Saga Pattern: Tutorial thì dễ, Production là "Ác mộng"
Khi mới bước chân vào thế giới Microservices, Saga Pattern thường được ca tụng như một "vị cứu tinh" hoàn hảo cho bài toán quản lý giao dịch phân tán (Distributed Transaction). Bạn mở một bài tutorial lên, gõ theo vài đoạn code mẫu, thử giả lập một lỗi nhỏ để xem cơ chế bù trừ (compensating transaction) hoạt động ra sao. Mọi thứ diễn ra trơn tru như sách giáo khoa: lỗi ở đâu, rollback sạch sẽ ở đó.
Nhưng "tuần trăng mật" đó sẽ nhanh chóng kết thúc khi bạn mang đoạn code ấy lên môi trường production.
Thực tế tàn khốc hơn rất nhiều khi hệ thống của bạn không chỉ chạy nội bộ mà bắt đầu phải giao tiếp, đồng bộ trạng thái và đẩy dữ liệu sang các hệ thống third-party như Jira, ServiceNow hay các cổng thanh toán. Chuyện gì sẽ xảy ra khi API bên thứ ba bỗng dưng trả về timeout nhưng dữ liệu thực tế đã được ghi nhận? Bạn sẽ retry hay rollback? Làm sao để xử lý khi một service trung gian lăn ra chết, bỏ lại luồng dữ liệu kẹt vĩnh viễn ở trạng thái "pending"? Lúc này, từ một pattern thanh lịch, Saga biến thành một mớ bòng bong khổng lồ với hàng tá luồng xử lý edge-case chồng chéo, vắt kiệt sức lực của cả team chỉ để ngồi trace log mỗi khi có transaction thất bại.
Saga Pattern trên production thực sự là một con thú dữ khó thuần phục. Tuy nhiên, để tìm ra cách "sống sót" và thiết kế một hệ thống chịu lỗi tốt (fault-tolerant), chúng ta không thể đi đường tắt. Trước khi bước vào phân tích những góc khuất "đẫm máu" của quá trình triển khai thực tế, hãy cùng tôi lùi lại một chút ở Phần 1. Chúng ta sẽ cùng rà soát lại nền tảng cốt lõi của Saga Pattern: Bản chất thực sự của nó là gì, vì sao nó lại là "cái ác bắt buộc" trong kiến trúc phân tán, và cách thức hoạt động của hai mô hình kinh điển nhất hiện nay.
1. Nỗi đau mà Saga Pattern sinh ra để giải quyết
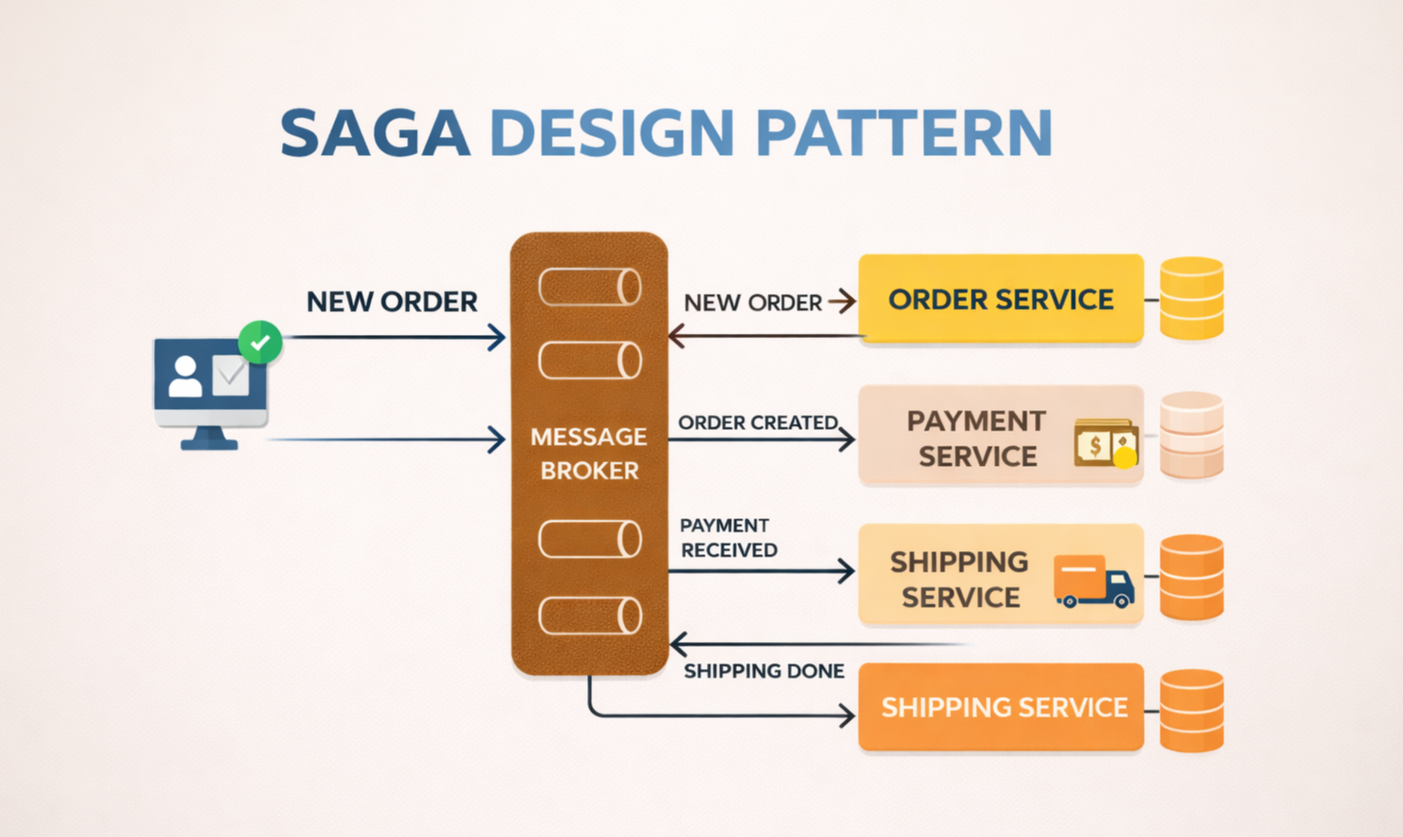
Nỗi đau lớn nhất mang tên: Giao dịch phân tán (Distributed Transactions) trong môi trường mỗi service có một database riêng (Database-per-service).
