[Phần 1] Aerospike bạn đã biết gì chưa?
Bài đăng này đã không được cập nhật trong 4 năm
 Xem thêm: https://engineering.admicro.vn/aerospike-ban-da-biet-gi-chua
Nếu đã từng nghe đến Redis (Remote Dictionary Server) thì chắc hẳn mọi người đã hiểu nó là gì đúng không ? Aerospike cũng vậy, nhưng Aerospike là cái gì, tại sao nó lại "cũng vậy" và có gì thú vị mà tôi viết về em nó, hãy cùng tôi phiêu lưu trên chuyến hành trình tìm hiểu về em này nhé.
Xem thêm: https://engineering.admicro.vn/aerospike-ban-da-biet-gi-chua
Nếu đã từng nghe đến Redis (Remote Dictionary Server) thì chắc hẳn mọi người đã hiểu nó là gì đúng không ? Aerospike cũng vậy, nhưng Aerospike là cái gì, tại sao nó lại "cũng vậy" và có gì thú vị mà tôi viết về em nó, hãy cùng tôi phiêu lưu trên chuyến hành trình tìm hiểu về em này nhé.
1. Giới thiệu
Như mọi người đã biết, In-memory DB mang đến 1 tốc độ đáng kinh ngạc, còn NoSQL mang đến sự linh hoạt của dữ liệu. Sự kết hợp giữa In-memory DB và NoSQL là một sự kết hợp vô cùng mạnh, nó mang đến lợi ích rất lớn cho doanh nghiệp trong những bài toán kinh doanh của họ. Mình sẽ nói sơ qua về 2 điều này:
- NoSQL: với CSDL truyền thống thì khó mở rộng hoặc thay đổi cấu trúc của dữ liệu, còn NoSQL thì không cần xác định trước dữ liệu gồm những gì, điều này mang lại hiệu suất nhanh và khả năng mở rộng cho dữ liệu
Ví dụ : hôm nay cô gái này chưa có người yêu nhưng ngày mai cô ấy lấy chồng -> không thể tính toán trước mọi trường hợp xảy ra. Cũng như không thể tính toán trước được những thông tin sẽ có là gì?
- In-memory DB: dữ liệu được lưu trữ trên RAM. Như đã biết lưu trữ trên RAM thì tốc độ read/write nhanh hơn rất nhiều so với dữ liệu được lưu trữ trên HDD hoặc SSD. Điều này giúp tăng tốc độ tương tác với dữ liệu.
Ví dụ: crush của bạn đăng 1 bức ảnh, bạn muốn là người thả tym đầu tiên, bạn bấm vào nút thả tym, nhưng do ứng dụng đó không cập nhật lại cho bạn ngay nên bạn ngỡ chưa bấm, bạn bấm lại 1 lần nữa thành ra bạn không những không thả tym mà còn không phải là người đầu tiên -> không ấn tượng -> mất crush
Aerospike Database chính là sự kết hợp hoàn hảo của 2 điều trên, đây là một cơ sở dữ liệu phân tán, có thể mở rộng. Với 3 mục tiêu chính:
- Tạo ra 1 nền tảng linh hoạt, có thể mở rộng cho các ứng dụng
- Cung cấp sự mạnh mẽ và độ tin cậy (như ACID) từ cơ sở dữ liệu truyền thống
- Cung cấp sự hoạt động hiệu quả với giảm thiểu sự tham gia thủ công.
Các bài toán sử dụng của các doanh nghiệp trên thế giới:
- AI/ML: cải thiện về việc lấy data từ các nguồn khác nhau trong thời gian thực.
- Fraud Prevention: Xử lý dữ liệu nhanh chóng, giảm tối đa gian lận
- Internet of Things: Tối ưu hoá nơi quản lý dữ liệu
Ngoài các bài toán trên, cá nhân tôi và team đã áp dụng và giải quyết các bài toán sau:
- Notification của ứng dụng: dùng làm cache list notification cho user, giúp việc lấy danh sách notification cho user nhanh chóng.
- Cảnh báo chứng khoán (app CafeF): với quy mô 500.000 user và thị trường chứng khoán biến động liên tục, mà mỗi user có nhu cầu cảnh báo giá với nhiều mã. Nên cần quản lý các cảnh báo và đưa ra thông tin kịp thời.
- Quản lý danh sách mã chứng khoán người dùng theo dõi (app CafeF): tin tức rất quan trọng đối với người chơi chứng khoán, để update thông tin kịp thời cần phải gửi tin tức liên quan đến mã chứng khoán mà user theo dõi một cách nhanh chóng.
