Restricted Boltzmann machine - An overview
Bài đăng này đã không được cập nhật trong 4 năm
Restricted Boltzmann machine
Restricted Boltzmann machine(RBM) is an algorithm, useful for dimensionality reduction, classification, regression, collaborative filtering, feature learning and topic modeling. RBMs are probabilistic graphical models that can be interpreted as stochastic neural networks. They have attracted much attention as building blocks for the multi-layer learning system called deep belief nets(DBNs). In recent years, models extending or borrowing concepts from RBM have experienced much popularity for pattern analysis and generation with application including image classification, processing and generation.
It has been successfully applied to problems involving high dimensional data such as images. In this context, two approaches are usually followed. First, an RBM is trained in an unsupervised manner to model the distributions of the inputs (possibly more than one RBM could be trained, stacking them on top of each other). Then the RBM is used in one of the two ways: either its hidden layer is used to preprocess the input data by replacing it with the representation given by the hidden layer or the parameters of the RBM are used to initialize a feed-forward neural network. In both cases, RBM is paired with some other learning algorithm to solve the supervised learning problem.
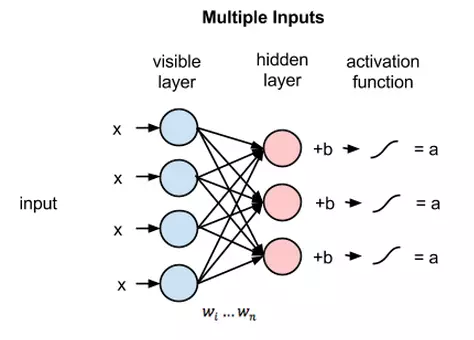
In Boltzmann machines, two types of units can be distinguished. They have visible neurons and potentially hidden neurons. RBMs always have both types of units, and these can be thought of as being arranged in two layers. The visible units constitute the first layer and correspond to the components of an observation (e.g., one visible unit for each pixel of a digital input image). The hidden units model dependencies between the components of observations (e.g., dependencies between the pixels in the images).
Each visible node takes a low-level feature from an item in the dataset to be learned. For example, from a dataset of grayscale images, each visible node would receive one pixel-value for each pixel in one image. MNIST images have 784 pixels, so neural networks processing them must have 784 input nodes on the input layer.
Application: DBNs are an emerging application in the machine learning domain, which use Restricted Boltzmann Machines (RBMs) as their basic building block. Although small scale DBNs have shown great potential, the computational cost of RBM training has been a major challenge in scaling to large networks.
A DBN is a multilayer generative model that is trained to extract the essential features of the input data by maximizing the likelihood of its training data. DBNs have recently gained great popularity in the machine learning community due to their potential in solving previously difficult learning problems. DBNs use Restricted Boltzmann Machines (RBMs) to efficiently train each layer of a deep network. DBNs have been successfully demonstrated in various applications, such as handwritten digit recognition and human motion modeling.
The Restricted Boltzmann Machine is the key component of DBN processing, where the vast majority of the computation takes place.
RBM Training : RBMs are probabilistic generative models that are able to automatically extract features of their input data using a completely unsupervised learning algorithm. RBMs consist of a layer of hidden and a layer of visible neurons with connection strengths between hidden and visible neurons represented by an array of weights. To train an RBM, samples from a training set are used as input to the RBM through the visible neurons, and then the network alternatively samples back and forth between the visible and hidden neurons. The goal of training is to learn visible-hidden connection weights and neuron activation biases such that the RBM learns to reconstruct the input data during the phase where it samples the visible neurons from the hidden neurons.
Activity of neuron: The artificial neuron receives one or more inputs and sums them to produce an output (or activation). Usually the sums of each node are weighted, and the sum is passed through a nonlinear function known as an activation function. The activation functions usually have a sigmoid shape, but they may also take the form of other nonlinear functions, piecewise linear functions, threshold or setmax function. They are also often monotonically increasing, continuous, differentiable and bounded.
