RabbitMQ và Kafka - cùng đặt lên bàn cân

Khi xây dựng các hệ thống phân phối thông điệp, lựa chọn công nghệ phù hợp có thể là một quyết định quan trọng. Trong thế giới của các giải pháp mã nguồn mở, RabbitMQ và Kafka đều nổi bật như những công nghệ phổ biến và mạnh mẽ. Tuy nhiên, việc quyết định sử dụng RabbitMQ hay Kafka thường phụ thuộc vào yêu cầu cụ thể của dự án, mục tiêu kỹ thuật, và các yếu tố khác.
Trong bài viết này, chúng ta sẽ so sánh RabbitMQ và Kafka từ nhiều góc độ khác nhau, từ cấu trúc và hiệu suất đến khả năng mở rộng và tính linh hoạt. Bằng cách đặt lên bàn cân các ưu điểm và nhược điểm của từng công nghệ, chúng ta sẽ giúp bạn có cái nhìn sâu hơn để lựa chọn công nghệ phù hợp nhất cho nhu cầu của mình.
Hãy cùng khám phá và đặt RabbitMQ và Kafka lên bàn cân để tìm ra lựa chọn tốt nhất cho hệ thống phân phối thông điệp của bạn.
Các bài viết về hai công cụ này đã có rất nhiều, các bạn có thể tìm đọc nếu thấy bài viết này không phù hợp với bản thân. Nhưng mình vẫn muốn hoàn thành nó bới đơn giản mình muốn tổng hợp lại tất cả các kiến thức cần thiết trên con đường trở thành một lập trình viên Java chuyên nghiệp. Nên dù nó có là kiến thức cũ, có hàng triệu bài viết đi chăng nữa, các bạn vẫn sẽ luôn tìm được những thứ có ích trên trang cá nhân của mình. Follow để theo dõi nhiều hơn những kiến thức khác về Java cùng mình nhé. 😘😘😘
A. Message Broker là gì?
Message Broker là một phần mềm trung gian giúp tiêu chuẩn hóa giao tiếp giữa các hệ thống, ứng dụng, và dịch vụ khác nhau trong một kiến trúc phân tán. Nó hoạt động bằng cách nhận tin nhắn từ người gửi (publisher) và sau đó phân phối chúng đến người nhận (subscriber) thích hợp, dựa trên một loạt các quy tắc và cấu hình đã định trước. Message broker hỗ trợ nhiều mô hình giao tiếp, bao gồm publish/subscribe, request/reply và point-to-point, qua đó tạo điều kiện cho việc trao đổi tin nhắn một cách linh hoạt và đáng tin cậy.
B. Tại sao lại cần Message Broker?
Tiết kiệm thời gian và công sức: Hệ thống phân phối thông điệp giúp tự động hóa quá trình truyền tải thông điệp, giảm bớt sự can thiệp của con người và tiết kiệm thời gian so với việc truyền tải thủ công.
-
Tách biệt giữa người sản xuất và người tiêu dùng: Giúp các hệ thống hoặc ứng dụng có thể giao tiếp với nhau mà không cần biết đến chi tiết cụ thể về người nhận hay nguồn gửi, qua đó giảm sự phụ thuộc và tăng tính linh hoạt trong kiến trúc hệ thống.
-
Đảm bảo tin nhắn: Message broker có thể lưu trữ tạm thời các tin nhắn để đảm bảo rằng chúng không bị mất trong trường hợp có sự cố, giúp cải thiện độ tin cậy của quá trình giao tiếp.
-
Mở rộng và phân tán: Hỗ trợ việc mở rộng quy mô ứng dụng và phân tán giao tiếp, làm giảm tải cho hệ thống và cho phép quản lý tốt hơn tài nguyên và công suất xử lý.
-
Giao tiếp đa hình thức: Hỗ trợ nhiều loại giao tiếp và mô hình tin nhắn, từ đồng bộ đến bất đồng bộ, giúp tối ưu hóa quá trình trao đổi dữ liệu giữa các hệ thống.
Tóm lại, hệ thống phân phối thông điệp là một phần quan trọng của hạ tầng thông tin hiện đại, giúp các tổ chức truyền tải thông tin một cách hiệu quả, tin cậy và an toàn.
C. Các công cụ Message Broker phổ biến
-
Apache Kafka: Một hệ thống phát trực tiếp dữ liệu phân tán được thiết kế để xử lý lượng lớn dữ liệu trong thời gian thực.
-
RabbitMQ: Một message broker linh hoạt, hỗ trợ nhiều giao thức giao tiếp, bao gồm AMQP, STOMP, MQTT, giúp nó trở thành sự lựa chọn phổ biến cho các ứng dụng cần độ trễ thấp và đảm bảo giao tiếp.
-
ActiveMQ: Một message broker mã nguồn mở hỗ trợ nhiều giao thức giao tiếp và được thiết kế cho tính linh hoạt cao và độ tin cậy.
-
Amazon SQS (Simple Queue Service): Một dịch vụ hàng đợi tin nhắn quản lý hoàn toàn, cung cấp độ đàn hồi cao và khả năng mở rộng mà không cần quản lý cơ sở hạ tầng.
-
Azure Service Bus: Một dịch vụ truyền thông đám mây tích hợp, hỗ trợ các mô hình giao tiếp phức tạp và điều phối giao tiếp trong các ứng dụng đám mây lớn.
Oke, sau khi đã nắm được sơ lược về message broker là gì, chúng ta hãy cùng đi vào chủ đề chính của bài ngày hôm nay. Đó chính là hai công cụ được xem là phổ biến nhất và tích hợp trên nhiều ứng dụng
D. Apache Kafka
1. Apache Kafka là gì?
Apache Kafka là một nền tảng phân tán mã nguồn mở được thiết kế để xử lý dữ liệu dạng luồng. Ban đầu, Kafka được phát triển bởi LinkedIn và sau đó đã trở thành một phần của Apache Software Foundation. Kafka được thiết kế để cung cấp khả năng mở rộng cao, độ tin cậy và hiệu suất cao cho việc xử lý dữ liệu thời gian thực.
2. Kafka dùng để làm gì?
Apache Kafka thường được sử dụng trong các tình huống như xử lý luồng dữ liệu thời gian thực, xây dựng hệ thống dữ liệu lớn, xử lý sự kiện trong ứng dụng, và làm cơ sở dữ liệu sự kiện để theo dõi các thay đổi trong dữ liệu.
-
Xử lý luồng dữ liệu thời gian thực: Kafka được thiết kế để xử lý lượng lớn dữ liệu dạng luồng, cho phép phân tích và xử lý dữ liệu thời gian thực, như dữ liệu từ thiết bị IoT, hệ thống giao dịch tài chính, hoặc bất kỳ nguồn dữ liệu nào cập nhật liên tục.
-
Nhập và xuất dữ liệu giữa các hệ thống: Kafka thường được dùng như một cầu nối giữa các hệ thống, cho phép dễ dàng nhập và xuất dữ liệu giữa các hệ thống và ứng dụng khác nhau, từ cơ sở dữ liệu đến các dịch vụ web.
