Regular Expression
Bài đăng này đã không được cập nhật trong 6 năm
1. Regular Expression là gì:
- Regular Express là các pattern mô tả cấc trúc hoặc nội dung của string.
- Ví dụ
/\s/ # any whitespace /\d/ # any digit /\w/ # any word - Trong các thư viện của Ruby và Rails có cung cấp sẵn 1 số Regular Express như
URI::Regexp Devise.email_regexp - Regular Express thường được dùng để extract data từ string và sử dụng cho các mục đích khác nhau.
- Ví dụ: validation email, url, ....
- Một số trang web hay về Ruby Regular Express như.
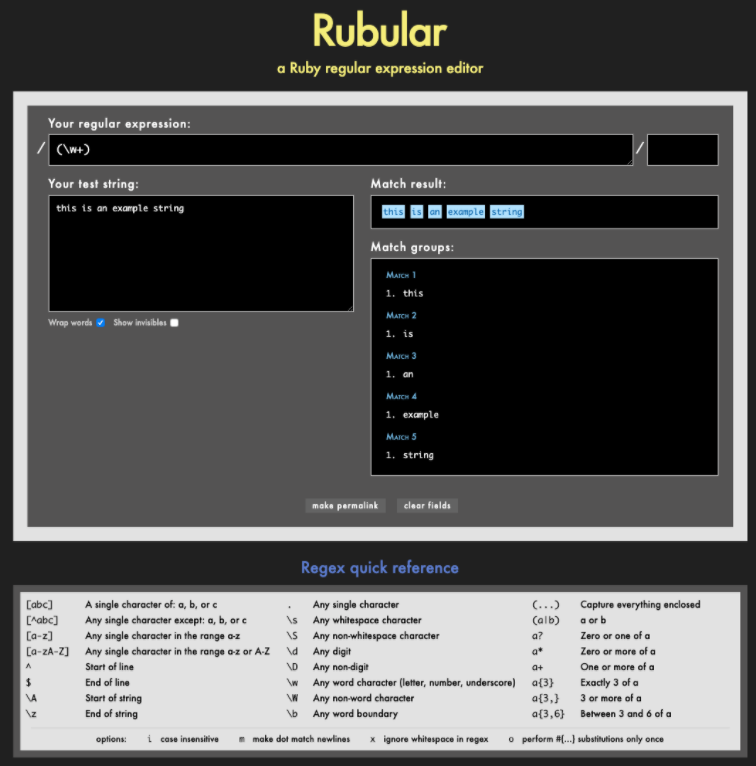
- Rubular editor online cho Ruby Regular Express.
- Rubular cung cấp 1 số tính năng như hiển thị Regex quick reference, hiển thị các Match result, ...
![]()
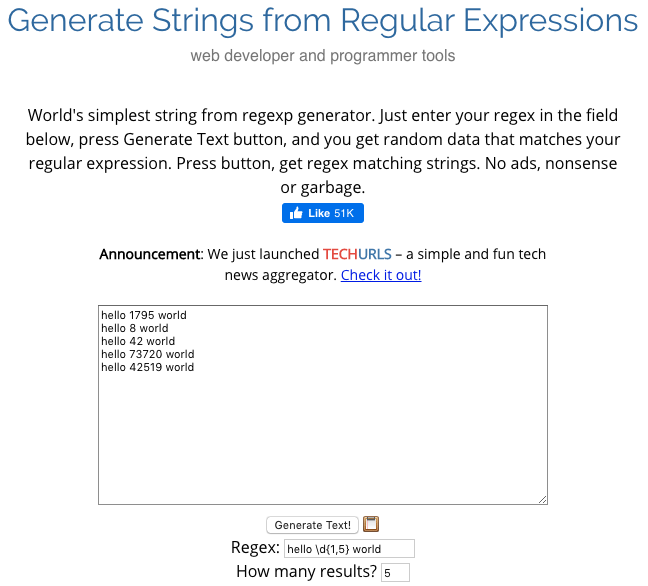
- Browserling generate random string từ Regular Expression.
![]()
2. Một số method sử dụng Regular Expression:
a.scan():
- Được sử dụng để tạo mảng các sub-string match với Regular Expression từ string cho trước.
- Ví dụ:
"ruby on rails".scan(/\w/) # ["r", "u", "b", "y", "o", "n", "r", "a", "i", "l", "s"] "ruby on rails".scan(/\w+/) # ["ruby", "on", "rails"] - Trong trường hơp không có sub-string match với Regular Expression thì trả về mảng rỗng.