Basic RBM architecture: In the RBMs network graph, each neuron is connected to all the neurons in the other layer. However, there are no connections between neurons in the same layer, and this restriction gives the RBM its name. Each neuron is a locus of computation that processes input and begins by making some random decisions about whether to transmit that input or not.
Output = activation function((weight w * input x) + bias b)
Here, bias is used to shift(increase or decrease) the net input of activation function. Bias may be either positive or negative. Here, several inputs are combined at one hidden node. Each x is multiplied by its corresponding weight, the products are summed, then added to a bias and again the result is passed through an activation function to produce the node’s output.
If these two layers were part of a deeper neural network, the outputs of hidden layer 1 would be passed as inputs to hidden layer 2, and from there as many hidden layers as we like until they reach a final classifying layer.
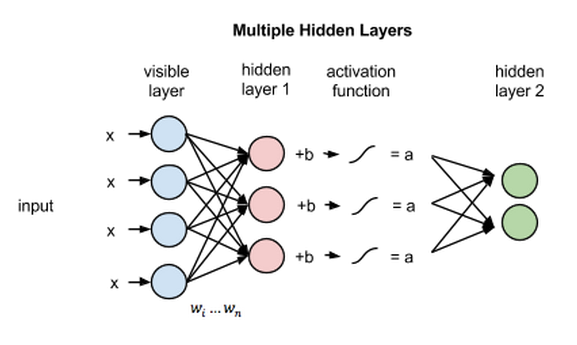
The basic idea underlying these deep architectures is that the hidden neurons of a trained RBM represent relevant features of the observations, and these features can serve as input for another RBM. By stacking RBMs in this way, one can learn features from features in the hope of arriving at a high-level representation.
It is an important property that single as well as stacked RBMs can be re-interpreted as deterministic feed-forward neural networks. When viewed as neural networks they are used as functions mapping the observations to the expectations of the latent variables in the top layer. These can be interpreted as the learned features, which can, for example, serve as inputs for a supervised learning system.
Furthermore, the neural network corresponding to a trained RBM or DBN can be augmented by an output layer where the additional units represent labels (e.g., corresponding to classes) of the observations. Then we have a standard neural network for classification or regression that can be further trained by standard supervised learning algorithms. It has been argued that this initialization (or unsupervised pretraining) of the feed-forward neural network weights based on a generative model helps to overcome some of the problems that have been observed when training multi-layer neural networks.
The graph of an RBM has connections only between the layer of hidden and the layer of visible variables, but not between two variables of the same layer. In terms of probability, this means that the hidden variables are independent given the state of the visible variables and vice versa. Thus, due to the absence of connections between hidden variables, the conditional distributions p(h | v) and p(v | h) factorize nicely.
The conditional independence between the variables in the same layer makes Gibbs sampling easy: instead of sampling new values for all variables subsequently, the states of all variables in one layer can be sampled jointly. Thus, Gibbs sampling can be performed in just two steps: sampling a new step h for the hidden neurons based on p(h | v) and sampling a state v for the visible layer based on p(v | h).
Any distribution on {0, 1}ᵐ can be modeled arbitrarily well by an RBM with m visible and k + 1 hidden units, where k denotes the cardinality of the support set of the target distribution, that is, the number of input elements from {0, 1}ᵐ that have a non-zero probability of being observed. It has been shown recently that even fewer units can be sufficient, depending on the patterns in the support set.
RBMs are shallow, two-layer neural networks that constitute the building blocks of deep-belief networks(DBN). Recent developments have demonstrated the capacity of RBM to be powerful generative models, able to extract useful features from input data or construct deep artificial neural networks. Though Boltzmann machines with unconstrained connectivity have not been proven useful for practical problems in machine learning or inference, but if the connectivity is properly constrained, this learning can be made efficient enough to be useful for practical problems.
All rights reserved
