
PaperQA - Công cụ đánh bại "ảo giác" trong nghiên cứu khoa học
Hiện nay, làn sóng bùng nổ của AI đã kích thích việc ứng dụng rộng rãi các mô hình ngôn ngữ lớn (LLM) như GPT, Copilot,... trong cộng đồng nghiên cứu khoa học, song hạn chế lớn nằm ở việc bối cảnh không đầy đủ và nhiều khía cạnh mang tính chuyên ngành, khoa học trìu tượng, dẫn tới nguy cơ các mô hình LLM tạo ra những kết quả không chính xác hoặc "bịa" ra kết quả. Trong bài viết này, mình sẽ cùng các bạn khám phá PaperQA, một công cụ hiện đại được xây dựng để khắc phục các nhược điểm khi sử dụng các mô hình LLM thuần ở phía trên. PaperQA đã giải quyết vấn đề này bằng cách xây dựng một vòng lặp tác nhân (agentic loop) để thu thập, đánh giá và tổng hợp minh chứng từ các bài báo khoa học.
Giới thiệu về PaperQA
PaperQA là một tác nhân AI (AI Agent) mã nguồn mở chuyên biệt cho việc trả lời các câu hỏi phức tạp dựa trên các bài báo khoa học. Điểm khác biệt lớn nhất của PaperQA so với các chatbot thông thường là khả năng trích dẫn nguồn chính xác (citations) và tổng hợp thông tin từ hàng ngàn tài liệu PDF cùng lúc. Công cụ này giúp các nhà nghiên cứu tiết kiệm hàng giờ đọc tài liệu mà vẫn đảm bảo tính xác thực cao, hạn chế tối đa tình trạng "ảo giác" của AI.
Tại sao chỉ sử dụng các LLM thuần là chưa đủ?
Mặc dù các mô hình ngôn ngữ lớn (LLM) truyền thống như ChatGPT hay Copilot rất mạnh mẽ trong việc tổng hợp thông tin, nhưng chúng vẫn bộc lộ những hạn chế nghiêm trọng khi áp dụng vào nghiên cứu khoa học chuyên sâu.
- Thứ nhất: các mô hình này thường dựa vào bộ nhớ huấn luyện cũ, dẫn đến hiện tượng 'ảo giác' (hallucination)—tức là AI tự tạo ra các thông tin hoặc trích dẫn trông có vẻ thuyết phục nhưng thực chất chưa chắc đã tồn tại.
- Thứ hai: phương pháp tra cứu thông thường chỉ quét qua bề nổi của nội dung (như tiêu đề hoặc tóm tắt) trong khi một bài báo khoa học thường rất dài và bao gồm nhiều hình ảnh, số liệu, phân tích. Do đó các phương pháp truyền thống không thể 'thấu hiểu' các chi tiết kỹ thuật phức tạp nằm sâu trong các bảng biểu hay phương pháp luận của tệp PDF.
- Thứ ba: các LLM này thiếu một quy trình kiểm chứng đa lớp để đánh giá độ tin cậy của từng nguồn tin, khiến người dùng dễ gặp rủi ro khi sử dụng các dữ liệu sai lệch hoặc đã bị rút tòa (retracted). Do đó, đối với những công việc đòi hỏi sự chính xác tuyệt đối và minh bạch về nguồn gốc, các hệ thống như PaperQA là sự thay thế cần thiết nhờ khả năng phân tích sâu và trích dẫn chuẩn xác từng dòng tài liệu."