-
Tích hợp dữ liệu: Kafka giúp tích hợp dữ liệu từ nhiều nguồn, bao gồm cả dữ liệu phi cấu trúc và cấu trúc, để tạo ra một luồng dữ liệu thống nhất có thể được sử dụng cho phân tích và xử lý dữ liệu.
-
Hệ thống ghi nhận sự kiện (Event Sourcing): Kafka có thể được sử dụng để lưu trữ trạng thái của một hệ thống thông qua chuỗi sự kiện, cho phép khôi phục trạng thái của hệ thống hoặc theo dõi các thay đổi trong dữ liệu theo thời gian.
-
Truyền thông tin trong hệ thống microservices: Kafka là một lựa chọn phổ biến để truyền thông tin giữa các dịch vụ trong kiến trúc microservices, giúp đảm bảo tính nhất quán và độ tin cậy trong việc trao đổi dữ liệu.
-
Phân tích dữ liệu lớn: Kafka được tích hợp với các công cụ phân tích dữ liệu lớn như Apache Spark, Apache Hadoop, để xử lý và phân tích dữ liệu lớn trong thời gian thực hoặc theo lô.
Nhờ khả năng mở rộng, độ tin cậy và hiệu suất cao, Kafka đã trở thành một thành phần quan trọng trong kiến trúc dữ liệu và ứng dụng của nhiều tổ chức và doanh nghiệp lớn.
3. Kafka hoạt động thế nào?
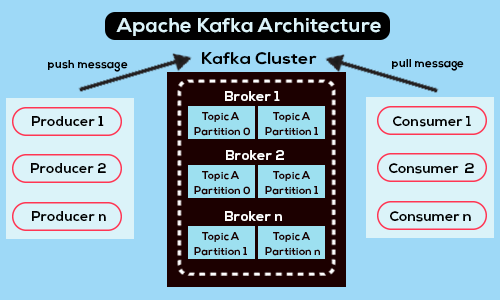
Kafka hoạt động dựa trên mô hình xuất bản - đăng ký (publish-subscribe), nơi mà các tin nhắn được phân loại thành các chủ đề (topics). Các nhà sản xuất (producers) gửi tin nhắn đến các chủ đề này và các người tiêu dùng (consumers) đăng ký chủ đề để nhận tin nhắn. Kafka được thiết kế để lưu trữ và phân phối một lượng lớn tin nhắn, hỗ trợ việc xử lý dữ liệu phức tạp và đa dạng..
Các thành phần chính:
-
Producer: Là thành phần gửi dữ liệu đến Kafka. Producer đẩy tin nhắn vào các topic mà nó muốn gửi dữ liệu.
-
Consumer: Là thành phần nhận dữ liệu từ Kafka. Consumer đăng ký với một hoặc nhiều topic và xử lý dữ liệu được gửi đến từ Kafka.
-
Broker: Là máy chủ trong cụm Kafka. Mỗi broker lưu trữ một số lượng dữ liệu cố định và thực hiện việc chuyển tin nhắn đến và đi từ producers và consumers.
-
Topic: Là danh mục hoặc ngữ cảnh mà dữ liệu được lưu trữ và phân loại. Tin nhắn trong Kafka được phân loại theo topic.
-
Partition: Là phân đoạn của topic. Mỗi topic có thể được chia thành nhiều partition, mỗi partition có thể có một hoặc nhiều bản sao. Partition giúp Kafka mở rộng và cân bằng tải bằng cách phân phối dữ liệu trên nhiều broker.
-
Offset: Là một con số duy nhất xác định vị trí của mỗi tin nhắn trong partition. Offset giúp Kafka theo dõi tin nhắn nào đã được consumer xử lý.
-
Replica: Là bản sao của partition. Kafka sao chép dữ liệu trên nhiều máy chủ để đảm bảo độ tin cậy và khả năng chịu lỗi.
-
Consumer Group: Là một nhóm các consumer làm việc cùng nhau để xử lý dữ liệu từ một topic. Kafka hỗ trợ việc xử lý song song bằng cách phân chia các partition của topic giữa các consumer trong cùng một nhóm.
-
Zookeeper: Là dịch vụ quản lý cấu hình cho Kafka. Zookeeper theo dõi trạng thái của các broker cũng như consumer group và quản lý metadata của Kafka.
-
Kafka Connect: Là một công cụ để tích hợp Kafka với các hệ thống dữ liệu khác như cơ sở dữ liệu, hệ thống tệp, và các dịch vụ.
-
Kafka Streams: Là một thư viện cho phép xử lý và phân tích dữ liệu dạng luồng trực tiếp từ Kafka.
Cách các thành phần tương tác
1. Producers Đẩy Thông Điệp đến các Topic tại Kafka Cluster:
-
Producers là các ứng dụng hay hệ thống sản xuất ra dữ liệu. Ví dụ: một ứng dụng web có thể gửi log hoạt động của người dùng, hoặc một cảm biến IoT gửi dữ liệu đo lường.
-
Khi producer có dữ liệu mới, nó sẽ tạo một tin nhắn (message) và gửi đến một topic đã được định nghĩa trong Kafka cluster. Topic là một danh mục được dùng để phân loại và lưu trữ các thông điệp tương tự.
-
Producer quyết định thông điệp sẽ được gửi đến partition nào trong topic bằng cách sử dụng key của thông điệp để xác định. Điều này giúp cân bằng việc phân phối thông điệp qua các partition.
2. Kafka Cluster Lưu Trữ Thông Điệp trong các Partitions của Topic:
-
Kafka Cluster bao gồm một hoặc nhiều brokers. Mỗi broker là một máy chủ độc lập có thể lưu trữ một hoặc nhiều partition của topic.
-
Mỗi partition có thể coi như là một hàng đợi FIFO (first-in-first-out) của thông điệp. Thông điệp được lưu trữ theo thứ tự chúng được nhận và mỗi thông điệp có một offset duy nhất.
-
Kafka hỗ trợ replication, tức là sao chép dữ liệu qua các broker, để đảm bảo dữ liệu không bị mất và cụm có thể chịu lỗi.
3. Consumers hoặc Consumer Groups Tiêu Thụ Thông Điệp từ Kafka Cluster:
-
Consumers đăng ký với topic và đọc thông điệp. Mỗi consumer có thể đọc từ một hoặc nhiều partition, tùy thuộc vào việc nó thuộc consumer group nào.
-
Trong một consumer group, mỗi consumer sẽ được giao đọc từ một số partition cụ thể, giúp tăng khả năng đọc dữ liệu song song và xử lý dữ liệu nhanh chóng.
-
Kafka theo dõi offset của mỗi thông điệp đã được consumer xử lý, đảm bảo rằng mỗi thông điệp chỉ được xử lý một lần và không có thông điệp nào bị sót.
