Paper reading | Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp của bài báo
Video Understanding là một bài toán hay và khó trong các task về Computer Vision  . Có nhiều kiến trúc mô hình được đề xuất để giải quyết bài toán này. Không như hình ảnh, ngoài capture spatio information các mô hình cần có khả năng capture được temporal information. Đa phần các mô hình trước đây đều tận dụng pretrained của các model hình ảnh cho model video. Tuy nhiên, khi sử dụng cho video thì các kernel này lại không còn khả năng dùng lại cho hình ảnh nữa.
. Có nhiều kiến trúc mô hình được đề xuất để giải quyết bài toán này. Không như hình ảnh, ngoài capture spatio information các mô hình cần có khả năng capture được temporal information. Đa phần các mô hình trước đây đều tận dụng pretrained của các model hình ảnh cho model video. Tuy nhiên, khi sử dụng cho video thì các kernel này lại không còn khả năng dùng lại cho hình ảnh nữa.
Ngoài ra, các phương pháp trước đây thường coi hình ảnh và video là các input hoàn toàn khác biệt, các phương pháp này thường xử lý độc lập cho video và hình ảnh vì thiết kế một mô hình có khả năng xử lý cả hai là vô cùng thách thức Một số phương pháp được đề xuất trước đây như Perceiver và Flamingo đưa ra phương pháp resampling input về lượng feature cố định, tuy nhiên cách làm này có chi phí rất lớn với video dài. Đối với Famingo, mô hình coi video là những frame độc lập và được sample tại 1 FPS, phương pháp này không hiệu quả do làm mất đi temporal information, đặc biệt đối với những dataset hành động có những hoạt động ngắn và rất nhanh.
Để giải quyết hạn chế này, nhóm tác giả đề xuất một mô hình đơn giản nhưng hiệu quả có tên là TubeViT, ý tưởng là sử dụng ViT một cách liền mạch cho cả ảnh và video. Mặt khác, các model trước đây chi phí training thường rất tốn kém nên chúng thường tận dụng các model pretrained và dùng cho video. Bài báo mở rộng từ ý tưởng trên, đề xuất sử dụng Sparse Video Tubes để có thể dễ dàng scale và tận dụng các mô hình pretrained ViT lớn. Với việc dùng Sparse Video Tubes, ta có thể chia sẻ weight cho cả ảnh và video
Phương pháp
Sơ lược về ứng dụng ViT cho video
Một kiến trúc ViT cơ bản nhận đầu vào là ảnh, chia ảnh thành các patch có kích thước không chồng nhau và chuyển thành patch embedding. Với ảnh có kích thước ta sẽ có 196 patch. Cho video , các cách tiếp cận trước đó sử dụng các dense 2D patch hoặc sử dụng dense 3D kernels, hệ quả là số lượng token trở nên rất lớn, ví dụ là trong đó là số lượng frame. Các tube hay patch sau đó được truyền vào một linear layer để chiếu vào một không gian embedding . Chuỗi các token sau đó được xử lý bởi transformer encoder sử dụng các thành phần cơ bản, MSA - multi-head self attention, MLP transformer projection layer và sử dụng LN (Layer Norm). Cho một chuỗi các layer , ta thực hiện tính toán biểu diễn và các token feature cho tất cả các token :
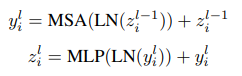
Sparse Video Tubes
Cách tiếp cận trong bài báo kế thừa ý tưởng của ViT, thực hiện xây dựng model dựa vào quan sát rằng sự thưa thớt là hiệu quả cho video Thay vì dense tokenize như các phương pháp trước, model vẫn sử dụng 2D kernel nhưng với temporal stride lớn hơn, ví dụ áp dụng cho mọi frame thứ 16. Khi đó, với một video đầu vào có kích thước thì ta sẽ có 392 = 2 * 196 token, ít hơn rất nhiều so với 6000 token trong TimeSFormer và 1000-2000 token trong ViViT.