- Ví dụ:
"ruby on rails".scan(/\d/) # []
b. match():
- Được sử dụng để extract
MatchDatamatch với Regular Expression từ string cho trước. - Khác với
scan(),match()chỉ convert sub-string đầu tiên thànhMatchDatathay vì convert tất cả sub-string. - Ví dụ:
"ruby on rails".match(/\w/) # <MatchData "r"> "ruby on rails".match(/\w+/) # <MatchData "ruby"> - Trong trường hơp không có sub-string match với Regular Expression thì trả về
nil. - Ví dụ:
"ruby on rails".match(/\d/) # nil
c. match?():
- Được sử dụng để kiểm tra string có match với Regular Expression hay không và trả về
truehoặcfalse. - Ví dụ:
"ruby on rails".match?(/\w/) # true "ruby on rails".match?(/\w+/) # true "ruby on rails".match?(/\d/) # false
d. =~:
- Được sử dụng để trả về index của sub-string đầu tiên match với Regular Expression.
- Ví dụ:
"ruby on rails" =~(/\w/) # 0 "ruby on rails" =~ (/\w+/) # 0 "ruby on rails" =~ (/\s/) # 4 - Trong trường hơp không có sub-string match với Regular Expression thì trả về
nil. - Ví dụ:
"ruby on rails" =~ (/\d/) # nil
3. gsub():
- Được dùng để replace tất cả các sub-string match với Regular Expression bằng 1 sub-string khác.
- Ví dụ:
"hello world".gsub(/hello/, "goodbye") # "goodbye world" - Trong Javascript cũng có hàm
replacethực hiện chức năng tương tự."hello world".gsub(/hello/, "goodbye") // "goodbye world" - Trong ví dụ trên cả hàm
gsubcủa Ruby và hàmreplacecủa Javascript đều trả về kết quả tương tự nhau. - Xét thêm 1 ví dụ khác như sau:
"hello hello".gsub(/hello/, "goodbye") # "goodbye goodbye" "hello hello".replace(/hello/, "goodbye") "goodbye hello" - Ở ví dụ này thì hàm
gsubcủa Ruby và hàmreplacecủa Javascript đang trả về 2 kết qủa khác nhau. - Chúng ta cùng tìm hiểu về các option của Regular Expression để tìm hiểu nguyên nhân.
4. Regular Expression options:
a. Global search - g:
- Quy định thực hiện thay thế tất cả các sub-string match với Regular Expression
- Là option mặc định của Ruby Regular Expression.
- Nên Regular Expression /hello/ trong Ruby tương đương với /hello/g trong Javascript.
- Với ví dụ so sánh hàm
gsub()của Ruby với hàmreplace()của Javascript, khi sử dụng Regular Expression /hello/g cho hàmreplace()của Javascript thì sẽ nhận được 2 kết qủa tương tự nhau."hello hello".gsub(/hello/, "goodbye") # "goodbye goodbye" "hello hello".replace(/hello/g, "goodbye") "goodbye goodbye"
b. Case insensitive - i:
- Theo mặc định thì Ruby Regular Expression là case sensitive - phân biệt hoa thường.
- Ví dụ:
"ABC".scan(/[a-z]/) # [] - Khi sử dụng Ruby Regular Expression với option i thì sẽ là case insensitive - không phân biệt hoa thường.
- Ví dụ:
"ABC".scan(/[a-z]/i) # ["A", "B", "C"] - Ngoài ra còn có 2 option khác là m và x.
5. gsub() advance:
- Trong các ví dụ trên, hàm gsub() được sử dụng với tham số thứ 2 là string.
- Hàm
gsub()cũng có thể nhận tham số thứ 2 là block. - Ví dụ:
"cat".gsub(/\w+/) { |animal| animal == "cat" ? "Tom" : "Jerry" } # "Tom" "mouse".gsub(/\w+/) { |animal| animal == "cat" ? "Tom" : "Jerry" } # "Jerry" - Hàm
gsub()cũng có thể nhận tham số thứ 2 là hash. - Ví dụ:
animals = { "cat" => "Tom", "mouse" => "Jerry", "duck" => "Donald" } "duck".gsub(/\w+/, animals) # Donald
6. capture:
- Xét bài toán sau, cho trước 1 string gồm tên và tuổi, ví dụ: "Tome 30 David 25"
- Để lấy tên và tuổi từ string, ta sử dụng 2 Regular Expression là /\w+/ và /\d+/
- Khi đó
data = "Tom 30 David 25".scan(/\w+ \d+/) # ["Tome 30", "David 25"] - Với kết quả trả về như trên ta vẫn chưa thể lấy được tên và tuổi, sử dụng chức năng capture, bao Regular Expression trong () ta được kết quả như sau.
data = "Tom 30 David 25".scan(/(\w+) (\d+)/) # [["Tome", "30"], ["David", "25"]] data[0][0] # "Tom" data[0][1] # "30"
All rights reserved