4. Zookeeper Quản Lý và Điều Phối Trạng Thái của Cụm Kafka:
-
Zookeeper là một dịch vụ phối hợp cấu hình và đồng bộ cho các dịch vụ phân tán. Trong Kafka, Zookeeper dùng để quản lý và theo dõi trạng thái của brokers và consumer groups, bao gồm việc giữ thông tin về topics, partitions, offsets, và các thông tin cấu hình khác.
-
Zookeeper cũng giúp quản lý việc chọn leader cho mỗi partition. Leader là broker có trách nhiệm nhận và phục vụ tất cả các yêu cầu đọc và ghi cho partition đó. Các broker khác có thể phục vụ như là bản sao (follower) để đảm bảo tính khả dụng và độ tin cậy.
Ví dụ trong thực tế:
Giả sử một ứng dụng mạng xã hội cần theo dõi các sự kiện như đăng nhập, đăng xuất, và bài viết mới của người dùng để phân tích hành vi và tương tác của người dùng:
-
Producer: Mỗi khi một người dùng đăng nhập, đăng xuất, hoặc đăng bài, ứng dụng sẽ gửi một tin nhắn đến Kafka, với mỗi loại sự kiện được gửi đến một topic riêng biệt.
-
Kafka Cluster: Kafka lưu trữ và quản lý các tin nhắn này trong các topic tương ứng. Nếu có nhiều tin nhắn, chúng được phân phối đều qua các partition để cân bằng tải.
-
Consumer: Các hệ thống phân tích dữ liệu đăng ký làm consumer cho các topic này. Chúng tiêu thụ dữ liệu từ Kafka và thực hiện các phân tích như đếm số lần đăng nhập hàng ngày hoặc phân tích xu hướng nội dung bài viết.
Qua ví dụ này, Kafka cho phép ứng dụng mạng xã hội quản lý và xử lý lượng lớn sự kiện một cách hiệu quả, và cung cấp dữ liệu thời gian thực cho các hệ thống phân tích và quảng cáo.
4. Triển khai Kafka
Bước 1: Cài đặt và Chạy Kafka
1.Tải về và Giải nén Apache Kafka:
-
Truy cập trang web chính thức của Apache Kafka (kafka.apache.org) để tải về bản mới nhất.
-
Giải nén gói đã tải về vào một thư mục trên máy của bạn.
2.Chạy Zookeeper:
Kafka sử dụng Zookeeper để quản lý cluster, do đó bạn cần khởi chạy nó trước:
bin/zookeeper-server-start.sh config/zookeeper.properties
Trên Windows, sử dụng zookeeper-server-start.bat thay cho sh.
Chạy Kafka Server:
Mở một terminal mới và chạy Kafka server:
bin/kafka-server-start.sh config/server.properties
Trên Windows, sử dụng kafka-server-start.bat.
Bước 2: Cấu Hình Kafka trong Spring Boot
1.Thêm Dependencies vào pom.xml
Thêm các dependencies sau đây vào tệp pom.xml của dự án Spring Boot của bạn:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.5.6.RELEASE</version>
</dependency>
Điều chỉnh phiên bản phù hợp với phiên bản Spring Boot của bạn.
2. Cấu Hình Kafka Producer và Consumer:
Có hai cách để cấu hình là qua file .properties/.yml hoặc thông qua code, tùy vào khẩu vị hoặc yêu cầu của dự án các bạn có thể lựa chọn
-- Cấu hình qua file application.properties hoặc application.yml --
Trong application.properties hoặc application.yml của bạn, thêm cấu hình cho Kafka Producer và Consumer:
# Producer
spring.kafka.producer.bootstrap-servers=localhost:9092
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# Consumer
spring.kafka.consumer.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=myGroup
spring.kafka.consumer.key-serializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-serializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.auto-offset-reset=earliest
-- Cấu hình thông qua code --
//CẤU HÌNH KAFKA PRODUCER
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
//CẤU HÌNH KAFKA CONSUMER
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import java.util.HashMap;
import java.util.Map;
@EnableKafka
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ConsumerConfig.GROUP_ID_CONFIG, "myGroup");
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(configProps);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
Trong cấu hình trên, bạn thấy rằng tất cả các cấu hình cần thiết cho Kafka producer và consumer được định nghĩa trực tiếp trong code thông qua các bean. Bạn có thể điều chỉnh các giá trị cấu hình (ví dụ: địa chỉ bootstrap-servers, group-id, v.v.) theo nhu cầu của mình.
Sử dụng phương pháp này cho phép bạn linh hoạt hơn trong việc quản lý cấu hình của Kafka, đặc biệt là khi bạn cần cấu hình động hoặc dựa trên điều kiện khác nhau trong ứng dụng của mình.
Bước 3: Sử Dụng Kafka trong Spring Boot
1.Gửi Tin Nhắn (Producer):
Tạo một service để gửi tin nhắn đến Kafka:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
@Service
public class ProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String msg) {
kafkaTemplate.send("topicName", msg);
}
}
2.Nhận Tin Nhắn (Consumer)
Tạo một listener để nhận tin nhắn từ Kafka:
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class ConsumerService {
@KafkaListener(topics = "topicName", groupId = "myGroup")
public void listenGroupFoo(String message) {
System.out.println("Received Message in group myGroup: " + message);
}
}
Sau khi thực hiện các bước trên, bạn đã có thể gửi và nhận tin nhắn qua Kafka từ ứng dụng Spring Boot của mình. Đảm bảo rằng Zookeeper và Kafka server đang chạy trước khi bạn khởi động ứng dụng Spring Boot.
5. Ưu nhược điểm
Apache Kafka là một nền tảng xử lý dữ liệu dạng luồng phân tán mạnh mẽ, được thiết kế để xử lý dữ liệu ở quy mô lớn một cách hiệu quả. Tuy nhiên, như mọi công nghệ, Kafka không phải là giải pháp hoàn hảo cho mọi trường hợp sử dụng. Dưới đây là một số ưu điểm, nhược điểm và các kịch bản sử dụng thích hợp cho Kafka:
Ưu điểm của Apache Kafka
-
Khả năng mở rộng: Kafka được thiết kế để mở rộng ngang, có thể xử lý hàng trăm nghìn tin nhắn mỗi giây từ hàng nghìn máy chủ khách hàng.
-
Độ tin cậy và độ bền: Dữ liệu có thể được sao chép trên các nút trong cụm Kafka, đảm bảo rằng dữ liệu không bị mất và có sẵn ngay cả khi có sự cố xảy ra.
-
Hiệu suất cao: Kafka có hiệu suất xử lý dữ liệu dạng luồng cực kỳ cao, đồng thời duy trì độ trễ thấp, ngay cả khi xử lý khối lượng dữ liệu lớn.
-
Tích hợp: Hỗ trợ kết nối dễ dàng với hệ thống ngoài qua Kafka Connect, và xử lý dữ liệu phức tạp với Kafka Streams.
-
Hỗ trợ ngôn ngữ đa dạng: Có thể được tích hợp vào hầu hết các ứng dụng phần mềm thông qua các thư viện client cho nhiều ngôn ngữ lập trình.