Tuy nhiên, như đã đề cập ở phần đầu sparse spatial sampling có thể làm mất mát thông tin, đặc biệt cho những video có hành động ngắn và nhanh Do đó, nhóm tác giả tạo ra các tube thưa có shape khác nhau, ví dụ, một tube nhận thông tin từ nhiều frame với spatial resolution thấp. Các shape của tube là bất kì (trong phần phụ lục bài báo, nhóm tác giả cũng thực hiện thực nghiệm để nghiên cứu ảnh hưởng của shape lên performance model). Điều quan trọng là các tube cũng có các stride lớn, lấy mẫu thưa từ video với các view khác nhau Nhóm tác giả cũng thêm một offset (việc thêm này là tùy chọn) vào vị trí bắt đầu với mục tiêu là để các patch không phải lúc nào cũng bắt đầu từ (0, 0, 0) và điều này giúp cho giảm sự chồng chéo giữa các tube. Để hiểu rõ hơn, bạn có thể xem hình dưới:
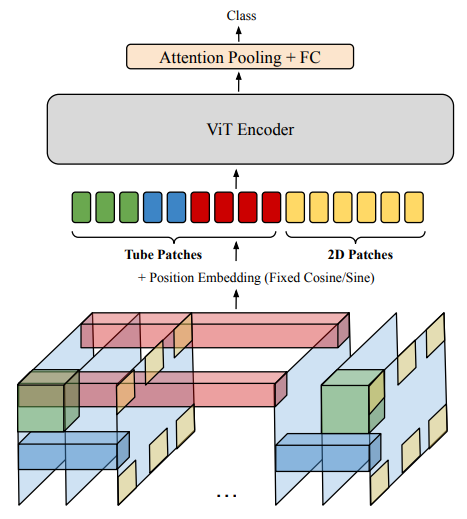
Ngoài ra, mô hình cũng cho phép overlap giữa các tube. Cụ thể, ta có thể biểu diễn một tube là kernel có shape , là spatio-temporal stride cho kernel và là offset của điểm xuất phát.
Với thiết kế này, model có thể nắm bắt được thông tin tổng hợp của cả hình ảnh và video.
Vậy keyword ta thu được ở đây là sự thưa thớt và đa dạng shape và stride cho tube Việc sparse spatial sampling cho phép sharing image, các frame token và các sparse video tube tạo một lượng nhỏ các token cho video cụ thể. Điều này giúp cho việc "chia sẻ weight" tốt hơn giữa hình ảnh và video.
Cài đặt cho module Sparse Tubes Tokenizer như sau:
class SparseTubesTokenizer(nn.Module):
def __init__(self, hidden_dim, kernel_sizes, strides, offsets):
super().__init__()
self.hidden_dim = hidden_dim
self.kernel_sizes = kernel_sizes
self.strides = strides
self.offsets = offsets
self.conv_proj_weight = nn.Parameter(torch.empty((self.hidden_dim, 3, *self.kernel_sizes[0])).normal_(),
requires_grad=True)
self.register_parameter('conv_proj_weight', self.conv_proj_weight)
self.conv_proj_bias = nn.Parameter(torch.zeros(len(self.kernel_sizes), self.hidden_dim), requires_grad=True)
self.register_parameter('conv_proj_bias', self.conv_proj_bias)
def forward(self, x: Tensor) -> Tensor:
n, c, t, h, w = x.shape # CTHW
tubes = []
for i in range(len(self.kernel_sizes)):
if i == 0:
weight = self.conv_proj_weight
else:
weight = F.interpolate(self.conv_proj_weight, self.kernel_sizes[i], mode='trilinear')
tube = F.conv3d(
x[:, :, self.offsets[i][0]:, self.offsets[i][1]:, self.offsets[i][2]:],
weight,
bias=self.conv_proj_bias[i],
stride=self.strides[i],
)
tube = tube.reshape((n, self.hidden_dim, -1))
tubes.append(tube)
x = torch.cat(tubes, dim=-1)
x = x.permute(0, 2, 1).contiguous()
return
Positional embedding cho các sparse video tube
Một ý tưởng khác trong việc cài đặt postional embedding cũng được đề cập trong bài báo. Nếu như trong các language model, relative positional embedding là một cách tiếp cận phổ biến và hiệu quả thì trong các mô hình visual, relative position giữa 2 token không mang nhiều ý nghĩa và không có một tham chiếu thực để biết xem patch hay tube nằm ở đâu trong video hay ảnh gốc cả, đặc biệt trong trường hợp các tube bị overlap sẽ còn khoai hơn
Thay vào đó, nhóm tác giả đề xuất sử dụng sine/cosine embedding cố định. Việc sử dụng các tham số stride, kernel shape và offset cho positional embedding sẽ đảm bảo positional embedding cho mỗi tube có global spatio-temporal location của tube đó.
