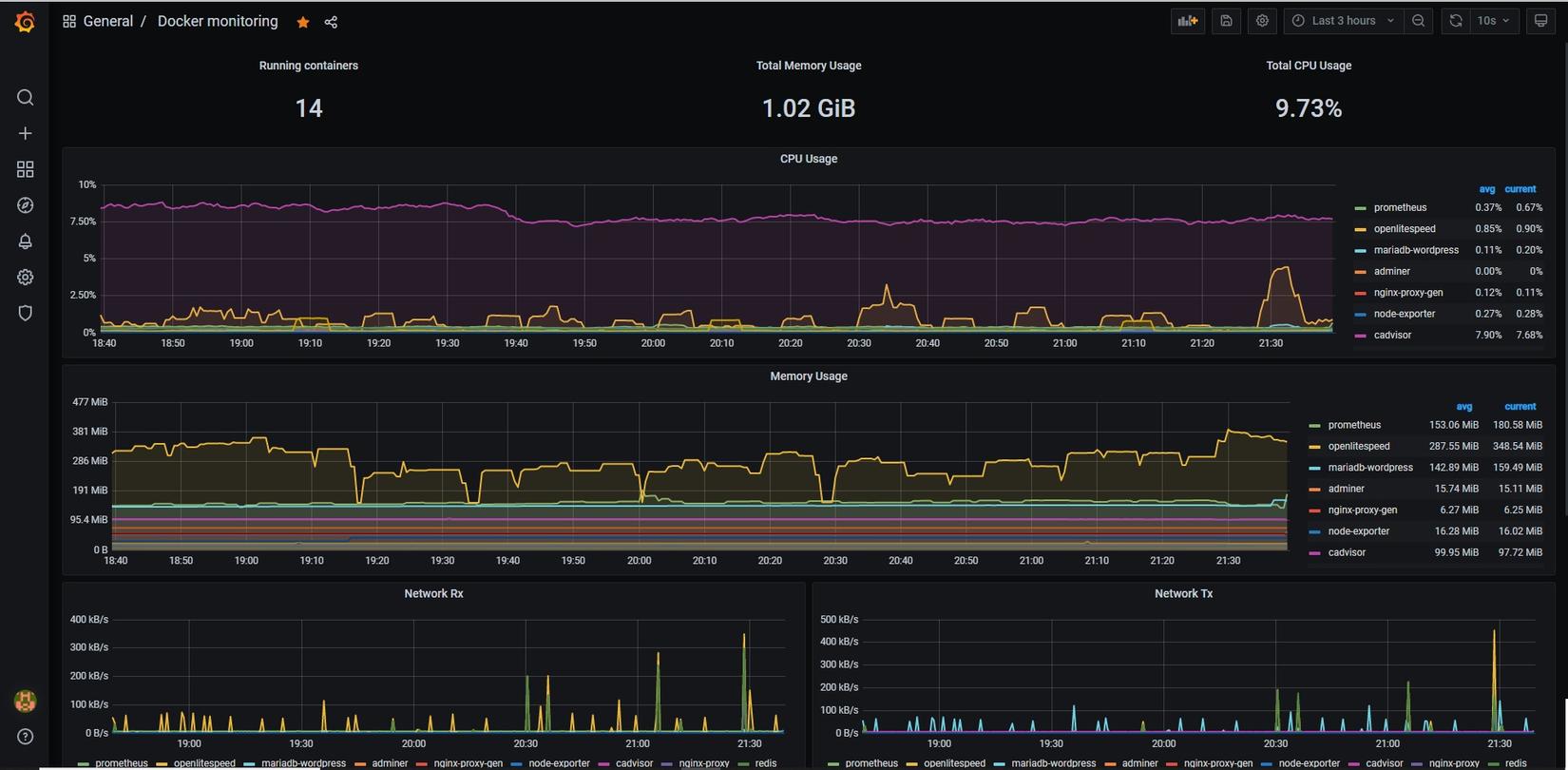
Vâng nhìn quả giao diện trên thì ít ai biết rằng chúng đều miễn phí và cấu hình cũng không phải là quá khó khăn với Docker(đến đây lại thấy yêu Docker hơn 😛 ). Và sau đây chính là các thành phần trong hệ thống server monitoring của chúng ta, xin được phép giới thiệu:
- Node-exporter: Đây là một exporter chạy được viết trên Golang(Exporter tạm hiểu là các service có khả năng thu thập/xuất ra các thông số của server/vps).
