Replica Set Mongodb
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu

Replica set là một hệ replication trong MongoDB. Database của bạn sẽ được nhân bản trên nhiều server thay vì tập trung trên một single server. Nhờ vậy, replica set cung cấp tính năng high availability và dự phòng cứu nguy cho server của bạn trong nhiều trường hợp mất dữ liệu có thể xảy ra. Mô hình của replica set trong mongodb gần giống replication trong mysql.
Tổng quan
Một replica set chỉ có duy nhất một primary node. Primary node sẽ nhận các write request. Primary node sẽ ghi các thay đổi của nó vào oplog. Các secondary node sẽ được bất đồng bộ từ primary node nên có chung data set với primary node. Read request có thể scale trên primary node và tất cả các secondary node. Một replica set có thể có tối đa là 50 node. Nếu lớn hơn 50 node thì bạn phải dùng giải pháp khác.
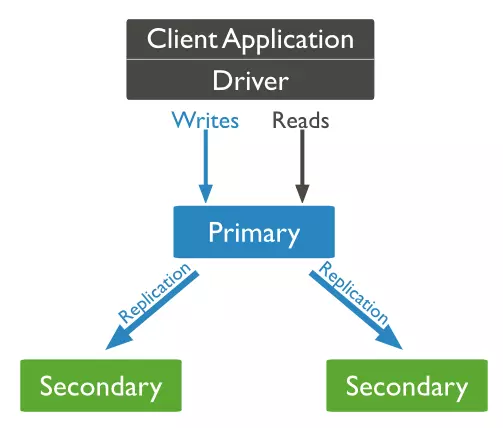
Giữa các node trong replica set luôn duy trì kết nối heartbeat nên khi một node nào đó down các node còn lại sẽ nhận ra luôn và tự động tiến hành failover. Đây là điểm khác biệt so với mysql. Mysql replication thiếu cơ chế để tự động failover ( Trong các phiên bản mysql từ 5.6 thì mysql bắt đầu có thể failover tự động nhưng để thực hiện được, bạn cần sử dụng một node giám sát như mysqlfailover còn trong mongodb thì các node tự giám sát và tự failover )
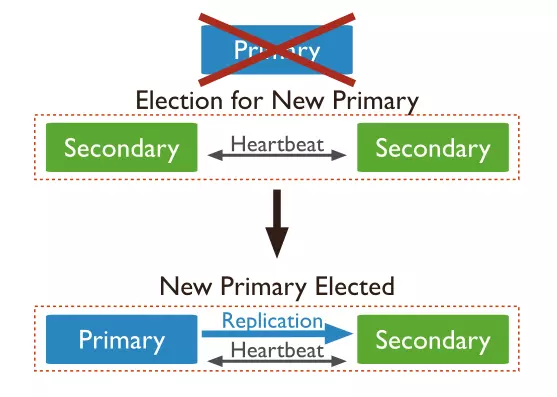
Cơ chế thực hiện failover của replica set là dựa trên voting. Một secondary node sẽ được bầu lên làm primary node của cả replica set. Để voting thành công thì số node trong một replica set phải là số lẻ nếu không sẽ xảy ra trường hợp hai ứng viên đều nhận được số phiếu bầu bằng nhau rốt cục chẳng ai làm primary node cả hoặc có thể dẫn đến tình huống có hai node đều tự nhận là primary node nếu network partition xảy ra.
Tuy vậy, để giảm chi phí đầu tư, bạn có thể chỉ cần hai node trong một replica set. Thành viên thứ ba sẽ là một arbiter. Arbiter là một node đặc biệt. Nó không apply các oplog từ primary node nên nó không lưu data gì cả. Nhiệm vụ của arbiter là giám sát hệ replica set qua các đường liên kết heartbeat và bầu chọn một secondary node lên primary node khi failover. Arbiter hoạt động không có gì nặng nề, bạn không cần server riêng cho arbiter nhưng arbiter không nên được deploy trên server dùng làm primary node hay secondary node trong replica set. Arbiter thì sẽ mãi là arbiter không như primary node có thể down rồi trở thành secondary node khi join lại vào replica set hay secondary node có thể trở thành primary node khi failover xảy ra.
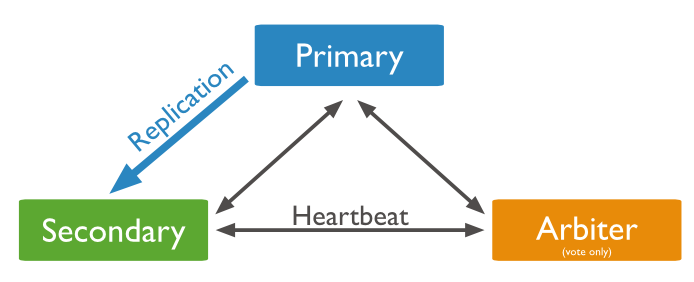
Replication từ primary node về secondary node là bất đồng bộ (asynchronous) do đó writeset có trên primary node sẽ không thể ngay lập tức có trên secondary node. Hệ quả là data set trên secondary node sẽ không phản ánh trạng thái mới nhất của data set trên primary node. Đây là nhược điểm đều có trong mọi hệ thống mà dựa trên replication.