Nhược điểm của Apache Kafka
-
Độ phức tạp: Cài đặt, cấu hình và quản lý Kafka có thể phức tạp, đặc biệt là khi triển khai ở quy mô lớn.
-
Yêu cầu tài nguyên: Kafka yêu cầu một lượng đáng kể tài nguyên hệ thống và bộ nhớ để hoạt động hiệu quả, đặc biệt là khi lưu trữ lượng lớn dữ liệu.
-
Thời gian học tập: Có một đường cong học tập liên quan đến việc sử dụng và quản lý Kafka một cách hiệu quả.
6. Khi nào nên và không nên sử dụng
NÊN:
-
Xử lý và phân tích dữ liệu thời gian thực: Ví dụ, theo dõi hành vi người dùng trên website, xử lý luồng sự kiện từ thiết bị IoT.
-
Hệ thống ghi nhận và truyền dữ liệu giữa các ứng dụng: Đồng bộ hóa dữ liệu giữa các dịch vụ và ứng dụng, như đồng bộ hóa cơ sở dữ liệu giữa các môi trường.
-
Hệ thống tin nhắn đáng tin cậy ở quy mô lớn: Xây dựng hệ thống messaging backbone cho các ứng dụng phức tạp và đa dịch vụ.
KHÔNG NÊN:
-
Dự án nhỏ hoặc yêu cầu đơn giản: Đối với các ứng dụng đơn giản không yêu cầu khả năng xử lý dữ liệu thời gian thực hoặc không cần đến sự mở rộng và tính bền vững ở quy mô lớn, việc sử dụng Kafka có thể là quá phức tạp và không cần thiết.
-
Ứng dụng cần đến độ trễ cực thấp: Trong một số trường hợp cụ thể, nơi độ trễ cực kỳ thấp là yếu tố quan trọng (ví dụ, giao dịch tài chính trong milisecond), Kafka có thể không phải là lựa chọn tốt nhất do cách thiết kế và cơ chế lưu trữ dữ liệu.
-
Các dự án có yêu cầu bảo mật dữ liệu cao: Kafka hỗ trợ bảo mật, nhưng việc triển khai và duy trì các tính năng bảo mật phức tạp ở quy mô lớn đôi khi có thể gặp khó khăn. Trong các trường hợp yêu cầu bảo mật dữ liệu cực kỳ cao, cần phải cân nhắc kỹ lưỡng.
E. RabbitMQ
1. RabbitMQ là gì?

RabbitMQ là một hệ thống trung gian tin nhắn (message broker) mã nguồn mở được dùng để xử lý và truyền tin nhắn giữa các ứng dụng phần mềm. Nó là một phần của hệ thống nhắn tin AMQP (Advanced Message Queuing Protocol), một giao thức nhắn tin tiêu chuẩn cho phép các ứng dụng giao tiếp với nhau theo cách đáng tin cậy, linh hoạt và mở rộng.
RabbitMQ hỗ trợ nhiều loại giao tiếp giữa các ứng dụng, bao gồm gửi và nhận tin nhắn một cách đồng bộ hoặc bất đồng bộ. Nó được thiết kế để mở rộng dễ dàng, cho phép hệ thống xử lý một lượng lớn tin nhắn mà không làm giảm hiệu suất.
2. RabbitMQ dùng để làm gì?
-
Giao tiếp giữa các dịch vụ phân tán: RabbitMQ rất hữu ích trong kiến trúc microservices, nơi cần có sự giao tiếp giữa các dịch vụ nhỏ và độc lập. Nó giúp giảm bớt sự phức tạp khi giao tiếp giữa các dịch vụ này bằng cách đóng vai trò là một trung gian.
-
Xử lý công việc nền (background jobs): Có thể sử dụng RabbitMQ để gửi công việc nặng về tài nguyên hoặc mất thời gian để xử lý nền, như việc gửi email, xử lý hình ảnh, hoặc tải dữ liệu lớn, giúp giảm tải cho hệ thống chính và tăng hiệu suất ứng dụng.
-
Buffering (Đệm): RabbitMQ có thể đóng vai trò là một hệ thống đệm để giữ tin nhắn khi hệ thống đích không sẵn sàng để xử lý ngay lập tức, giúp cân bằng tải và tránh mất mát dữ liệu trong các trường hợp có lượng tin nhắn cao đột biến.
-
Đảm bảo giao tiếp đáng tin cậy: RabbitMQ hỗ trợ các tính năng như message acknowledgment, durable queues, và persistent messages để đảm bảo rằng thông điệp không bị mất trong quá trình truyền tải, kể cả khi có sự cố xảy ra.
-
Hỗ trợ nhiều ngôn ngữ lập trình: Với API hỗ trợ nhiều ngôn ngữ như Java, .NET, Python, Ruby, và nhiều hơn nữa, RabbitMQ có thể dễ dàng được tích hợp vào hầu như bất kỳ hệ thống nào.
-
Routing và Filtering: RabbitMQ cung cấp khả năng linh hoạt cao trong việc định tuyến và lọc tin nhắn, cho phép các ứng dụng gửi và nhận tin nhắn một cách chính xác theo nhu cầu.
-
Phân phối sự kiện: RabbitMQ có thể được sử dụng để phát và nhận các sự kiện trong hệ thống, giúp các thành phần ứng dụng có thể phản ứng với các thay đổi mà không cần biết đến nhau.
3. RabbitMQ hoạt động thế nào?
RabbitMQ hoạt động dựa trên mô hình AMQP (Advanced Message Queuing Protocol), một giao thức truyền tin nâng cao, và cung cấp cơ chế trung gian cho phép các ứng dụng gửi và nhận tin nhắn. Dưới đây là một cái nhìn tổng quan về cách hoạt động và cấu trúc cơ bản của RabbitMQ:
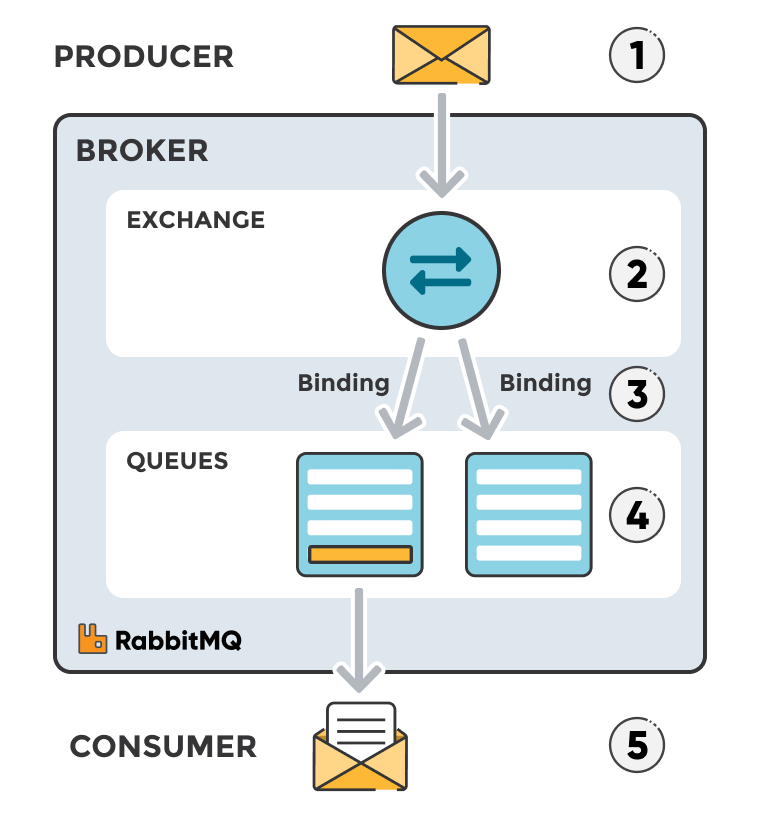
(1) Producer (Người sản xuất): Một ứng dụng gửi tin nhắn được gọi là producer. Producer tạo tin nhắn và gửi chúng đến một exchange.
