Paper reading | VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp của bài báo
Để train hiệu quả các mô hình vision transformer (ViT) cần bộ dữ liệu được gán nhãn lớn. Các model ViT đạt được kết quả SOTA khi được train trên hàng trăm triệu ảnh được gán nhãn. Tuy nhiên, việc sử dụng video transformer còn nhiều hạn chế vể mặt hiệu suất do phụ thuộc vào pretrain của các model ViT trên ảnh. Do đó, bài toán ở đây là làm như nào để có thể train hiệu quả model vision transformer trên video sử dụng data là chính video luôn mà không phụ thuộc vào bất kì pretrained model trên hình ảnh  Vấn đề nữa là data về video có gán nhãn còn rất hạn chế nên sẽ rất là hợp lý nếu ta sử dụng self-supervised learning cho data video.
Vấn đề nữa là data về video có gán nhãn còn rất hạn chế nên sẽ rất là hợp lý nếu ta sử dụng self-supervised learning cho data video.
Trong bài báo, nhóm tác giả đề xuất model VideoMAE với những ý tưởng và kết quả mới như sau:
- Đề xuất một cơ chế masking hiệu quả (tube masking) cho video với tỉ lệ masking cao. Giải quyết vấn đề information leakage trong masked video modeling
- Các model được pretrain với VideoMAE đạt kết quả ấn tượng so với việc train từ đầu hoặc pretrained theo phương pháp constrastive learning.
- Chứng minh VideoMAE học hiệu quả trên dữ liệu, dữ liệu được sử dụng để train chỉ bao gồm 3500 video. Chất lượng dữ liệu quan trọng hơn số lượng dữ liệu đối với Self-supervised video pretraining khi có sự dịch chuyển về domain giữa source và target dataset.
Phương pháp
Nhắc lại Image Masked Autoencoder
ImageMAE thực hiện nhiệm vụ masking và reconstruction sử dụng kiến trúc encoder-decoder bất đối xứng. Cho ảnh input , ban đầu ảnh được chia thành các patch có kích thức không chồng chéo nhau và mỗi patch sẽ được biểu diễn bởi token embedding tương ứng.
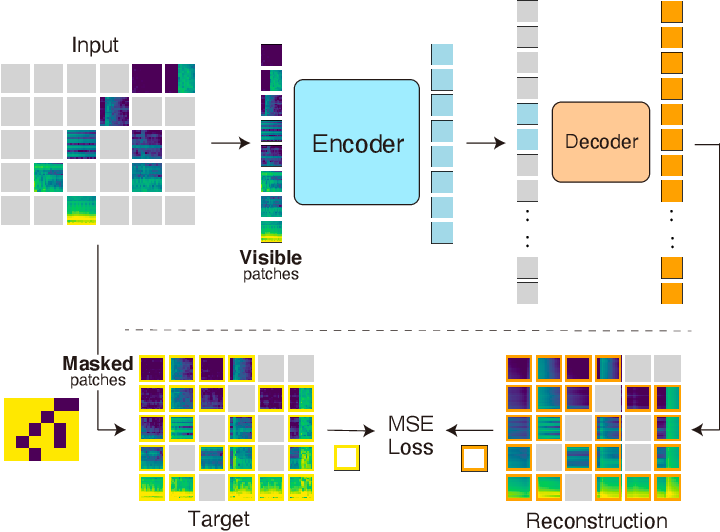
Sau đó một tập con các token sẽ được ngẫu nhiên mask với tỉ lệ mask (che) nào đó (thường là 75%) và chỉ các token còn lại được đưa vào transformer encoder . Cuối cùng, một decoder được sử dụng để reconstruct (tái tạo) lại token bị mask. Loss function là mean squared error (MSE) loss giữa token bị mask đã được chuẩn hóa và token được reconstruct trong không gian pixel.
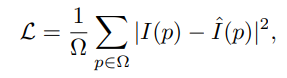
trong đó là token index, là tập các token được mask, là ảnh đầu vào, là ảnh được reconstruct.
