Read and write PDF files in Java using Apache PDFBox

Apache PDFBox - Một thư viện PDF Java
Thư viện Apache PDFBox là một công cụ mã nguồn mở Java làm việc với các văn bản PDF. Nó cung cấp cho người dùng khả năng tạo mới các văn bản PDF, thao tác trên các file PDF đã có và khả năng trích xuất nội dung từ các văn bản PDF. Hiện nay Apache PDFBox được phát hành mới nhất theo phiên bản v2.0 của Apache.
Cài đặt
- Trước hết các bạn vào link PDFBox library, sau đó download về máy phiên bản mới nhất của
pdfbox-app.jar, ở đây mình chọnpdfbox-app-2.0.0-RC2.jar. - Sau đó, các bạn tiến hành thêm thư viện này vào project Java của mình: Chuột phải chọn
Build Path>>Add External Archives>> Selectpdfbox-app-2.0.0-RC2.jar>> OK. - Như vậy bạn đã có thể làm việc được với thư viện này rồi đó (yeah)
Làm việc với PDFBox
Tạo một file PDF mới (chỉ có một trang trống)
Các bước cần phải làm để tạo một file Blank PDF:
- Tạo một file PDF (sử dụng
PDDocument) - Thêm một
page( sử dụngPDPage) - Save and close file PDF đó
import org.apache.pdfbox.pdmodel.*;
import java.io.*;
public class BlankPDF {
public static void main(String[] args) {
PDDocument doc = null;
try{
doc = new PDDocument();
doc.addPage(new PDPage());
doc.save("empty_doc.pdf");
doc.close();
} catch (Exception ex){
System.out.println(ex);
}
}
}
Tạo một file PDF mới (với text)
Các bước tạo để tạo một file PDF with text:
- Tạo file và thêm page (như trên)
- Thêm nội dung cho trang sử dụng
PDPageContentStreamvà một số hàm sau đây:beginText()- Thiết lập kiểu chữ và màu chữ cho text sử dụng
setFont()vàsetNonStrokingColor() - Xác định vị trí của text sử dụng
moveTextPositionByAmount() - Nhập text với
drawString() endText()vàclose()
- Save và close file PDF đó
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.font.PDFont;
import org.apache.pdfbox.pdmodel.font.PDType1Font;
import java.awt.Color;
import java.io.*;
public class PDFWithText {
public static void main(String[] args) {
PDDocument doc = null;
PDPage page = null;
try {
doc = new PDDocument();
page = new PDPage();
doc.addPage(page);
PDFont font = PDType1Font.HELVETICA_BOLD;
PDPageContentStream content = new PDPageContentStream(doc, page);
content.beginText();
content.setFont( font, 20 );
content.setNonStrokingColor(Color.BLUE);
content.moveTextPositionByAmount( 100, 700 );
content.drawString("Hello It's me");
content.endText();
content.close();
doc.save("pdf_with_text.pdf");
doc.close();
} catch (Exception ex) {
System.out.println(ex);
}
}
}
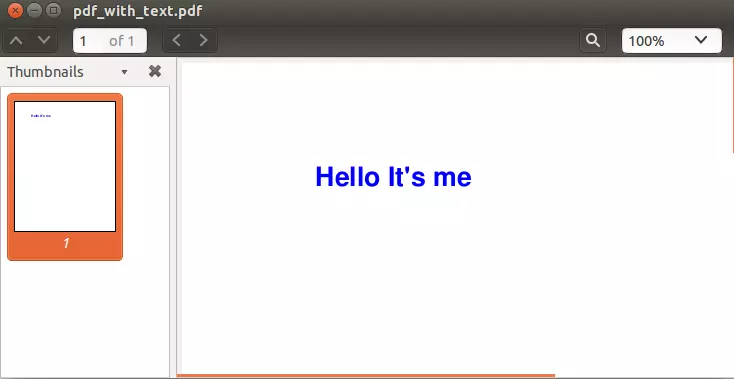
Và đây là thành quả của chúng ta sau khi chạy code ở trên ^_^
Trích xuất nội dung của một file PDF
Để trích xuất nội dung của một file PDF ta sử dụng class PDFTextStripper.