Để dễ hình dung, hãy so sánh hai thời kỳ:
Thời kỳ Monolithic (Nguyên khối - Quá khứ êm đẹp):
Khi bạn có một hệ thống lớn dùng chung một database duy nhất. Mọi thứ rất dễ dàng nhờ đặc tính ACID của database quan hệ.
-
Ví dụ: Khi khách mua hàng, bạn cần: (1) Tạo đơn hàng, (2) Trừ tiền, (3) Trừ kho.
-
Bạn chỉ cần gói gọn 3 việc này trong một transaction. Nếu bước (3) trừ kho thất bại vì hết hàng, bạn chỉ cần gọi một lệnh ROLLBACK. Database sẽ tự động hủy việc tạo đơn và trả lại tiền. Mọi thứ an toàn tuyệt đối.
Thời kỳ Microservices (Hiện tại - Nỗi đau bắt đầu):
Bây giờ hệ thống chia làm 3 service độc lập: Order Service, Payment Service, và Inventory Service. Mỗi service dùng một database riêng biệt.
-
Bước 1: Order Service tạo đơn thành công (lưu vào DB của nó).
-
Bước 2: Payment Service trừ tiền thành công (lưu vào DB của nó).
-
Bước 3: Inventory Service báo lỗi hết hàng.
Câu hỏi ác mộng: Làm sao để ROLLBACK bước 1 và bước 2? Bạn không thể gõ lệnh ROLLBACK xuyên qua 3 database khác nhau được.
Lúc này, bạn đối mặt với 2 lựa chọn tồi tệ:
Dùng Two-Phase Commit (2PC): Bắt tất cả database phải khóa (lock) dữ liệu lại, đợi tất cả cùng đồng ý thì mới lưu. Cách này giải quyết được vấn đề nhất quán dữ liệu nhưng giết chết hiệu năng. Hệ thống sẽ rất chậm và dễ bị treo (deadlock).
Kệ nó: Chấp nhận việc dữ liệu bị sai lệch. Khách bị trừ tiền nhưng không có hàng, phải chờ nhân viên CSKH xử lý bằng tay.
=> Nỗi đau ở đây là: Làm sao để giữ cho dữ liệu đồng nhất trên nhiều database khác nhau mà không làm hệ thống chậm rùa bò?
2. Saga Pattern là gì? (Cách giải quyết nỗi đau)
Saga Pattern chính là giải pháp thay thế hoàn hảo cho lệnh ROLLBACK và cơ chế 2PC cồng kềnh trong Microservices.
Thay vì cố gắng nhồi nhét mọi thứ vào một giao dịch khổng lồ và khóa chặt hệ thống, Saga chia nhỏ quy trình thành một chuỗi các Giao dịch cục bộ (Local Transactions) chạy nối tiếp nhau.
Điểm cốt lõi tạo nên sức mạnh của Saga là cơ chế Giao dịch hoàn tác (Compensating Transactions).
Cách Saga "chữa lành" nỗi đau: Thay vì khóa dữ liệu, Saga cho phép dữ liệu cứ được lưu lại ở từng bước (để hệ thống chạy nhanh). Nhưng nếu có một bước ở giữa gãy gánh, hệ thống sẽ tự động chạy lùi lại, kích hoạt các đoạn code "chữa cháy" để đảo ngược kết quả.
Áp dụng vào ví dụ mua hàng:
-
Order Service tạo đơn hàng trạng thái Pending. (Thành công)
-
Payment Service thực hiện trừ tiền. (Thành công)
-
Inventory Service báo hết hàng. (Thất bại!)
-
Saga kích hoạt quy trình lùi:
-
Gọi Payment Service: Thực hiện giao dịch Hoàn tiền (Refund) để bù đắp cho việc trừ tiền ở bước 2.
-
Gọi Order Service: Thực hiện giao dịch Hủy đơn (Cancel) để bù đắp cho việc tạo đơn ở bước 1.
-
Nhờ Saga, hệ thống đạt được trạng thái Eventually Consistent (Nhất quán sau cùng): Trong một khoảnh khắc ngắn, dữ liệu có thể bị lệch (tiền đã trừ, hàng chưa có), nhưng "sau cùng", hệ thống sẽ tự động dọn dẹp để bù trừ và đưa mọi thứ về trạng thái đúng đắn mà không cần khóa bất kỳ database nào. Nhưng cũng chính cơ chế "bù trừ" lỏng lẻo này có thế sẽ là khởi nguồn cho những góc khuất khốc liệt nhất trên production.