Đặc điểm của Video data
So sánh với ảnh tĩnh thì video bao gồm thêm một chiều gọi là temporal (có thể hiểu là chiều thời gian ). Một số đặc điểm về dữ liệu video mà tác giả phân tích trong bài báo như sau:
Temporal redundancy. Video là một tập hợp các frame, nếu xem các video clip thì các bạn sẽ thấy là các hình ảnh cách nhau 1 -2 giây thường không thay đổi gì nhiều hay nói một cách khác là một số frame liền kề bị dư thừa như hình dưới:

Điều này dẫn đến 2 vấn đề trong masked video autoencoding. Đầu tiên, sẽ là không hiệu quả nếu như ta giữ nguyên frame rate (tỷ lệ lấy mẫu frame) vì điều này dẫn đến việc model tập trung nhiều vào các chuyển động tĩnh hoặc chậm. Thứ hai, sự dư thừa frame sẽ làm loãng các biểu diễn chuyển động. Điều này sẽ làm cho nhiệm vụ reconstruct các pixel bị mask không khó khăn theo tỷ lệ masking thông thường (50% đến 75%) do các frame liền kề na ná nhau Encoder backbone cũng trở nên không hiệu quả trong việc nắm bắt các biểu diễn chuyển động.
Temporal correlation. Video là một tập hợp các frame nên có thể giữa các frame liền kề sẽ có mối tương quan nào đó. Sự tương quan này làm tăng rủi ro bị information leakage (rò rỉ thông tin) trong luồng masking và reconstruction. Do đó cần một chiến lược masking để làm cho việc reconstruction trở nên thử thách hơn và thúc đẩy việc học hiểu quả biểu diễn cấu trúc spatiotemporal (không gian - thời gian)
VideoMAE
Hình dưới là kiến trúc tổng quan của VideoMAE.
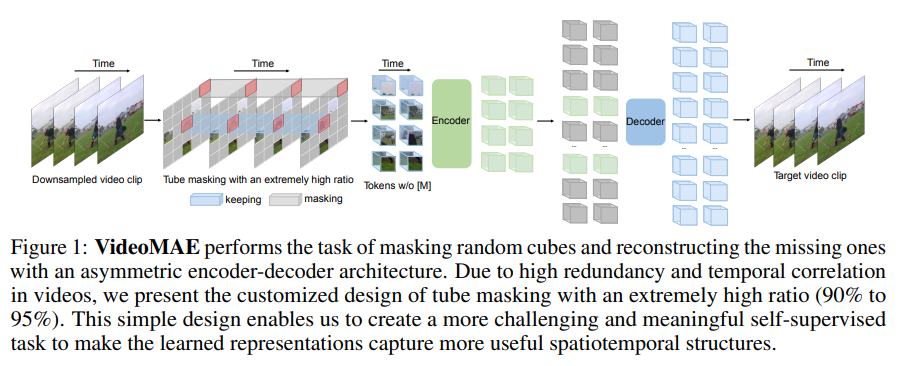
VideoMAE nhận các frame đã được downsample làm input và sử dụng cube embedding để nhận các video token. Bài báo đề xuất một thiết kế đơn giản của tube masking với tỉ lệ cao để thực hiện pretrain MAE với kiến trúc encoder-decoder đối xứng. Backbone được sử dụng là vanilla ViT với joint space-time attention.
Temporal downsampling. Do vấn đề temporal redundancy ở các frame liên tiếp, nhóm tác giả để xuất sử dụng chiến lược strided temporal sampling (lấy mẫu frame theo chiều thời gian bởi bước nhảy, giống như stride trong CNN theo chiều không gian ) để thực hiện train video hiệu quả hơn. Cụ thể,ban đầu một video clip gồm frame liên tiếp sẽ được lấy mẫu ngẫu nhiên từ video gốc . Sau đó sử dụng temporal sampling để nén clip xuống còn frame, mỗi frame gồm pixel. Trong thực nghiệm, stride được đặt lần lượt là 4 và 2 trên tập Kinetic và Something-Something.
