Rút ngắn thời gian train model với TPU
Bài đăng này đã không được cập nhật trong 6 năm
Đặt vấn đề
Mình thường sử dụng nền tảng Google Colab và Kaggle để tận dụng GPU miễn phí, đây là 2 nền tảng tuyệt vời cho cá nhân hoặc các nhóm nghiên cứu nhỏ. Một vấn đề: mỗi lần request một máy ảo GPU, chúng ta thường nhận được con K80, thỉnh thoảng vớ được con T4... hên lắm thì được con P100. Mà dùng con K80 train thì lâu dã man, vẫn biết là có em K80 thì còn tốt hơn không có =)), nhưng có cách nào tốt hơn không.
- Cách 1: Chúng ta chơi trò test nhân phẩm: Các bạn reset factory trên colab tới khi nào nhận được con GPU xịn thì bắt đầu train. Bạn kiên trì làm là sẽ được, nhưng mình không thích cách này lắm =))
- Cách 2: Sử dụng TPU để train thay vì GPU, trên Colab chúng ta sẽ có TPU phiên bản v2, trên Kaggle chúng ta sẽ có TPU phiên bản v3
Trong bài viết này, chúng ta sẽ :
- Tìm hiểu về TPU: vài nét về cấu tạo, cách hoạt động
- Thử train một số model và so sánh thời gian train TPU với GPU
TPU là gì

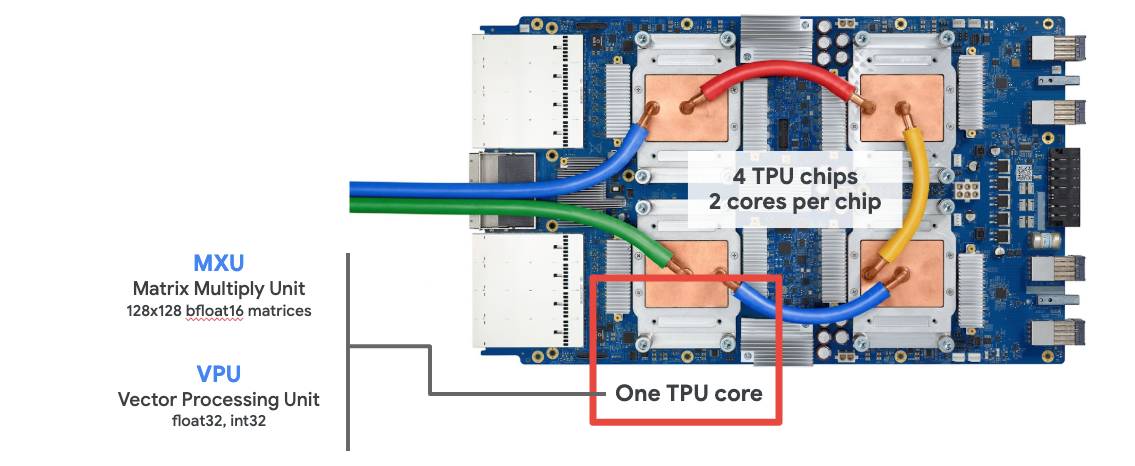
Hình ảnh của một TPU board
Một TPU là một mạch tích hợp dùng riêng cho các ứng dụng AI, được Google phát triển với mục đích:
- Tạo ra phần cứng cho ứng dụng AI với giá thành rẻ
- Tăng tốc độ train và inference
- Tiết kiệm năng lượng
Cấu tạo của một TPU core
Một core của TPU gồm hai thành phần chính là MXU and VPU.
- MXU (Matrix Multiply Unit) là thành phần thực hiện các phép nhân ma trận
- VPU (Vector Processing Unit) là thành phần thực hiện các task như activations, softmax ...
