Query tuning (Part 1)
Bài đăng này đã không được cập nhật trong 6 năm
Hôm nay chúng ta sẽ đến với một chủ đề mới trong loạt bài viết của mình, đó là Query tuning (tối ưu hóa câu truy vấn). Thực ra là mình định viết tiếp series Laravel mình đang viết dở nhưng mà mình vẫn chưa tìm được ý tưởng mới  , thêm nữa, mình nghĩ SQL cũng là một chủ đề khá cần thiết với anh em mình nên mình đã lựa chọn chủ đề này. Hi vọng bài viết sẽ hữu ích với anh em. Giờ thì vào bài thôi nào
, thêm nữa, mình nghĩ SQL cũng là một chủ đề khá cần thiết với anh em mình nên mình đã lựa chọn chủ đề này. Hi vọng bài viết sẽ hữu ích với anh em. Giờ thì vào bài thôi nào 
Query Tuning là gì?
SQL có thể nói là một trong những kĩ năng không thể thiếu đối với mỗi lập trình viên. Việc viết được ra một câu truy vấn thực sự khá là đơn giản. Tuy nhiên, việc chỉ viết câu truy vấn thôi là chưa đủ, việc đảm bảo việc câu truy vấn luôn được thực thi một cách hiệu quả trong thực tế mới là vấn đề khó. Đó là lý do tại sao chúng ta phải đánh giá hiệu năng truy vấn và tối ưu truy vấn (Query Tuning) nếu hiệu năng thực thi của truy vấn thấp.
Query Tuning có thể hiểu là việc viết lại câu truy vấn để truy vấn được thực thi nhanh hơn, hiệu quả hơn, và là việc tất yếu phải làm nếu truy vấn hiện tại có hiệu năng quá thấp. Vậy làm sao để tối ưu câu truy vấn, tối ưu như thế nào? Chúng ta cùng tìm hiểu nhé!
Query Processing và Query Execution
Để học cách tối ưu thì trước tiên chúng ta cần hiểu được quá trình xử lý và thực thi một câu truy vấn được diễn ra như thế nào.
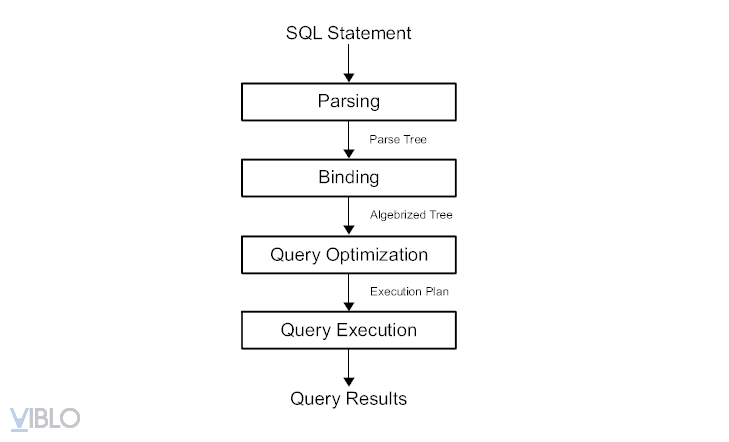
Như bạn có thể thấy, quy trình này gồm:
-
Bước 1 (Parse and binding): Câu truy vấn sẽ được parse (phân tích) thành một
parse-treevà được binding lại thành mộtalgebrized-tree- Input: câu lệnh sql
- Output: biểu thức đại số quan hệ.
- Ví dụ:
Ví dụ:
Input
SELECT balance FROM account WHERE balance < 2500Output
hoặc
-
Bước 2: Tối ưu (Query Optimization)
- Input: biểu thức đại số quan hệ
- Output: kế hoạch truy vấn
Trong phần sau, mình sẽ nói rõ hơn về bước này.
-
Bước 3: Thực thi câu truy vấn (Query Execution)
- Input: kế hoạch truy vấn
- Output: kết quả truy vấn
Query Optimization
Mục đích của bước này là tìm ra kế hoạch thực thi tốt nhất cho câu truy vấn.
