Self-Attention và Multi-head Sefl-Attention trong Transformers
Transformers là gì? Liệu nó có gì đặc biệt mà trong machine learning người ta nhắc đến nó nhiều như thế? Trước thời điểm Google giới thiệu bài báo nổi tiếng Attention Is All You Need thì transformers là "Người máy biến hình" là "Máy biến áp". Sau khi bài báo được công bố thì transformers lại trở thành một trong những kiến trúc nổi bật trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) và xử lý ảnh. Với khả năng xử lý song song và nắm bắt các mối quan hệ phức tạp giữa các từ trong câu, transformers đã giải quyết các hạn chế của mạng RNN và các biến thể (LSTM, GRU...). Xương sống của kiến trúc này chính là cơ chế self-attention giúp mô hình tập trung vào các thông tin quan trọng, hiệu quả hơn trong việc hiểu ngữ cảnh của từng từ trong câu và cho phép các transformers có bộ nhớ cực kỳ dài hạn. Có thể ví transformers như là 1 hộp đen, trong một ứng dụng dịch máy, nó sẽ "ngậm" vào một câu trong một ngôn ngữ và "thổi" ra bản dịch của nó trong một ngôn ngữ khác.
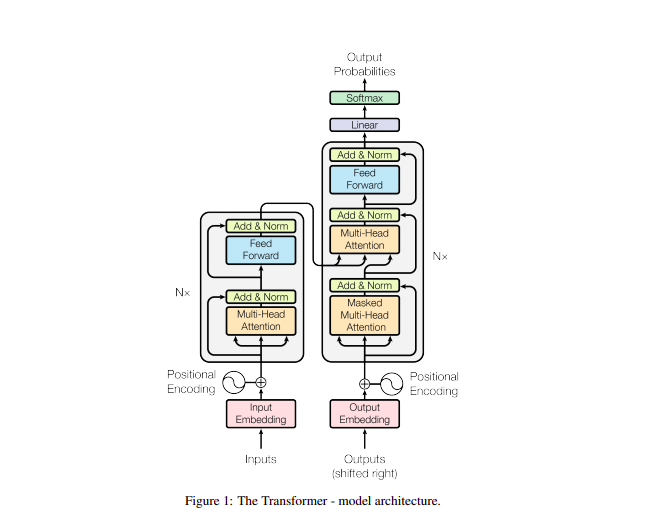
1. Self-Attention là gì?
Như chúng ta đã biết, Word Embedding là vector đại diện cho ngữ nghĩa của một từ trong câu. Trong bước tiền xử lý, chúng ta đã tạo ra một không gian vector chứa các vector embedding của các từ. Những từ có nghĩa tương tự nhau sẽ có vector ở gần nhau trong không gian đó và ngược lại. Tuy nhiên, ý nghĩa của các từ riêng lẻ trong một câu không thể đại diện cho toàn bộ ý nghĩa của câu đó. Chẳng hạn, trong câu "The apple on the table", từ "apple" trong ngữ cảnh này được hiểu là quả "táo" . Nhưng nếu đặt trong một ngữ cảnh khác, như trong câu "The Apple keynote was interesting", từ "Apple" có thể ám chỉ đến công ty công nghệ.
Cơ chế Self-Attention được đề xuất trong bài báo Attention Is All You Need có thể giải quyết tốt vấn đề này. Ý tưởng của nó là so sánh các từ với nhau đôi một, bao gồm cả chính nó (self), để tìm ra mức độ quan trọng của mỗi từ mà mô hình nên chú ý tới (thể hiện qua trọng số). Điều này giúp mô hình hiểu đúng ý nghĩa của từ trong ngữ cảnh cụ thể, thay vì chỉ dựa vào ý nghĩa tổng quát của từ đó khi đứng riêng lẻ.
2. Cơ chế hoạt động của Self-Attention.
2.1 Attention trong seq2seq.
Quay lại với bài toán dịch máy, nếu chúng ta chỉ dịch từng từ ở ngôn ngữ này sang ngôn ngữ khác bằng cách ánh xạ word-by-word , thì đó quả là một phương pháp tệ, thiếu hiệu quả do không học được thông tin từ những từ xung quanh.