Cụ thể, ta sẽ tính embedding như sau. Với là hằng số hyperparmeter (có giá trị là 1000). Thực hiện vòng lặp for từ 0 tới ( là số lượng feature) và for từ 0 tới :
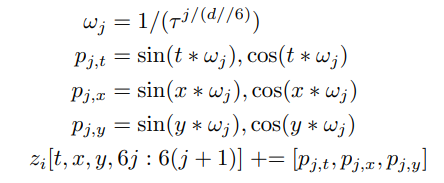
Với cách tính toán trên, ta sẽ cộng mỗi spatio-temporal position embedding với feature dimension của token . được sử dụng vì ta có 6 phần tử (giá trị sin và cos cho mỗi ).
Cài đặt cho positional embedding sẽ như sau:
from typing import Tuple
import torch
def get_3d_sincos_pos_embed(embed_dim: int,
tube_shape: Tuple[int, int, int],
stride,
offset,
kernel_size,
cls_token: bool = False) -> torch.Tensor:
"""
Get 3D sine-cosine positional embedding.
Args:
tube_shape: (t_size, grid_h_size, grid_w_size)
kernel_size:
offset:
stride:
embed_dim:
cls_token: bool, whether to contain CLS token
Returns:
(torch.Tensor): [t_size*grid_size*grid_size, embed_dim] or [1+t_size*grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
"""
assert embed_dim % 4 == 0
embed_dim_spatial = embed_dim // 3 * 2
embed_dim_temporal = embed_dim // 3
# spatial
grid_h_size = tube_shape[1]
grid_h = torch.arange(grid_h_size, dtype=torch.float)
grid_h = grid_h * stride[1] + offset[1] + kernel_size[1] // 2
grid_w_size = tube_shape[2]
grid_w = torch.arange(tube_shape[2], dtype=torch.float)
grid_w = grid_w * stride[2] + offset[2] + kernel_size[2] // 2
grid = torch.meshgrid(grid_w, grid_h, indexing='ij')
grid = torch.stack(grid, dim=0)
grid = grid.reshape([2, 1, grid_h_size, grid_w_size])
pos_embed_spatial = get_2d_sincos_pos_embed_from_grid(embed_dim_spatial, grid)
# temporal
t_size = tube_shape[0]
grid_t = torch.arange(t_size, dtype=torch.float)
grid_t = grid_t * stride[0] + offset[0] + kernel_size[0] // 2
pos_embed_temporal = get_1d_sincos_pos_embed_from_grid(embed_dim_temporal, grid_t)
pos_embed_temporal = pos_embed_temporal[:, None, :]
pos_embed_temporal = torch.repeat_interleave(pos_embed_temporal, grid_h_size * grid_w_size, dim=1)
pos_embed_spatial = pos_embed_spatial[None, :, :]
pos_embed_spatial = torch.repeat_interleave(pos_embed_spatial, t_size, dim=0)
pos_embed = torch.cat([pos_embed_temporal, pos_embed_spatial], dim=-1)
pos_embed = pos_embed.reshape([-1, embed_dim])
if cls_token:
pos_embed = torch.cat([torch.zeros([1, embed_dim]), pos_embed], dim=0)
return pos_embed
def get_2d_sincos_pos_embed(embed_dim: int, grid_size: int, cls_token: bool = False) -> torch.Tensor:
"""
Get 2D sine-cosine positional embedding.
