Quá trình đạo tạo ChatGPT
Bài đăng này đã không được cập nhật trong 3 năm
ChatGPT là một phát triển từ InstructGPT, đưa ra một phương pháp mới để tích hợp phản hồi từ con người vào quá trình huấn luyện để đạt được các kết quả phù hợp với ý đồ của người dùng. Việc Học tăng cường từ Phản hồi của con người (RLHF) được miêu tả chi tiết trong bài báo của OpenAI năm 2022 về Huấn luyện các mô hình ngôn ngữ để theo dõi các hướng dẫn với phản hồi từ con người và được đơn giản hóa ở dưới đây.
Bước 1: Mô hình Tinh chỉnh Siêu giám sát (SFT - Supervised Fine Tuning)
Sự phát triển đầu tiên liên quan đến việc tinh chỉnh mô hình GPT-3 bằng cách thuê 40 nhân viên để tạo ra một tập dữ liệu huấn luyện giám sát, trong đó đầu vào có một đầu ra đã biết để mô hình có thể học từ đó. Các đầu vào, hoặc lời nhắn, được thu thập từ các thông tin người dùng thực tế vào Open API. Sau đó, những người đánh dấu đã viết một phản hồi phù hợp với lời nhắn, tạo ra một đầu ra đã biết cho mỗi đầu vào. Mô hình GPT-3 sau đó được tinh chỉnh bằng cách sử dụng tập dữ liệu giám sát mới này, để tạo ra GPT-3.5, còn được gọi là mô hình SFT.
Để tối đa hóa sự đa dạng trong tập dữ liệu lời nhắn, chỉ có thể có 200 lời nhắn từ bất kỳ ID người dùng nào và tất cả các lời nhắn chia sẻ tiền tố chung dài đều bị loại bỏ. Cuối cùng, tất cả các lời nhắn chứa thông tin nhận dạng cá nhân (PII) đã bị loại bỏ.
Sau khi tổng hợp các lời nhắn từ OpenAI API, những người đánh dấu cũng được yêu cầu tạo ra các lời nhắn mẫu để điền vào các danh mục mà chỉ có ít dữ liệu mẫu thực tế. Các danh mục quan tâm bao gồm
- Plain prompts – câu hỏi đơn giản: Là các yêu cầu tùy ý mà không giới hạn bởi loại nào.
- Few-shot prompts – các câu hỏi và câu trả lời mẫu: Là các hướng dẫn chứa nhiều cặp truy vấn/phản hồi, có thể được sử dụng để học từ các ví dụ cụ thể.
- User-based prompts – các câu hỏi dựa trên người dùng: Là các hướng dẫn tương ứng với một trường hợp sử dụng cụ thể đã được yêu cầu cho OpenAI API.
Khi tạo ra các phản hồi, các nhãn viên được yêu cầu cố gắng suy luận xem hướng dẫn từ người dùng là gì. Bài báo mô tả ba cách chính mà các hướng dẫn yêu cầu thông tin.
- Direct - Trực tiếp: "Kể cho tôi về ..."
- Few-shot: Cho hai ví dụ về một câu chuyện, viết câu chuyện khác về chủ đề tương tự.
- Continuation - Tiếp tục: Được cho bắt đầu của một câu chuyện, hãy hoàn thành nó.
Tổng hợp các hướng dẫn từ OpenAI API và được viết bởi các nhân viên dẫn đến 13.000 mẫu đầu vào/đầu ra để sử dụng cho mô hình được giám sát.