Cube embedding. Bài báo áp dụng joint space-time cube embedding trong mô hình. Cụ thể, ta sẽ chọn mỗi cube có kích thước là một token embedding. Do đó, cube embedding layer nhận một số lượng là 3D tokens và map mỗi token với channel dimension D. Cách thiết kế này làm giảm số chiều spatial và temporal của input, giúp giảm bớt sự dư thừa về spatial và temporal trong video.
Tube masking with extremely high ratios. Nhóm tác giả nhận thấy rằng mô hình VideoMAE khi thực hiện masking với tỉ lệ lớn (90% - 95%, lớn hơn nhiều so với ImageMAE) sẽ cho kết quả tốt. Mật độ thông tin của video ít hơn nhiều so với hình ảnh và mục đích của tỉ lệ masking cao là làm tăng độ khó của việc reconstruction Tỷ lệ masking cao này rất hữu ích để giảm thiểu information leakage và làm cho việc reconstruct masked video trở thành một task self-supervised pre-training hiệu quả hơn.
Ngoài ra, nhóm tác giả cũng đề xuất cơ chế temporal tube masking để cải thiện hiệu quả của việc masking. Cụ thể, cơ chế tube masking được mô tả là và thời gian khác nhau chia sẻ cùng một giá trị (ở frame nào cũng mask các vị trí giống hệt nhau).
Module tube masking có thể được cài đặt như sau:
import numpy as np
class TubeMaskingGenerator:
def __init__(self, input_size, mask_ratio):
# Initialize the TubeMaskingGenerator object with input size and mask ratio
self.frames, self.height, self.width = input_size
# Get information about the number of frames, height, and width
self.num_patches_per_frame = self.height * self.width
# Number of patches per frame = height * width
self.total_patches = self.frames * self.num_patches_per_frame
# Total number of patches in the entire video = frames * patches per frame
self.num_masks_per_frame = int(mask_ratio * self.num_patches_per_frame)
# Number of masks per frame = mask ratio * patches per frame
self.total_masks = self.frames * self.num_masks_per_frame
# Total number of masks in the entire video = frames * masks per frame
def __repr__(self):
# Method to represent the string of the TubeMaskingGenerator object
repr_str = "Masks: total patches {}, mask patches {}".format(