Args:
grid_size: int of the grid height and width
cls_token: bool, whether to contain CLS token
Returns:
(torch.Tensor): [grid_size*grid_size, embed_dim] or [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
"""
grid_h = torch.arange(grid_size, dtype=torch.float)
grid_w = torch.arange(grid_size, dtype=torch.float)
grid = torch.meshgrid(grid_w, grid_h, indexing='ij')
grid = torch.stack(grid, dim=0)
grid = grid.reshape([2, 1, grid_size, grid_size])
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
if cls_token:
pos_embed = torch.cat([torch.zeros([1, embed_dim]), pos_embed], dim=0)
return pos_embed
def get_2d_sincos_pos_embed_from_grid(embed_dim: int, grid: torch.Tensor) -> torch.Tensor:
"""
Get 2D sine-cosine positional embedding from grid.
Args:
embed_dim: embedding dimension.
grid: positions
Returns:
(torch.Tensor): [grid_size*grid_size, embed_dim] or [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
"""
assert embed_dim % 2 == 0
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0])
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1])
emb = torch.cat([emb_h, emb_w], dim=1)
return emb
def get_1d_sincos_pos_embed_from_grid(embed_dim: int, pos: torch.Tensor) -> torch.Tensor:
"""
Get 1D sine-cosine positional embedding.
Args:
embed_dim: output dimension for each position
pos: a list of positions to be encoded: size (M,)
Returns:
(torch.Tensor): tensor of shape (M, D)
"""
assert embed_dim % 2 == 0
omega = torch.arange(embed_dim // 2, dtype=torch.float)
omega /= embed_dim / 2.0
omega = 1.0 / 10000 ** omega
pos = pos.reshape(-1)
out = torch.einsum("m,d->md", pos, omega)
emb_sin = torch.sin(out)
emb_cos = torch.cos(out)
emb = torch.cat([emb_sin, emb_cos], dim=1)
return
Xây dựng Sparse Tube
Bài báo đề xuất 2 tube: tube được sử dụng để tokenize ảnh và một tube để tokenize video, cả 2 đều có stride là . Đây là base tokenizer được sử dụng và đạt hiệu suất cao, tuy nhiên bài báo cũng bổ sung thêm một vài biến thể mới
Multi-Tube. Nhóm tác giả thực hiện thêm một số tube mới với các kích thước khác nhau. Ví dụ, ta có thể thêm một tube có chiều temporal dài hơn và spatial nhỏ hơn như để học các hành động trong thời gian dài của dữ liệu. Mặt khác, ta cũng có thể thêm tube có spatial lớn hơn như để tập trung vào spatial. Tất nhiên, có rất nhiều biến thể của tube về shape và stride mà ta có thể thực nghiệm
Space-to-Depth. Một cách khác để mở rộng cách tiếp cận chính là ta giảm số lượng channel trong một tube (giảm theo lũy thừa cơ số 2). Khi đó, shape của tube sẽ là . Sau đó, ta sẽ concat 2 token theo chiều channel. Ta cũng có thể giảm stride của tube. Kết quả là cùng số lượng token và dimension như ban đầu nhưng việc tăng kernel size không làm thay đổi số lượng tham số. Tức là, khi giảm stride theo chiều temporal, token đại diện cho vị trí nhưng vẫn chỉ sử dụng tham số.
Interpolated Kernels. Với cách này thay vì dùng một shape riêng cho mỗi tube, ta sẽ học 1 3D kernel có shape , sau đó sử dụng có thể tri-linear interpolation (nội suy tam tuyến) để reshape kernel thành nhiều kích thước khác nhau tùy thuộc vào config của tube. Bất kì kích thước kernel nào cũng có thể tạo từ một kernel duy nhất này Phương pháp này có một số ưu điểm:
- Giảm số lượng weight dùng trên luồng video
- Linh hoạt trong việc sử dụng kernel, có thể tăng chiều temporal cho những video dài hoặc tinh chỉnh chiều spatial để tìm các object có kích thước khác nhau.
