
[Paper Explain] Two-phase training mitigates class imbalance for camera trap image classification with CNNs
Bài đăng này đã không được cập nhật trong 4 năm
Các bộ dữ liệu không cân bằng luôn là niềm đau trong mỗi bài toán học máy. Để giải quyết vấn đề này bài báo Two-phase training mitigates class imbalance for camera trap image classification with CNNs đã sử dụng đào tạo hai giai đoạn để tăng hiệu suất cho các lớp thiểu số và kết quả thu được khá khả quan khi không chỉ cải thiện độ chính xác trên các lớp thiểu số mà còn hạn chế việc giảm thiểu hiệu suất trên các lớp khác. Trong bài viết này, ta sẽ cũng tìm hiểu cách thức thực hiện của nhóm tác giả cũng như chi tiết kết quả thu được.
Bài toán và dữ liệu
Bằng cách tận dụng học sâu để tự động phân loại hình ảnh thu được từ trap camera (là cái ở hình minh họa bên dưới), các nhà sinh thái học có thể giám sát các nỗ lực bảo tồn đa dạng sinh học và tác động của biến đổi khí hậu đối với hệ sinh thái một cách hiệu quả hơn. Tuy vậy, do sự phân bố không cân đối giữa các bộ dữ liệu ảnh, các mẫu máy ảnh hiện tại thường thiên về các lớp vốn chiếm tỉ lệ đa số. Kết quả là, các mô hình đạt được tỉ lệ chính xác cao đối với một số nhóm đa số nhưng lại khó có thể đưa ra các kết quả đoán nhận đúng đối với nhiều lớp thiểu số.Từ vấn đề đó, bài toán mà không chỉ bài báo này mà còn các bài báo liên quan khác được liệt kê tập trung giải quyết là cố gắng cải thiện độ chính xác trên các lớp thiểu số và cùng với đó hạn chế tối đa số việc ảnh hướng xấu đến kết quả đoán nhận trên các lớp còn lại.

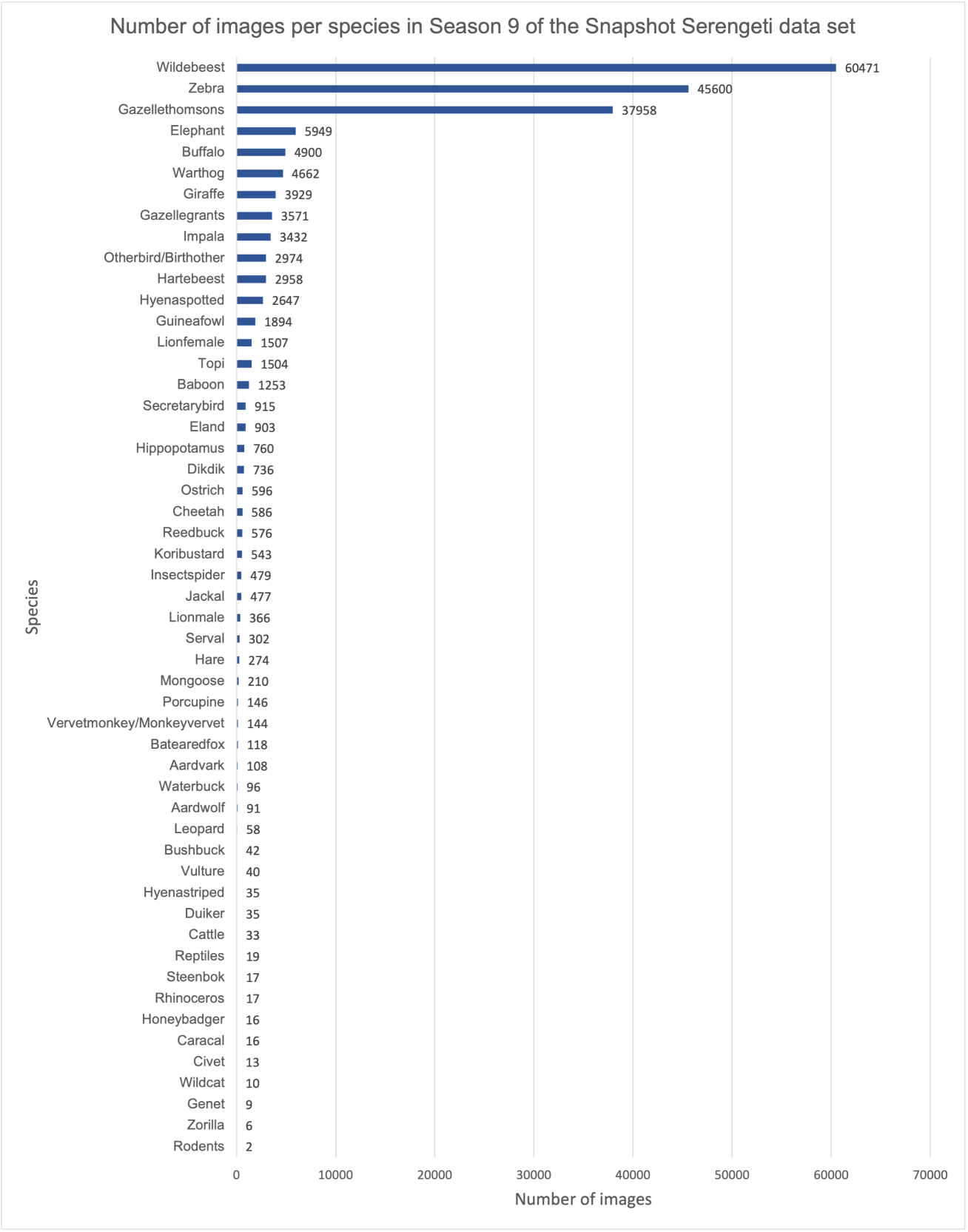
Quá trình thực nghiệm của các nhóm tác giả được thực hiện trên bộ dữ liệu Snapshot Serengeti. Đây là bộ dữ liệu được thu thập bằng cách triển khai 225 bẫy ảnh trên khắp 1.125 km 2 tại Vườn quốc gia Serengeti, Tanzania, để đánh giá động thái giữa các loài trong không gian và thời gian. Các máy ảnh đã hoạt động liên tục từ năm 2010 và đã tích lũy được 99.241 ngày bẫy ảnh và tạo ra 1,2 triệu bộ ảnh vào năm 2013 và chúng được cung cấp công khai tại địa chỉ http://www.snapshotserengeti.org/ Phần dữ liệu được sử dụng để thực hiện thí nghiệm là season thứ 9 trong bộ Snapshot Serengeti và đã được thực hiện qua các bước tiền xử lý nhằm loại bỏ các dữ liệu không hợp lệ. Cuối cùng, bộ dữ liệu sau khi xử lý (sẽ được gọi là bộ dữ liệu ban đầu) chứa 194.000 ảnh với 52 lớp. Phân bố dữ liệu trong bộ này được thể hiện ở hình dưới đây và ta có thể thấy rõ rằng, chúng đang rất không cân bằng khi mà ba nhóm đa số chiếm xấp xỉ 75% tổng số dữ liệu.