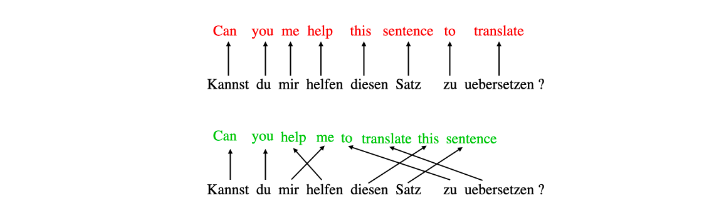
Mô hình seq2seq đã giới thiệu cơ chế attention. Trong cơ chế này, những từ đích được "chú ý" với các từ trong câu nguồn nhằm xác định xem mối quan hệ.Mỗi từ sẽ được biểu diễn dưới dạng vector embedding và có nhiều cách để tính toán "score attention". Ở đây, chúng ta sẽ sử dụng tích vô hướng (dot product). Hai từ có ngữ nghĩa càng tương đồng thì tích vô hướng vector embedding của chúng càng lớn (trong trường hợp này score attention càng cao ). Với mỗi từ đích , chúng ta tính tích vô hướng với tất cả các từ trong câu nguồn. Sau khi tính toán, chúng ta thu được một vector chứa các "score attention". Kết quả này được đưa qua hàm softmax để chuẩn hóa, từ đó xác định từ đích nên "chú ý" bao nhiêu phần trăm đến các từ trong câu nguồn.

Giả sử dịch câu "Tôi rất thích ăn cơm nếp" sang tiếng anh và ta có vector embedding của các từ trên:
tôi: [-0.124, 0.067, -0.089],rất: [0.156, -0.112, 0.078],thích: [-0.082, 0.145, -0.167],ăn: [0.134, -0.156, 0.112],cơm: [-0.167, 0.089, -0.134],nếp: [0.112, -0.145, 0.091],s1: [0.23, 0.34, 0.45],
Tính score attention:
sortmax:
kết quả này cho ta thấy s1 "chú ý" đến các từ trong câu nguồn là như nhau .
2.2 Chi tiết về Self-Attention.
Điểm khác biệt với cơ chế attention ở trên với self attention là ngoài "chú ý" với các từ xung quanh thì nó còn "tự chú ý" với chính nó. Để làm gì nhỉ? Tại sao lại cần "tự chú ý" với chính nó?.
Xét câu "Tôi cảm thấy tôi không được khoẻ." self-attention với khả năng "chú ý đến chính nó" giúp mô hình nhận ra sự liên quan giữa hai lần xuất hiện của từ "tôi" . Mô hình sẽ phân biệt được rằng cả hai lần "tôi" đều chỉ cùng một chủ thể, đồng thời cũng nắm bắt được cấu trúc câu. Hay trong câu "Tôi đọc sách của tôi." trong câu này, từ "tôi" cũng xuất hiện hai lần và lại có ngữ nghĩa liên quan đến chính người nói. Nhưng khi từ "Tôi" tự "chú ý" đến chính nó thì mô hình sẽ hiểu đây là chủ ngữ và thực hiện hành động đọc nhằm phân biệt với từ "tôi" thứ 2 không phải là chủ ngữ. Lúc này việc tự "chú ý" đến nó giúp mô hình hiểu ngữ cảnh một cách chính xác. Ngoài ra nó còn giúp giữ lại ngữ nghĩa cho từ, việc tự chú ý cho phép mỗi từ giữ lại ngữ nghĩa riêng của nó. Ví dụ, từ "tôi" khi xuất hiện lần thứ hai sẽ "nhớ" lại rằng nó đại diện cho người sở hữu cuốn sách, trong khi vẫn hiểu rõ rằng "Tôi" đầu tiên là chủ thể thực hiện hành động đọc.