3. Choreography vs Orchestration: Điểm bùng phát và Nút thắt cổ chai
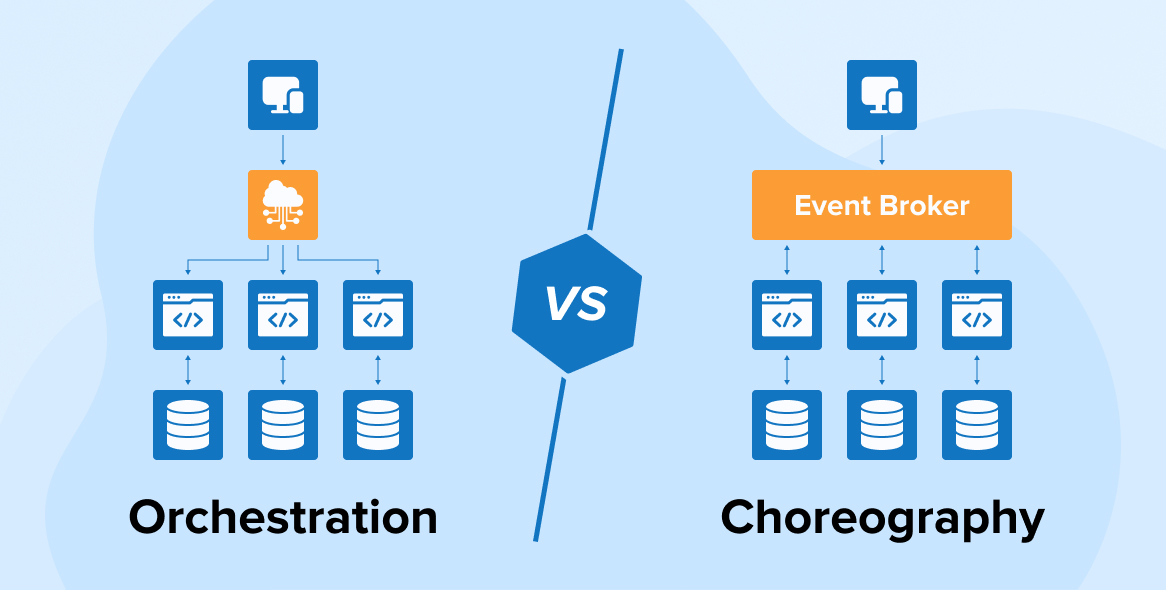
Ở mức độ tutorial, mọi người thường rập khuôn: Choreography là event-driven (các service tự phản ứng với sự kiện của nhau), còn Orchestration là command-driven (có một "nhạc trưởng" trung tâm ra lệnh).
Tuy nhiên, với góc nhìn của Senior/SA, bản chất của bài toán này trên production là sự dịch chuyển của độ phức tạp (Shift of Complexity):
-
Choreography và bẫy "Event Spaghetti": Hoạt động mượt mà với 2-3 bước. Nhưng khi hệ thống phình to (thêm Shipping, Loyalty), nó biến thành một mớ bòng bong. Điểm bùng phát là khi không một service nào nắm giữ toàn bộ "Trạng thái" (State). Để biết đơn hàng #123 kẹt ở đâu, kỹ sư phải mò mẫm trace log qua hàng loạt service.
-
Orchestration và hội chứng "God Service": Khi chuyển sang dùng "Nhạc trưởng" (Orchestrator) để quản lý State, các team thường vô tình nhét luôn logic nghiệp vụ vào nó. Hậu quả là Orchestrator biến thành nút thắt cổ chai (Single point of failure). Nguyên tắc: Orchestrator chỉ quản lý quy trình (gửi Command "Hãy trừ kho"), tuyệt đối không chứa logic (không tự tính toán kho nào còn hàng).
Chúng ta hãy thử cùng làm rõ điểm bùng phát (tipping point) khiến chúng ta buộc phải chuyển đổi giữa hai pattern này.
Mình có một tình huống như này, các bạn hãy thử đặt mình vào vị trí của SA đang thiết kế một luồn E-commerce phức tạp (Order > Inventory > Payment > Shipping > Loyalty). Theo góc nhìn của bạn, đâu là những dấu hiệu cảnh báo (red flags 🚩) rõ nhất trong quá trình phát triển hoặc vận hành khiến bạn phải đưa ra quyết định: "Luồng này quá phức sức với Choreography rồi, bắt buộc phải đưa nhạc trưởng vào ?" 3s đếm ngược nhé1️⃣2️⃣3️⃣
Dấu hiệu ở đây rõ ràng nhất chính là số lượng service tham gia vào luồng (workflow) tăng lên (một rule-of-thumb phổ biến trong giới SA là từ 4-5 bước trở lên), chúng ta sẽ bắt đầu đối mặt với "Event Spaghetti 💥".
Lúc này, để trả lời một câu hỏi vận hành đơn giản như: "Đơn hàng #123 của khách đang bị kẹt ở đâu?", hệ thống không có cách nào trả lời ngay lập tức. Chúng ta phải dùng Correlation ID để mò mẫm trace log qua hàng loạt service khác nhau vì không có một nơi nào nắm giữ toàn bộ "State" (trạng thái) của giao dịch đó.
Đó chính là điểm bùng phát buộc chúng ta phải đưa "nhạc trưởng" (Orchestrator) 🎼 vào cuộc. Orchestrator sẽ lưu trữ State Machine (ví dụ: PENDING_PAYMENT, PAYMENT_SUCCESS, INVENTORY_FAILED...) để quản lý tập trung trạng thái của toàn bộ quá trình.
=> Tuy nhiên, mang Orchestrator vào lại sinh ra một cái bẫy chết người khác trên production: Hội chứng "God Service".