- Counter like, share, comment (mạng xã hội Lotus): cập nhật và đưa ra thông số của bài viết trong ứng dụng mạng xã hội.
- Quản lý hoạt động của user (mạng xã hội Lotus): cập nhật các hoạt động khi người dùng sử dụng mạng xã hội.
2.Kiến trúc
2.1 Tổng quan
 Trên đây là kiến trúc tổng quan của 1 hệ thống sử dụng Aerospike Database. Kiến trúc trên gồm có 3 layer:
Trên đây là kiến trúc tổng quan của 1 hệ thống sử dụng Aerospike Database. Kiến trúc trên gồm có 3 layer:
- Client Layer: bao gồm các thư viện, API Aerospike, theo dõi và biết dữ liệu đang nằm ở đâu trong cluster.
- Distribution Layer: quản lý các nodes trong cluster và automates fail-over, intelligent re-balancing và data migration.
- Data Layer: lưu trữ dữ liệu
2.2 Cluster Management
Trong 1 cluster gồm có nhiều nodes Aerospike, các node này có vai trò như nhau, không có master node ,mỗi node này sẽ tự động được gán với 1 định danh: <cluster_key, succession_list>
- cluster_key: 8 bytes, là ID của node, sẽ thay đổi với mỗi lần cluster view thay đổi
- sucession_list: danh sách các nodeID có trong cụm
Nhờ định danh trên mà 1 node biết được trong cluster đang có những node nào.
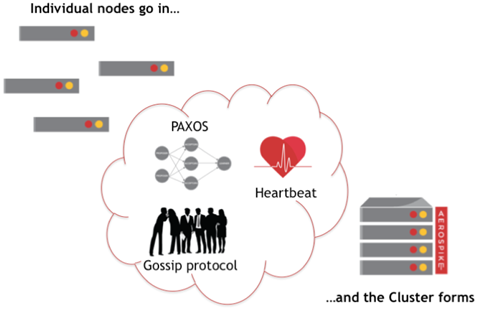
Để biết được điều đó, các nodes theo dõi lẫn nhau để phát hiện ra sự thay đổi bằng cách sử dụng cơ chế Heartbeat, nói nôm na Heartbeat là các nodes sẽ gửi message cho nhau và xem có phản hồi lại không.
Kiểu như là Alo anh Bình Gold đây phải không ạ, à nhầm... alo anh hàng xóm có đó không sang sửa giúp em ống nước, nếu hàng xóm trả lời thì có nhà, còn nếu gọi mãi không trả lời thì khả năng phải gọi anh khác.
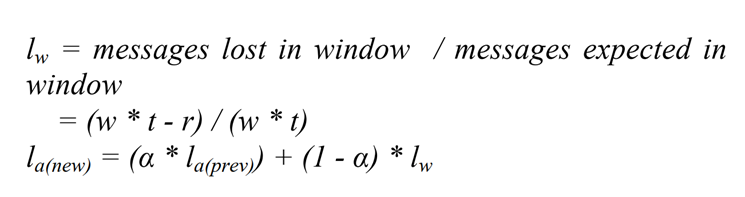
- t: khoảng thời gian gửi message
- w: độ dài của sliding window
- r: số lượng message nhận được trong sliding window
- l(w): số message bị mất trong sliding window
- l(a_prev): trung bình message bị mất tính đến hiện tại
- l(a_new): trung bình message mới nhất
Trên đây là công thức tính sự mất mát message, nếu dưới 1 ngưỡng nào đó thì xác định rằng node đó không tồn tại.
Sau khi phát hiện ra sự thay đổi của cluster (cluster view change), các nodes khác sử dụng Paxos-based gossip voting để xác định các nodes nào đang tồn tại. Thuật toán Aerospike Smart Partitions sẽ tự động phân bổ lại các partitions và cân bằng cluster.
3. Data distribution
3.1 Tổng quan
Sử dụng kiến trúc Share-Nothing:
- Mỗi node trong cluster đều giống hệt nhau
- Tất cả các nodes đều là "đồng nghiệp"
- Không có single point of failure
 Nhìn hình trên mọi người cảm thấy khó hiểu đúng không? Cứ từ từ tôi sẽ giải thích từng phần:
Nhìn hình trên mọi người cảm thấy khó hiểu đúng không? Cứ từ từ tôi sẽ giải thích từng phần:
 Trong 1 cluster sẽ có namespace, mỗi namespace là 1 collection của data, mỗi namespace này sẽ được chia ra thành 4096 partitions.