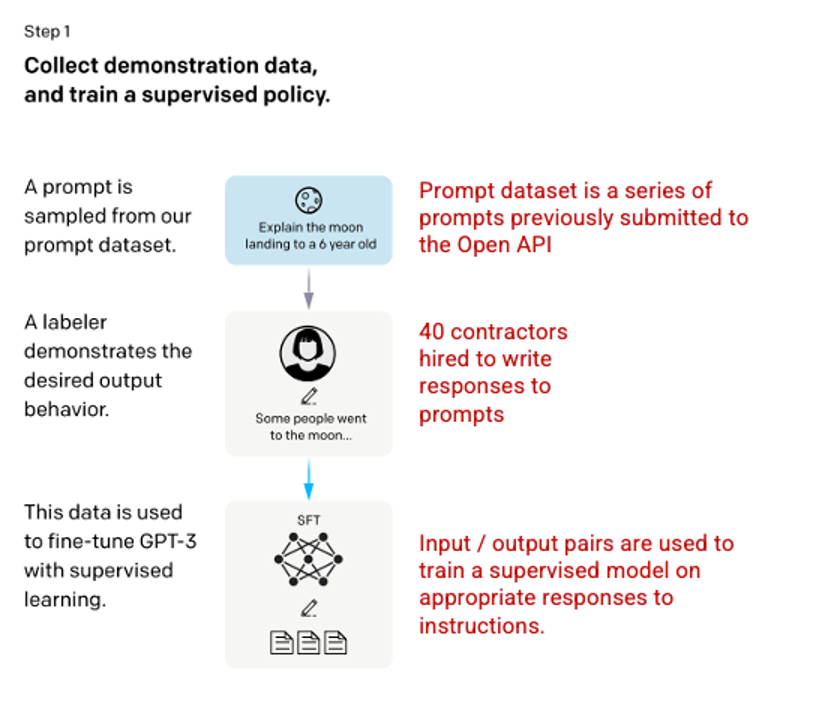
Picture 3.1.11.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. Additional context added in red (right) by the author.
Bước 2: Reward Model
Sau khi mô hình SFT được huấn luyện ở bước 1, mô hình sẽ tạo ra các phản hồi tương thích hơn với yêu cầu của người dùng. Bước cải tiến tiếp theo là huấn luyện một mô hình phần thưởng (reward model) trong đó đầu vào của mô hình là một chuỗi các yêu cầu và phản hồi, và đầu ra là một giá trị scaler được gọi là phần thưởng (reward). Mô hình phần thưởng được yêu cầu để tận dụng Học tăng cường (Reinforcement Learning) trong đó một mô hình học để tạo ra các đầu ra để tối đa hoá phần thưởng của nó (xem bước 3).