- Nhiều team khi chuyển sang Orchestration lại vô tình nhét luôn cả logic nghiệp vụ (ví dụ: công thức tính mã giảm giá, luật chọn kho hàng gần nhất) vào thẳng bên trong Orchestrator. Hậu quả là Orchestrator biến thành một cục Monolith 2.0 khổng lồ, tightly-coupled (kết dính chặt) với mọi service xung quanh.
Chính vì thế để giữ Orchestrator không biến thành "God Service", nguyên tắc cốt lõi là phân tách rõ ràng giữa Luồng điều phối (Workflow) và Logic nghiệp vụ (Domain Logic).
Hãy hình dung Orchestrator giống như một người quản lý nhà hàng 🤵. Người quản lý chỉ ra lệnh: "Đầu bếp, hãy làm món bò bít tết" (Command). Người quản lý tuyệt đối không dạy đầu bếp cách ướp thịt hay nướng thịt.
Trong hệ thống thực tế, nó hoạt động như sau:
-
Orchestrator gửi một thông điệp (Command) như ReserveInventory (Giữ hàng) đến Inventory Service 📦.
-
Inventory Service tự chạy các logic phức tạp của riêng nó (kiểm tra tồn kho, áp dụng quy tắc giữ hàng theo VIP...) sau đó ghi vào database của chính nó.
-
Inventory Service trả về một kết quả (Event/Reply) là InventoryReserved (Đã giữ hàng) hoặc OutOfStock (Hết hàng).
-
Orchestrator nhận kết quả và tra bảng State Machine để biết bước tiếp theo phải gọi service nào (ví dụ gọi Payment Service 💳).
Nhờ vậy, Orchestrator chỉ quan tâm đến cái gì cần làm và thứ tự ra sao, chứ không bao giờ chứa logic làm như thế nào.
4. Bản chất của "Rollback" & Vấn đề Isolation
Rồi cuối cùng chúng ta cũng đã đặt chân tới nơi khái niệm "ác mộng" thực sự bắt đầu.
Trong một hệ thống nguyên khối (Monolith) dùng chung một cơ sở dữ liệu, nếu có lỗi xảy ra, chúng ta chỉ cần gọi lệnh ROLLBACK của SQL, mọi thứ sẽ trở lại như chưa từng có cuộc chiến (đảm bảo tính ACID).
Nhưng trong hệ thống phân tán, mỗi service lại ôm một database độc lập. Giả sử Inventory Service đã trừ kho và commit (lưu) thành công vào database của nó. Ngay bước tiếp theo, Payment Service lại báo lỗi (ví dụ khách hàng gõ sai mã OTP). Chúng ta không thể thò tay sang database của Inventory để gọi lệnh ROLLBACK được nữa.
Chúng ta hãy cùng thử ôn nhanh lại bài chút nhé, vậy thay vì dùng cơ chế Rollback của database, kiến trúc Saga giải quyết bài toán "hoàn tác" (undo) một giao dịch đã thành công ở bước trước đó bằng cách nào?
Giải pháp cốt lõi của Saga cho vấn đề này là sử dụng Compensating Transactions (Giao dịch bù trừ) ⏪.
Thay vì dựa vào cơ sở dữ liệu để ROLLBACK (xóa đi những gì vừa viết một cách vô hình), Saga yêu cầu chúng ta phải chạy một giao dịch mới để đảo ngược kết quả nghiệp vụ của giao dịch cũ. Ví dụ: Nếu bước 1 Inventory Service chạy hàm giảm_tồn_kho(), thì khi có lỗi ở bước 2, hệ thống phải gọi một hàm bù trừ là tăng_lại_tồn_kho().
Nhưng đây mới là lúc "ác mộng" thực sự xuất hiện trên production do hệ thống bị mất đi tính Isolation (Cô lập). Hãy xét kịch bản này:
Khách hàng A đặt mua chiếc áo thun cuối cùng. Inventory trừ kho thành công (Kho = 0).
Trong lúc chờ khách hàng A chuyển sang trang Payment để nhập mã OTP, khách hàng B vào xem đúng chiếc áo đó. Thấy Kho = 0, khách B thất vọng rời trang web. (Đây gọi là hiện tượng Dirty Read - Đọc dữ liệu rác/chưa chốt).
Khách A nhập sai OTP 3 lần, thanh toán thất bại ❌. Saga kích hoạt Compensating Transaction, trả lại chiếc áo vào kho (Kho = 1).
🎌Hậu quả: Dữ liệu cuối cùng thì đúng, nhưng cửa hàng đã mất oan khách hàng B vì tính trạng thiếu Isolation của Saga.
Đây chính là một trong những bài toán hóc búa nhất của hệ thống phân tán! Khi Saga thiếu đi tính Isolation (cô lập) mặc định của database, chúng ta bắt buộc phải dùng các thủ thuật ở tầng Logic nghiệp vụ (Business Logic) để bù đắp.
Để giải quyết kịch bản khách hàng B bị mất oan, các Senior/SA thường áp dụng 2 chiến thuật kinh điển sau:
1. Semantic Lock (Khóa ngữ nghĩa)
Thay vì ngay lập tức cập nhật dữ liệu gốc (trừ thẳng tồn kho về 0), chúng ta thêm một trạng thái trung gian (flag) vào dữ liệu.
-
Khi khách A bắt đầu thanh toán, số lượng thực tế trong kho vẫn là 1, nhưng ta tạo một bản ghi "Đang giữ hàng" (Reserved = 1) có thời hạn (ví dụ: 5 phút).