Lưu ý:
- Input: biểu thức đại số quan hệ
- Output: kế hoạch truy vấn
Trình tối ưu hóa sẽ liệt kê ra toàn bộ các kế hoạch có thể thực hiện, lấy thông tin về trạng thái của cơ sở dữ liệu hiện tại, đánh giá chi phí của từng kế hoạch và sau đó là chọn ra kế hoạch tốt nhất. Quá trình này gồm 3 bước:
1. Biến đổi tương đương
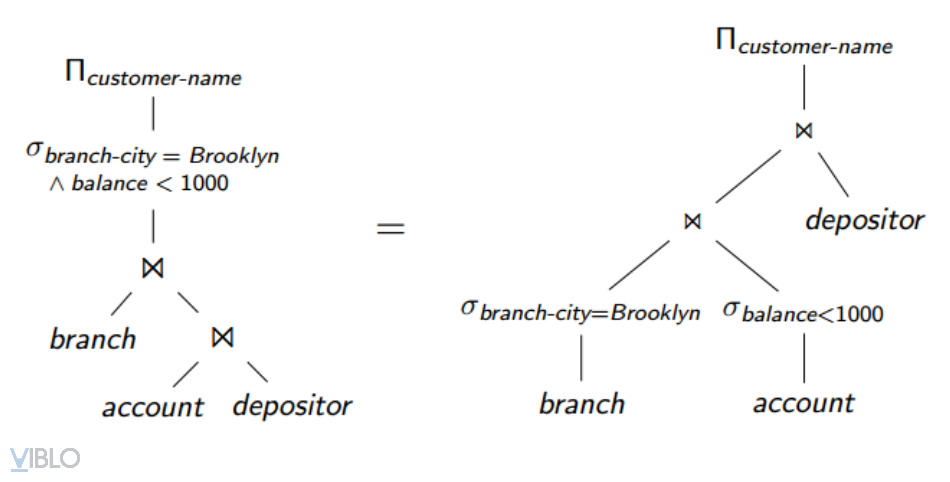
Hai biểu thức quan hệ đại số được coi là equivalence (tương đương) nếu chúng cùng tạo ra một kết quả trên cùng một tập dữ liệu hợp pháp (cơ sở dữ liệu đáp ứng tất cả các ràng buộc toàn vẹn được chỉ định trong lược đồ cơ sở dữ liệu)
Quy tắc biến đổi tương đương là phải biến đổi một biểu thức đại số quan hệ thành một biểu thức đại số quan hệ khác tương đương.
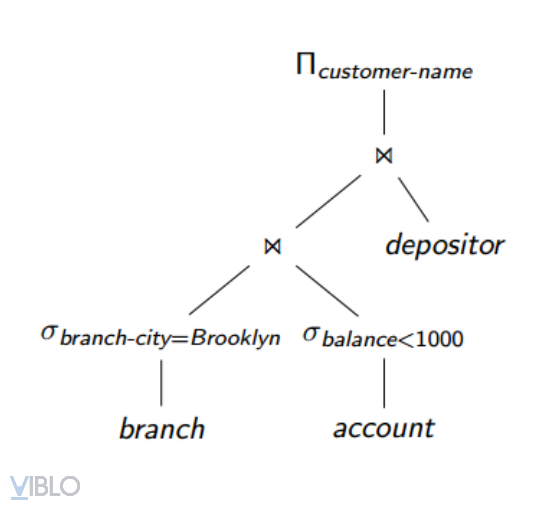
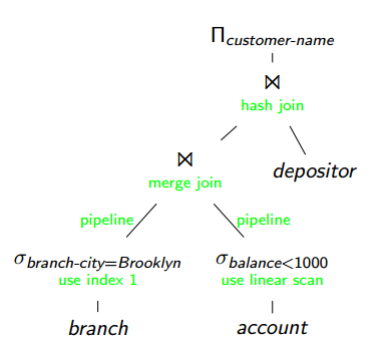
2. Lập các kế hoạch truy vấn
Biểu thức đại số không phải là kế hoạch truy vấn
Một biểu thức đại số có thể tạo ra nhiều kế hoạch truy vấn
Ở bước này sẽ bổ sung:
- Các index sẽ được sử dụng, cho joins hay selects,...
- Thuật toán sử dụng: sort, merge hay join,...
- ...
Ví dụ:
3. Ước tính chi phí
Mục đích của bước này là để tìm ra kế hoạch truy vấn tốt nhất
Đây là chi phí
ƯỚC TÍNH, không phải chi phí thực tế
Chi phí này được ước tính dựa trên các yếu tố như:
- Số bộ dữ liệu trên mỗi quan hệ
- Số lượng blocks trên đĩa cho mỗi quan hệ
- Số lượng giá trị distinct cho mỗi trường
- histogram cho giá trị của mỗi trường
Dựa vào chi phí ước tính, sẽ lựa chọn ra kế hoạch truy vấn "rẻ nhất" cho quá trình query optimization.
Tại sao phải Query Tuning?
Sau khi tìm hiểu về Query Processing, theo bạn thì Query optimization liệu có đủ để tối ưu truy vấn? Câu trả lời là không đủ, bởi vì:
- Các phép biến đổi chỉ là một phần trong kế hoạch truy vấn.
- Chỉ một phần các kế hoạch được sử dụng.
- Chi phí chỉ là ước tính.
Nếu thực hiện Query Tuning để tối ưu câu truy vấn ngay từ đầu Query Processing thì quá trình Query Optimization sẽ được đơn giản hóa và hiệu quả hơn. Vì vậy, chúng ta vẫn cần phải thực hiện Query Tuning.
