
Self-training with noisy students
Bài đăng này đã không được cập nhật trong 5 năm
1. Review lại các khái niệm learning cơ bản
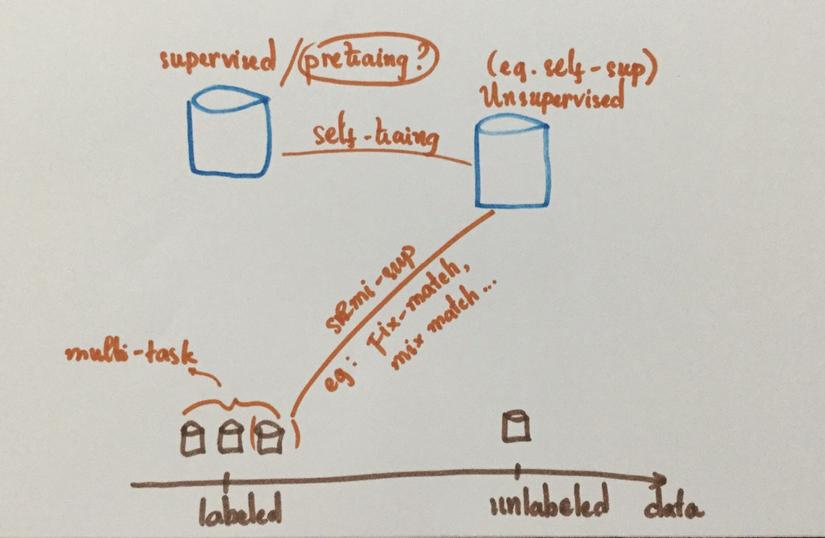
- Supervised learning: data set đều gồm labeled data points . Các bài quen thuộc trong dạng này như classification hay object detection. Nếu ở* high dimentions* và continous (như ảnh) hay discrete (như text), lượng data cần cho các bài toán này sẽ là rất lớn, manual labling sẽ trở thành vẫn đề nhất là với những domain cần label bởi expert (như medical domain).
- Unsupervised learning : unlabeled, chỉ bao gồm . Các method quen thuộc như clustering, autoencoder được sử dụng để learn representation của distribution mà không cần dùng đến labels. Lượng raw data in the world là rất nhiều, còn lượng labeled data chỉ chiếm một phần rất nhỏ, và dạng learning tận dụng lượng raw data đó.
- Semi supervised learning: Gồm cả labeled lẫn unlabeled data. Self-learning là một nhánh của semi supervised learning, nhưng ở hiện tại self-learning cần một vài điều kiện để hoạt động, đấy là labeled data cũng phải nhiều.
Và noisy student là một phương pháp thuộc self-learning. Teacher-student model không phải là phương pháp mới trong semi-supervised learning. Nó có rất nhiều variants được biết đến nhiều qua models về knowlegde distillation. Self-training with Noisy Student improves ImageNet classification sử dụng teacher-student model với data set gồm nhiều unlabeled lẫn labeled data, cộng vói rất nhiều technical factors khác, thành công traning model cho task image classification trên Imagenet, vượt qua state of the art khi đó đến hơn 2% test accuracy.
Trong bài này, tôi muốn discuss về những điểm hay của model này và nó có thể được sử dụng, traning như thế nào.
** Note: nãy giờ tôi vẫn overused tính từ “ít, nhiều”. Vậy ít nhiều ở đây là mức bao nhiêu thì phụ thuộc vào rất nhiều yếu tố và cần nhiều experiments để kiểm chứng.