Trong 1 cluster sẽ có namespace, mỗi namespace là 1 collection của data, mỗi namespace này sẽ được chia ra thành 4096 partitions.
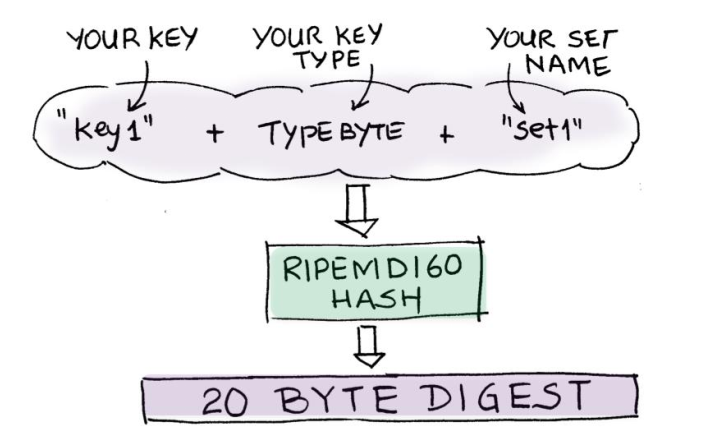
1 record sẽ có 1 key (key-value), key này sẽ được hashing (băm) ra digests bằng cách sử dụng RIPEMD160. Sử dụng 12 bits của digests để phân bổ vào các partitions (2^12 = 4096), lúc này data sẽ được phân bổ đều vào 4096 partitions.
 Aerospike sử dụng random hasing để phân bổ các partitions này vào các nodes trong cluster. Với mỗi partition thì sẽ có 1 bản chính (master) và nhiều bản phụ (replica) phân bổ cho các nodes, vậy ở đây ta sẽ có master đối với partition (còn giữa các nodes vẫn tương đương nhau). Sau đây là ví dụ với cluster có 5 node với hệ số replica là 3:
Aerospike sử dụng random hasing để phân bổ các partitions này vào các nodes trong cluster. Với mỗi partition thì sẽ có 1 bản chính (master) và nhiều bản phụ (replica) phân bổ cho các nodes, vậy ở đây ta sẽ có master đối với partition (còn giữa các nodes vẫn tương đương nhau). Sau đây là ví dụ với cluster có 5 node với hệ số replica là 3:
 Bảng trên gọi là partition table, mỗi partition sẽ có REPLICATION_LIST là thứ tự các node(phần tử đầu là master, sau đó đến các replica và các node khác trong cụm) nhưng nó có ý nghĩa gì ? Loằng ngoằng hả ? Không đâu, làm gì có gì tự nhiên sinh ra, ý đồ cả đấy.
Bảng trên gọi là partition table, mỗi partition sẽ có REPLICATION_LIST là thứ tự các node(phần tử đầu là master, sau đó đến các replica và các node khác trong cụm) nhưng nó có ý nghĩa gì ? Loằng ngoằng hả ? Không đâu, làm gì có gì tự nhiên sinh ra, ý đồ cả đấy.
3.2 Data khi các vấn đề xảy ra với node
Khi 1 node có vấn đề hoặc được sửa thì cluster sẽ xử lý ra sao?, data sẽ như thế nào?, chúng ta cùng phân tích từng trường hợp nhé
3.2.1 Node goes down

 Nhìn vào bảng trên có thể thấy được từng partition sẽ biết master node, replica node. Khi node C die REPLICATION_LIST của từng partition sẽ dịch chuyển sang trái.
Nhìn vào bảng trên có thể thấy được từng partition sẽ biết master node, replica node. Khi node C die REPLICATION_LIST của từng partition sẽ dịch chuyển sang trái.
Partition 0: node C không là gì cả, chỉ góp mặt trong list thôi nên không có điều gì xảy ra.
Partition 1: node C đang là replica node, khi này node A sẽ được lên làm replica node và data sẽ mirgate từ node E(master) sang node A.
Partition 4049: node C đang là master node, khi này node B đang là replica node sẽ được lên làm master node, node A sẽ được làm replica node và data sẽ mirgate từ node B sang node A
3.2.2 Node rejoin the cluster
 Node C được phục hồi trước khi cập nhật partition table mới, hắn đã trở lại, điều gì sẽ xảy ra.
Node C được phục hồi trước khi cập nhật partition table mới, hắn đã trở lại, điều gì sẽ xảy ra.
