Reindex Elasticsearch data with zero downtime
Bài đăng này đã không được cập nhật trong 5 năm
Elasticsearch là một search engine tuyệt vời cho mọi dự án muốn áp dụng chức năng search cho sản phẩm của mình, với những tính năng như là near-realtime search, auto-complete, suggestion,.... Cùng với đó là lợi thế kiến trúc distributed search system, có thể dễ dàng scaling, failing handle.
Thế nhưng cùng với những tính năng mạnh mẽ của mình, thì Elasticsearch cũng có một số điểm mà chúng ta phải đánh đổi để sử dụng nó có thể kể đến như: index một khi đã đi vào hoạt động và có nhiều document thì không thể thay đổi kiểu dữ liệu của một field nào, khó có thể thay đổi cấu trúc cũng như số shards trong trường hợp chúng ta muốn tối ưu hóa tối đa hệ thống của mình.
Khi muốn làm một trong những điều trên, cách duy nhất chúng ta có thể thực hiện đó là reindex toàn bộ dữ liệu của mình sang một index mới. Điều trên hoàn toàn có thể dễ thực hiện với một lượng data nhỏ không đáng kể, nhưng nếu hệ thống của bạn hoạt động trên môi trường production và có một lượng lớn dữ liệu text search ~ hơn 100MiB và vào khoảng 1 triệu documents thì lúc đó việc reindex dữ liệu từ các cơ sở dữ liệu quan hệ sang ES, hay thậm chí reindex trực tiếp từ ES cũng là một thử thách lớn.
Vậy trong bài viết này, chúng ta hãy cùng nhau đi tìm hiểu một phương pháp "reindex không thời gian chết" (zero-downtime), bài viết được tham khảo tại: https://medium.com/craftsmenltd/rebuild-elasticsearch-index-without-downtime-168363829ea4.
Bắt buộc phải sử dụng index alias cho hệ thống của bạn
Việc đầu tiên và là điều kiện tiên quyết giúp cho quá trình reindex trở nên nhẹ nhàng đó là việc sử dụng alias, nếu bạn chưa biết về alias có thể tham khảo tại đây.
Nói đơn giản thì alias là một tên gọi khác của index của bạn. Vậy tại sao chúng ta phải sử dụng alias, index name có vẻ như là đủ rồi mà?
- Trong cùng một cluster thì khi bạn đặt tên cho index của mình thì tên đó sẽ không được sử dụng lại được nữa, nếu muốn sử dụng lại index name đó thì việc duy nhất có thể làm là build một cluster khác rồi chuyển dữ liệu sang -> rất tốn kém.
- Nếu chỉ dùng index name mỗi khi chúng ta build lại index ta phải đặt cho nó một cái tên mới, ví dụ:
# old index
article_ver1.0
# new index
article_ver1.1
và cùng với đó mỗi lần như vậy chúng ta lại phải cập nhật lại code sử dụng index name mới, đồng thời việc chỉ nhìn vào index name rất khó quản lý, chúng ta đôi khi sẽ bị loạn không biết index nào đang được sử dụng, index nào không.
- Khi dùng alias, chúng ta có thể đặt tên chung nhất cho nó và trỏ vào index name mà ta mong muốn (index name lúc này hoàn toàn có thể kèm theo yếu tố version hay timestamp để biết phiên bản hiện tại), ví dụ với kibana dev tool:
# GET _aliases
{
"article_ver1.0": {
"aliases": {
"article_production": {}
}
}
}
- Khi chúng ta dựng lại một index mới
article_ver1.1để tối ưuarticle_ver1.0, việc duy nhất chúng ta cần làm đó là trỏ lại alias vào index name mới, trong code chúng ta chỉ giữ nguyên index là tên của alias (article_production).
POST /_aliases
{
"actions" : [
{ "remove" : { "index" : "article_ver1.0", "alias" : "article_production" } },
{ "add" : { "index" : "article_ver1.1", "alias" : "article_production" } }
]
}
Vì vậy, chúng ta sẽ sử dụng alias name để giao tiếp giữa application và ES, alias sẽ trỏ vào index cũ trong quá trình rebuild index mới. Sau khi việc reindex được thực hiện xong, chúng ta sẽ trỏ lại alias vào index mới và có thể sử dụng index mới bình thường mà không phải setting lại cho application.
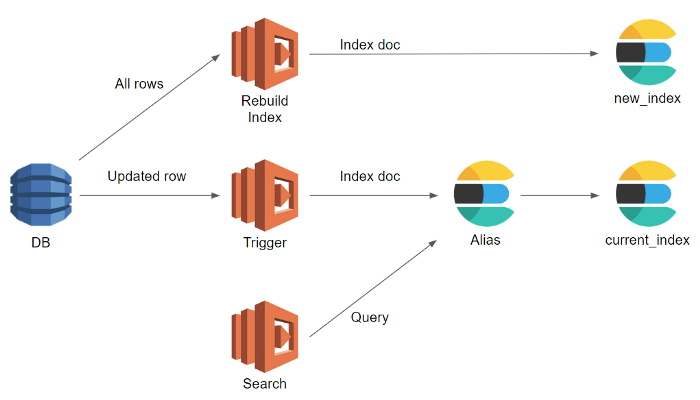
Sơ đồ tham khảo sử dụng AWS service, thay đổi trong DB sẽ được update lên index cũ, việc search vẫn được thực hiện bình thường qua index cũ, index mới được rebuild trong quá trình này
Không nên sử dụng _reindex API
Mặc dù ES đã cung cấp sẵn cho chúng ta tính năng reindex, nhưng chúng ta không nên sử dụng nó để làm công cụ reindex dữ liệu. Bản thân mình cũng đã tưởng tượng là nó sẽ tốt hơn nhiều việc tự dựng cơ chế reindex vì nó là đồ built-in mà.