(2) Exchange (Trạm trung chuyển): Đây là nơi mà tin nhắn từ producer được gửi đến trước. Exchange xác định làm thế nào để chuyển hướng tin nhắn đến một hoặc nhiều hàng đợi dựa trên các thuộc tính của tin nhắn và các quy tắc định tuyến. Có nhiều loại exchange khác nhau như direct, topic, fanout, và headers, mỗi loại phục vụ cho một mục đích định tuyến cụ thể.
(3) Bindings: Quy tắc định tuyến liên kết một exchange với một hàng đợi. Bindings có thể chứa routing keys hoặc pattern matching để xác định cách tin nhắn từ exchange được định tuyến đến các hàng đợi.
(4) Queue (Hàng đợi): Tin nhắn sau khi được định tuyến bởi exchange sẽ được lưu trữ trong hàng đợi cho đến khi được consumer xử lý. Hàng đợi đóng vai trò như một bộ đệm và cũng đảm bảo tính toàn vẹn và độ tin cậy của tin nhắn.
(5) Consumer (Người tiêu dùng): Consumer là ứng dụng đọc và xử lý tin nhắn từ hàng đợi. Một hàng đợi có thể có nhiều consumer; RabbitMQ hỗ trợ cả mô hình xử lý tin nhắn đồng thời và phân phối công bằng giữa các consumer.
4. Exchange và các loại Exchange
Một khái niệm quan trọng mà bạn cần phải biết khi muốn tiếp cận và sử dụng RabbitMQ đó là Exchange
Message không được publish trực tiếp vào Queue; thay vào đó, Producer gửi message đến Exchange.
Exchanges đóng vai trò là điểm nhận tin nhắn từ producers và sau đó chuyển tiếp chúng đến một hoặc nhiều queues dựa trên các quy tắc định tuyến và bindings
Thuật toán định tuyến được sử dụng phụ thuộc vào loại Exchange và quy tắc (còn gọi là ràng buộc hay binding).
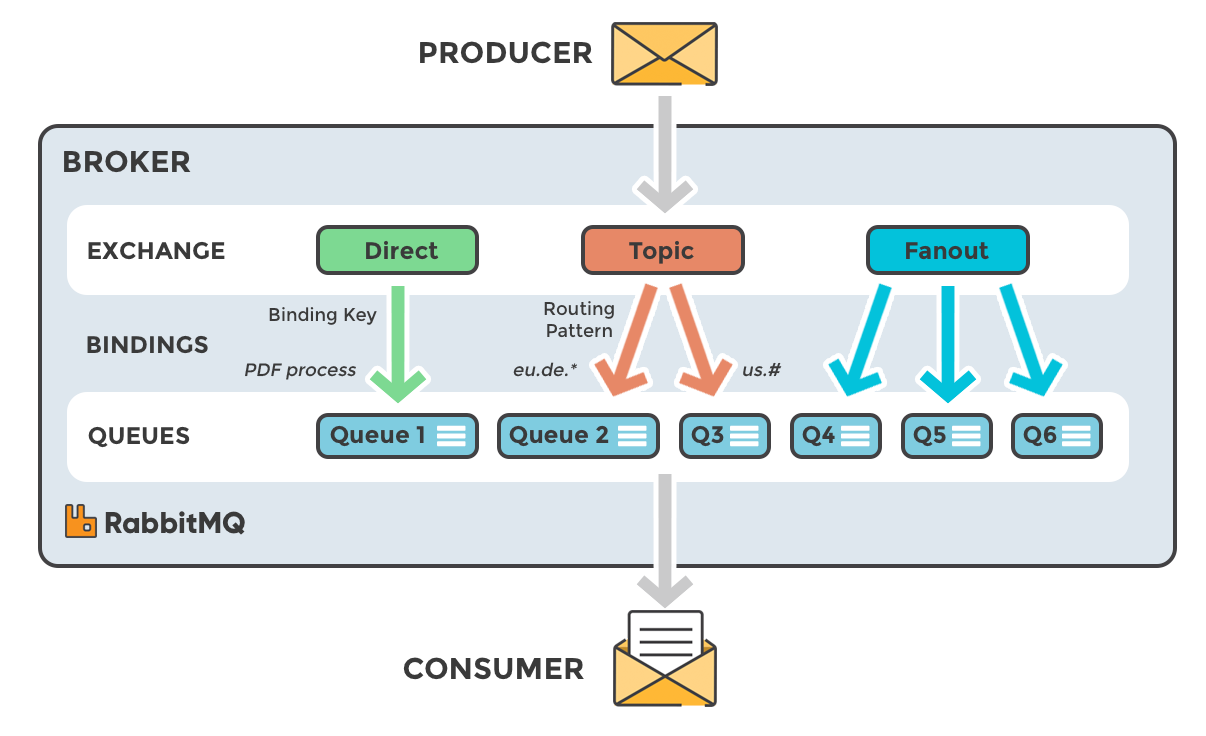
Exchanges có bốn loại chính : Direct, Fanout, Topic, Headers, mỗi loại có cơ chế định tuyến tin nhắn khác nhau:
4.1 Direct Exchange
Direct exchange chuyển tiếp tin nhắn đến queues dựa trên routing key mà tin nhắn được gửi kèm. Queue sẽ nhận tin nhắn từ exchange này nếu routing key của tin nhắn khớp với routing key mà queue đã sử dụng để liên kết với exchange.