Tóm lại, việc tự "chú ý " đến chính nó trong self-attention là cần thiết để mô hình giữ được ngữ nghĩa nguyên bản của từ và phân biệt chính xác các mối quan hệ ngữ cảnh trong câu, đặc biệt trong các cấu trúc phức tạp và câu có từ lặp lại.
Vậy tại sao attention trong seq2seq lại không tự "chú ý" đến chính nó. Đơn giản là seq2seq thường sử dụng RNN hoặc LSTM cho encoder và decoder, do đó thông tin được truyền tuần tự từ trái sang phải trong chuỗi và không có sự tương tác trực tiếp giữa các từ đầu ra tại cùng thời điểm. Điều này khác với self-attention, nơi các từ có thể tương tác với nhau ngay tại encoder hoặc decoder để tạo ngữ cảnh toàn diện hơn.
Positional Encoding?
Transformers xử lý tất cả các embedding cùng một lúc. Điều này giúp Transformer nhanh hơn nhiều, nhưng lại làm mất đi thông tin liên quan đến thứ tự của các từ trong câu. Để giải quyết vấn đề này, các tác giả của bài báo "Attention is All You Need" đã giới thiệu khái niệm positional encoding (trong bài viết này, chúng ta sẽ không đi sâu vào chi tiết). Có thể hiểu rằng: mỗi từ trong câu sẽ được gán một vector đánh dấu vị trí của nó. Vector này sẽ được cộng vào embedding của từng từ, từ đó tạo ra một vector mới dùng làm đầu vào cho mô hình. Cách làm này giúp mô hình không chỉ nhận diện nội dung của từ mà còn hiểu được vị trí của nó trong ngữ cảnh của câu, từ đó cải thiện khả năng xử lý ngữ nghĩa của toàn bộ đoạn văn.
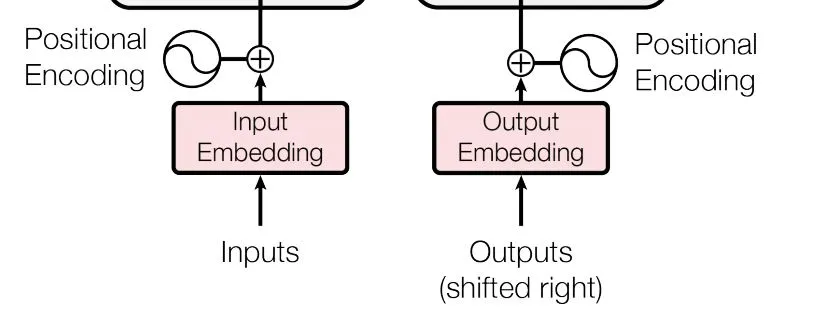
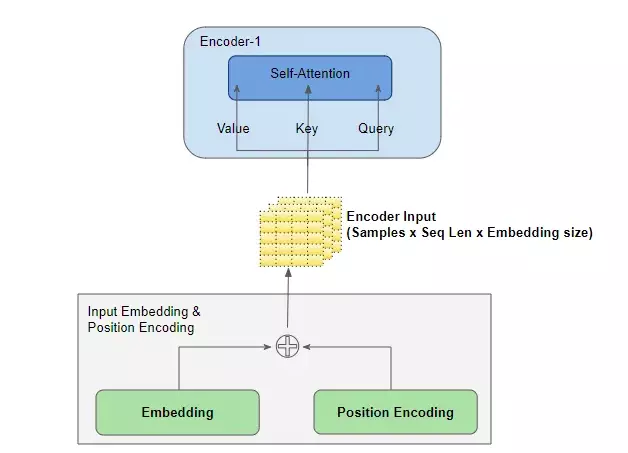
Bây giờ, chúng ta sẽ cùng đi sâu vào cách self-attention hoạt động. Đầu tiên, hãy xem cách tính self-attention bằng cách sử dụng các vector, sau đó sẽ chuyển sang cách cài đặt thực tế với các ma trận. Trước tiên, chúng ta cần làm rõ ba vector q (query), k (key), và v (value) là gì.
