Phân cụm K-Means (K-Means clustering)
Bài đăng này đã không được cập nhật trong 7 năm
Hôm nay mình sẽ trình bày về cách phân cụm dữ liệu dưới mô hình toán học với hy vọng có một cái nhìn dễ hơn về lý thuyết của một bài toán của machine learning: Với bài toán học phi giám sát, làm sao ta có thể sắp xếp dữ liệu vào các nhóm tương ứng? Bài viết này sẽ trình bày một phương pháp đơn giản để có thể thực hiện được việc này là phương pháp phân cụm K-Means.
1. Đặt vấn đề
Giả sử ta có một tập dữ liệu và ta cần phải nhóm các dữ liệu có tính chất tượng tự nhau vào các cụm khác nhau chưa biết trước. Một cách đơn giản để mô phỏng bài toán này là biểu diễn qua cái nhìn hình học. Các dữ liệu có thể coi là các điểm trong không gian và khoảng cách giữa các điểm có thể được coi là thông số mức độ giống nhau của chúng. 2 điểm càng gần nhau thì chúng càng giống nhau.

Với cách nhìn hình học như vậy, ta có thể viết lại bài toán dưới dạng hình thức như sau:
Dữ liệu: tập dữ liệu X ∈ R^(nd) gồm n điểm dữ liệu có dd chiều Nhiệm vụ: phân tập dữ liệu ra làm kk cụm các dữ liệu tương tự nhau. Đương nhiên là k ≤ n. Để giải quyết bài toàn này, người ta có thể dùng 1 phương pháp đơn giản là giải thuật K-Means mà ta sẽ cùng thảo luận trong bài viết này.
2. Giải thuật
2.1. Lý thuyết
Về cơ bản giải thuật được thực hiện như sau:
1. Khởi tạo
- Chọn ngẫu nhiên kk điểm bất kì làm điểm trung tâm
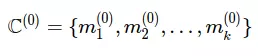
2. Nhóm dữ liệu
- Nhóm mỗi điểm dữ liệu vào 1 cụm có điểm trung tâm gần nhất với nó
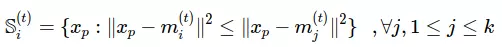
- Nếu các cụm sau khi nhóm không thay đổi so với trước khi nhóm thì ta dừng giải thuật
3. Cập nhập trung tâm
- Với mỗi cụm sau khi nhóm lại, ta cập nhập lại điểm trung tâm của chúng bằng cách lấy trung bình cộng
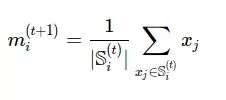
- Quay lại bước 2
Để dễ hiểu hơn bạn có thể thao tác với mô phỏng dưới đây để xem thuật toán được thực thi thế nào nhé. Thao tác cơ bản như sau:
- Bước 1: Tạo dữ liệu mô phỏng bằng nút Tạo dữ liệu với số điểm dữ liệu và số cụm tương ứng.
- Bước 2: Sử dụng nút Tiếp theo để chạy một vòng lặp: 2. Nhóm dữ liệu ⇄ 3. Cập nhập trung tâm. Ngoài ra, bạn cũng có thể click ngay vào mà hình mô phỏng để chạy vòng lặp cực kì tiện lợi.
- Bước 3: Nếu bạn muốn khởi động lại vòng lặp mà vẫn giữ nguyên tập dữ liệu hiện tại thì có thể sử dụng nút Khởi tạo lại.

Ban đầu các điểm trung tâm khởi tạo x sẽ được gắn một cách ngẫu nhiên. Sau mỗi vòng lặp thì màu của chúng được thay đổi và điểm trung tâm mới được cập nhập. Khi giải thuật thực hiện xong thì việc cập nhập thế này sẽ dừng lại.

2.2. Lập trình
# Số nhóm K
K = 6
# Tạo dữ liệu gồm 1500 điểm quây tụ lại với K nhóm ở trên
from sklearn.datasets import make_blobs
X,_ = make_blobs(n_samples=1500,
n_features=2,
centers=K,
cluster_std=0.5,
shuffle=True,
random_state=0)
# Các hàm thành phần thực hiện giải thuật
# 1. init center points
def init_centers(X, k):
return X[np.random.choice(X.shape[0], k, replace=False)]
# 2. grouping
def group_data(X, centers):
y = np.zeros(X.shape[0])
for i in range(X.shape[0]):
d = X[i] - centers
d = np.linalg.norm(d, axis=1)
y[i] = np.argmin(d)
return y
# 3. Update center points
def update_centers(X, y, k):
centers = np.zeros((k, X.shape[1]))
for i in range(k):
X_i = X[y==i, :]
centers[i] = np.mean(X_i, axis = 0)
return centers
# kmeans algorithm
def kmeans(X, k):
centers = init_centers(X, k)
y = []
while True:
# save pre-loop groups
y_old = y
# grouping
y = group_data(X, centers)
# break while loop if groups are not changed
if np.array_equal(y, y_old):
break
# update centers
centers = update_centers(X, y, k)
return (centers, y)
Đoạn mã trên sẽ cho kết quả như hình dưới đây:
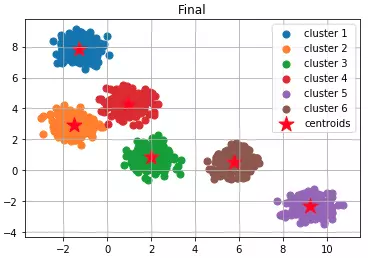
Về cơ bản, giải thuật gồm 3 phần chính như phần lý thuyết đề cập phía trên:
-
- Khởi tạo K điểm trung tâm: init_centers(X, k)
-
- Phân cụm dựa trên điểm trung tâm: group_data(X, centers)
-
- Cập nhập lại các điểm trung tâm của mỗi cụm: update_centers(X, y, k)
3. Hạn chế và dị bản
3.1. Cần biết số nhóm trước
Dễ thấy rằng điều kiện đầu vào của giải thuật bắt buộc phải chỉ rõ giá trị của kk, nhưng trong thực tế không phải lúc nào ta cũng có thể biết trước được có bao nhiêu nhóm cả. Vấn đề này có thể cải thiện dựa vào một số phương pháp sau:
- Phương pháp Elbow
- Phương pháp X-means
3.2. Khởi tạo ảnh hưởng tới chất lượng
Vị trí của các điểm khởi tạo có ý nghĩa lớn tới tốc độ và độ chính xác của thuật toán. Để phần nào khắc phục được tình trạng này, người ta có thể sử dụng một số cách như:
- Chạy giải thuật nhiều lần với mỗi cách khởi tạo khác nhau và chọn lấy cách đưa ra kết quả tốt nhất
- Sử dụng phương pháp khởi tạo K-Means++
Bài viết còn nhiều sơ sài mong mọi người thông cảm!!!
All rights reserved