Cách MXU thực hiện phép nhân
Chúng ta quan sát hình mô tả dưới đây:
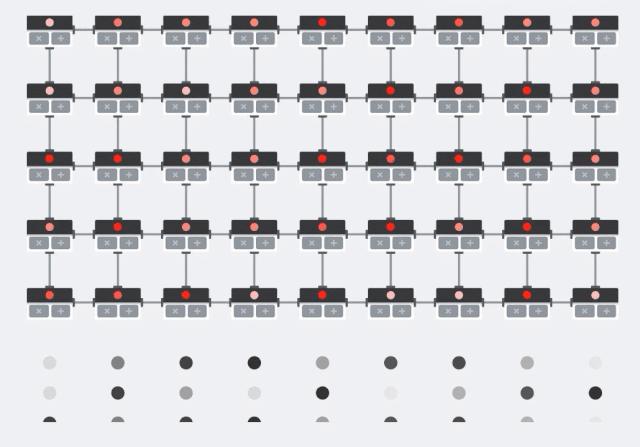
Giả sử, chúng ta cần thực hiện phép nhân ma trận Y = X*W . Kết quả của một phần tử trong phép nhân trên sẽ là:
Y[i, k] = X[i, 0]*W[0, k] + X[i, 1]*W[1, k] + X[i, 2]*W[2, k] + ... + X[i, n]*W[n, k]
Các phần tử trong X sẽ được load vào vị trí các điểm màu đỏ, còn các phần tử trong W sẽ được load vào vị trí các điểm màu xám. Việc load dữ liệu này được mô tả trong hình vẽ trên là các điểm lần lượt di chuyển theo hàng dọc từ dưới lên trên. Tại mỗi nút thực hiện phép tính của MXU, sau khi load đủ dữ liệu tại nút đó, phép nhân được thực hiện, giá trị của phép nhân này sẽ được nút lân cận sử dụng để tính tổng tạm thời. Giá trị tổng tạm thời đó như dòng chảy từ trái qua phải giữa các nút nên không cần thêm một biến trung gian hay bộ nhớ tạm thời nào khác. Cấu trúc của MXU này được gọi là Systolic array. Nhờ vào cấu trúc này, TPU có tốc độ thực hiện phép tính cao và tiết kiệm năng lượng.
Cloud TPU
Khi bạn request một service Cloud TPU v2, bạn sẽ nhận được một máy ảo connect với một TPU board. Một TPU board có 4 core và mỗi core có một VPU và một MXU (128x128) . Khi sử dụng TPU trên colab, chúng ta sẽ nhận được cấu hình TPU tương đương vậy.

Note:
- Khi thuê TPU trên GCP chúng ta sẽ mất 4.5$ cho mỗi giờ trong khi sử dụng TPU trên colab là miễn phí :v
- Để tối ưu thời gian trainning, các bạn nên sử dụng data pipline của tensorflow. Bởi vì tốc độ thực hiện của TPU là rất nhanh, nếu chúng ta cấp data không đủ nhanh thì cũng như tạo một nút thắt tại đầu vào trước mỗi epoch.
- Mỗi TPU board có 8 core nên khi train các bạn lấy BATCH_SIZE = batch_size(bình thường vẫn chọn) nhân với 8 thì sẽ tối ưu việc sử dụng TPU
Sử dụng TPU trên Colab
Cách cấu hình để sử dụng TPU
Việc sử dụng TPU Colab để train cho các mô hình tensorflow 2 hay keras rất đơn giản, có 2 phần chính cần thêm trong code:
Detect TPU và config tensorflow:
# detect the TPU
tpu = tf.distribute.cluster_resolver.TPUClusterResolver() # tìm thông tin TPU
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
Khởi tạo model và fit dữ liệu:
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Note:
- HIện tại, TPU chỉ hỗ trợ các kiểu dữ liệu: tf.float32, tf.int32, tf.bfloat16, tf.bool. Vậy nên các bạn cần format data về các định dạng đó trước khi train
- Cloud TPU chỉ hỗ trợ load file input từ cloud storage. Tức là, nếu bạn tải dữ liệu về máy ảo của bạn rồi thực hiện load input thì sẽ có lỗi xảy ra. Đây là một điều khá bất tiện, vì như vậy chúng ta cũng không thể tận dụng kho dữ liệu từ google driver. Nhưng không sao, chúng ta đăng kí một tài khoản của Google Cloud và nhận được 300$ miễn phí sử dụng dịch vụ trong 1 năm và miễn phí 5G lưu trữ cloud storage (Méo mó có vẫn hơn không mà
 )
)
Ví dụ train model với TPU
Để thử nghiệm nhanh việc sử dụng TPU trên colab, mình sẽ sử dụng bộ data "Flowers " public trên Google Storage.
Đường dẫn data: gs://flowers-public/tfrecords-jpeg-192x192-2/
Bộ data có 5 nhãn:
- Daisy
- Dandelion
- Roses
- Sunflowers
- Tulips
 Tiếp theo, mình lần lượt train dữ liệu với 4 model khác nhau và thực hiện train với các phần cứng TPU, K80, T4, P100. Thời gian train cho 25 epochs sẽ được ghi lại để làm kết quả so sánh.
Các model dùng trong thử nghiệm:
Tiếp theo, mình lần lượt train dữ liệu với 4 model khác nhau và thực hiện train với các phần cứng TPU, K80, T4, P100. Thời gian train cho 25 epochs sẽ được ghi lại để làm kết quả so sánh.