Agentic workflow
Khác với các AI truyền thống chỉ hoạt động theo một đường thẳng (Hỏi Trả lời), PaperQA2 hoạt động như một vòng lặp tư duy trí tuệ. Tác tử (Agent) trung tâm đóng vai trò là "bộ não" điều phối 4 module chuyên biệt:
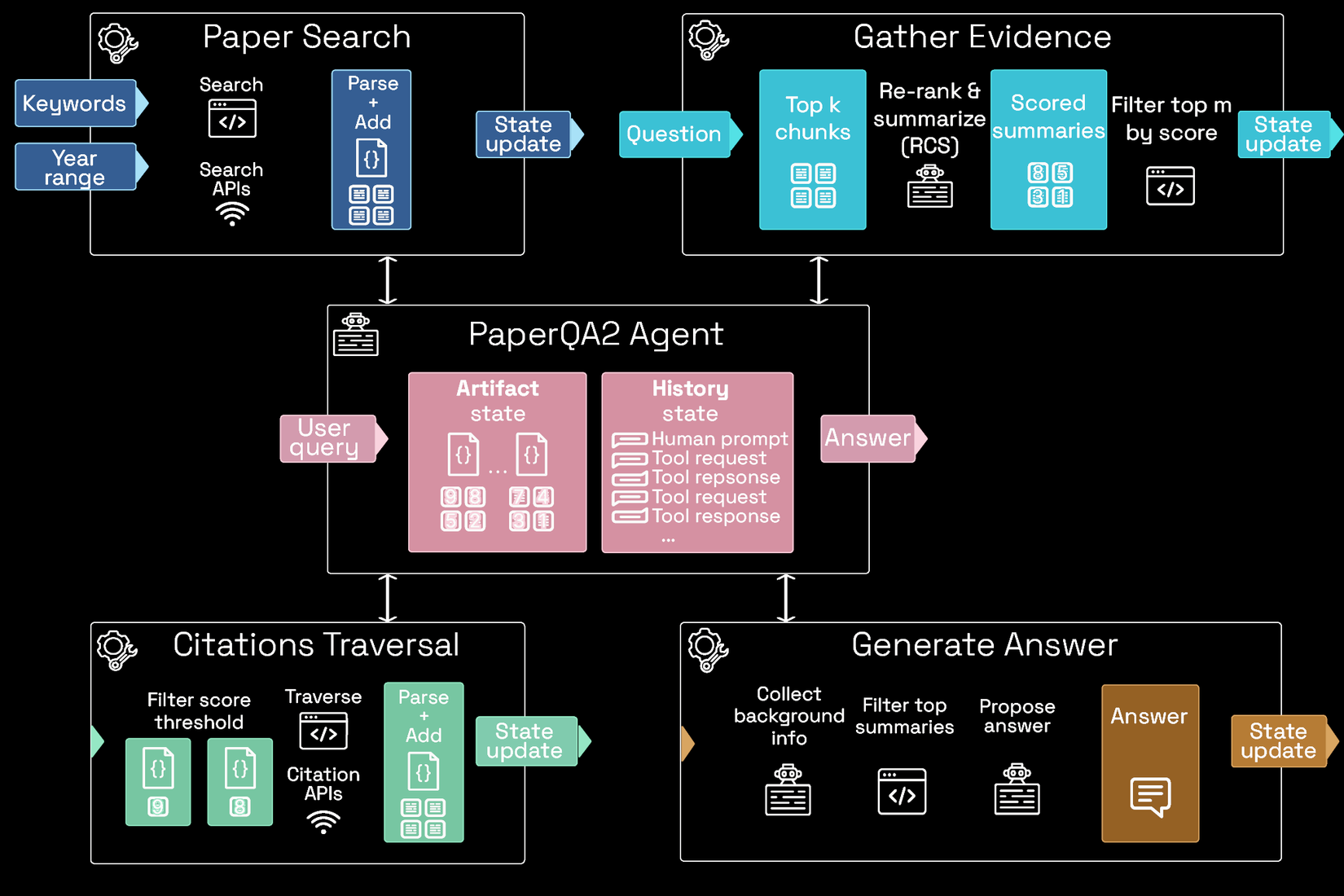
Trung tâm điều phối: Agent
Trước khi đi vào từng module, cần hiểu về "trung tâm chỉ huy" này. Agent duy trì hai trạng thái quan trọng xuyên suốt quá trình:
- Artifact State (Trạng thái vật thể): Lưu trữ toàn bộ tệp PDF, các đoạn văn bản đã trích xuất, và dữ liệu thô.
- History State (Trạng thái lịch sử): Ghi lại mọi suy luận, các yêu cầu gọi công cụ (tool requests) và phản hồi từ hệ thống (tool responses). Điều này cho phép Agent tự kiểm tra: "Mình đã tìm đủ chưa? Dữ liệu này có mâu thuẫn không?".
1. Module: Paper Search (Tìm kiếm và Sàng lọc Tài liệu)
Thay vì chỉ tìm kiếm một cách thụ động, module này đóng vai trò như một chuyên viên quản lý thư viện, biết cách tối ưu hóa các câu lệnh để tìm đúng tài liệu cần thiết.
- Mở rộng truy vấn (Query Expansion): Khi bạn đặt một câu hỏi, Agent không dùng nguyên văn câu đó để tìm. Nó sử dụng LLM để phân tách thành 5-10 truy vấn khác nhau, bao gồm các thuật ngữ đồng nghĩa, từ chuyên ngành và các biến thể ngôn ngữ.
- Đa dạng hóa nguồn tin (Multi-source Retrieval): Module này kết nối đồng thời với nhiều API học thuật như Semantic Scholar, Crossref, PubMed, và ArXiv. Nó không chỉ lấy kết quả đầu tiên mà quét qua hàng trăm tiêu đề để chọn ra những bài báo có độ tương quan cao nhất.