Phương pháp
Các phương pháp có liên quan
Giải quyết bài toán dữ liệu không cân bằng không phải là công việc mới xuất hiện và không chỉ vậy, đây còn là vấn đề điển hình của các bài toán liên quan đến hình ảnh thu được từ trap camera. Các nghiên cứu được công bố trước nghiên cứu này thường tìm đến các phương pháp bao gồm: khó quá thì bỏ quá - loại bỏ lớp hiếm khỏi bộ dữ liệu như Towards Automatic Wild Animal Monitoring: Identification of Animal Species in Camera-trap Images using Very Deep Convolutional Neural Networks, sử dụng hàm lỗi có trọng số Illuminating dark fishing fleets in North Korea hay sử dụng kết hợp tăng cường hình ảnh bổ sung cho các lớp hiếm và kỹ thuật lấy mẫu mới Three critical factors affecting automated image species recognition performance for camera traps. Nhìn chung các phương pháp được tiếp cận để giảm thiểu sự mất cân bằng lớp thường được chia thanh hai loại chính: kĩ thuật cấp dữ liệu (làm thay đổi phân phối lớp của dữ liệu, chẳng hạn như lấy mẫu quá mức thiểu số ngẫu nhiên (ROS) và lấy mẫu dưới phần lớn ngẫu nhiên (RUS), ...) và cấp thuật toán (thay đổi trên chính quá trình huấn luyện chẳng hạn như thay thế hàm mất mát, ...)
Bên cạnh các phương pháp kể trên, huấn luyện hai giai đoạn, một kỹ thuật lai, gần đây đã được giới thiệu và cho thấy thu được kết quả tốt để huấn luyện một bộ phân loại CNN trên một tập dữ liệu rất mất cân bằng về hình ảnh của sinh vật phù du, và sau đó nó được những người khác sử dụng để phân đoạn và phân loại hình ảnh. Do những kết quả đầy hứa hẹn này và khả năng áp dụng rộng rãi của đào tạo 2 giai đoạn, nhóm tác giả thử nghiệm đào tạo 2 giai đoạn đối với hình ảnh bẫy ảnh.
Phương pháp đề xuất
Quá trình huấn luyện hai giai đoạn được thực hiện thông qua hai bước:
- Giai đoạn 1: Một mạng CNN được đào tạo trên tập dữ liệu cân bằng hơn , thu được bằng bất kỳ phương pháp lấy mẫu nào như ROS, RUS hoặc kết hợp của chúng.