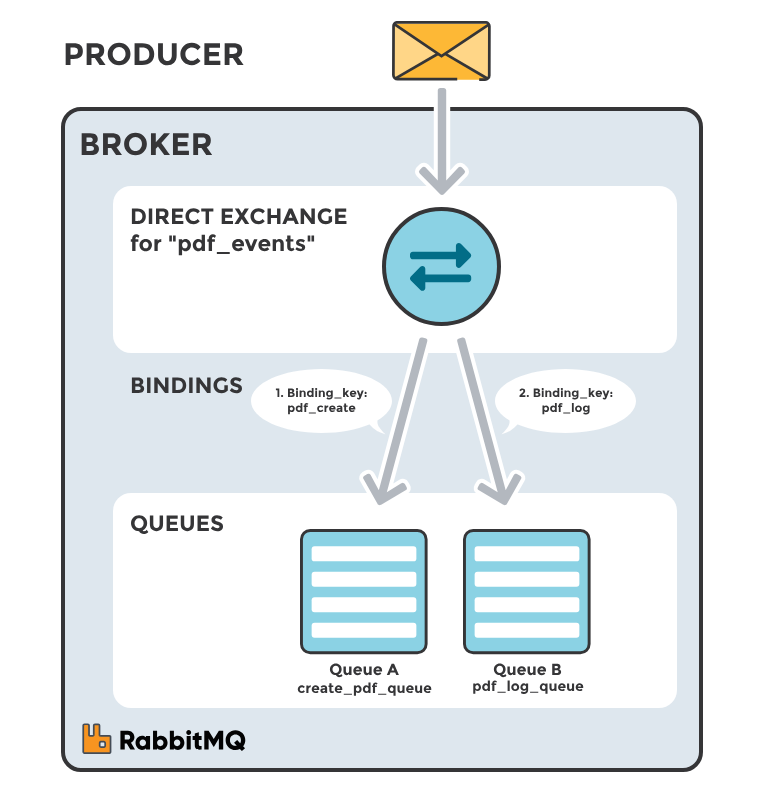
Một Exchange không xác định tên (hay còn được gọi là "nameless exchange" hoặc empty string exchange) , đây là loại Default Exchange, một dạng đặc biệt của là Direct Exchange. Default Exchange được liên kết ngầm định với mọi Queue với khóa định tuyến bằng với tên Queue. Khi một tin nhắn được gửi đến default exchange, bạn phải chỉ định routing key. Default exchange sẽ chuyển tiếp tin nhắn đến queue có tên trùng khớp với routing key đó. Nếu không có queue nào có tên khớp với routing key, tin nhắn sẽ bị mất. Điều này làm cho quá trình gửi tin nhắn đến một queue cụ thể trở nên đơn giản và trực tiếp.
Direct Exchange thường được sử dụng khi bạn muốn mỗi tin nhắn được chuyển đến một queue cụ thể dựa trên một thuộc tính cụ thể của tin nhắn (ví dụ, ID hoặc loại của tin nhắn).
Ví dụ: nếu hàng đợi (Queue) gắn với một exchange có binding key là "ngocbach99", message được đẩy vào exchange với routing key là "ngocbach99" sẽ được đưa vào hàng đợi này.
4.2 Fanout Exchange
Fanout exchange chuyển tiếp tin nhắn đến tất cả các queues mà nó biết, bất kể routing key của tin nhắn. Không quan tâm đến routing key; mỗi tin nhắn được gửi đến fanout exchange sẽ được chuyển tiếp đến mọi queue đã liên kết với nó.
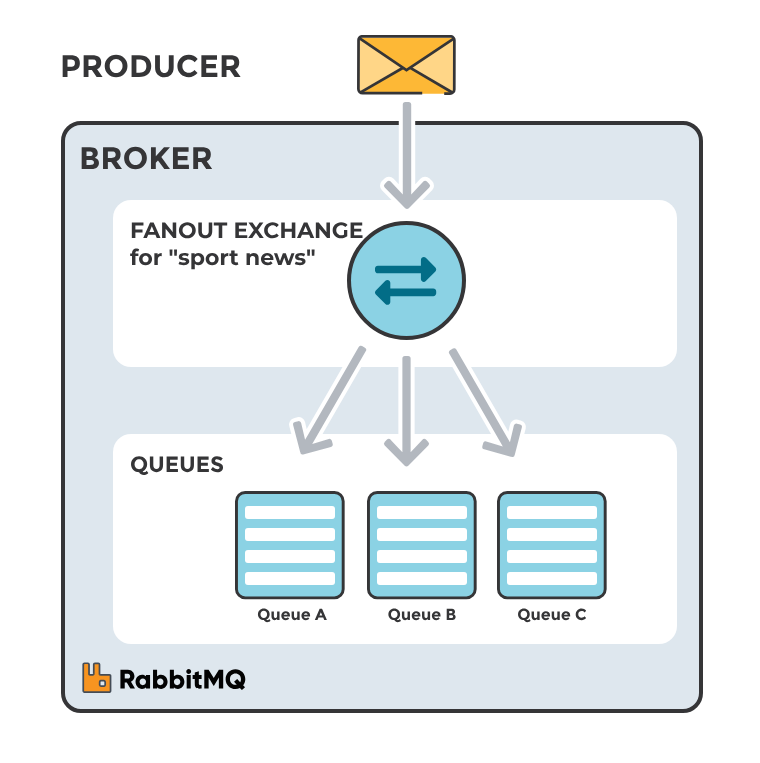
Thích hợp cho việc broadcast tin nhắn, nơi mà mỗi tin nhắn cần được gửi đến tất cả các consumer, như cập nhật trạng thái hoặc thông báo sự kiện.
4.3 Topic Exchange
Topic exchange cho phép định tuyến tin nhắn phức tạp dựa trên một routing key mà tin nhắn được gửi kèm và một pattern mà các queues sử dụng khi liên kết với exchange. Routing keys và binding patterns có thể chứa từ wildcards như "#" (khớp với một hoặc nhiều từ) và "*" (khớp với đúng một từ).
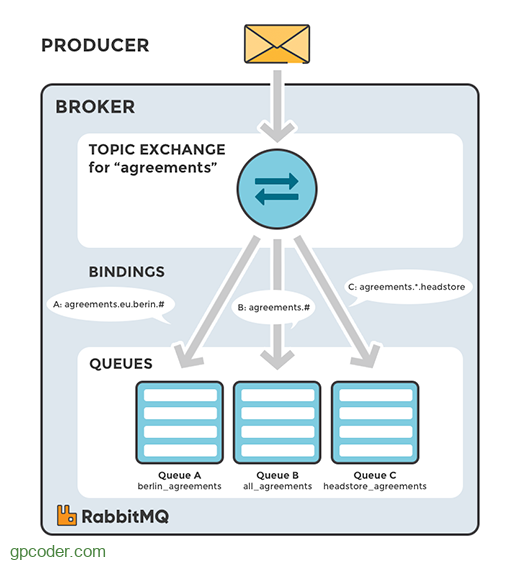
Ví dụ:
agreements.*.headstore : Được đăng ký bởi tất cả những key với pattern bắt đầu bằng agreements, theo sau là một từ bất kỳ và kết thúc là headstore.
agreements.# : Được đăng ký bởi tất cả các key bắt đầu với agreements.
4.4 Headers Exchange
Headers exchange chuyển tiếp tin nhắn dựa vào các thuộc tính header của tin nhắn thay vì routing key. Queues liên kết với exchange này sẽ chỉ nhận tin nhắn nếu headers của tin nhắn khớp với các thuộc tính mà queue đã định nghĩa cho binding. Có thể sử dụng các điều kiện "x-match" như "all" hoặc "any" để kiểm soát cách khớp headers.