- Xử lý hậu kỳ (Parsing & Normalization): Các tệp PDF thường có cấu trúc rất lộn xộn (cột đôi, bảng biểu, chú thích chân trang). Module này thực hiện việc "làm sạch" dữ liệu, tách riêng phần văn bản thuần túy và trích xuất Metadata (DOI, năm xuất bản, tác giả) để đảm bảo tính chính danh cho các bước sau.
- Cập nhật Artifact State: Mọi tệp PDF tìm được đều được gắn mã định danh duy nhất và lưu vào kho "Artifacts", sẵn sàng cho việc truy xuất ngay lập tức.
2. Module: Gather Evidence (Trình trích xuất bằng chứng - RCS)
Đây là module quan trọng nhất giúp PaperQA2 vượt trội hơn các công cụ khác. Nó không chỉ "tìm" mà còn "thấu hiểu" từng đoạn văn bản thông qua quy trình RCS (Re-rank & Summarize).
- Chia nhỏ và Định danh (Chunking): Mỗi bài báo được chia thành các đoạn nhỏ khoảng 200-500 từ. Mỗi đoạn này mang theo thông tin trích dẫn của bài báo gốc.
- Chấm điểm sự liên quan (Semantic Scoring): Một Agent LLM sẽ đọc từng đoạn văn và tự hỏi: "Nếu tôi dùng đoạn này để trả lời câu hỏi của người dùng, nó có hữu ích không?". Nó sẽ chấm điểm từ 1 đến 10. Những đoạn điểm thấp (như phần giới thiệu chung chung) sẽ bị loại bỏ ngay lập tức.
- Tóm tắt theo ngữ cảnh (Contextual Summarization): Thay vì giữ nguyên văn đoạn văn dài dòng, Agent sẽ viết lại một bản tóm tắt cực ngắn tập trung duy nhất vào thông tin trả lời cho câu hỏi.Ví dụ: Nếu bạn hỏi về "liều lượng", bản tóm tắt sẽ chỉ ghi "Liều lượng là 5mg/kg", bỏ qua mọi thông tin về quy trình thí nghiệm khác.
- Lọc nhiễu tối đa (Noise Reduction): Chỉ giữ lại bản tóm tắt có điểm cao nhất để chuyển sang module tổng hợp, giúp LLM cuối cùng không bị "quá tải" thông tin.
3. Module: Citations Traversal (Truy vết mạng lưới trích dẫn)
Module này tạo ra khả năng suy luận vượt ra ngoài những gì tìm thấy ban đầu, giải quyết vấn đề "điểm mù" của từ khóa.
- Mở rộng đồ thị tri thức (Citation Graph Expansion): Trong khoa học, một bài báo hay thường trích dẫn những bài báo hay khác. Agent sẽ quét phần "Tài liệu tham khảo" của các bằng chứng tốt nhất tìm được ở Module 2.
- Hành động "Vượt rào": Nếu thấy một bài báo cũ hơn (ví dụ năm 2015) được trích dẫn như một nền tảng quan trọng, Agent sẽ thực hiện lệnh Traverse. Nó sẽ tìm kiếm tiêu đề bài báo đó, tải về và nạp ngược lại vào Module 1.
- Xác minh chéo (Cross-verification): Bước này giúp Agent nhận ra các xu hướng: "Nghiên cứu A nói X, nhưng nó trích dẫn nghiên cứu B vốn đã bị phản bác bởi nghiên cứu C". Đây là tư duy phản biện mà các hệ thống RAG thông thường không bao giờ có được.
4. Module: Generate Answer (Tổng hợp và Khởi tạo câu trả lời)
Khi đã có trong tay danh sách các bản chấm điểm dựa trên các minh chứng tìm được (Scored Summaries) cực kỳ chất lượng, module này mới thực hiện nhiệm vụ cuối cùng.
- Thu thập thông tin nền (Context Gathering): Nó tập hợp toàn bộ các bản tóm tắt, thông tin trích dẫn và các mối liên hệ tìm được từ bước Traversal.
- Soạn thảo có kiểm chứng (Evidence-based Drafting): Agent viết câu trả lời theo phong cách học thuật. Mỗi khi viết một câu, nó phải kiểm tra xem: "Câu này có bằng chứng nào ủng hộ không?".
- Định dạng trích dẫn chuẩn hóa: Hệ thống tự động chuyển đổi các trích dẫn thành định dạng chuyên nghiệp (ví dụ: (Author et al., Year)).