Để huấn luyện mô hình phần thưởng, những người đánh giá được trình bày 4 đến 9 đầu ra của mô hình SFT cho một yêu cầu đầu vào duy nhất. Họ được yêu cầu xếp hạng các đầu ra này từ tốt nhất đến xấu nhất, tạo ra các kết hợp xếp hạng đầu ra như sau.
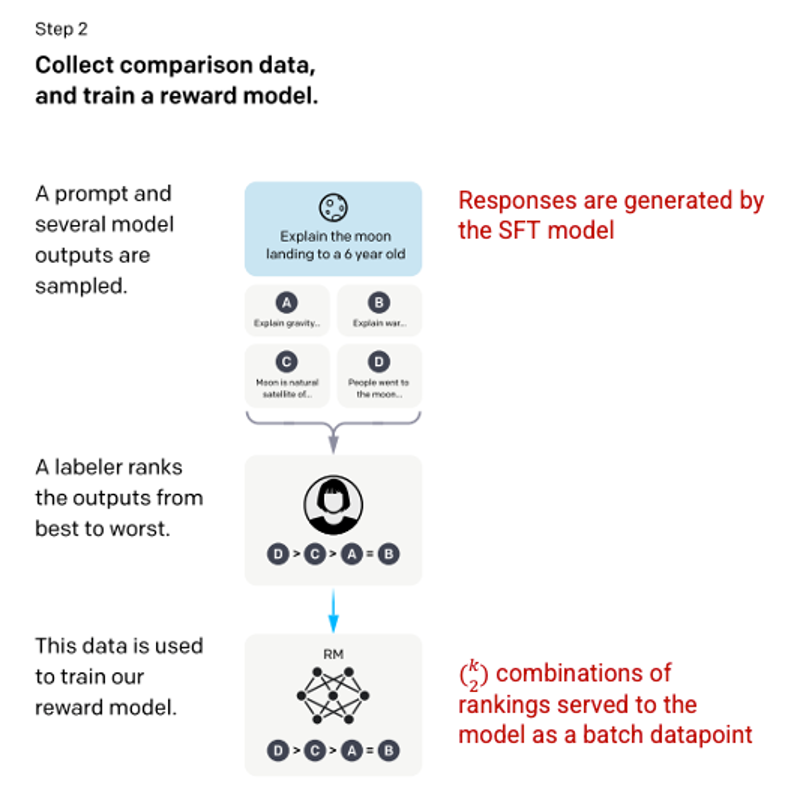 Picture 3.1.12.en Example of response ranking combinations
Picture 3.1.12.en Example of response ranking combinations
Việc bao gồm từng kết hợp vào mô hình là một điểm dữ liệu riêng biệt dẫn đến hiện tượng quá khớp (không thể áp dụng được trên dữ liệu mới). Để giải quyết vấn đề này, mô hình được xây dựng dựa trên mỗi nhóm xếp hạng là một điểm dữ liệu đơn lẻ.
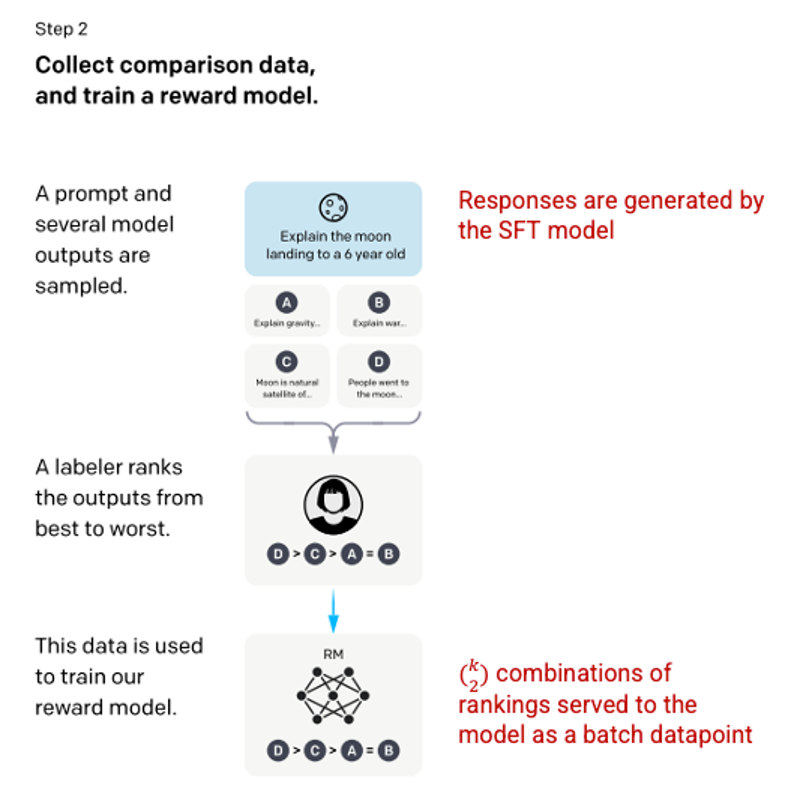 Picture 3.1.13.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. Additional context added in red (right) by the author.
Picture 3.1.13.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. Additional context added in red (right) by the author.