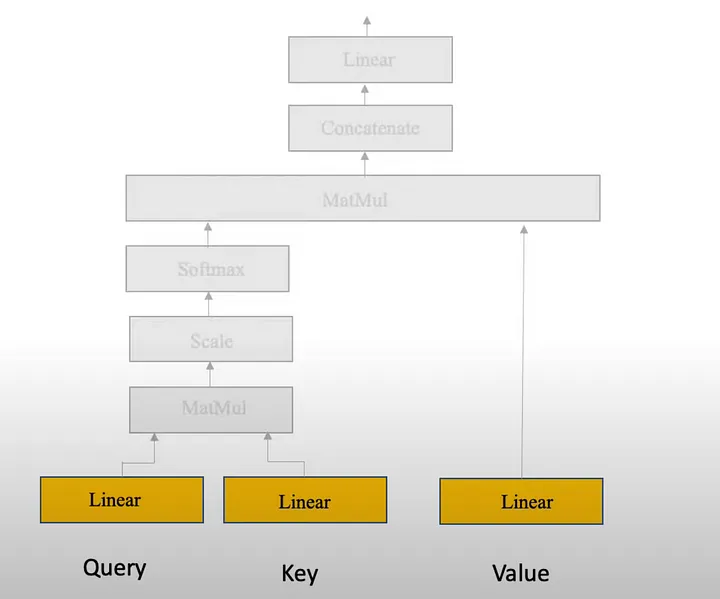
Giống như tên gọi của chúng, hãy tưởng tượng bạn tìm kiếm một từ khóa trên Google. Từ khóa mà bạn nhập vào được xem là q (query), các kết quả xuất hiện là k (key), và nội dung trong các kết quả đó là v (value). Để tìm ra kết quả khớp nhất, ta cần đo lường mức độ tương đồng giữa q và k. Để thực hiện điều này, self-attention sử dụng tích vô hướng giữa các vector.
Sau khi xác định được các vector đầu vào, ta sẽ nhân từng vector với ba ma trận trọng số W_Q, W_K, Q_V để thu được các vector q, k, và v đã biến đổi. Thêm một câu hỏi đặt ra là: Tại sao chúng ta phải nhân các vector này với các ma trận trọng số? Chắc chắn là không phải làm cho vui rồi  .Việc này không chỉ để giảm chiều vector đầu vào, giúp tối ưu hóa tính toán, mà quan trọng hơn, việc nhân với ma trận trọng số cho phép mô hình có thể học và cập nhật các trọng số này trong quá trình huấn luyện. Giúp mô hình cải thiện độ chính xác của self-attention trong các lần tính toán tiếp theo.
.Việc này không chỉ để giảm chiều vector đầu vào, giúp tối ưu hóa tính toán, mà quan trọng hơn, việc nhân với ma trận trọng số cho phép mô hình có thể học và cập nhật các trọng số này trong quá trình huấn luyện. Giúp mô hình cải thiện độ chính xác của self-attention trong các lần tính toán tiếp theo.
Kích thước của các ma trận trọng số được tính như sau:
- Ma trận trọng số W_q: có kích thước d_q x d_model
- Ma trận trọng số W_k: có kích thước d_k x d_model
- Ma trận trọng số W_v: có kích thước d_q x d_model
Trong đó:
- d_model là kích thước của mỗi vector đầu vào
- d_q, d_k là kích thước của các vector truy vấn (query) và khóa (key) d_q = d_k
- d_v là kích thước của vector giá trị (value) và có thể khác với d_q và d_k.
- trong bài báo Attention Is All You Need họ chọn chiều d_q = d_k = d_v = d_model / h (h là số lượng đầu (heads) trong cơ chế multi-head attention.)

Trong ví dụ trên 2 từ "Thinking" và "Machines" sau khi cộng embedding với positional encoding tương ứng ta thu được 2 vector đầu vào là x1và x2. Sau khi nhân lần lượt với các ma trận trọng số W_q, W_k, W_v ( các ma trận này ban đầu được khởi tạo ngẫu nhiên) ta được lần lượt các vector q1, k1, v1 cho từ "Thinking" và q2,k2,v2 cho từ "Machines".