2. Noisy student training explain
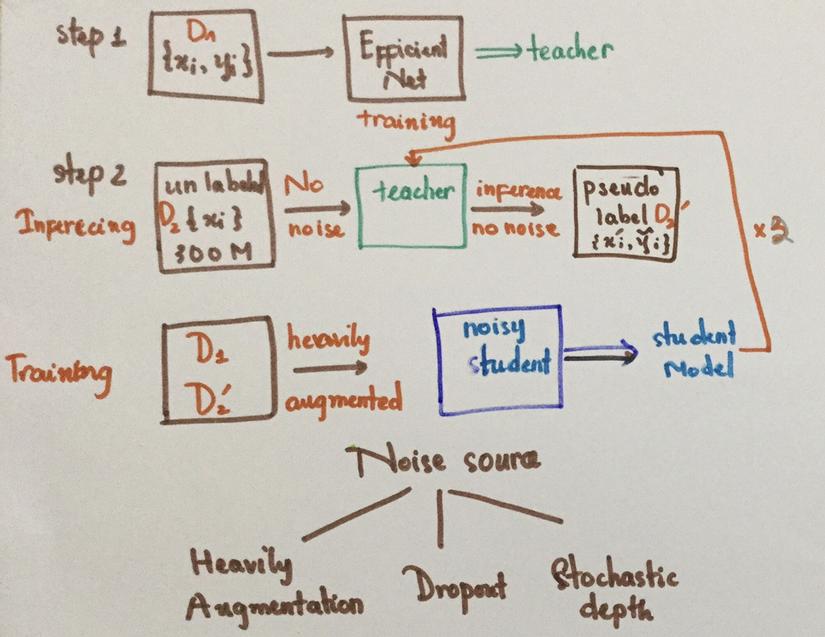
Set up:
-
2 dataset: labeled(D) và unlabeled(UD), cả hai đều redundant, như trong paper thì labeled dataset là ImageNet còn unlabeled là JFT-300M.
-
Model: teacher : paper chọn teacher lần lượt là EfficientNet từ B0-B7. Các student tương ứng sẽ lớn hơn hoặc bằng về size với teacher.
-
Noise: Data augmentation, Dropout, Stochastic depth (như drop out nhưng thay vì drop randomly activation units thì sẽ drop randomly entire layer)
Training:
-
Đầu tiên, teacher model sẽ được train để classify images trong labeled data (D) . Lúc này, teacher cũng sẽ được inject noise (noisy training).
-
Sau đó, teacher model sẽ được dùng để deterministically (without noise) infer labels cho UD. Pseudo labels này có thể ở dạng hard (one-hot) hoặc soft (output of softmax activation).
-
Bây giờ, cả labeled và unlabeled dataset sẽ được dùng để jointly train student model with noise (noisy training). Hàm loss vẫn sẽ là cross-entropy nhưng data sẽ được over-sampling (chances để sample data thuộc D ít hơn thuộc UD) để train student model với nhiều data thuộc UD hơn.
-
Sau đó student model lại trở thành deterministic teacher và quá trinhg training lại diễn ra như vậy thêm 2 lần nữa (Iteration)
3. Tại sao training như vậy lại hoạt động
Không chỉ tăng accuracy trên ImageNet tới 2% so với state of the art lúc đó, mà quá trình trraining như vậy còn làm tăng tính robustness của model, achieve significant gain in accuracy và low error rate trên các tập ImageNet-A, ImageNet-C, ImageNet-P
Paper có đưa ra một số giải thích như sau:
Noise góp phần rất lớn vào sự thành công đó của model. Khi train teacher với noise, noise trong data khiến teacher trở nên robust hơn với several pertubation của data. Còn noise trong model giúp teacher, trong inference, khi ngắt noise đi, sẽ trở thành một ensembled model . Còn khi training noisy students, students không chỉ phải trở nên robust hơn với small pertubation của input mà học tốt được knowlegde của một ensembled model là teacher model.
Đến đoạn này chắc các bạn sẽ hỏi: peusdo labels là do teacher model infer mà ra, student model được train trên D và UD, thì làm sao student model có thể làm tốt hơn teacher model, đâu có objective nào là student model phải làm tốt hơn teacher model đâu? Và nếu teacher model cũng mess up (predict không tốt UD), thì student model cũng sẽ mess up thì sao?
Và thực sự khi đọc paper tôi cũng không biết thành công của quá trình training này đến từ đâu. Vì cần nhiều yếu tố để nó hoạt động tốt và không phải với set up nào áp dụng noisy student cũng thành công. Nhưng sau nhiều experiments thì paper có chỉ ra rằng, thành công của họ phần nhiều nằm ở heavy noise injecting và large student model. Và tất nhiên phải có good teacher model nữa, không có thầy giỏi thì thật khó để có trò hay.
Như tôi vừa nói trên, large student model giúp student trở nên flexible hơn, nhiều learning capacity hơn để learn better than the teacher. Với experiments họ cũng chỉ ra rằng, bigger students achieve significant gain in performace then same-size-as-teacher student. Tuy nhiên, trong đoạn này có điều tôi không hiểu. Nếu student lớn hơn về size so với teacher và nếu student cùng family function với teacher thì chỉ cần copy teacher model là được. Nhưng có lẽ, lớn hơn về size sẽ đồng thời lớn hơn về lượng noise inject trong model, làm student model trở nên noisy hơn, khó học hơn. Chính vì thể để học được teacher, nó buộc phải làm tốt hơn teacher. Nếu các có cách giải thích hợp lý hơn và có cả cách chứng minh nữa thì tôi rất mong được lắng nghe.