- CAdvisor: Ở trên node-exporter thì xuất ra các thông số của server/vps nhưng mình muốn theo dõi thêm các thông số của các container đang chạy trong hệ thống thì sử dụng thằng CAdvisor(Cũng là một exporter) này cực ngon mà lại còn là hàng của google nữa.
- Prometheus: Có chức năng thu thập data từ các exporter(VD: Node-exporter, CAdvisor, Mongodb, InfluxDB,…) dưới dạng metric theo từng interval(Ví dụ cứ 5s thì pull data từ 1 exporter bất kỳ) sau đó gắn các metric với thời gian hiện tại và đưa vào database để lưu trữ ở dạng time series. Ngoài ra prometheus còn có chức năng cảnh báo khi đạt ngưỡng(Ví dụ: Khi ram sử dụng quá 50% thì gửi cảnh báo cho chúng ta qua các kênh như STMP) nhưng trong bài viết này mình sẽ tập trung vào phần chính và các bạn có thể thử nghiên cứu thêm.
- Grafana: Sau khi kết hợp các exporter và prometheus thì cơ bản là có thể monitor server rồi tuy nhiên giao diện khá cùi và thiếu trực quan. Vậy nên chúng sẽ kết hợp prometheus với grafana để hiển thị dữ liệu. Về cơ bản thằng grafana này có khả năng hiển thị mọi loại dữ liệu ở dạng time series rất tối ưu và đa dạng nguồn dữ liệu.
Bỏ qua mấy phần chém gió tốn thời gian ở trên, cùng thực hành luôn cho nóng 😆
- Đầu tiên ta cần tạo file prometheus.yml để cấu hình scrape.
global:
scrape_interval: 20s
scrape_timeout: 15s
scrape_configs:
- job_name: cadvisor
static_configs:
- targets:
- cadvisor:8080
- job_name: node_exporter
static_configs:
- targets:
- node-exporter:9100
- global mình sẽ cấu hình scrape_interval: 20s(tương ứng cứ 20s sẽ gọi tới các job và lấy data 1 lần)và timeout_interval: 25s(nghĩa là sau 25s mà không lấy được dữ liệu từ exporter thì sẽ timeout). Config ở global sẽ được apply vào toàn bộ các job.
- job_name đặt theo ý của bạn nhưng nên đặt theo tên exporter để dễ quản lý.
- static_configs => targets => cadvisor:8080 ở dòng này là config exporter mà scrape sẽ pull data về. cadvisor:8080 là do mình chạy cadvisor trên docker-compose nên cadvisor sẽ tương ứng với host giả sử cadvisor chạy trên ip 172.10.0.12 thì cadvisor:8080 <=> 172.10.0.12:8080. Các bạn tìm hiểu thêm về phần networking trong docker nhé. Lưu ý: cadvisor chạy mặc định ở port 8080 và node-exporter chạy mặc định ở port 9100.
- Tiếp theo thực hiện config file docker-compose.yml với nội dung như sau:
version: "3"
services:
cadvisor:
image: gcr.io/cadvisor/cadvisor:v0.39.0
container_name: cadvisor
restart: always
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
node-exporter:
image: prom/node-exporter:v1.1.2
container_name: node-exporter
restart: always
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- "--path.procfs=/host/proc"
- "--path.sysfs=/host/sys"
- "--path.rootfs=/rootfs"
- "--collector.filesystem.ignored-mount-points='^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)'"
prometheus:
image: prom/prometheus:v2.26.0
container_name: prometheus
restart: always
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
depends_on:
- cadvisor
grafana:
image: grafana/grafana:7.5.3-ubuntu
container_name: grafana
restart: always
ports:
- 3000:3000
depends_on:
- prometheus
- Mở cmd và run
docker-compose up -d
- Truy cập [ip của vps]:3000 ví dụ vps mình là: 132.123.1x.xx:3000 sẽ thấy xuất hiện trang login của grafana như sau.