Bước thứ hai để tính self-attention là tính điểm, với từ “Thinking”. Ta cần tính điểm cho mỗi từ trong câu đầu vào so với từ này. Điểm sẽ quyết định cần chú ý bao nhiêu vào các phần khác của câu đầu vào khi ta đang mã hóa một từ cụ thể.
Điểm được tính bằng phép nhân vô hướng giữa véc tơ truy vấn q với véc tơ khóa k của từ mà ta đang tính điểm. Nếu ta tiến hành self-attention cho từ ở vị trí thứ nhất, điểm đầu tiên sẽ là tích vô hướng của q1 và k1. Điểm thứ hai là tích vô hướng của q1 và k2.

Bước tiếp theo chúng ta cần Scale. Chia điểm cho 8 (căn bậc hai của số chiều của véc tơ khóa trong bài báo gốc – 64. Điều này giúp cho độ dốc ổn định hơn. Có thể có các giá trị khả dĩ khác, nhưng đây là giá trị mặc định), và truyền kết quả qua một phép softmax. Softmax chuẩn hóa các điểm để chúng là các số dương có tổng bằng 1.

Điểm softmax sẽ quyết định mỗi từ sẽ được thể hiện nhiều hay ít tại vị trí hiện tại. Rõ ràng là từ tại vị trí này sẽ có điểm softmax cao nhất, nhưng đôi khi, chú ý đến các từ khác là cần thiết để hiểu từ hiện tại.
Tiếp theo nhân mỗi véc tơ v (value) với điểm softmax (trước khi cộng chúng lại). Một cách trực giác, việc nhân vector v (value) với các giá trị sortmax này giúp bảo toàn giá trị của các từ mà ta muốn chú ý và bỏ qua các từ không liên quan (nhân chúng với một số rất nhỏ, ví dụ 0.001).
Cuối cùng là cộng các véc tơ v ( value ) đã được nhân trọng số. Kết quả chính là đầu ra của lớp self-attention tại vị trí hiện tại (từ đầu tiên trong ví dụ của ta). Để minh họa ta giả sử từ vector v (value) của 2 từ "Thinking" là và "Machines" như sau:
- Vector
v1của từ "Thinking" là[1, 0.5, 0.3] - Vector
v2của từ "Machines" là[0.2, 0.4, 0.6]
Sau khi tính toán softmax, ta có:
- Điểm softmax cho "Thinking" chú ý vào chính nó là
0.88 - Điểm softmax cho "Thinking" chú ý vào "Machines" là
0.12
Bây giờ, chúng ta nhân các điểm softmax này với các vector v tương ứng:
- Với "Thinking" chú ý vào chính nó:
- [1, 0.5, 0.3] * 0.88 = [0.88, 0.44, 0.264]
- Với "Thinking" chú ý vào "Machines":
- [0.2, 0.4, 0.6] * 0.12 = [0.024, 0.048, 0.072]
Cuối cùng, ta cộng hai vector này lại để có được đầu ra tổng hợp cho từ "Thinking":
- [0.88,0.44,0.264]+[0.024,0.048,0.072]=[0.904,0.488,0.336]
Kết quả cuối cùng [0.904, 0.488, 0.336] là vector đầu ra của lớp self-attention cho từ "Thinking". Vector này là một sự kết hợp có trọng số giữa các thông tin từ "Thinking" và "Machines", nhưng trọng số của "Thinking" chiếm ưu thế hơn do điểm softmax cao hơn.
Tính self-attention bằng ma trận
Giả sử ta nhập vào một câu: “Hi, How are you?” và muốn transformer của bạn xuất ra “I am fine”. Sau khi xử lý embedding và positional encoding ta thư đuợc một ma trận đầu vào của các từ trên. Sau đó nhân với các ma trận trọng số W_q, W_k, W_v ta đuợc 3 ma trận Q, K, V.