Thế nhưng bản chất của _reindex API chỉ là cung cấp cho chúng ta một bản snapshot tại thời điểm chúng ta call API và reindex nó vào index mới, nó có 2 nhược điểm:
- index mới có thể sẽ require những dữ liệu mà index cũ không có.
- Việc chụp snapshot tại thời điểm call API không đảm bảo cho chúng ta việc dữ liệu ở index mới sẽ là up-to-date so với index cũ, vì trong quá trình reindex (with zero-downtime) thì dữ liệu sẽ được update liên tục ở index cũ, vì vậy sau khi reindex xong switch sang index mới dữ liệu mới được cập nhật sẽ mất hết.
Tất nhiên với việc sử dụng hệ thống tham khảo trong sơ đồ bên trên, index mới cũng sẽ không có những data mới được cập nhật (do việc update vẫn update vào index cũ), vì vậy chúng ta phải chỉnh sửa hệ thống chúng ta thêm chút nữa để có data up-to-date.
Update data vào index trong khi reindex
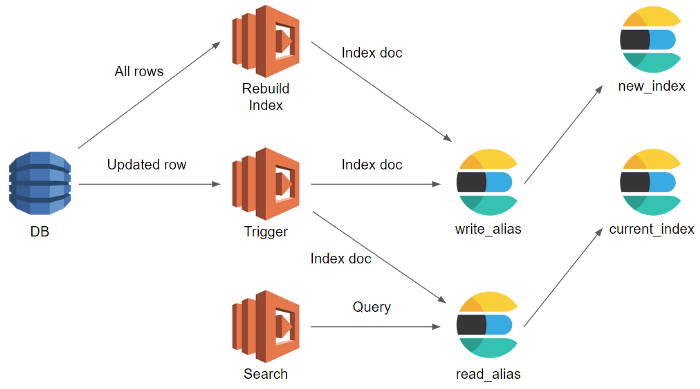
Ở sơ đồ hệ thống trên, chúng ta có thể thấy sự có mặt của 2 alias, một dùng để write, một dùng để read.
- Việc reindex được thực hiện ở index mới.
- Khi có dữ liệu thay đổi ở DB, nó sẽ được update vào cả index cũ và index mới.
- Việc đọc dữ liệu vẫn ở index cũ.
- Sau khi việc reindex được thực hiện xong, chúng ta sẽ trỏ read index vào index mới -> cùng lúc để đọc và ghi dữ liệu, lúc này dữ liệu đã bao gồm dữ liệu được index lại với cấu trúc mới, đồng thời những dữ liệu cũ sử dụng lại từ index cũ cũng được up-to-date.
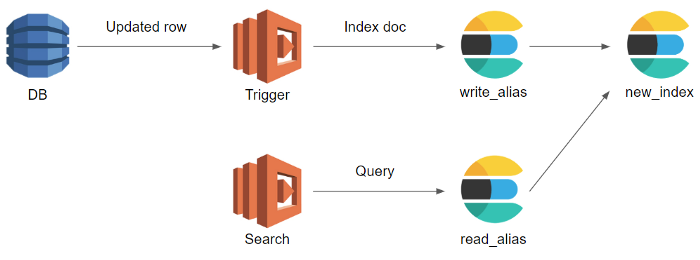
Trong sơ đồ tham khảo ở bài viết (link tham khảo ở trên), chúng ta cũng có thể thấy việc sử dụng thêm một alias mới dùng để ghi cũng là một phương pháp tránh để phải sửa code giữa các lần dựng index mới.
Áp dụng với ứng dụng chạy Rails và gem searchkick
Gần đây trong một số dự án mình tham gia cũng đã gặp phải vài issue liên quan đến performance, đại khái là đều chưa tối ưu index, kiểu dữ liệu của index và mong muốn của các dự án là cũng muốn reindex no downtime mặc dù lượng dữ liệu không phải là nhỏ.
Đối với một dự án Rails sử dụng gem searchkick, mình cũng thử demo một quá trình reindex no downtime và cũng đã thành công. Cách làm của mình sử dụng chủ yếu việc overwrite lại code và một số setting, không require phải xây dựng nhiều code lambda chạy bằng cách trigger event của AWS nên sẽ không phải tăng spec resource quá nhiều. Nhưng nếu là dự án có lượng dữ liệu lớn và có thể sẽ phải thay đổi nhiều về index thì recommend là vẫn nên xây dựng một hệ thống reindex chuẩn như trong bài viết tham khảo bên trên.
Nếu có dịp mình sẽ update chi tiết cách thực hiện ở bài viết sau với chi tiết code demo.
All rights reserved