Train đồng thời ảnh và video
Để tận dụng được những tập dữ liệu gán nhãn của cả ảnh và video thì việc thiết kế model có thể train cùng lúc cả ảnh và video là cần thiết. Việc training đồng thời cả ảnh và video theo phương pháp trong bài báo khá dễ dàng, ảnh sẽ được tokenize bởi 2D kernel còn video được tokenize bởi cả 2D patch (với temporal stride lớn) và Sparse Tube. Cả 2 sau đó sẽ được truyền vào mạng ViT. Position embedding được sử dụng cho cả 2 trường hợp.
Mở rộng model từ ảnh sang video
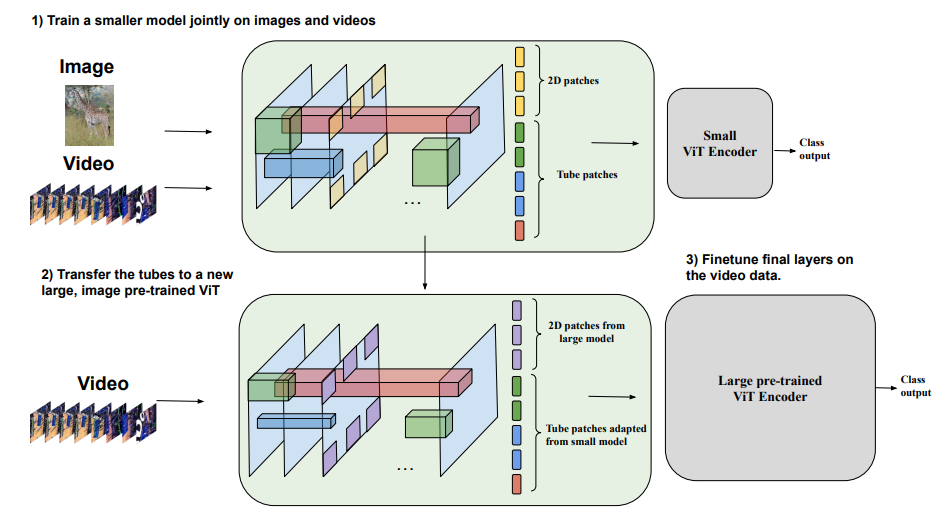
Bài báo cũng đề xuất một phương pháp hiệu quả để scaling up model. Để training một model ViT lớn thì chi phí tính toán là rất tốn kém, đặc biệt là với video. Do hầu như tất cả các thành phần của model TubeViT đều chia sẻ giữa ảnh và video, nhóm tác giả thực hiện nghiên cứu cách khởi tạo model lớn mà tối ưu chi phí để fine tuning.
Đầu tiên, ta thực hiện train model ViT nhỏ cho cả ảnh và video, từ đó thu được một tập các weight cho tube. Sau đó ta sẽ transfer weight tube từ model nhỏ vào một model pretrained ViT lớn cho ảnh. Vì model ViT lớn thường sử dụng nhiều channel dimension hơn là model nhỏ, ta có thể sử dụng biến đổi space-to-depth (đã trình bày ở phần trước) để tạo các token có channel dimension phù hợp mà không cần weight mới.
Sau đó, ta chọn một điểm trên mạng và đóng băng tất cả các layer trước đó. Ví dụ, layer thứ 26 trong 32 của model ViT-H. Tại điểm này, ta cộng một gated connection vào mạng:
![]()
trong đó là layer của mạng bị đóng băng và là các raw input token từ tube. là tham số learnable gating được khởi tạo bằng 0. Trong bước training đầu tiên, gate này không ảnh hưởng tới biểu diễn nên ViT sẽ không đổi. Tuy nhiên, nó có thể học cách kết hợp tube thô tại điểm này và tinh chỉnh các weight sau.