Trường hợp này, broker cần một hoặc nhiều thông tin từ application developer, cụ thể là, nên quan tâm đến những tin nhắn với tiêu đề nào phù hợp hoặc tất cả chúng. Headers Exchange rất giống với Topic Exchange, nhưng nó định tuyến dựa trên các giá trị header thay vì routing key.
Một Message được coi là phù hợp nếu giá trị của header bằng với giá trị được chỉ định khi ràng buộc.
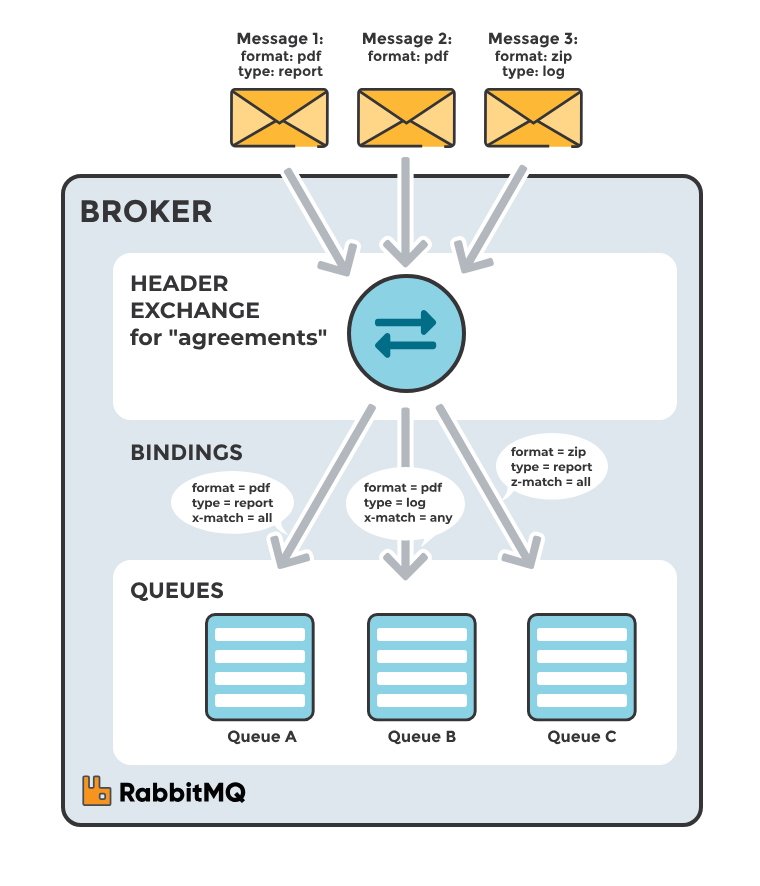
Phù hợp với các tình huống mà việc định tuyến cần dựa trên nhiều thuộc tính của tin nhắn hơn là chỉ một routing key. Ví dụ, bạn có thể muốn tin nhắn được chuyển đến một hàng đợi nếu nó có header "format" với giá trị "pdf" và "type" với giá trị "report".
4.5 Dead Letter Exchange
Nếu không tìm thấy hàng đợi phù hợp cho tin nhắn, tin nhắn sẽ tự động bị hủy. RabbitMQ cung cấp một tiện ích mở rộng AMQP được gọi là “Dead Letter Exchange”. Cung cấp chức năng để chụp các tin nhắn không thể gửi được.
5. Triển khai RabbitMQ
Để tích hợp RabbitMQ vào một ứng dụng Spring Boot, bạn cần thực hiện một số bước cơ bản sau đây. Điều này bao gồm việc thêm các dependency cần thiết, cấu hình kết nối với RabbitMQ, và viết code để gửi và nhận tin nhắn.
Bước 1: Cài Đặt Dependencies
Trước tiên, thêm dependency spring-boot-starter-amqp vào file pom.xml để sử dụng Spring AMQP với RabbitMQ.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
Bước 2: Cấu Hình RabbitMQ
Thêm cấu hình cho RabbitMQ vào file application.properties. Điều này bao gồm thông tin về máy chủ RabbitMQ, cổng, tên người dùng, và mật khẩu.
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
Các bạn cũng có thể cấu hình các thông số này bằng code để linh hoạt hơn
import org.springframework.amqp.rabbit.connection.CachingConnectionFactory;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitMQConfig {
@Bean
public ConnectionFactory connectionFactory() {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
connectionFactory.setHost("localhost");
connectionFactory.setPort(5672);
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
return connectionFactory;
}
}
Khi bạn đã định nghĩa bean ConnectionFactory, Spring Boot sẽ tự động sử dụng nó cho mọi tương tác với RabbitMQ trong ứng dụng của bạn, bao gồm việc gửi và nhận tin nhắn.
Bước 3: Định Nghĩa Queue, Exchange, và Binding
Trong lớp cấu hình, bạn định nghĩa một Queue, một Exchange, và một Binding giữa chúng. Điều này tạo ra cấu trúc cần thiết trong RabbitMQ khi ứng dụng khởi động.
@Configuration
public class RabbitConfig {
@Bean
Queue queue() {
return new Queue("exampleQueue", false);
}
@Bean
TopicExchange exchange() {
return new TopicExchange("exampleExchange");
}
@Bean
Binding binding(Queue queue, TopicExchange exchange) {
return BindingBuilder.bind(queue).to(exchange).with("routing.key.#");
}
}
Bước 4: Gửi Tin Nhắn
Tạo một controller để gửi tin nhắn. RabbitTemplate được sử dụng để gửi tin nhắn đến exchange với một routing key cụ thể.
@RestController
public class MessageSendingController {
@Autowired
private RabbitTemplate rabbitTemplate;
@PostMapping("/send")
public String sendMessage(@RequestBody String message) {
rabbitTemplate.convertAndSend("exampleExchange", "routing.key.specific", message);
return "Message sent";
}
}
Bước 5: Nhận Tin Nhắn
Tạo một listener để nhận tin nhắn. @RabbitListener đánh dấu phương thức nên được gọi khi có tin nhắn trong queue.
@Service
public class MessageListenerService {
@RabbitListener(queues = "exampleQueue")
public void receiveMessage(String message) {
System.out.println("Received message: " + message);
}
}
6. Ưu nhược điểm
Ưu điểm của RabbitMQ
- Đa Protocol Hỗ Trợ: RabbitMQ hỗ trợ nhiều protocol bao gồm AMQP, MQTT, và STOMP, cho phép nó dễ dàng tích hợp vào nhiều loại ứng dụng khác nhau.
- Độ Tin Cậy Cao: RabbitMQ cung cấp các tính năng như durable messages, message acknowledgments, và persistent queues để đảm bảo rằng tin nhắn không bị mất.