Các model dùng trong thử nghiệm:
- Custom model: 78,263 params
- Custom VGG19: 112,327,749 params
- Custom Xception: 20,871,725 params
- Custom Resnet: 58,341,893 params
Ví dụ với custom VGG19:
Các bạn có thể tham khảo source: https://colab.research.google.com/drive/1gQJ-M2ocLjr9Utnqzt279KezN6jdCijJ?usp=sharing
Khởi tạo model:
with strategy.scope():
model = tf.keras.applications.VGG19(weights=None, input_shape=[*IMAGE_SIZE, 3], classes=5)
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
Sau khi chạy đoạn code trên, ta thu được model với tổng 112,327,749 params. Tiến hành trainning nào:
from time import process_time, time
EPOCHS = 25
t1_start = time()
history = model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, verbose=True)
t1_stop = time()
print("Elapsed time during the whole program in seconds model", t1_stop-t1_start)
Mình thực hiện train với 25 epochs và đo tổng thời gian của quá trình fit, kết quả là:
Epoch 1/25
23/23 [==============================] - 14s 619ms/step - accuracy: 0.2364 - loss: 1.6089 - val_accuracy: 0.2406 - val_loss: 1.5989
Epoch 2/25
23/23 [==============================] - 4s 171ms/step - accuracy: 0.2456 - loss: 1.6020 - val_accuracy: 0.2406 - val_loss: 1.6002
Epoch 3/25
23/23 [==============================] - 4s 177ms/step - accuracy: 0.2446 - loss: 1.6018 - val_accuracy: 0.2406 - val_loss: 1.6000
Epoch 4/25
23/23 [==============================] - 4s 172ms/step - accuracy: 0.2459 - loss: 1.6012 - val_accuracy: 0.2406 - val_loss: 1.6001
Epoch 5/25
23/23 [==============================] - 4s 171ms/step - accuracy: 0.2452 - loss: 1.6013 - val_accuracy: 0.2406 - val_loss: 1.6001
Thực sự "phê", như các bạn thấy, thời gian cho epoch đầu tiên là ~14s, thời gian cho các epochs sau là ~4s , tổng thời gian train sau 25 epochs là 127,82s (hơn 2 phút). Trong khi sử dụng K80 trên colab, thời gian cho mỗi epochs ~74s và tổng thời gian train là 1866.703s (hơn 30 phút)
So sánh thời gian train giữa TPU-K80-T4-P100
1: Trong thử nghiệm này, mình sẽ train các model trên TPU và GPU với cùng điều kiện dữ liệu, batch size = 32 với 25 epochs. Thực chất để batch size như vậy thì hơi thiệt thòi cho TPU vì như vậy 8 core của TPU sẽ không được sử dụng hết. Nhưng để batch size lớn hơn thì máy GPU thường xuất hiện lỗi OOM (Out of memory) =))
| TPUv2 | K80 | T4 | P100 | |
|---|---|---|---|---|
| Custom | 90.5885 | 205.77 | 113.49 | 72.94 |
| VGG19 | 213.0066 | 1866.703 | 947.92 | 510.689 |
| Xception | 211.558 | 2188.83 | 1053.5027 | 683.13 |
| ResNet152V2 | 532.368 | 2997.055 | 1362.987 | 813.402 |
Bảng 1: Thời gian train một số model (giây)
2: Lần này, mình cho TPU được bung lụa, trên máy TPU mình set batch size = 128, các máy GPU vẫn giữ nguyên và thực hiện train lại
| TPUv2 | K80 | T4 | P100 | |
|---|---|---|---|---|
| Custom | 67.78s | 205.77 | 113.49 | 72.94 |
| VGG19 | 127,82 | 1866.703 | 947.92 | 510.689 |
| Xception | 132.0539 | 2188.83 | 1053.5027 | 683.13 |
| ResNet152V2 | 295.56 | 2997.055 | 1362.987 | 813.402 |
Bảng 2: Thời gian train một số model (giây)
Nhận xét
- Thời gian train trên máy TPU rút ngắn một cách rõ rệt so với K80 và T4
- Khi kích thước model nhỏ, sự chênh lệch thời gian train giữa máy TPU và P100 là không nhiều, thậm chí TPU sẽ chậm hơn P100 một chút như trong Bảng 1
- Khi kích thước model lớn hơn, TPU thể hiện được sức mạnh rõ rệt, thời gian train trên TPU nhanh hơn so với P100 thường nhanh hơn khoảng 1.5 - 2 lần tùy vào kiến trúc model (Sự so sánh này không hoàn hảo do còn phụ thuộc nhiều yếu tố như memory , batch size...)
Tổng kết
Trên đây chúng ta đã đi tìm hiểu về TPU và cách sử dụng TPU trên Colab. Hi vọng bài viết đem lại một số thông tin hữu ích cho các bạn. Cảm ơn mọi người đã đọc bài!
All rights reserved