Teacher-student model không phải model mới nhưng chưa quá trình training nào trước đó thành công như paper này cả. Có rất nhiều yếu tố khác biệt giúp model này hoạt động nhưng điểm lớn nhất đó chính là noise injection.
4. Những yếu tố nào khác giúp training process này hoạt động
Có nhiều yếu tố kết hợp dẫn đến sự thành công của paper, điều này càng khiến khó khăn hơn trong việc xác định cái nào thực sự hoạt động. Dù vậy, self-learning cũng là một phương pháp rất khó bỏ qua nếu bạn dư thừa của cải, cả labeled lẫn unlabled data. Vậy nên biết được các yếu tố giúp training thành công cũng rất quan trọng. Các yếu tố này được paper’s author study một cách khá cẩn thận, tôi recommend bạn nên dành thời gian đọc kỹ paper và cả Rethinking Pre-training and Self-training nếu muốn dùng nó.
Các yếu tố này là:
-
Teacher phải large và được train cẩn thận. (understandable, better teacher có nhiều chance để có better students)
-
Lượng unlabeled data phải nhiều. Nghe thì có vẻ obvious vì cần nhiều data mới cho student còn học, nhưng điều này lại khá confused với tôi. Unlabled data ơi đây có lẽ cũng cần phải dùng distribution với labeled data đúng không? nếu không thì khi teacher model không generalize tốt với out of distribution data, student sẽ fail. Và teamate của tôi cũng cho tôi gợi ý rằng nếu teacher model không robust, có thể be confident ngay cả khi nó sai thì sao?
-
Tiếp theo là soft pseudo labels sẽ hoạt động tốt hơn là hard pseudo labels. Điều này được observe bởi experiments chứ không có hypothesis nào để giải thích cả, và sự “tốt hơn” ở đây cũng rất subtle. Nếu để soft pseudo labels không phải sẽ encourage student học đúng những gì teacher biết hay sao? Liệu có tốt hơn nếu chuyển thành hard labels rồi dùng label smoothing?
-
Ngoài việc teacher có thể rất confident trong việc đóan sai, thì student làm sao học tốt được nếu teacher is indecisive (return same predicted probability cho các class)? Để giải quyết vấn đề này, trong lúc tạo pseudo labels, mọi data points mà teacher model không tự tin để predict thì sẽ bị discard (data filtering).
-
Jointly training tốt hơn là seperately training : train student model trên cả D và UD cùng một lúc. Ngoài ra có thể weighting loss value của data point đến từ D và UD bởi Nhưng có thể đơn giản hóa điều này bằng cách tạo sample rate khác nhau cho Dataloader : data point thuộc D sẽ được sample bằng một rate khác so với datapoints thuộc UD. Paper suggest để sampling ratio giữa UD và D càng cao (khoảng 3) càng tốt vì student model có thể được train trên tập UD nhiều hơn. Heuristically, teacher ban đầu chỉ được train trên D, như vậy student phải tận dụng được tối đa extra infomation từ UD để làm tốt hơn teacher.
-
Paper cũng suggest train student from scratch mà không dùng teacher model là pretrain thì sẽ tốt hơn là dùng teacher làm pretrain. Sự "tốt hơn" rất subtle và tốn nhiều epochs để thấy được. Tôi vẫn nghĩ rằng nên dùng pretrain để có warm start vì nó không có nhiều sự khác biệt đến thế, oppotunity cost vẫn là lớn nhất là khi không có nhiều nguồn lực về thiết bị.
5. Khi nào nên dùng self-training noisy student model?
Thành công của noisy student model:
-
Achieve best accuracy trên tập ImageNet vào thời điểm paper được published.
-
Nhưng theo tôi, thành công lớn nhất của paper là train được một model robust, tăng very significant performace trên các dataset mà chứa difficult images, common corruption và perburbations (ImageNet A, C, P) và đặc biệt là trên adversarial perturbations.