- Đa Ngôn Ngữ Lập Trình: Có sẵn thư viện khách hàng cho hầu hết các ngôn ngữ lập trình phổ biến, giúp tích hợp dễ dàng vào các hệ thống hiện có.
- Clustering và High Availability: RabbitMQ hỗ trợ clustering và mirrored queues, giúp xây dựng các hệ thống có khả năng chịu lỗi cao và mở rộng dễ dàng.
- Flexible Routing: Các loại exchanges khác nhau (direct, topic, fanout, headers) cung cấp khả năng định tuyến tin nhắn linh hoạt và mạnh mẽ.
Nhược điểm của RabbitMQ
- Quản lý và Bảo trì: RabbitMQ có thể khó quản lý và bảo trì ở quy mô lớn nếu không có đủ kiến thức và kinh nghiệm.
- Tài nguyên và Hiệu suất: Trong một số trường hợp cụ thể, việc sử dụng RabbitMQ có thể đòi hỏi nhiều tài nguyên hệ thống và có thể không đạt được hiệu suất mong muốn so với một số giải pháp nhẹ nhàng khác.
- Độ Trễ trong Giao tiếp Đồng bộ: Trong các ứng dụng cần giao tiếp đồng bộ nhanh, việc sử dụng một hệ thống message-oriented middleware như RabbitMQ có thể tạo ra độ trễ không mong muốn.
7. Khi nào nên và không nên sử dụng
Nên
- Khi cần một hệ thống message broker đáng tin cậy, hỗ trợ đa protocol và đa ngôn ngữ lập trình.
- Trong các hệ thống phân tán cần đảm bảo việc giao tiếp không đồng bộ và cần độ tin cậy cao.
- Khi cần độ linh hoạt cao trong việc định tuyến tin nhắn giữa các dịch vụ.
- Khi cần một giải pháp có khả năng mở rộng và cao khả năng chịu lỗi.
Không nên
- Khi ứng dụng chỉ cần giao tiếp đồng bộ đơn giản và không cần các tính năng phức tạp của một message broker.
- Trong các ứng dụng nhỏ không yêu cầu khả năng chịu lỗi cao hoặc clustering.
- Khi tài nguyên hệ thống (ví dụ: bộ nhớ và CPU) là một vấn đề lớn và ứng dụng cần giảm thiểu tối đa việc sử dụng tài nguyên.
Quyết định sử dụng RabbitMQ nên dựa trên việc đánh giá kỹ lưỡng các yêu cầu kỹ thuật, kích thước và phạm vi của dự án, cũng như khả năng quản lý và bảo trì hệ thống trong dài hạn.
F. So sánh RabbitMQ và Kafka
Ở trên chúng ta đã cùng đi qua các điểm nổi bật của 2 message broker vô cùng phổ biến này, nhưng mục tiêu thiết kế, kiến trúc và cách sử dụng của chúng khác nhau khá nhiều.
1. Tổng qua so sánh
| Tiêu chí | RabbitMQ | Apache Kafka |
|---|---|---|
| Loại | Message Broker (Message Queue) | Distributed Event Streaming Platform (Log-based) |
| Kiến trúc | Queue-based, push messages | Log-based, pull messages |
| Mô hình chính | Message Queue (AMQP – Advanced Message Queuing Protocol) | Distributed Commit Log (Pub/Sub, Stream processing) |
2. So sánh chi tiết
| Tiêu chí | RabbitMQ | Apache Kafka |
|---|---|---|
| Cách gửi/nhận message | Push-based: RabbitMQ đẩy message đến consumer. | Pull-based: Consumer chủ động lấy message từ Kafka. |
| Thứ tự message | Không đảm bảo tuyệt đối, có thể bị xáo trộn nếu nhiều consumer. | Đảm bảo thứ tự trong cùng một partition. |
| Tốc độ xử lý (Throughput) | Tốc độ trung bình, phù hợp với hệ thống vừa và nhỏ. | Rất cao, thích hợp với hệ thống lớn và dữ liệu thời gian thực. |
| Lưu trữ message | Lưu tạm thời, thường bị xóa sau khi message được xử lý. | Lưu trữ lâu dài theo cấu hình (ngày, tuần...). |
| Replay message | Không hỗ trợ tự nhiên, cần custom hoặc dùng dead-letter queue. | Hỗ trợ tự nhiên, có thể đọc lại từ offset bất kỳ. |
| Độ trễ (Latency) | Thấp, phản hồi nhanh trong môi trường đơn giản. | Có thể cao hơn một chút do lưu trữ và xử lý phân tán. |
| Khả năng mở rộng (Scalability) | Dễ mở rộng theo chiều dọc (scale-up). | Dễ mở rộng theo chiều ngang (scale-out qua partition & broker). |
| Giao thức hỗ trợ | AMQP, MQTT, STOMP, HTTP, WebSocket... | Kafka protocol riêng, hỗ trợ client nhiều ngôn ngữ. |
| Transaction & Acknowledgement | Hỗ trợ transactional message, manual ack, retry linh hoạt. | Hỗ trợ transactional write, ack theo offset, cấu hình phức tạp hơn. |
| Use case chính | Task queue, gửi email, xử lý background job, microservice messaging. | Event streaming, log processing, real-time analytics, data pipeline. |
| Hệ sinh thái mở rộng | Có plugin, nhưng ít công cụ xử lý stream chuyên biệt. | Hệ sinh thái phong phú: Kafka Streams, Connect, KSQL, Schema Registry. |
G. Kết luận
RabbitMQ và Kafka – Mỗi công cụ, một chiến trường
RabbitMQ và Apache Kafka đều là những giải pháp messaging mạnh mẽ, nhưng được sinh ra cho những mục tiêu khác nhau:
🟢 RabbitMQ lý tưởng cho các hệ thống cần xử lý tác vụ nền (background jobs), giao tiếp giữa microservice, cần ACK linh hoạt và retry dễ dàng. Nếu bạn đang xây dựng một hệ thống web hoặc mobile thông thường với các tác vụ như gửi email, thanh toán, xử lý hàng đợi, RabbitMQ là lựa chọn nhanh gọn và đáng tin cậy.
🟢 Apache Kafka lại phù hợp với các hệ thống có lượng dữ liệu lớn, yêu cầu lưu trữ lâu dài, cần phân tích thời gian thực hoặc streaming, chẳng hạn như hệ thống log, clickstream, hoặc big data pipeline. Với khả năng scale tốt và hệ sinh thái phong phú, Kafka là nền tảng mạnh mẽ cho các doanh nghiệp lớn.
⏹️ Tóm lại:
-
Nếu bạn cần hàng đợi nhiệm vụ (task queue) → Chọn RabbitMQ.
-
Nếu bạn cần luồng sự kiện, ghi log, phân tích dữ liệu → Chọn Kafka.
🔅 Việc lựa chọn không nên chỉ dựa trên hiệu năng, mà cần dựa vào kiến trúc hệ thống, mục tiêu nghiệp vụ, yêu cầu kỹ thuật và khả năng mở rộng trong tương lai.
All rights reserved