self.total_patches, self.total_masks
)
return repr_str
def __call__(self):
# Method to generate a mask for the frames
mask_per_frame = np.hstack([
np.zeros(self.num_patches_per_frame - self.num_masks_per_frame),
np.ones(self.num_masks_per_frame),
])
# Create an array with the number of elements equal to the total patches per frame,
# with the number of non-masked patches (0) and the number of masked patches (1)
np.random.shuffle(mask_per_frame)
# Randomly shuffle the elements of the mask array for each frame
mask = np.tile(mask_per_frame, (self.frames, 1)).flatten()
# Repeat the mask array for the number of frames and flatten the array to 1D
return mask
# Return the mask array for the frames
Backbone: joint space-time attention. Như đã trình bày ở trên, do tỉ lệ masking cao, ta chỉ sử dụng một số ít các token còn lại làm input cho encoder. Vì vậy, để capture thông tin spatial và temporal được tốt hơn, nhóm tác giả sử dụng backbone là ViT và bổ sung thêm joint space-time attention. Kiến trúc cụ thể như sau:
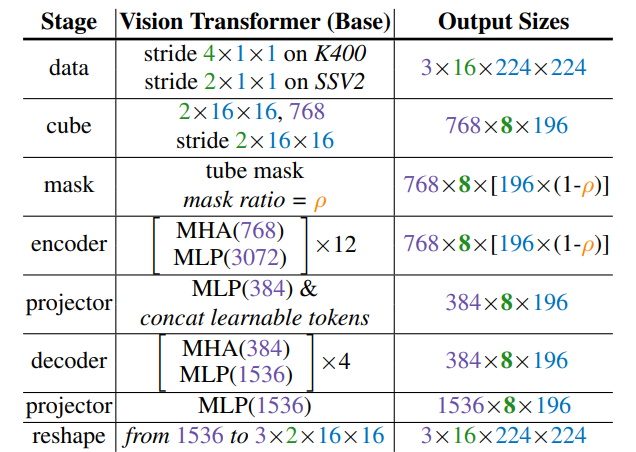
Với cách sử dụng model trên, tất cả các cặp token có thể tương tác với nhau trong multi-head self-attention layer. Do độ phức tạp của cơ chế joint space-time attention là bậc hai nên sẽ là một vấn đề cho thời gian tính toán, tuy nhiên vì tỉ lệ masking cao nên sẽ giảm bớt phần nào vấn đề này
Thực nghiệm
Nhóm tác giả thực hiện thực nghiệm trên 2 tập dữ liệu Something-Something V2 và Kinetics-400. Backbone là 16-frame vanilla ViT-B và tất cả model được pretrain với mask ratio là với 800 epoch và được finetuning cho việc đánh giá. Các kết quả của model với setup các thành phần khác nhau như sau:

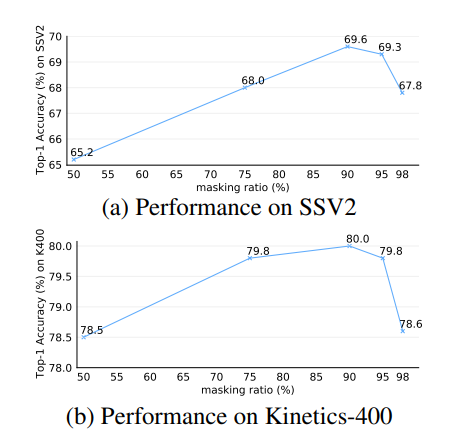
Biểu đồ dưới thể hiện mỗi quan hệ giữa masking ratio với hiệu suất của mô hình trên 2 bộ dữ liệu là Something-Something V2 và Kinetics-400. Kết quả cho thấy với tỉ lệ masking cao là 90% cho ra kết quả tốt nhất,
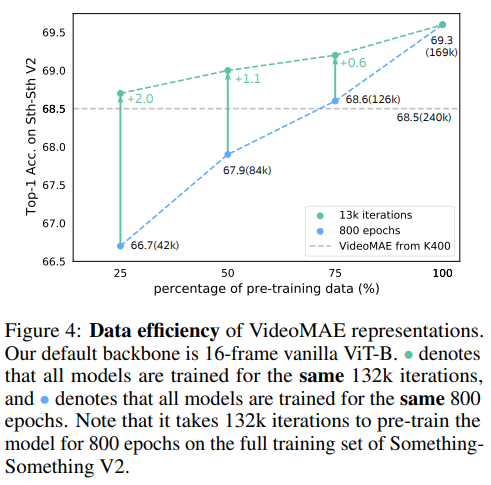
Biểu đồ dưới thể hiện khả năng biểu diễn data hiệu quả của VideoMAE.