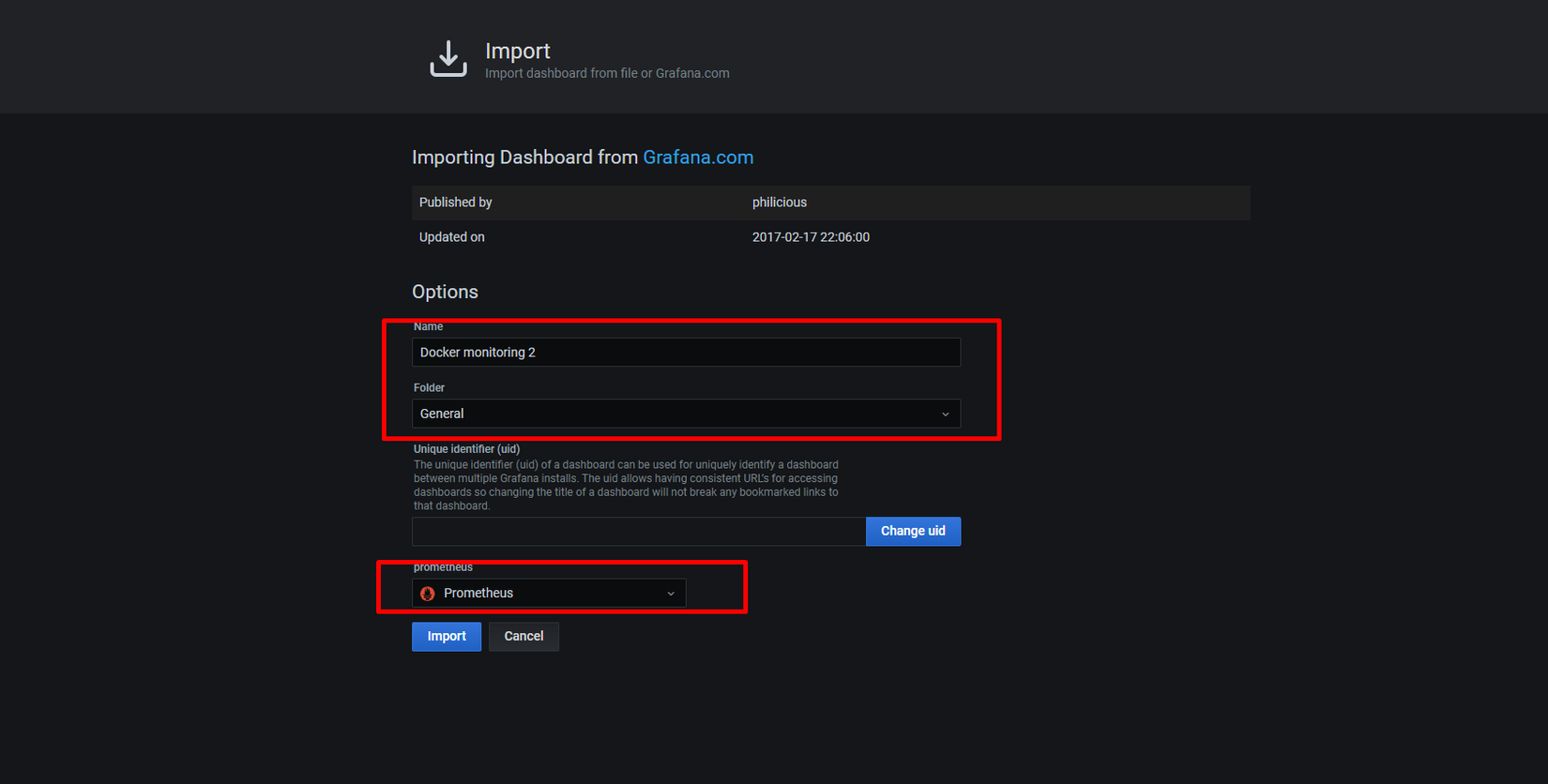
![]() Mật khẩu và tài khoản mặc định là admin:admin sau khi đăng nhập ta chọn Dashboard => Manage => Import chọn import via grafana.com điền id dashboard là 1860(node-exporter) và 193(cadvisor) sau đó click Load và điền name, folder, datasource prometheus như sau.
Lưu ý với mỗi dashboard ta thực hiện import riêng 1 lần.
Mật khẩu và tài khoản mặc định là admin:admin sau khi đăng nhập ta chọn Dashboard => Manage => Import chọn import via grafana.com điền id dashboard là 1860(node-exporter) và 193(cadvisor) sau đó click Load và điền name, folder, datasource prometheus như sau.
Lưu ý với mỗi dashboard ta thực hiện import riêng 1 lần.
![]() Click import và tada đây là kết quả.
Click import và tada đây là kết quả.