Partition 0: node C không là gì nên không có điều gì xảy ra
Partition 1: node C sẽ trở lại làm replica node, lúc này node E sẽ cập nhật lại cho node C các data mà node C đã bỏ lỡ khi bị die
Partition 4094: node C sẽ trở lại làm master node và node B sẽ tạm thời làm master node cho đến khi node C update xong data từ node B
3.2.3 Adding a node

 Chăn đang ấm tự dưng có thằng chui vào, node F được thêm vào cluster:
Chăn đang ấm tự dưng có thằng chui vào, node F được thêm vào cluster:
Partition 0: node F được làm replica node, data sẽ mirgate từ node B sang node F.
Partition 1: node F được làm master node, khi này node E sẽ tạm thời làm master node cho đến khi migrate data sang node F xong.
Partition 4094: node F chỉ được bổ sung vào danh sách và không có vai trò gì nên không có điều gì xảy ra.
4. Data Storage
4.1 Data model
namespace là vùng chứa data cấp cao nhất. Cách thu thập data liên quan đến cách lưu trữ và quản lý. Trong namespace bao gồm các records, indexes và policies. Các policies của namespace bao gồm:
- Data được lưu trữ thế nào
- Có bao nhiêu replicas
- Hết hạn đối với records
1 database có thể có nhiều namespace riêng biệt, mỗi namespaces có các policies khác nhau để phù hợp với ứng dụng.
 ns1: Index lưu trên RAM, data lưu trên SSD. Trường hợp này đảm bảo data được toàn vẹn
ns1: Index lưu trên RAM, data lưu trên SSD. Trường hợp này đảm bảo data được toàn vẹn
ns2: Index + data lưu trên RAM. Trường hợp này việc read/write rất nhanh, nhưng data sẽ mất hoàn toàn khi có sự cố.
ns3: Index + data lưu trên SSD. Trường hợp này việc read/write chậm nhưng Index + data được đảm bảo.
ns4: Index + data lưu trên RAM và data được lưu thêm trên disk. Trường hợp này việc read/write tương tự như ns2 (rất nhanh) và cũng đảm bảo data được an toàn.
 Set: trong namespace các records được nhóm lại với nhau gọi là set
Set: trong namespace các records được nhóm lại với nhau gọi là set
Có thể hiểu tương tự như trong MySQL, namespace là database, set là table
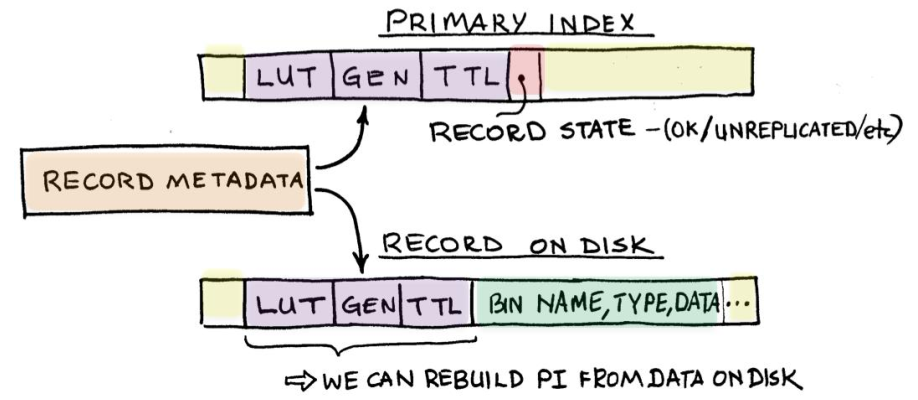
Record: là đơn vị lưu trữ cơ bản trong database, các records có thể thuộc về một namespace hoặc một set trong namespace, mỗi record được xác định bằng key. Record bao gồm:
- key: định danh duy nhất của record
- metadata: chứa thông tin version, TTL (time to live) và LUT (last update time)
- bin: dữ liệu của record, có kiểu dữ liệu riêng. Nhiều bin có thể được lưu trữ trong 1 record. Có thể hiểu như bin là column.
4.2 Index
4.2.1 Primary index
Aerospike sử dụng cấu trúc Red-Black Tree để lưu trữ Primary Index, theo ý tưởng ban đầu mỗi partition có 1 Red-Black Tree, nhưng khi data trong 1 partition tăng lên thì chi phí tìm kiếm tăng lên, để giải quyết vấn đề đó partition sẽ tách ra làm nhiều Red-Black Tree.
Nếu Primary Index được lưu trên RAM và bị mất khi node có sự cố (vì dữ liệu trên RAM sẽ bị mất hoàn toàn khi node bị tắt) thì có thể khôi phục lại dựa trên data (được lưu trên ổ cứng).
