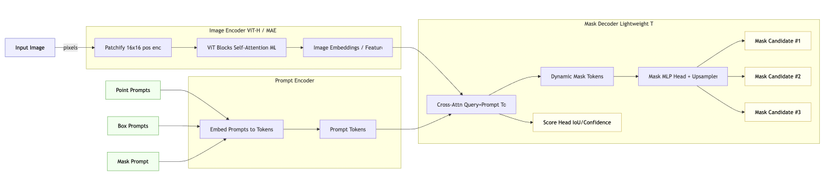
SAM Segment Anything Model — Kiến trúc & Công thức Toán học
🧮 Công thức Toán học Chính trong SAM
1. Patch Embedding — Ảnh sang Tokens
Mỗi patch được ánh xạ thành vector nhúng:
Trong đó là ma trận trọng số học được.
Giải thích:
Công thức này chuyển từng mảnh nhỏ của ảnh (patch) thành một vector để mô hình có thể hiểu.Ví dụ: Ảnh 224x224 được chia thành 16x16 patch → 196 patch. Mỗi patch được chuyển thành vector 768 chiều để đưa vào Transformer.
2. Self-Attention trong Image Encoder (ViT)
Công thức Attention:
Với:
Output của mỗi layer:
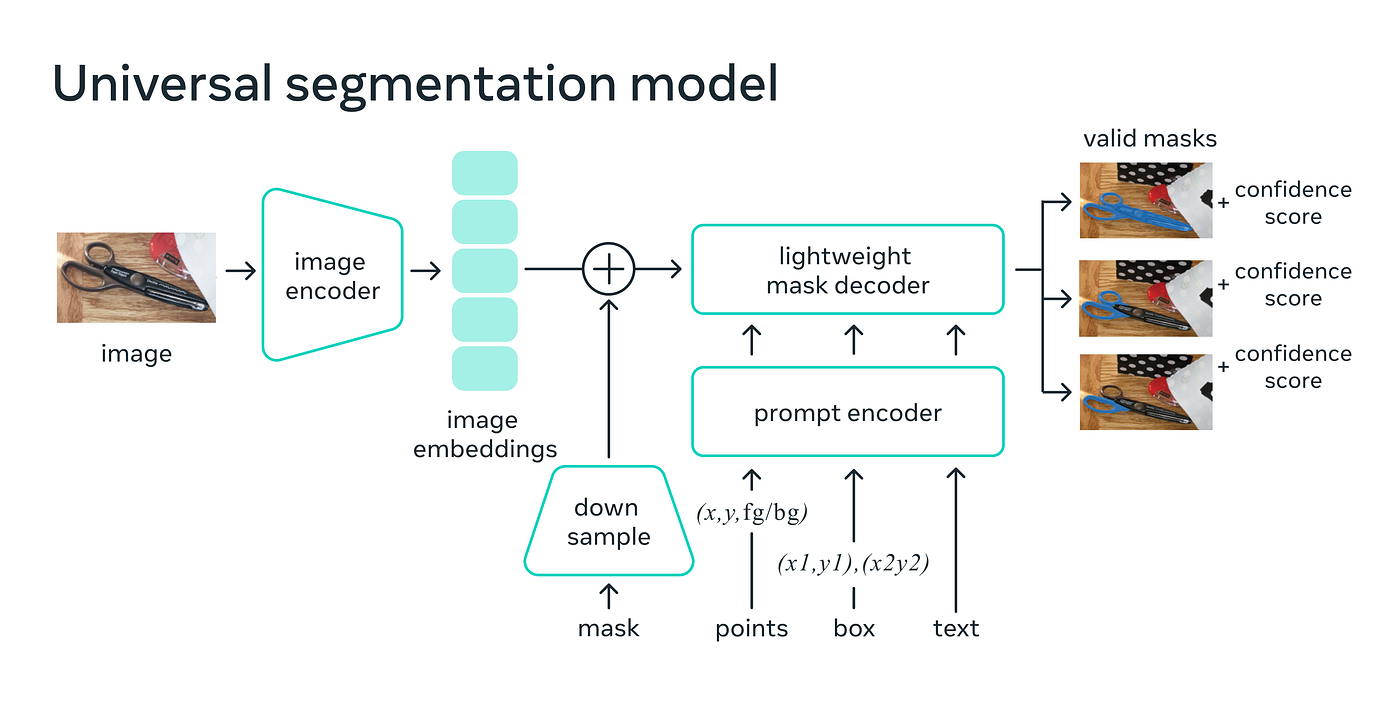
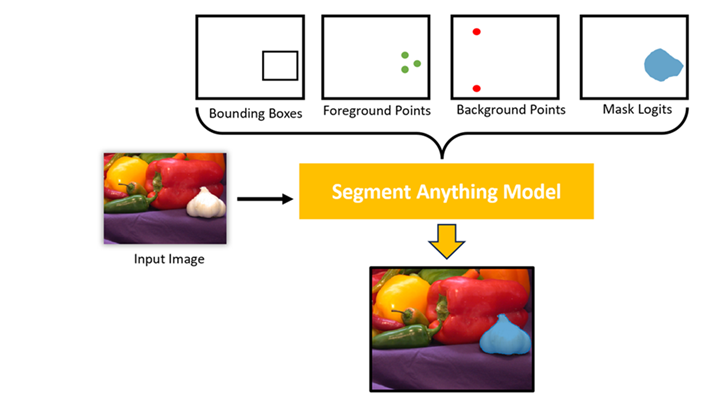
3. Prompt Encoding
Mỗi prompt (điểm, khung, hoặc mask) được mã hóa thành vector:
Ví dụ:
- Điểm: tọa độ
- Khung:
- Mask: ma trận nhị phân
Các vector này tạo thành:
4. Cross-Attention giữa Prompt và Image Features
Decoder sử dụng cross-attention giữa (prompt tokens) và (image embeddings):
là biểu diễn hợp nhất giữa thông tin prompt và ảnh.
5. Mask Generation
Từ đầu ra :
- : xác suất pixel thuộc vùng đối tượng.
- : hàm sigmoid.
6. Confidence Score (IoU Evaluation)
Giải thích: Đánh giá độ trùng giữa mask dự đoán và mask thật. Ví dụ: Nếu SAM phát hiện vùng kéo trùng 92% với vùng thật → .
🔍 Tóm tắt Dòng Chảy Dữ Liệu
Nói cách khác:
SAM không chỉ "nhìn" ảnh, mà còn học được cách hiểu ranh giới của mọi vật thể. Từ con mèo, cánh cửa đến ký tự nhỏ — tất cả đều được phân tách bằng cùng một cơ chế toán học duy nhất.
Ref:
All rights reserved