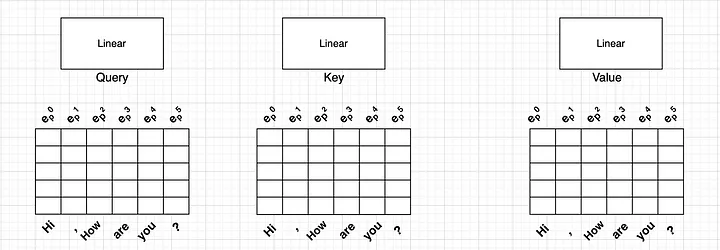


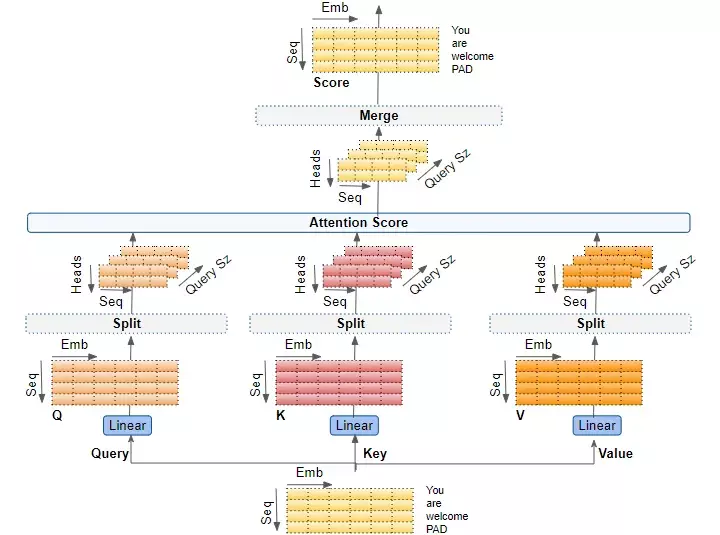
3. Multi-head Sefl-Attention.
Trong kiến trúc transformers phần mã hóa là một ngăn xếp encoder các encoder xếp chồng lên nhau (bài báo gốc sử dụng 6 encoder). Thành phần giải mã là một ngăn xếp decoder với cùng số lượng. Trong mỗi encoder người ta sử dụng nhiều self attention còn được gọi là attention head thay vì chỉ một Cơ chế này cải thiện hiệu năng của lớp attention theo hai khía cạnh:
- Nó mở rộng khả năng của mô hình trong việc tập trung vào các vị trí khác nhau. Nếu chỉ sử dụng 1 self attention việc tự "chú ý" vào chính nó sẽ bị bởi chính thông tin của từ đó làm lấn át đi một số thông tin mã hóa từ các vị trí khác,
- Nó mang lại cho lớp attention nhiều không gian con để biểu diễn. Với multi-headed attention chúng ta không chỉ có một mà nhiều bộ ma trận trọng số Query/Key/Value (Transformer sử dụng tám đầu attention, do đó ta sẽ có 8 bộ cho mỗi encoder/decoder). Mỗi bộ được khởi tạo ngẫu nhiên. Sau đó, kết thúc huấn luyện, mỗi bộ được dùng để phản ánh embedding đầu vào (hoặc véc tơ từ các encoder/decoder phía dưới) trong một không gian con riêng biệt.

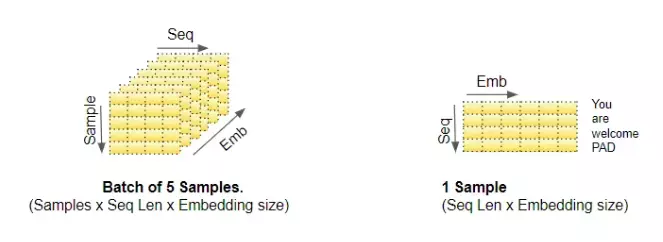
Chúng ta hãy xem cách nó hoạt động trong khi Transformer giải quyết vấn đề dịch thuật. Chúng ta sẽ sử dụng một mẫu dữ liệu đào tạo bao gồm một chuỗi đầu vào ('You are welcome' trong tiếng Anh) và một chuỗi mục tiêu ('De nada' trong tiếng Tây Ban Nha).