Bước 3: Reinforcement Learning Model – Mô hình học tăng cường
Ở giai đoạn cuối cùng, mô hình được đưa ra một câu hỏi ngẫu nhiên và trả về một câu trả lời. Câu trả lời được tạo ra bằng cách sử dụng 'chính sách' mà mô hình đã học được ở bước 2. Chính sách đại diện cho một chiến lược mà máy học đã học để đạt được mục tiêu của nó; trong trường hợp này, tối đa hóa phần thưởng của nó. Dựa trên mô hình phần thưởng được phát triển ở bước 2, một giá trị phần thưởng được xác định cho cặp câu hỏi và câu trả lời. Phần thưởng sau đó được đưa trở lại vào mô hình để tiến hóa chính sách.
Năm 2017, Schulman et al. giới thiệu Proximal Policy Optimization (PPO), phương pháp được sử dụng để cập nhật chính sách của mô hình khi mỗi câu trả lời được tạo ra. PPO tích hợp một khoản phạt Kullback–Leibler (KL) per-token từ mô hình SFT. KL divergence đo độ tương tự của hai hàm phân phối và phạt khoảng cách cực đại. Trong trường hợp này, sử dụng phạt KL giảm khoảng cách mà các câu trả lời có thể khác so với đầu ra của mô hình SFT được đào tạo ở bước 1 để tránh quá tối ưu hóa mô hình phần thưởng và lệch quá nhiều so với tập dữ liệu ý định của con người.
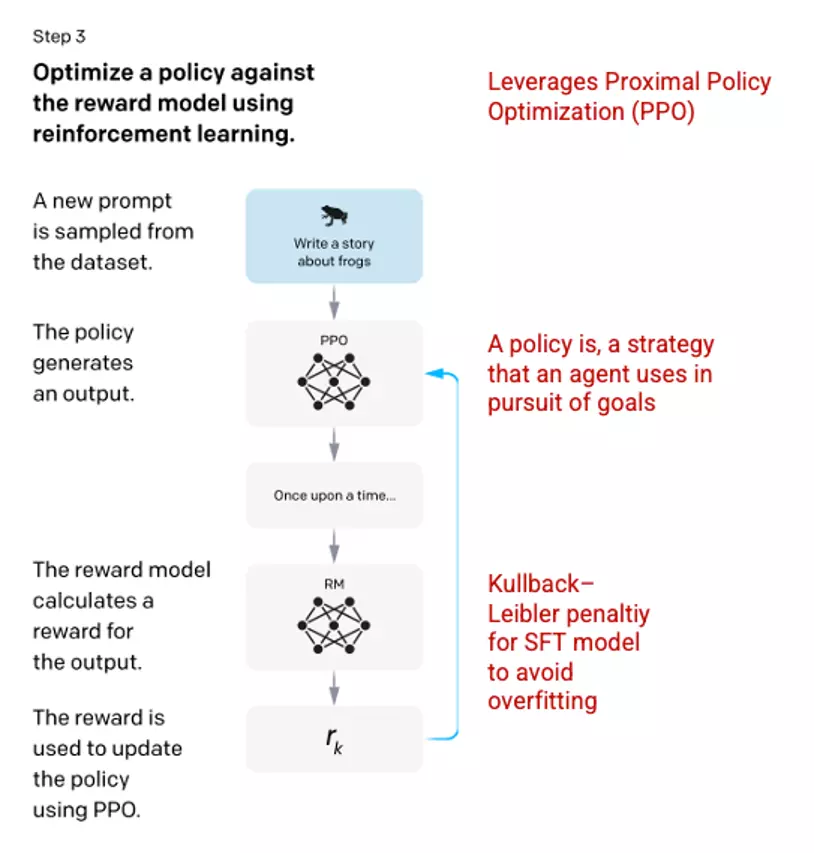 Picture 3.1.14.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. Additional context added in red (right) by the author.
Picture 3.1.14.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. Additional context added in red (right) by the author.
Các bước 2 và 3 của quá trình có thể lặp lại nhiều lần trong thực tế, tuy nhiên điều này chưa được thực hiện nhiều.
All rights reserved