- Giai đoạn 2: Các trọng số chập 3 của bị đóng băng và mạng được đào tạo thêm trên tập dữ liệu không cân bằng ban đầu .
Để lý giải về việc thực hiện như mô tả ở trên, các tác giả cho rằng giai đoạn đầu tiên đào tạo các lớp tích chập với tầm quan trọng ngang nhau được phân bổ cho các lớp thiểu số, vì vậy chúng cũng sẽ học cách trích xuất các đặc trưng có liên quan cho các lớp này. Tiếp đó, trong giai đoạn thứ 2, các lớp phân loại học cách mô hình hóa sự mất cân bằng lớp có trong tập dữ liệu.
Thực nghiệm
Cách thức thực hiện
Để kiểm tra tính hiệu quả của phương pháp huấn luyện hai giai đoạn, nhóm tác giả đã huấn luyện mô hình cơ bản với cả bộ dữ liệu ban đầu . Tiếp theo,nhóm tác giả đào tạo 4 mô hình với các cách khởi tạo khác nhau của cho giai đoạn thứ nhất của quá trình đạo tạo bao gồm:
- : ROS (oversampling) classes có ít hơn 5000 ảnh cho tới 5000 ảnh
- : RUS (lấy mẫu dưới) các lớp có hơn 15k hình ảnh cho tới 15000 ảnh
- : ROS classes ít hơn 5k ảnh cho tới 5k và RUS classes có nhiều hơn 15k ảnh cho tới 15k
- : ROS classes ít hơn 5k ảnh cho tới 5k và RUS classes có nhiều hơn 5k ảnh cho tới 5k.
Bên cạnh đó, nhóm tác giả cũng đã sử dụng tỷ lệ mẫu thấp hơn cho các lớp có rất ít hình ảnh để tránh overfitting. Về các chỉ số đánh giá, nhóm tác giả không chỉ sử dụng top-1 accuracy mà còn sử dụng precision, recall và F1-score, vì các chỉ số này mang nhiều thông tin hơn đối với sự mất cân bằng trong lớp.
Kết quả thu được
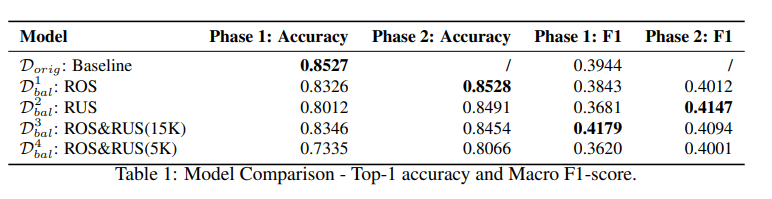
Về tổng quan thì bảng trên cho thấy việc đào tạo về tập dữ liệu cân bằng hơn làm giảm độ chính xác trong giai đoạn 1 cho tất cả các mô hình so với mô hình cơ sở đã được đào tạo về tập dữ liệu không cân bằng . Tuy nhiên, việc đào tạo thêm các lớp phân loại trong giai đoạn 2 trên tập dữ liệu đầy đủ sẽ làm tăng độ chính xác trở lại ít nhiều so với mức cơ sở cho tất cả các mô hình (ngoại trừ ROS & RUS (5K)) và cùng với đó độ chính xác trung bình giai đoạn 2 về cơ bản cao hơn đáng kể so với độ chính xác trung bình giai đoạn 1. Những quan sát này giúp chúng ta kết luận rằng 1) đào tạo hai giai đoạn hoạt động tốt hơn việc chỉ sử dụng các kỹ thuật lấy mẫu trên hầu hết các chế độ lấy mẫu và 2) đào tạo hai giai đoạn có thể tăng điểm F1 mà không mà không làm giảm đáng kể độ chính xác, có nghĩa là nó cải thiện các dự đoán của lớp thiểu số với rất hạn chế mất mát trong thành tích của lớp đa số.