Read preference
Mặc định, driver mongodb sẽ luôn thực hiện read request đến master. Read request chỉ từ primary node gọi là strict consistency với ý nghĩa application sẽ luôn lấy data state mới nhất. Nếu application không yêu cầu luôn trả về phiên bản mới nhất của data thì bạn có thể điều chỉnh read preference của mongodb để scale out read. Read từ secondary node gọi là eventual consistency với ý nghĩa rồi cuối cùng thì thế nào data state trên secondary node cũng đồng nhất với primary node. Read preference có 5 mode tất cả: http://docs.mongodb.org/manual/core/read-preference/#read-preference-modes
- primary node là mặc định, mọi read request sẽ chỉ đi đến primary node
- primary nodePreferred: mọi read request sẽ đi đến primary node nhưng nếu primary node down nó sẽ đi đến secondary node
- secondary node: mọi read request chỉ đi đến các secondary node.
- secondary nodePreferred: mọi read request sẽ đi đến secondary node nhưng nếu tất cả các secondary node down nó sẽ đi đến primary node.
- nearest: read request sẽ đến node có network latency thấp nhất không phân biết node đó là primary node hay secondary node. Tham số read preference bạn sẽ khai báo từ application. Chi tiết tham khảo ở đây: https://docs.mongodb.org/manual/reference/connection-string/
Write concern
Write concern sẽ yêu cầu mongodb xác nhận một write request có thành công hay không. Với replica set, mặc định write concern sẽ chỉ yêu cầu mongodb xác nhận write request trên primary node node. Ở chế độ này, application chỉ có thể biết được write request có thành công hay không trên primary node. Nó không thể biết được liệu write request đó đã được replicate thành công đến các secondary node node hay chưa.
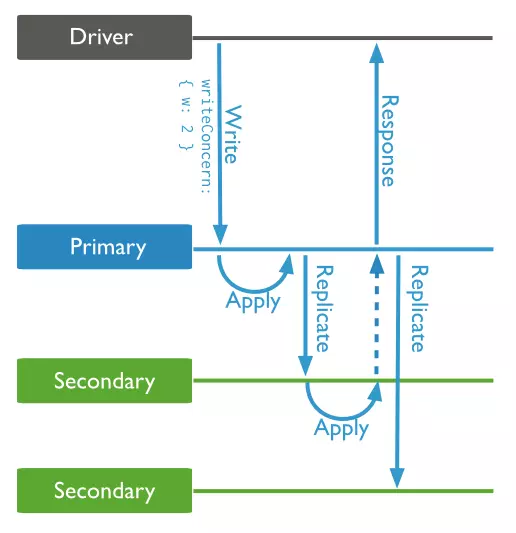
Mongodb cho phép bạn thay đổi hành vi mặc định của write concern. Application có thể lựa chọn thay đổi write concern ngay trong write request. Hành vi write concern thay đổi chỉ áp dụng cho write request này:
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: 2, wtimeout: 5000 } }
)
Write request insert một item vào collection products sẽ được trả về sau khi write request thực hiện trên primary node và ít nhất một secondary node (w: 2) hoặc nếu không có kết quả trả về thì kết thúc trong vòng 5s (wtimeout: 5000). Giá trị wtimeout để tránh cho write request bị block lại quá lâu nếu như không có đủ số nodes mà write concern cần.
Bạn cũng có thể thay đổi hành vi mặc định của write concern trên phạm vi toàn bộ các write request thay vì chỉ từng request như trên:
cfg = rs.conf()
cfg.settings = {}
cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 }
rs.reconfig(cfg)
Cấu hình trên sẽ yêu cầu mongodb trả về kết quả sau khi write request được hoàn thành trên majority node hoặc trả về sau 5s. Majority nodes là phần node chiếm đa số trong một replica set. Ví dụ một replica set có 5 node thì majority node sẽ bao gồm 1 primary node và ít nhất 2 secondary node ( Tổng số sẽ là 3 trên 5 ). Majority trong write concern đề cập sẽ luôn có primary node vì write request luôn đập vào primary node node trước tiên.
Từ vị trí application, nếu bạn không áp dụng write concern đủ thì có thể dẫn đến write set bị mất sau khi failover: Giả sử application dùng write concern mặc định nên kết quả trả về ngay khi primary node xử lý xong write set nhưng có thể vì lý do nào đó, write set đó chưa được replicate sang secondary node. Application không biết điều này. Không may, tại thời điểm đó, primary node down, failover được thực hiện tự động, một secondary node lên làm primary node nhưng secondary node này sẽ không có write set đó. Đó là cách dữ liệu bị mất khi dùng write concern không đầy đủ.