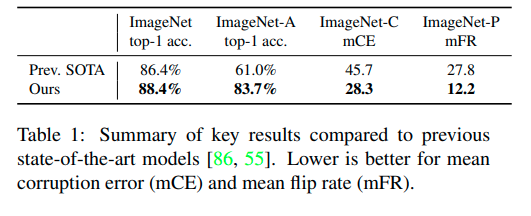
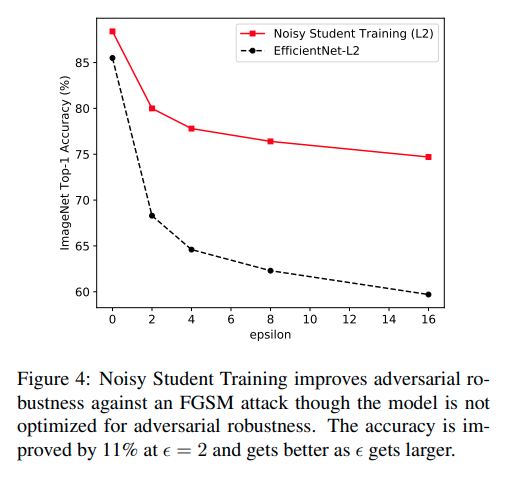
Source: Self-training with Noisy Student improves ImageNet classification
Điều này cũng có nghĩa là các features mà model học được là robust hơn, nhưng liệu có meaningful hơn so với các model khác? Như vậy , liệu self-noisy student model có giúp nhiều trong pretrain không và giúp khi nào ? Có quá nhiều factor có và unknows để biết được điều này và cách tốt nhất mà tôi biết là ta bỏ thời gian ra để thử.
Nhưng Rethinking Pre-training and Self-training sheds some lights cho thắc mắc này. Paper chỉ ra rằng, pretrain với model robust và lớn như noisy student sẽ cho kết quả tốt hơn các model khác cùng train trên tập ImageNet khi data của downstream task là ít. Và khi data càng nhiều lên thì sự khác biệt về performace này càng rút ngắn và hơn hết, các pretrain model thường thua model training from total scratch khi data is abundant và training với heavy augmentation. Ngoài ra pretraining sẽ thua training from scratch nhiều nhất khi distribution của pretraining khác với downstream task (kết hợp với cả 2 yếu tố trên )
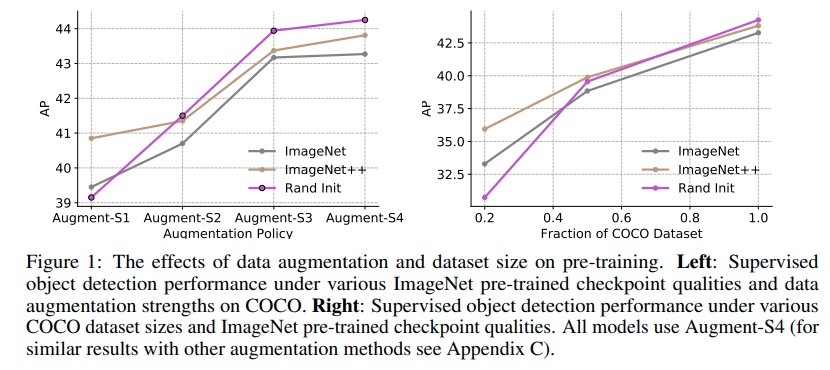
Source : Rethinking Pre-training and Self-training
Nhưng khi data is abundant và dùng nhiều augmentation, self-training process itself, không phải pretraining, với noisy students sẽ giúp. Paper hypothesize rằng điều này là do khả năng adapt new domain của self-training tốt hơn nhiều pretraining.
6. Conclusion
** Đây đều là ý kiến chủ quan của tôi, mong bạn đọc cân nhắc kỹ trong lúc đọc
-
Teacher-student model không phải là idea mới, nhưng để tạo nên sự thành công của paper thì gồm rất nhiều yếu tố, trong đó noise đóng góp một phần rất quan trọng
-
Sử dụng model này cho pretrain cần tùy thuộc vào nhiều yếu tố, và cả dùng cho self-learning cũng vậy. Nhưng đây là một phương pháp nay, ai "nhà giàu" (về cả data lẫn training resource) nên cân nhắc sử dụng, vì nó có kết quả rất promising so với pretraining, nhất là cho domain adaptation.
Reference
Self-training with Noisy Student improves ImageNet classification: https://arxiv.org/pdf/1911.04252.pdf
Rethinking Pre-training and Self-training: https://arxiv.org/pdf/2006.06882.pdf
ImageNet A, C, P : https://arxiv.org/pdf/1903.12261.pdf
All rights reserved