Các bước cần phải làm:
- load file PDF đã có sử dụng hàm
loadcủaPDDocument - thiết lập trang đầu và trang cuối cần để trích xuất nội dung, sử dụng
setStartPage()vàsetEndPage()trong classPDFTextStripper - ghi nội dung đó ra một file txt, sử dụng hàm
writeText()
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.text.PDFTextStripper;
import java.awt.Color;
import java.io.*;
public class ExtractContentFromPDF {
public static void main(String[] args) {
PDDocument doc;
BufferedWriter bw;
try {
File input = new File("pdf_with_text.pdf");
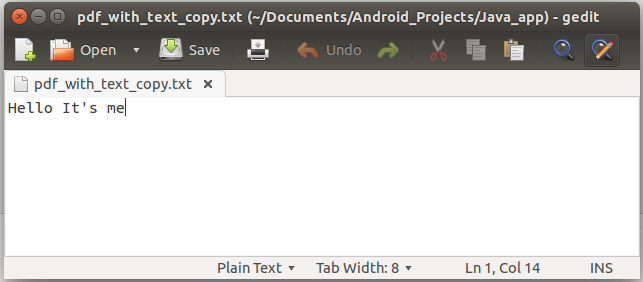
File output = new File("pdf_with_text_copy.txt");
doc = PDDocument.load(input);
System.out.println(doc.getNumberOfPages());
PDFTextStripper stripper = new PDFTextStripper();
stripper.setStartPage(1);
stripper.setEndPage(2);
// nếu bạn muốn lấy tất cả text của cả file pdf thì sử dụng code sau
// stripper.setEndPage(doc.getNumberOfPages())
bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(output)));
stripper.writeText(doc, bw);
bw.close();
doc.close();
} catch (Exception ex) {
System.out.println(ex);
}
}
}
Convert một file ảnh thành một file PDF
Các bước để thực hiện convert một file ảnh thành một file PDF:
- Tạo file và thêm page (như trên)
- Sử dụng class
JPEGFactoryđể tạo mộtPDImageXObjectchứa ảnh JPEG đã được nén - Tạo một
content streamtừPDPageContentStreamliên quan đến văn bản và trang sẽ chứa ảnh - Sử dụng hàm
drawImagetrongPDPageContentStreamđể vẽ ảnh lên trang văn bản bao gồm vị trí và kích thước
import org.apache.pdfbox.pdmodel.*;
import org.apache.pdfbox.pdmodel.graphics.image.JPEGFactory;
import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject;
import java.awt.Color;
import java.io.*;
public class ConvertImageToPDF {
public static void main(String[] args) {
PDDocument doc;
try {
doc = new PDDocument();
PDPage page = new PDPage();
doc.addPage(page);
PDImageXObject image = JPEGFactory.createFromStream(doc, new FileInputStream("background.jpeg"));
PDPageContentStream content = new PDPageContentStream(doc, page);
content.drawImage(image, 100, 500, 480, 270);
content.close();
doc.save("image_pdf.pdf");
} catch (Exception ex) {
System.out.println(ex);
}
}
}
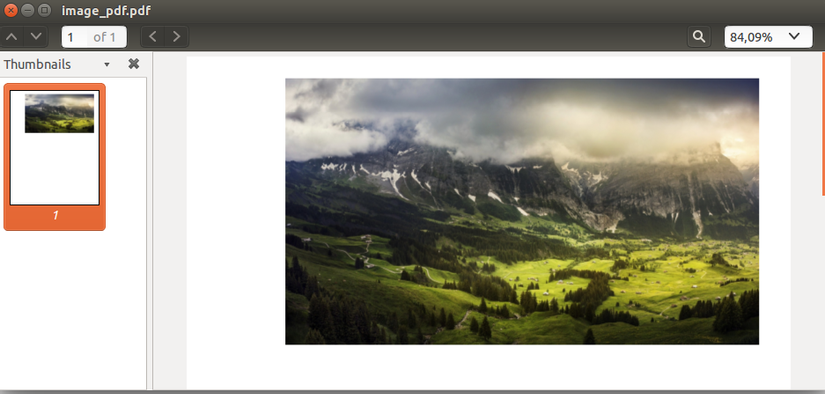
Và sau đây là thành quả khi chạy codes ở trên (yeah) :
Trên đây, mình đã giới thiệu qua về việc đọc và ghi file PDF sử dụng thư viện Apache PDFBox, hi vọng nó sẽ giúp ích được cho bạn đọc (hehe).
Tài liệu tham khảo
All rights reserved