Các loại secondary node node
Priority 0 replica set node
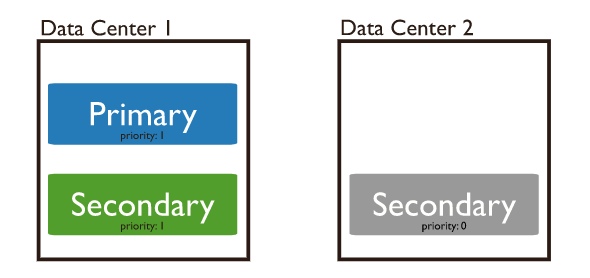
Là một secondary node node không bao giờ có thể trở thành primary node được. Nó cũng không thể trigger một event election nhưng vẫn có thể tham gia vào quá trình voting. Vai trò của priority 0 node giống như một standby node được dùng để thay thế các secondary node node mà bị unavailable. Một trường hợp khác mà priority 0 node được dùng là khi các node có thông số hardware mạnh yếu khác nhau. Những node khỏe mạnh thì có thể được đôn lên làm primary node khi failover. Những node yếu hơn chút thì có thể giữ ở vị trí secondary node node.
Hidden replica set node
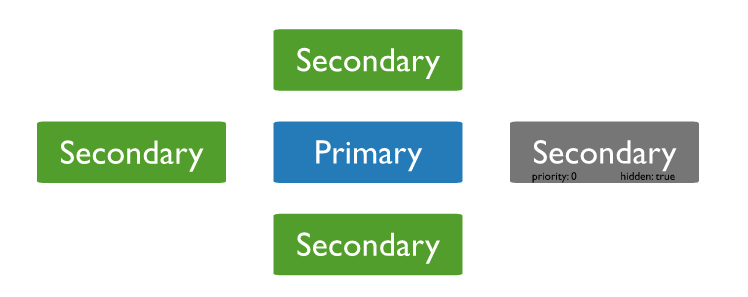
Là một priority 0 node nên nó không thể trở thành primary node nhưng vẫn tham gia vào quá trình voting. Điểm khác biệt là nó hoàn toàn ẩn đi với client. Client sẽ không gửi read request đến hidden node do đó ngoài replication, trên hidden node không còn traffic nào khác. Bạn có thể sử dụng hidden node trong vài trò backup hoặc reporting server. Tuy vậy, sử dụng nó với vai trò backup thì có rủi ro vì nó luôn là một bản sao của primary node. Giả sử, một developer lỡ tay thực hiện remove document khỏi collection trên primary node mà quên không truyền điều kiện vậy là ôi thôi đi tong cả collection. Tệ hơn, một system admin vô ý gõ nhầm drop collection trên primary node. Cả hai tình huống đó, backup trên hidden node không thể cứu vãn được. Đó thực sự là thảm họa.
Delay replica set node
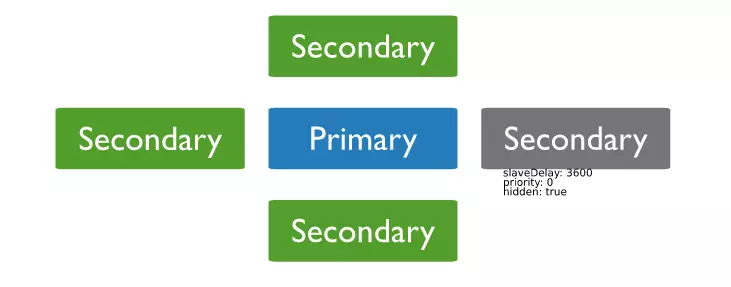
Là một priority 0, hidden node, tham gia vào quá trình voting khi failover. Đây là loại node sẽ giải quyết hai tình huống mà hidden node bó tay ở trên. Delay node cũng replicate data từ oplog của primary node như các secondary node khác nhưng có khác một chút là data set của delay node luôn cũ hơn của primary node một khoảng thời gian nhất định. Khoảng thời gian này gọi là slaveDelay có thể cấu hình được. Như vậy, nếu một sự cố vô ý mất dữ liệu do thao tác sai lúc 9h sáng thì chúng ta vẫn còn data set nguyên vẹn của thời điểm 8h sáng ( nếu slaveDelay là 3600s ). Tuy lượng data backup bị hụt đi so với data hiện tại khoảng gần 1 tiếng nhưng dù sao khi sự cố xảy ra bạn cũng không mất hết. Delay node có ưu việt hơn hidden node không ? Tôi nghĩ là không. Mỗi loại node giải quyết một bài toán khác nhau. Nếu tình huống là primary node bị hỏng ổ cứng, kernel panic... thì hidden node tỏ ra ưu việt hơn delay node khi vẫn giữ được gần như toàn bộ data set.
All rights reserved