-
Khi khách B vào xem, hệ thống không hiển thị "Hết hàng" một cách phũ phàng. Thay vào đó, qua việc tính toán (Tồn kho thực tế - Đang giữ hàng), UI có thể khéo léo hiển thị: "Sản phẩm đang nằm trong giỏ hàng của người khác, vui lòng quay lại sau 5 phút".
2. Đảo trình tự luồng (Reordering Steps)
Một nguyên tắc trong Saga là: Hãy đưa bước dễ thất bại nhất lên làm đầu tiên.
-
Trong E-commerce, việc thanh toán (Payment) thường có tỉ lệ lỗi cao nhất (do khách nhập sai mã, thẻ hết tiền, ngân hàng bảo trì...).
-
Nếu ta đảo luồng: Cho khách hàng thanh toán thành công (hoặc ít nhất là "Hold" tiền trong thẻ) rồi mới gọi sang Inventory Service để trừ kho, chúng ta sẽ giảm thiểu được tới 90% các trường hợp phải chạy lệnh hoàn tác (Compensating Transaction) cho tồn kho.
Hai thủ thuật này giúp hệ thống vừa trơn tru, vừa không làm mất trải nghiệm người dùng khi có giao dịch chạy song song.
Bây giờ, chúng ta cùng bước sang mảnh ghép cuối cùng và cũng là thứ dễ bị "bỏ quên" nhất.
5. Idempotency (Tính lũy đẳng) & Retry.
Trong môi trường production mạng mẽo không bao giờ hoàn hảo. Thông điệp giao tiếp giữa các service thường được thiết kế theo cơ chế At-least-once delivery (Gửi ít nhất một lần). Nghĩa là do mạng chập chờn (timeout), hệ thống có thể tự động Retry và gửi lệnh Trừ_Tiền_Khách_Hàng đến Payment Service tới 3 lần cho cùng một đơn hàng.
Nếu chúng ta là người thiết kế Payment Service, theo bạn, chúng ta cần lưu trữ hay kiểm tra điều gì trong database để khi nhận được 3 lệnh trừ tiền giống hệt nhau, hệ thống vẫn tự tin nói: "Tôi đã xử lý cái này rồi, sẽ không trừ tiền khách thêm lần nào nữa".
Đây là "chốt chặn" cuối cùng và cũng là nơi phân loại rõ nhất giữa một hệ thống "chạy được" và một hệ thống "sẵn sàng cho production". Để Payment Service nhận 3 lệnh trừ tiền giống hệt nhau mà chỉ trừ tiền đúng 1 lần, các Senior/SA áp dụng một kỹ thuật gọi là Idempotency Key (Khóa lũy đẳng) kết hợp với cơ chế Khóa (Locking) ở tầng Database.
Dưới đây là cách nó hoạt động trên thực tế, vượt ra khỏi các lý thuyết cơ bản:
1. Sinh ra một "Idempotency Key" duy nhất
Khi Orchestrator (hoặc Client) gọi sang Payment Service, nó không chỉ gửi thông tin OrderID=123 và Amount=500k. Nó phải đính kèm một mã độc nhất cho chính lần gọi đó, ví dụ trên Header: Idempotency-Key: charge_order_123_attempt_1.
2. Bẫy "Race Condition" (Điều kiện tương tranh) – Ác mộng thực sự
Cách làm "ngây thơ" mà các tutorial hay dạy là:
-
Bước 1: Query DB xem Idempotency-Key này đã tồn tại chưa.
-
Bước 2: Nếu chưa, tiến hành gọi API ngân hàng trừ tiền.
-
Bước 3: Lưu Idempotency-Key vào DB để đánh dấu là đã xử lý.
Vấn đề trên Production: Nếu mạng lag, Orchestrator gửi liền 2 request tới cùng lúc (chỉ cách nhau vài mili-giây). Cả 2 request cùng chạy Bước 1, cùng thấy DB chưa có key này, và kết quả là... khách hàng vẫn bị trừ tiền 2 lần!
3. Giải pháp của Senior/SA: Uỷ thác cho Database (Database Constraint)
Để chống lại Race Condition, chúng ta không dùng lệnh IF / ELSE trong code, mà ép Database làm "kẻ gác đền":
-
Tạo một bảng idempotency_records với cột idempotency_key được set là UNIQUE INDEX (chỉ mục duy nhất).
-
Khi nhận request, service sẽ cố gắng thực hiện lệnh INSERT INTO idempotency_records (idempotency_key) VALUES (...) ngay lập tức.
-
Request đầu tiên sẽ INSERT thành công và đi tiếp vào luồng trừ tiền.
-
Request thứ 2 (dù đến cùng lúc) sẽ bị Database văng ra lỗi DuplicateKeyException (Lỗi trùng khóa). Service catch được lỗi này và lập tức biết rằng: "À, có một luồng khác đang xử lý key này rồi, mình dừng lại thôi!".
(Nhiều hệ thống lớn có thể dùng Redis với lệnh SETNX - Set if Not eXists để làm distributed lock thay cho DB quan hệ để tăng tốc độ).
4. Trả về kết quả cũ (Cached Response)
Một nguyên tắc quan trọng: Khi request thứ 3, thứ 4 đến (sau khi request 1 đã trừ tiền thành công), Payment Service không được trả về lỗi. Nó phải lấy kết quả thành công của lần 1 (đã lưu trong bảng idempotency_records) và trả về HTTP 200 y hệt như cũ. Nhờ vậy, Orchestrator ở đầu kia mới yên tâm là giao dịch đã hoàn tất và đi tiếp.