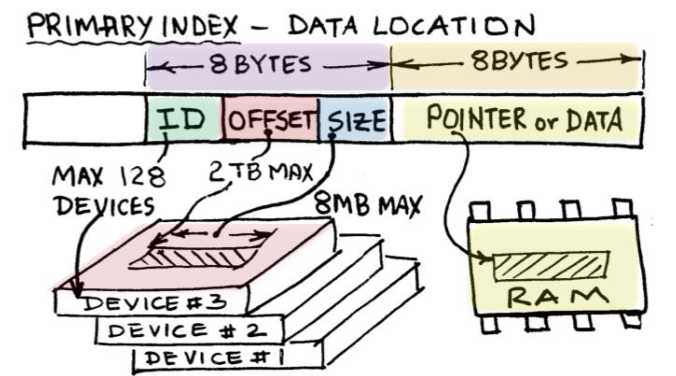
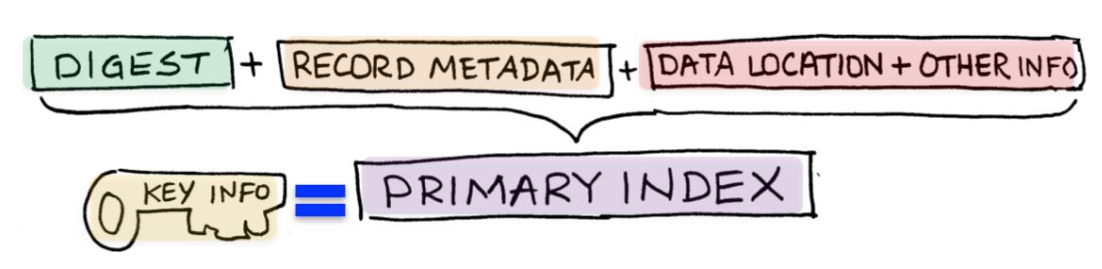 Kích thước của Primary Index là 64 bytes
Trong đó:
Kích thước của Primary Index là 64 bytes
Trong đó:
- Digest
![image.png]()
- Record metadata
![image.png]()
- Data location
![image.png]()
4.2.2 Secondary Index
Là 1 cấu trúc dữ liệu được sử dụng để định vị nhanh chóng tất cả các bản ghi trong 1 namespace hoặc 1 set, dựa trên value của bin trong record. Có thể hiểu đơn giản là đánh Index trên 1 trường của Record
5. Read and write transaction
Client khi read/write data, dựa vào partition table thì nó sẽ biết record đó thuộc PartitionID nào và tương ứng với partition đó là các node nào. Partition table này sẽ được client tải xuống và update liên tục trong thời gian connect tới server.
5.1 Read transaction

 Dựa vào 2 hình trên có thể thấy các bước:
Dựa vào 2 hình trên có thể thấy các bước:
- Dựa vào key của Record sẽ biết được record đó đang ở partition nào và partition đó nằm ở những node nào (master, replica)
- Nhảy vào master node đầu tiên (nhắc lại lần nữa nhé master node đối với partition), lấy ra Primary Index và dựa vào thông tin chứa trong Primary Index sẽ lấy ra data.
- Nếu read từ master node thất bại thì sẽ đọc từ replica node.
5.2 Write transaction

 Các bước đối với write:
Các bước đối với write:
- Dựa vào key của Record sẽ biết được record sẽ được ghi vào partition nào và partition đó có những master node, replica node là gì.
- Record được ghi vào master node đầu tiên đồng thời add Primary Index vào Red-Black Tree tương ứng.
- Master node thông báo success thì sẽ write vào các replica node
6. Kết luận
Tóm cái váy lại bài viết này có những ý chính sau:
- Aerospike là một database NoSQL với khả năng phân tán cùng với sự tự động hoá cao
- Các nodes trong cluster tự theo dõi và quản lý lẫn nhau
- Data trong Aerospike được phân bố đều cho các nodes giúp cho cluster được cân bằng
- Index được tổ chức hợp lý và mang lại hiệu suất cao cho việc read/write
Dựa vào những gì trình bày ở trên, hi vọng mọi người có thể thấy sức mạnh của Aerospike và cân nhắc dùng cho đúng bài toán.
Lưu ý: Aerospike là caching đừng dùng nó như 1 database để lưu trữ bất hợp lý. Hãy phân tích bài toán thật kỹ để sử dụng cho phù hợp.
Đừng thấy hoa nở mà ngỡ xuân về
Phần cài đặt, chi tiết sử dụng và ưu-nhược điểm hẹn mọi người phần sau nhé.....
All rights reserved