Khi nào cần Query Tuning
Khi các câu truy vấn chạy quá chậm
- Các truy vấn truy xuất vào quá nhiều vùng nhớ (truy xuất từ nhiều bảng)
- Các truy vấn có đánh index mà không được sử dụng.
Một số cách để Query Tuning
Chỉ lấy những dữ liệu bạn cần:
-
Tránh SELECT *
Liệt kê cụ thể các trường khi sử dụng SELECT sẽ giúp loại bỏ các trường không cần thiết ra khỏi câu truy vấn.
Đặt tên cho kết quả khi SELECT để kiểm tra điều kiện EXISTS
SELECT driverslicensenr, name FROM Drivers WHERE EXISTS (SELECT 'check' FROM Fines WHERE fines.driverslicensenr = drivers.driverslicensenr); -
Tránh DISTINCT
DISTINCT sẽ làm tăng thời gian truy vấn nên nếu không cần thì tốt nhất là bạn không nên sử dụng, đặc biệt là đối với các trường unique.
-
Hạn chế dữ liệu mà bạn trả về bằng cách sử dụng TOP, LIMIT hoặc ROWNUM
Hạn chế sử dụng truy vấn lồng nhau
Việc sử dụng subqueries có thể sẽ không hiệu quả nếu các subqueries này không tương quan (các thuộc tính của truy vấn bên ngoài không được sử dụng ở các truy vấn con).
Như ở ví dụ ở mục tránh SELECT *, sử dụng INNER JOIN sẽ hiệu quả hơn việc sử dụng subquery:
SELECT driverslicensenr, name
FROM Drivers
INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr;
Không sử dụng HAVING khi chỉ WHERE là đủ
HAVING thường được sử dụng với GROUP BY để xét điều kiện giới hạn các nhóm được trả về. Tuy nhiên, nếu bạn sử dụng mệnh đề này trong truy vấn của mình, index sẽ không được sử dụng, điều này có thể làm chậm câu truy vấn.
SELECT state, COUNT(*)
FROM Drivers
WHERE state IN ('GA', 'TX')
GROUP BY state
ORDER BY state
SELECT state, COUNT(*)
FROM Drivers
GROUP BY state
HAVING state IN ('GA', 'TX')
ORDER BY state
Hai câu truy vấn trên sẽ trả về cùng một kết quả trên một cơ sở dũ liệu nhưng query_01 sẽ nhanh hơn vì query_01 sẽ đặt điều kiện để hạn chế kết quả trả về còn query_02 tổng hợp tất cả kết quả sau đó mới dùng HAVING để loại bỏ các state khác "GA" và "TX".
Sử dụng clustering indexes để join
SELECT Employee.ssnum
FROM Employee, Student
WHERE Employee.name = Student.name
SELECT Employee.ssnum
FROM Employee, Student
WHERE Employee.ssnum = Student.ssnum
query_b sẽ hiệu quả hơn query_b vì:
- Join trên hai cluster index sẽ cho phép merge join => hiệu quả truy vấn tốt hơn.
- So sánh số nguyên sẽ nhanh hơn so sánh chuỗi
Lưu ý một số vấn đề hệ thống
-
LIKE và index
Khi sử dụng toán tử LIKE, index sẽ không được sử dụng nếu patern chứa
%hoặc_. Hơn nữa, truy vấn này cũng có thể truy xuất tới rất nhiều bản ghi không cần thiết. -
OR và index
Một số hệ thống không bao giờ sử dụng index khi sử dụng toán tử OR. Lý do là vì indexes được sử dụng để nhanh chóng định vị hoặc tra cứu dữ liệu mà không phải tìm kiếm mọi hàng trong cơ sở dữ liệu.
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr = 123456 OR driverslicensenr = 678910 OR driverslicensenr = 345678;có thể thay thế bằng
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr IN (123456, 678910, 345678); -
NOT và index
Tương tự như OR, index cũng có thể không được sử dụng với toán tử NOT thay vì
SELECT driverslicensenr, name FROM Drivers WHERE NOT (year > 1980);hãy viết:
SELECT driverslicensenr, name FROM Drivers WHERE year <= 1980; -
AND và index
Cũng tương tự như OR và AND, nó sẽ làm chậm câu truy vấn trong một số trường hợp nó được sử dụng một cách không hiệu quả như:
SELECT driverslicensenr, name SELECT driverslicensenr, name FROM Drivers WHERE year >= 1960 AND year <= 1980;bạn có thể đổi thành:
SELECT driverslicensenr, name FROM Drivers WHERE year BETWEEN 1960 AND 1980; -
Order trong mệnh đề FROM: Việc order trong FROM là không thích hợp và sẽ làm chậm truy vấn của bạn trừ trường hợp câu truy vấn có phép JOIN quá nhiều bảng (8 bảng trở lên).
Tài liệu tham khảo: SQL Tutorial: How To Write Better Queries
All rights reserved