6: Đảm bảo tính nhất quán dữ liệu và Xử lý ngoại lệ trong Hệ thống phân tán
Vừa rồi ở trên chúng ta đã cùng nhau mổ xẻ khá sâu và "bóc trần" được những góc khuất khốc liệt nhất của Saga Pattern trên môi trường Production:
-
Sự dịch chuyển độ phức tạp giữa Choreography và Orchestration, và cách tránh tạo ra "God Service".
-
Bản chất của Rollback, sự thiếu hụt Isolation dẫn đến Dirty Read, và các thủ thuật (Semantic Lock, Đảo luồng).
-
Idempotency và cuộc chiến với Race Condition khi hệ thống tự động Retry.
Về cơ bản, 3 trụ cột chúng ta vừa mổ xẻ đã rất vững chắc và đầy đủ về những thứ chúng ta cần lưu tâm xung quanh Saga. Tuy nhiên, để bức tranh "ác mộng production" thực sự hoàn thiện, có 2 mảnh ghép ẩn thường đi kèm với Saga mà chúng ta cũng cần phải chú ý.
-
Thảm họa "Lệch nhịp": Khi lưu Database thành công nhưng Event thất lạc (Transactional Outbox Pattern) 📦 Khi một service cập nhật database của nó xong, nó phải bắn một Event (ví dụ: OrderCreated) ra Message Broker (Kafka, RabbitMQ) để service khác biết. Nhưng nếu lưu DB thành công mà lúc bắn Event mạng lại sập thì sao? Saga sẽ đứt gãy ngay từ bước đầu tiên. Pattern Transactional Outbox thường được dùng để giải bài toán này.
-
Bước đường cùng: Khi cả lệnh Hoàn tác (Compensating) cũng thất bại ☠️ Chúng ta đã nói về Retry, nhưng điều gì xảy ra nếu hệ thống cứ Retry mãi lệnh bù trừ (ví dụ: cộng lại tồn kho) mà vẫn lỗi (do database bên Inventory chết hẳn)? Lúc này Saga bị kẹt ở trạng thái lấp lửng. Đây là lúc cần đến Dead Letter Queue (DLQ) và cơ chế cảnh báo (Alerting) để con người (Operation Team) nhảy vào can thiệp thủ công.
Có thể nói đây là 2 gia vị rất quan trọng của Saga Pattern mà chúng cần thêm vào để tăng tính thực chiến. Chính vì thế chúng ta hãy cùng lần lượt môt xẻ 2 vấn đền trên xem nó thực sự là gì nhé.
1. Thảm họa "Lệch nhịp": Khi lưu Database thành công nhưng Event thất lạc.
Trong Saga, các service thường giao tiếp với nhau bằng Message/Event thông qua Message Broker (như Kafka hay RabbitMQ). Hãy tưởng tượng Order Service phải thực hiện tuần tự 2 việc:
-
Bước 1: Lưu trạng thái đơn hàng vào Database.
-
Bước 2: Bắn sự kiện OrderCreated lên Kafka để báo cho các service khác (như Payment, Inventory) làm việc tiếp.
Nếu bước 1 thành công nhưng bước 2 thất bại (do rớt mạng hoặc Kafka đang khởi động lại), toàn bộ luồng Saga sẽ bị "mù" và đứng im mãi mãi vì không ai nhận được thông báo để chạy tiếp. Chúng ta lại không thể gộp lệnh lưu Database và lệnh gọi Kafka vào chung một SQL Transaction được.
Giải pháp kinh điển ở đây là sử dụng Transactional Outbox Pattern 📦. Vậy Pattern này giúp chúng ta giải quyết vấn đề này như thế nào.
Để khắc phục, chúng ta áp dụng tư duy: Chỉ dùng Transaction cho những thứ nằm chung một nhà.
Hãy tưởng tượng bạn là một vị Giám đốc. Bạn cần làm 2 việc: Ký quyết định nội bộ (Lưu Order) và Thông báo cho toàn công ty (Bắn Kafka). Thay vì vừa ký giấy vừa tự cầm điện thoại gọi cho từng người, bạn làm thế này:
-
Bước 1 (Lưu trữ): Bạn tạo thêm một cái khay nhựa trên bàn làm việc đặt tên là Outbox (Hộp thư đi).
-
Bước 2 (Giao dịch cục bộ - Local Transaction): Mỗi khi có đơn hàng, bạn lưu dữ liệu vào bảng orders, ĐỒNG THỜI tạo một bản ghi sự kiện (ví dụ: Order_123_Created) nhét vào bảng outbox.
-
Điểm mấu chốt: Thay vì cố gắng gọi thẳng Kafka, Order Service sẽ lưu sự kiện đó vào một bảng chuyên dụng tên là outbox nằm cùng một database với bảng orders. Vì chúng nằm chung một database, chúng ta có thể dùng tính năng Transaction mặc định của cơ sở dữ liệu (ACID): hoặc là lưu thành công cả đơn hàng lẫn sự kiện, hoặc là rollback không lưu gì cả. Lúc này, dữ liệu nghiệp vụ và sự kiện giao tiếp luôn nhất quán 100%.
Nếu để ý, đoạn này có thể bạn sẽ thắc mắc là tại sao lại phải tạo thêm bảng Outbox trong khi ta đã lưu dữ liệu vào bảng Orders rồi, tại sao không dùng luôn Orders?
Giả sử chúng ta KHÔNG dùng bảng outbox và chỉ dùng mỗi bảng orders. Để "nhân viên bưu tá" (tiến trình chạy ngầm) biết cần gửi cái gì lên Kafka, nó phải phân biệt được đơn hàng nào chưa được gửi.