![]()
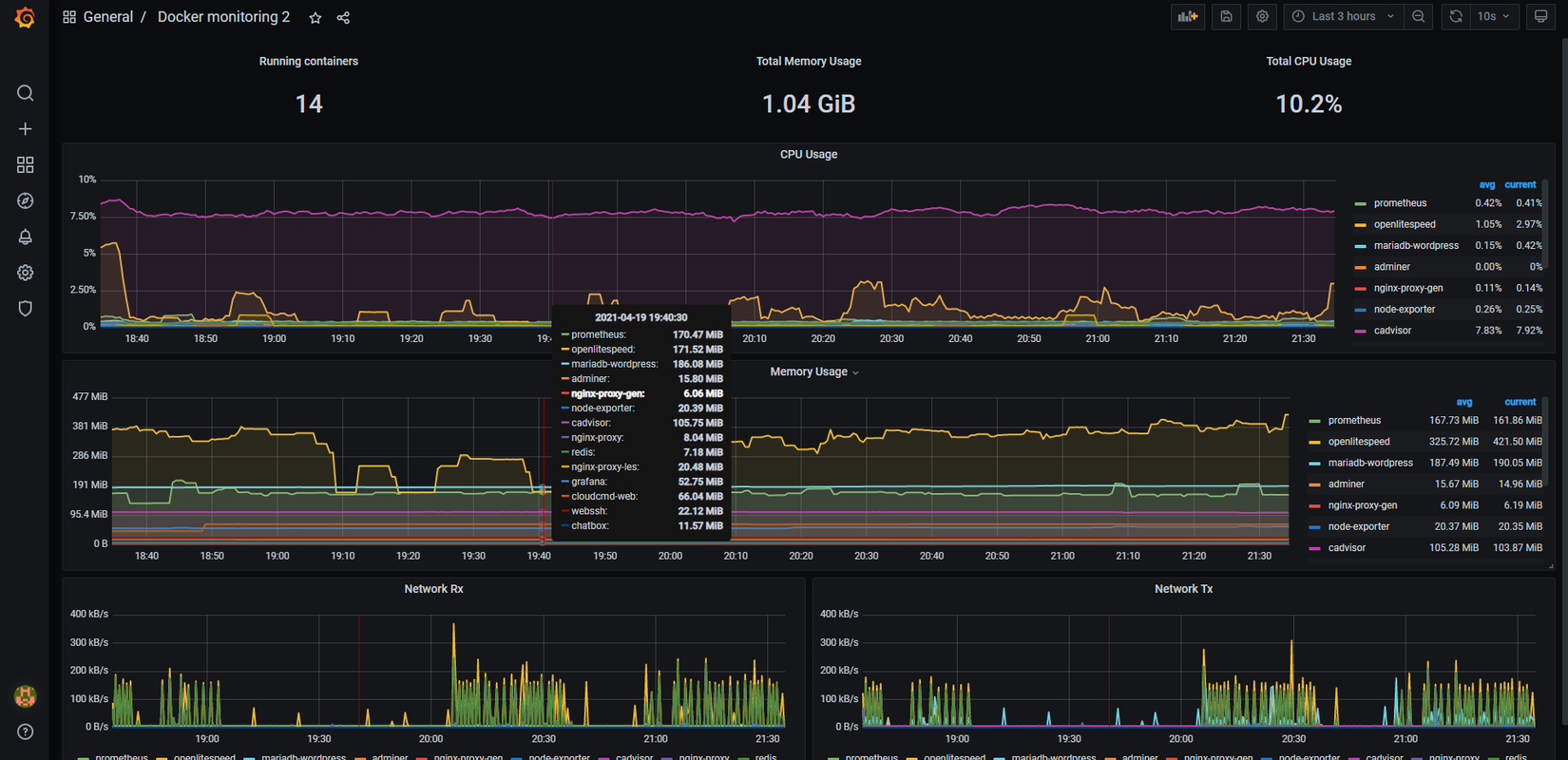
Trông cũng ra gì và này nọ nhể =)). Việc import dashboard được tạo sẵn và được đăng trên grafana nhằm rút ngắn thời gian thiết kế. Tất nhiên các bạn có thể tự thiết kế dashboard với các metrics nhé. Sau khi import xong 2 dash board cho containers(cadvisor) và host(node-exporter) thì bấm save lại để sử dụng sau này.
Qua bài viết này thì chúng ta đã cấu hình được 1 hệ thống monitoring server khá đơn giản và trực quan. Nếu trước đây có thể mất tới hằng tuần thậm chí hàng tháng để làm việc này thì giờ chỉ gói gọn trong khoảng 30p. Quá ngon đi =)). Các bạn có thể phát triển các tính năng cho hệ thống monitoring server trên bằng cách thêm cảnh báo khi vượt ngưỡng, chỉnh sửa lại dashboard hay thậm chí là cấu hình 1 con monitoring server để monitor các server/vps khác trong cùng hệ thống.
Hãy cùng đón chờ "Docker log monitor with Loki, Fluent bit" để hoàn thiện combo tracking của chúng ta nhé  ))
))
All rights reserved