- Kích thước embedding ở ví dụ này chúng ta đặt là 1x6 ( hay d_model = 6)
- d_Q = d_K = d_V trong ví dụ này là 3
- Số lượng Attention heads trong ví dụ này là 2
Bước tiếp là chúng ta cần chia dữ liệu thành nhiều head attention để mỗi head có thể xử lí riêng biệt. Ở đây, việc chia chỉ là chia về mặt logic. Thực tế vector đầu vào không được phân chia vật lý thành các ma trận riêng biệt một cho mỗi head . Tương tự như vậy, không chia vật lý cho các ma trận W_Q, W_K, W_V, riêng biệt một cho mỗi head. Tất cả các head chia sẻ cùng một ma trận W_Q, W_K, W_Vớp Linear nhưng chỉ đơn giản là hoạt động trên phần logic 'riêng' của của chúng. (Nếu chia vật lý, giả sử có n đầu thì có tới 3n ma trận trọng số việc này không hiệu qua trong quá trình cập nhật trọng số về sau).
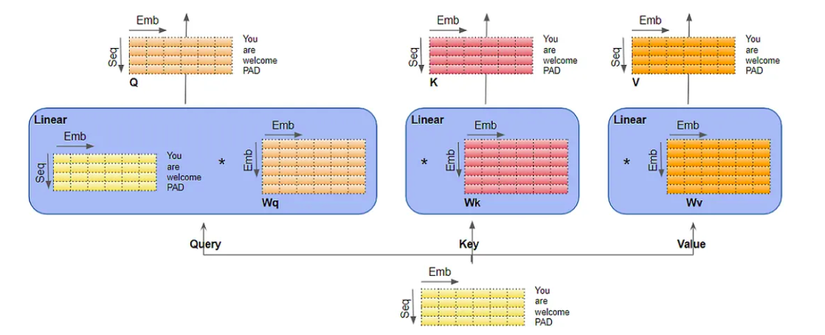
Tiếp theo chúng ta cần tính toán chiều của các ma trận W_Q, W_K, W_V cho mỗi head.
- Kích thước trước khi chia của mỗi W_Q, W_K, W_V làm emb_size x emb_size ( chọn kích thước này để chiều của Q, K , V cùng chiều cới vector đầu vào)emb_size
- Kich thước của W_Q, W_K, W_V khi chia cho mỗi đầu = emb_size) x (d_q x heads)
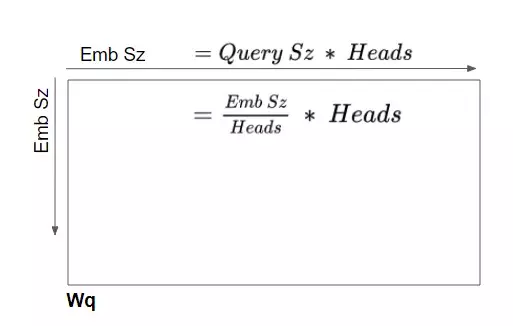
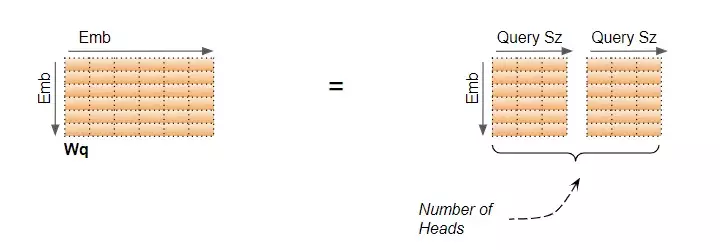
Mặc ma trân W_Q là một ma trận duy nhất, chúng ta có thể coi nó như là 'xếp chồng' các W_Q của mỗi head .