Cách duy nhất là chúng ta phải thêm một cột đánh dấu vào bảng orders, ví dụ: is_sent_to_kafka = false. Mỗi khi gửi xong, tiến trình ngầm phải cập nhật lại thành true.
Cách làm này sẽ gặp hai rào cản lớn:
-
Trộn lẫn trách nhiệm (Single Responsibility): Bảng orders sinh ra để phục vụ nghiệp vụ (trạng thái: chờ duyệt, đã thanh toán...). Nó không nên gánh thêm thông tin về hạ tầng kỹ thuật như "tin nhắn này đã lên Kafka chưa".
-
Khó quản lý nhiều loại sự kiện: Một giao dịch đơn hàng có thể sinh ra nhiều sự kiện khác nhau theo thời gian (VD: OrderCreated, rồi sau đó là OrderPaid, OrderCancelled). Rất khó để nhồi nhét lịch sử hàng loạt sự kiện này chỉ bằng việc thêm cột vào bảng orders.
Nhưng rào cản nghiêm trọng nhất trên môi trường production là Hiệu năng (Performance).
Hãy tưởng tượng sau một thời gian, bảng orders phình to lên hàng triệu dòng. Tiến trình ngầm cứ mỗi giây lại phải quét qua bảng khổng lồ đó (dùng lệnh SELECT * FROM orders WHERE is_sent_to_kafka = false) để tìm sự kiện mới. Việc này sẽ vắt kiệt tài nguyên của Database.
Ngược lại, bảng outbox được thiết kế thuần túy như một hàng đợi (queue) trung gian. Sau khi tiến trình ngầm đọc một sự kiện từ bảng outbox và đẩy thành công lên Kafka, ta sẽ xóa luôn dòng dữ liệu đó (hoặc chuyển sang một bảng lưu trữ lịch sử riêng) để giữ cho bảng outbox luôn nhẹ và truy vấn nhanh.
2. Dead Letter Queue (DLQ)
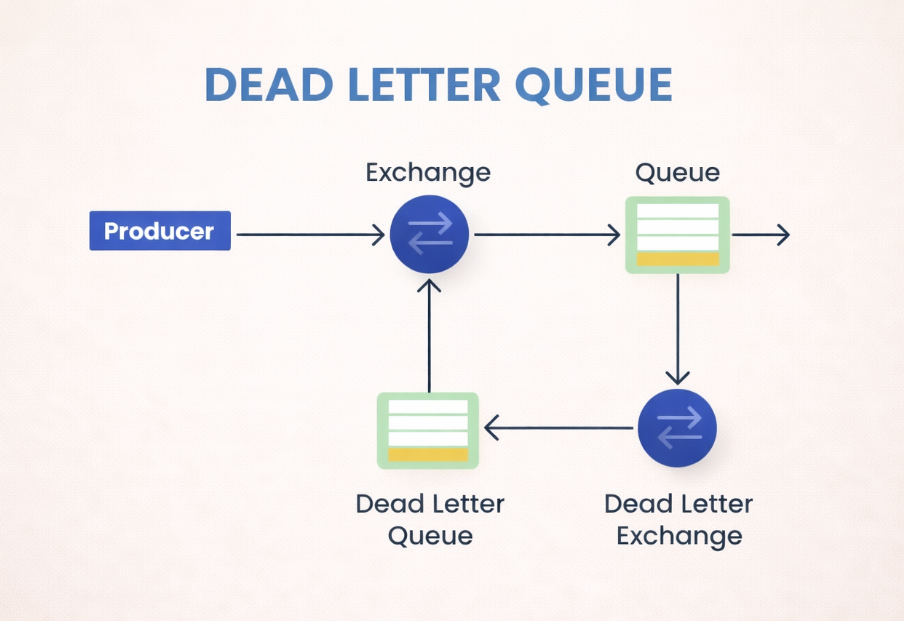
Chúng ta đã có 4 nội dung rất thực chiến. Mảnh ghép cuối cùng mà chúng ta nhắc tới trước đó là Dead Letter Queue (DLQ)
Giả sử trong luồng Saga, lệnh hoàn tác (ví dụ: cộng lại số lượng vào kho) đã được hệ thống tự động thử lại (retry) tới 5 lần, nhưng Database của kho bị sập nguồn hoàn toàn.
Theo bạn, thay vì cứ để hệ thống tự động retry vô tận và làm kẹt cứng các luồng xử lý khác, chúng ta nên chuyển thông tin của giao dịch lỗi này đi đâu và thiết kế thế nào để con người (đội vận hành) có thể phát hiện và can thiệp thủ công?
Có thể nói, đây chính là lúc máy móc phải "đầu hàng" và cần đến bàn tay con người. Hãy tưởng tượng Dead Letter Queue (DLQ) ☠️ giống như phòng "Thư thất lạc" của bưu điện. Khi bưu tá (hệ thống) cố gắng giao một bưu kiện (lệnh hoàn tác) đến một địa chỉ (Database Inventory) quá 5 lần mà nhà vẫn khóa trái cửa, bưu tá không thể đứng chờ mãi, cũng tuyệt đối không được phép vứt bưu kiện đi. Họ sẽ mang nó về cất vào phòng "Thư thất lạc" (DLQ).
Áp dụng vào Saga Pattern trên Production:
-
Khi lệnh Compensating (ví dụ: Cộng_Lại_Kho_Đơn_123) đã retry thất bại đến giới hạn (ví dụ: do Database kho sập hoàn toàn).