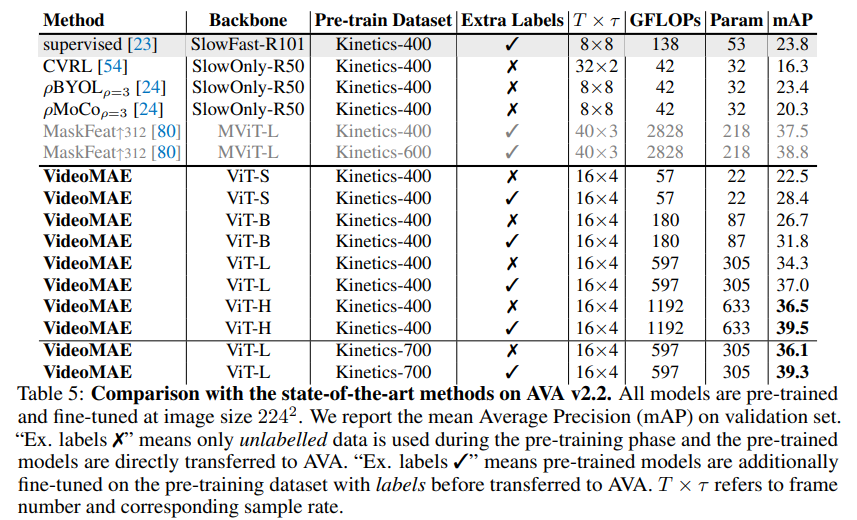
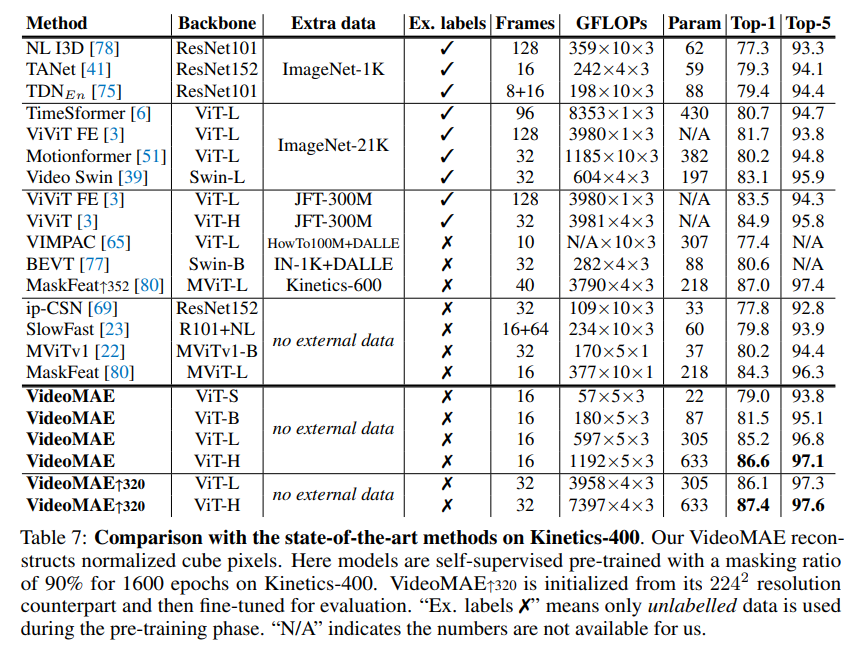
So sánh các kết quả của mô hình VideoMAE với model khác trên những tập dữ liệu khác nhau được thể hiện trong bảng dưới:
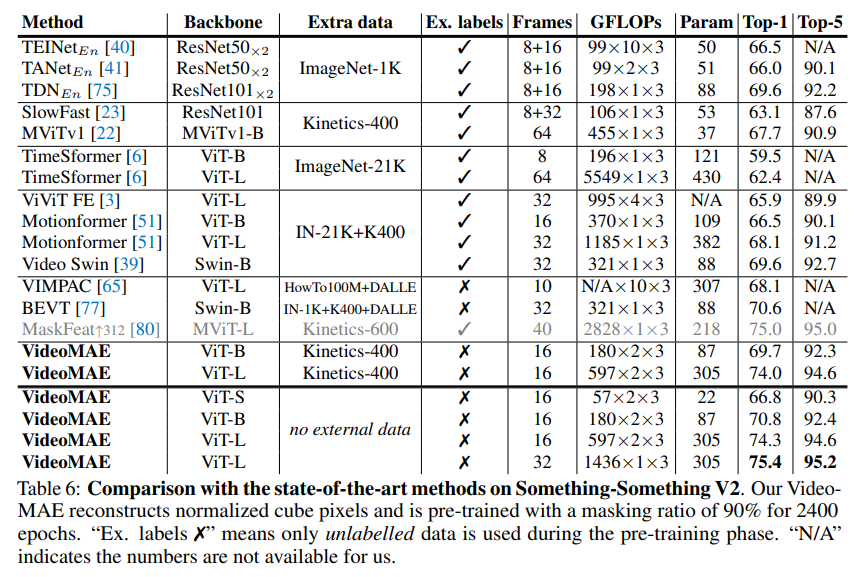
Tham khảo
[1] VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
All rights reserved