Module TubeViT được cài đặt như sau (mang tính chất tham khảo ):
class SelfAttentionPooling(nn.Module):
"""
Implementation of SelfAttentionPooling
Original Paper: Self-Attention Encoding and Pooling for Speaker Recognition
https://arxiv.org/pdf/2008.01077v1.pdf
code from https://gist.github.com/pohanchi/c77f6dbfbcbc21c5215acde4f62e4362
"""
def __init__(self, input_dim):
super(SelfAttentionPooling, self).__init__()
self.W = nn.Linear(input_dim, 1)
def forward(self, x):
"""
input:
batch_rep : size (N, T, H), N: batch size, T: sequence length, H: Hidden dimension
attention_weight:
att_w : size (N, T, 1)
return:
utter_rep: size (N, H)
"""
# (N, T, H) -> (N, T) -> (N, T, 1)
att_w = nn.functional.softmax(self.W(x).squeeze(dim=-1), dim=-1).unsqueeze(dim=-1)
x = torch.sum(x * att_w, dim=1)
return x
class TubeViT(nn.Module):
def __init__(
self,
num_classes: int,
video_shape: Union[List[int], np.ndarray], # CTHW
num_layers: int,
num_heads: int,
hidden_dim: int,
mlp_dim: int,
dropout: float = 0.0,
attention_dropout: float = 0.0,
representation_size=None,
):
super(TubeViT, self).__init__()
self.video_shape = np.array(video_shape) # CTHW
self.num_classes = num_classes
self.hidden_dim = hidden_dim
self.kernel_sizes = (
(8, 8, 8),
(16, 4, 4),
(4, 12, 12),
(1, 16, 16),
)
self.strides = (
(16, 32, 32),
(6, 32, 32),
(16, 32, 32),
(32, 16, 16),
)
self.offsets = (
(0, 0, 0),
(4, 8, 8),
(0, 16, 16),
(0, 0, 0),
)
self.sparse_tubes_tokenizer = SparseTubesTokenizer(self.hidden_dim, self.kernel_sizes, self.strides,
self.offsets)
self.pos_embedding = self._generate_position_embedding()
self.pos_embedding = torch.nn.Parameter(self.pos_embedding, requires_grad=False)
self.register_parameter('pos_embedding', self.pos_embedding)
# Add a class token
self.class_token = nn.Parameter(torch.zeros(1, 1, self.hidden_dim), requires_grad=True)
self.register_parameter('class_token', self.class_token)
self.encoder = Encoder(
num_layers=num_layers,
num_heads=num_heads,
hidden_dim=self.hidden_dim,
mlp_dim=mlp_dim,
dropout=dropout,
attention_dropout=attention_dropout,
)
self.attention_pooling = SelfAttentionPooling(self.hidden_dim)
heads_layers: OrderedDict[str, nn.Module] = OrderedDict()
if representation_size is None:
heads_layers["head"] = nn.Linear(self.hidden_dim, self.num_classes)
else:
heads_layers["pre_logits"] = nn.Linear(self.hidden_dim, representation_size)
heads_layers["act"] = nn.Tanh()
heads_layers["head"] = nn.Linear(representation_size, self.num_classes)
self.heads = nn.Sequential(heads_layers)
def forward(self, x):
x = self.sparse_tubes_tokenizer(x)
n = x.shape[0]
# Expand the class token to the full batch
batch_class_token = self.class_token.expand(n, -1, -1)
x = torch.cat([batch_class_token, x], dim=1)
x = x + self.pos_embedding
x = self.encoder(x)
# Attention pooling
x = self.attention_pooling(x)
x = self.heads(x)
return x
def _calc_conv_shape(self, kernel_size, stride, offset) -> np.ndarray:
kernel_size = np.array(kernel_size)
stride = np.array(stride)
offset = np.array(offset)
output = np.ceil((self.video_shape[[1, 2, 3]] - offset - kernel_size + 1) / stride).astype(int)
return output
def _generate_position_embedding(self) -> torch.nn.Parameter:
position_embedding = [torch.zeros(1, self.hidden_dim)]
for i in range(len(self.kernel_sizes)):
tube_shape = self._calc_conv_shape(self.kernel_sizes[i], self.strides[i], self.offsets[i])
pos_embed = get_3d_sincos_pos_embed(
embed_dim=self.hidden_dim,
tube_shape=tube_shape,
kernel_size=self.kernel_sizes[i],
stride=self.strides[i],
offset=self.offsets[i],
)
position_embedding.append(pos_embed)
position_embedding = torch.cat(position_embedding, dim=0).contiguous()
return
Thực nghiệm
Bảng dưới là so sánh hiệu suất của TubeViT trên tập dữ liệu Kinetics 400 với các model SOTA trước đó. Trong đó crop biểu thị là temporal và là spatial.