-
Hệ thống sẽ lấy thông điệp đó ra khỏi hàng đợi chính (để không làm kẹt các giao dịch của người khác) và ném vào một hàng đợi đặc biệt dành riêng cho các "ca khó đẻ" này: chính là DLQ.
Lúc này, toàn bộ hệ thống vẫn chạy trơn tru, nhưng riêng giao dịch #123 đang ở trạng thái "Lấp lửng" (Inconsistent): Đơn hàng của khách đã bị hủy, nhưng số lượng áo trong kho thì vẫn chưa được cộng lại.
Ngay khi có một thông điệp rơi vào DLQ, hệ thống sẽ kích hoạt Alert (báo động qua Slack, Telegram hoặc SMS) để gọi đội Vận hành (Operations Team) vào can thiệp thủ công (ví dụ: chạy một lệnh SQL bằng tay để sửa lại số tồn kho).
Nhưng để đội Vận hành không phải "mò kim đáy bể" lúc 2 giờ sáng, theo bạn: Trước khi ném thông điệp lỗi này vào DLQ, hệ thống nên "đóng gói" kèm theo những thông tin quan trọng sau vào thông điệp để giúp Dev nhìn vào là hiểu ngay chuyện gì đã xảy ra và phải cần sửa ở đâu:
-
Correlation ID (hoặc Saga ID): 🔗 Định danh duy nhất của toàn bộ luồng giao dịch (VD: Saga_Order_123). Đây là chìa khóa để kỹ sư dùng các tool như Jaeger hoặc Kibana tra cứu xem các service khác (Payment, Shipping) đang mắc kẹt ở trạng thái nào.
-
Original Payload (Dữ liệu gốc): 📦 Toàn bộ nội dung của thông điệp ban đầu (VD: {"order_id": 123, "item": "Áo thun", "qty": 1}). Không có thông tin này, người kỹ sư sẽ không biết cần cộng lại chính xác bao nhiêu món hàng vào kho bằng tay.
-
Chi tiết lỗi (Error Details & Stacktrace): ⚠️ Nguyên nhân cụ thể khiến việc retry chạm giới hạn (VD: ConnectionTimeoutException khi gọi vào Database Inventory).
-
Tên bước bị gãy (Failed Step): 📍 Điểm chính xác mà luồng hoàn tác bị dừng lại (VD: Compensate_Inventory_Step).
-
Lịch sử Retry (Retry Count & Timestamps): ⏱️ Thời điểm thông điệp rớt vào DLQ và số lần đã thử lại. Thông tin này giúp kỹ sư đối chiếu với các biểu đồ giám sát (như Grafana/Prometheus) để xem lúc đó hệ thống có đang chịu tải cao hay sập mạng cục bộ hay không.
Khi có đủ bộ thông tin này, người quản trị hay vận hành có thể dễ dàng chạy một script nhỏ để sửa dữ liệu, hoặc sau khi hệ thống ổn định lại, họ có thể ấn nút "Replay" (chạy lại) chính thông điệp đó từ DLQ vào hàng đợi chính để hệ thống tự động xử lý nốt.
7. Tổng kết: Không có "viên đạn bạc" trong hệ thống phân tán
Nhìn lại toàn bộ bức tranh, chúng ta có thể thấy rõ ràng: Saga Pattern tuyệt đối không phải là một phép màu đơn giản để thay thế lệnh ROLLBACK như các bài tutorial vẫn thường tô vẽ. Nó là một sự đánh đổi khốc liệt. Chúng ta chấp nhận hy sinh Tính nhất quán tức thì (Strong Consistency) để đổi lấy Khả năng mở rộng (Scalability) và Hiệu năng.
Và cái giá phải trả chính là sự phức tạp tột độ trong khâu thiết kế. Áp dụng Saga lên Production đồng nghĩa với việc bạn phải lập trình phòng thủ (defensive programming) ở mọi ngóc ngách:
-
Phải kìm cương Orchestrator để nó không phình to thành một "God Service".
-
Phải tự xây dựng Semantic Lock ở tầng nghiệp vụ để che đậy lỗ hổng thiếu hụt Isolation (Dirty Read).
-
Phải ép Database làm người gác đền cho Idempotency để chống lại ác mộng trừ tiền đúp khi có Race Condition.
-
Phải dùng Transactional Outbox để vá lỗi mất đồng bộ dữ liệu (Dual-Write) khi mạng chập chờn.
-
Và cuối cùng, phải luôn có Dead Letter Queue (DLQ) làm trạm cứu hộ để máy móc nhường quyền can thiệp cho con người khi mọi nỗ lực bù trừ đều thất bại.
Saga Pattern rất mạnh mẽ, và gần như là con đường bắt buộc trong thế giới Microservices. Nhưng nó chỉ thực sự an toàn khi nằm trong tay một đội ngũ hiểu rõ những "ác mộng" đang rình rập bên dưới mặt nước. Đừng bao giờ thiết kế kiến trúc dựa trên "happy path". Hãy luôn thiết kế với tâm thế: "Nếu ngay lúc này máy chủ sập nguồn thì sao?", "Nếu message này bị Kafka gửi lại 3 lần thì sao?".
Còn bạn thì sao? Trong dự án thực tế của mình, bạn đã từng nếm trải "ác mộng" nào khi chia nhỏ database và áp dụng Saga Pattern chưa? Giữa Choreography và Orchestration, team bạn đã chọn mô hình nào và đâu là điểm bùng phát buộc các bạn phải thay đổi kiến trúc? Hãy cùng chia sẻ những câu chuyện "đẫm máu" trên Production của bạn ở phần bình luận nhé!
All rights reserved