- Cơ chế "Từ chối" (Hallucination Guard): Nếu sau tất cả các bước, Agent không tìm thấy bằng chứng đủ mạnh, nó sẽ không "chém gió". Nó sẽ trả lời: "Tôi đã tìm thấy 10 bài báo liên quan nhưng không có bài báo nào cung cấp con số chính xác mà bạn yêu cầu". Đây là đỉnh cao của sự an toàn trong AI.
Ví dụ đơn giản
Cài đặt môi trường
Trước tiên, bạn cần cài đặt thư viện paper-qa thông qua terminal hoặc command prompt.
pip install paper-qa
Lưu ý: Bạn cần có API Key (OpenAI là phổ biến nhất) để PaperQA có thể sử dụng công cụ này.
export OPENAI_API_KEY='sk-your-key-here'
Mã nguồn chạy thử
from paperqa import Docs
docs = Docs()
docs.add("semaglutide_cardiovascular_study.pdf")
docs.add("https://www.nejm.org/doi/pdf/10.1056/NEJMoa1607141")
english_query = (
"What is the impact of GLP-1 receptor agonists on major adverse cardiovascular events (MACE) "
"in non-obese patients, and what are the reported hazard ratios?"
)
answer = docs.query(english_query)
print("--- MEDICAL ANALYSIS ---")
print(answer.formatted_answer)
Đầu ra mẫu
SCIENTIFIC QUERY RESPONSE
--------------------------------------------------------------------------------
ANSWER:
GLP-1 receptor agonists (GLP-1 RAs), particularly semaglutide, have demonstrated
significant efficacy in reducing major adverse cardiovascular events (MACE) in
clinical populations (Marso et al., 2016; Lincoff et al., 2023). In the
SUSTAIN-6 trial, semaglutide was associated with a 26% reduction in MACE risk
compared to placebo, with a reported Hazard Ratio (HR) of 0.74 (95% CI, 0.58
to 0.95; p < 0.001) (Marso et al., 2016). Further analysis from the SELECT
trial suggests these cardiovascular benefits extend to non-obese patients, as
the reduction in MACE was found to be independent of baseline body mass index
(BMI) (Lincoff et al., 2023). Recent meta-analyses confirm that the primary
mechanism involves anti-atherosclerotic effects rather than weight loss
alone (Fisher et al., 2024).
EVIDENCE SCORING AND ANALYSIS:
| Source ID | Score | Key Evidence Summary |
|-------------|-------|----------------------------------------------------------|
| Marso2016 | 10/10 | Primary outcome (MACE) occurred in 6.6% vs 8.9%; HR 0.74 |
| Lincoff2023 | 9/10 | Benefit consistent across all BMI subgroups in SELECT |
| Fisher2024 | 8/10 | Direct vascular protective effects confirmed via meta |
BIBLIOGRAPHY (BIBTEX/VANCOUVER COMPATIBLE):
[1] Marso, S. P., et al. (2016). "Semaglutide and Cardiovascular Outcomes in
Patients with Type 2 Diabetes." NEJM. DOI: 10.1056/NEJMoa1607141.
[2] Lincoff, A. M., et al. (2023). "Semaglutide and Cardiovascular Outcomes
in Patients with Overweight or Obesity." NEJM. DOI: 10.1056/NEJMoa2307563.
[3] Fisher, M., et al. (2024). "GLP-1 receptor agonists: a decade of
cardiovascular outcome trials." BMJ. DOI: 10.1136/bmj-2023-076543.
--------------------------------------------------------------------------------
Kết luận
Việc lựa chọn giữa PaperQA và các phương pháp LLM truyền thống (như ChatGPT, Copilot hay RAG cơ bản) không phải là việc chọn công cụ nào "giỏi hơn", mà là chọn công cụ nào phù hợp hơn với mục tiêu cụ thể của người dùng.
- Chọn Phương pháp Truyền thống (LLM/Standard RAG) khi ưu tiên tốc độ và kiến thức phổ quát: Phù hợp để nắm bắt nhanh khái niệm cơ bản, tổng hợp tin tức từ Web hoặc tra cứu thông tin tổng quát mà không đòi hỏi đối soát số liệu khắt khe hay trích dẫn chi tiết.
- Chọn PaperQA (Agentic Workflow) khi yêu cầu độ chính xác và minh bạch tuyệt đối: Tối ưu cho việc viết báo cáo quốc tế, trích xuất dữ liệu lâm sàng chính xác từ hàng ngàn PDF chuyên sâu nhờ cơ chế tự kiểm chứng, loại bỏ "ảo giác" và truy vết trích dẫn thông minh.
Tài liệu tham khảo
All rights reserved