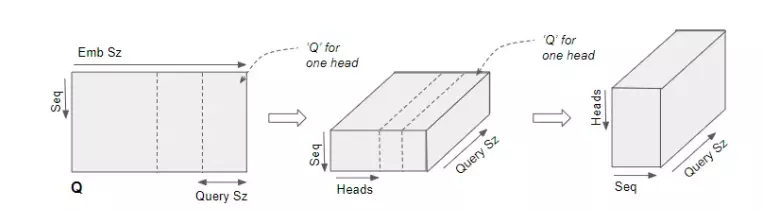
Bây giờ chúng ta cần định hình lại kích thước các ma trận Q,K, V. Ban đầu sau khi đi qua W_Q, W_K, W_V, các ma trận Q,K, V của chúng ta có chiều seq x emb (số câu x số chiều mỗi từ) trong ví dụ này là 4 x 6. Vì có 2 head nên chia 2 phần theo chiều embedding để mỗi chiều xử lí thông tin của một từ. Giả sử ta có embedding của "You are welcome"
You:[0.205, 0.352, 0.625, 0.256, 0.967, 0.423]are:[0.501, 0.750, 0.817, 0.609, 0.6057, 0.637]welcome:[0.080, 0.948, 0.696, 0.444, 0.376, 0.132]PAD:[0. , 0. , 0. , 0. , 0. , 0. ]
Chia các vector đầu vào này thành 2 phần tùy ý ( ở đây ta lấy mỗi phần có chiều là 3) cho mỗi đầu ta có :
-
với head 1:
You:[0.205, 0.352, 0.625]are:[0.501, 0.750, 0.817 ]welcome:[0.080, 0.948, 0.696]PAD:[0. , 0. , 0.]
-
với head 2:
You:[0.256, 0.967, 0.423]are:[0.609, 0.6057, 0.637]welcome:[0.444, 0.376, 0.132]PAD:[0. , 0. , 0.]
Chà!! việc chia như này tức là tạo ra các không gian vector riêng ở đây có thể xem head 1 và head 2 là các không gian vector riêng biệt và các từ trong không gian đấy có mối quan hệ là khác nhau . Việc này giúp mỗi head tập trung vào một mối quan hệ riêng. Ví dụ "Tôi thích ăn phở" head 1 có thể tập trung vào mối quan hệ chủ ngữ-vị ngữ ("Tôi" - "thích") trong khi đó head 2 có thể tập trung vào mối quan hệ vị ngữ-tân ngữ ("thích" - "phở").
Tiếp theo chúng ta tính score attention và sortmax cho mỗi head giống như ta đã làm ở self attention .
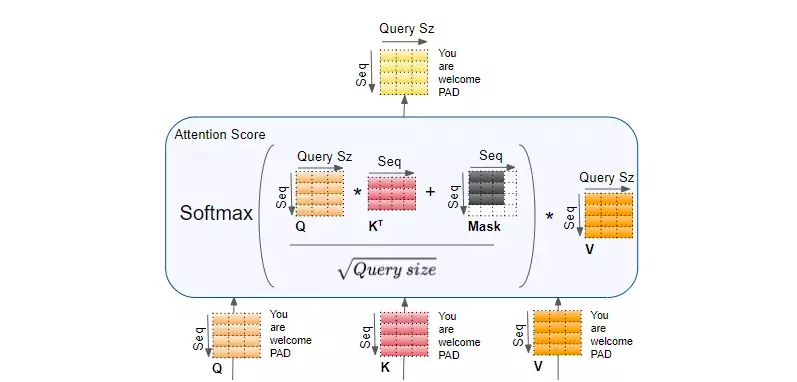
Sau khi tính toán xong ở mỗi head, chúng ta cần ghép (concatenate) các kết quả từ các head lại với nhau theo từng câu. Kết quả này chính là đầu vào cho encoder kế tiếp.
Lời kết.
Self attention , mutil-head attention cùng với mô hình Transformer đã được thể hiện được sự hiệu quả của nó trong nhiều lĩnh vực đặc biệt trong NLP và xử lý ảnh . Trên đây là một số kiến thức mà mình tìm hiểu được . Vì kiến thức mình hạn hẹp nên rất mong sự đóng góp của mọi người. Cảm ơn các bạn đọc bài viết .
-
Tài liệu tham khảo trong bài viết.
All rights reserved