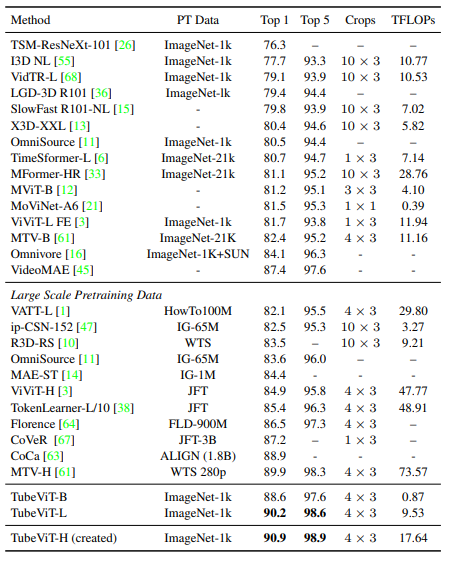
Bảng dưới là kết quả so sánh hiệu suất các model trên tập dữ liệu Kinetics 600. Tương tự như bảng trên, TubeViT sử dụng pretrained trên tập ImageNet-1k.
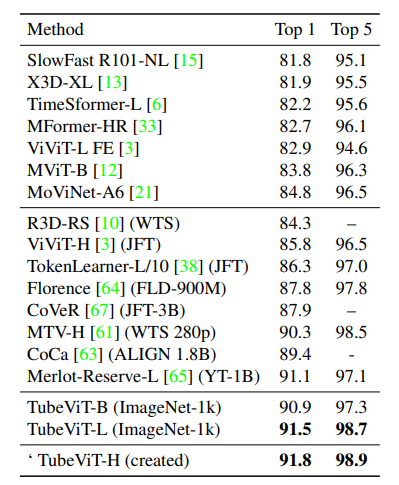
Bảng dưới là kết quả so sánh với các model SOTA trên tập dữ liệu Kinetics 700.
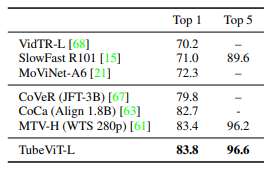
Bảng dưới là kết quả so sánh với các model SOTA trên tập dữ liệu Something-SomethingV2.
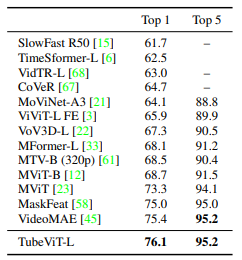
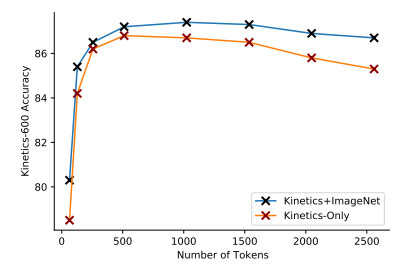
Kết hợp 2 dataset, TubeViT đạt kết quả ấn tượng trên tập Kinetics 600.

Biểu đồ dưới mô tả độ chính xác tương ứng với số lượng token sử dụng trong TubeViT.
Tham khảo
[1] Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning
All rights reserved