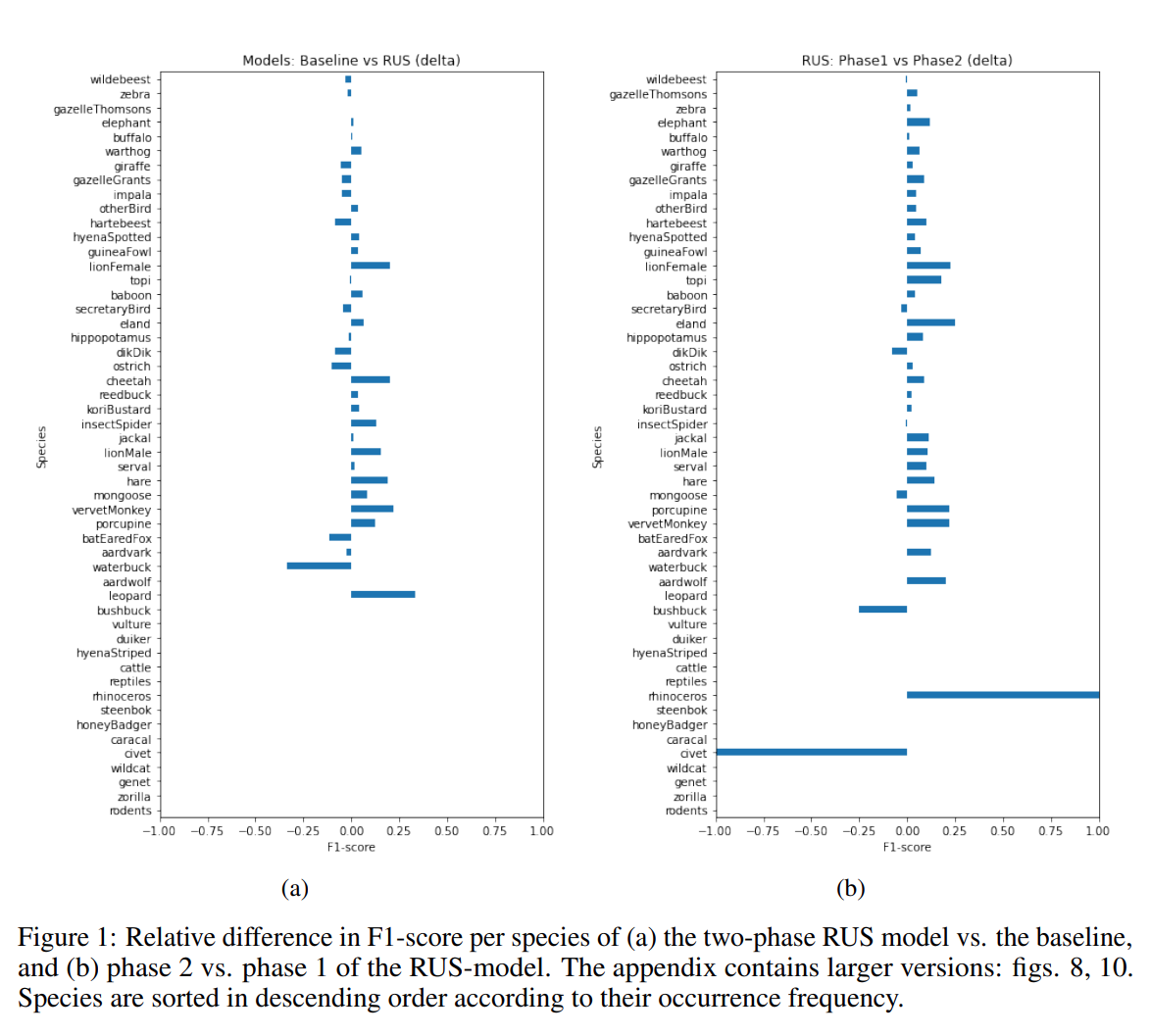
Về hiệu suất dành riêng cho từng lớp thì F1 score theo từng lớp tăng lên khi đào tạo hai giai đoạn cho đa số các lớp. Huấn luyện hai giai đoạn với RUS dẫn đến mức tăng trung bình lớn nhất của F1 theo trên mỗi lớp là 3% và sự gia tăng này đáng chú ý nhất đối với các tầng lớp thiểu số. RUS hoạt động tốt nhất là đáng chú ý, vì nhóm tác giả đã đào tạo mô hình RUS trong giai đoạn 1 với chỉ 85k hình ảnh, so với 131k – 231k cho các mô hình khác. Hình 1a cho thấy những thay đổi trong điểm F1 do huấn luyện hai giai đoạn với RUS.
Tổng kết
Bài viết này tập trung trình bày về cách thức sử dụng đào tạo hai giai đoạn để giảm thiểu vấn đề mất cân bằng lớp học đối với việc phân loại hình ảnh bẫy ảnh bằng CNN được trình bày trong bài báo Two-phase training mitigates class imbalance for camera trap image classification with CNNs. Dựa trên việc thực nghiệm, nhóm tác giả đã kết luận rằng 1) đào tạo hai giai đoạn hoạt động tốt hơn chỉ sử dụng kỹ thuật lấy mẫu trên hầu hết các chế độ lấy mẫu và 2) đào tạo hai giai đoạn cải thiện các dự đoán của lớp thiểu số với rất hạn chế mất hiệu suất của lớp đa số, so với việc chỉ đào tạo trên tập dữ liệu không cân bằng. Bài viết đến đây là hết, cảm ơn mọi người đã dành thời gian đọc.
All rights reserved
