
[Paper Explain] Cheaper Pre-training Lunch: An Efficient Paradigm for Object Detection
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Chắc hẳn mọi người mọi người khi nghiên cứu hoặc làm những ứng dụng về deep learning thì không còn xa lạ gì với khái niệm pre-training models. Điển hình ở đây chắc chắn là ImageNet pre-training, là một tập hợp các models pre-trained được đào tạo trên bộ dữ liệu ImageNet cực kỳ lớn. Nhưng rồi cái gì nó cũng sẽ có điểm yếu và dần phải được thay thế bởi những thứ mạnh mẽ hơn. Và đây chính là mục đích của bài viết này. Chào mừng đến với Montage pre-training. 
Rồi. Trước khi đi vào chi tiết thì mình phải biết được sức mạnh của nó thì mới bõ công đọc tiếp chứ đúng không. Ưu điểm thứ nhất là nó có thể tiết kiệm cả về mặt dữ liệu và chi phí tính toán, nó có thể tiết kiệm chi phí tính toán chỉ bằng 1/4 so với ImageNet pre-training. Ưu điểm thứ 2 là nó giảm khả năng dư thừa features từ ảnh gốc bằng cách sử dụng các kỹ thuật như sample selection và montage assembly việc này giúp cho độ chính xác của model tăng lên đáng kể, những kỹ thuật này chúng ta sẽ đi vào chi tiết ở phần tiếp theo.
Pipeline
Pipline của phương pháp được show ở hình bên dưới:
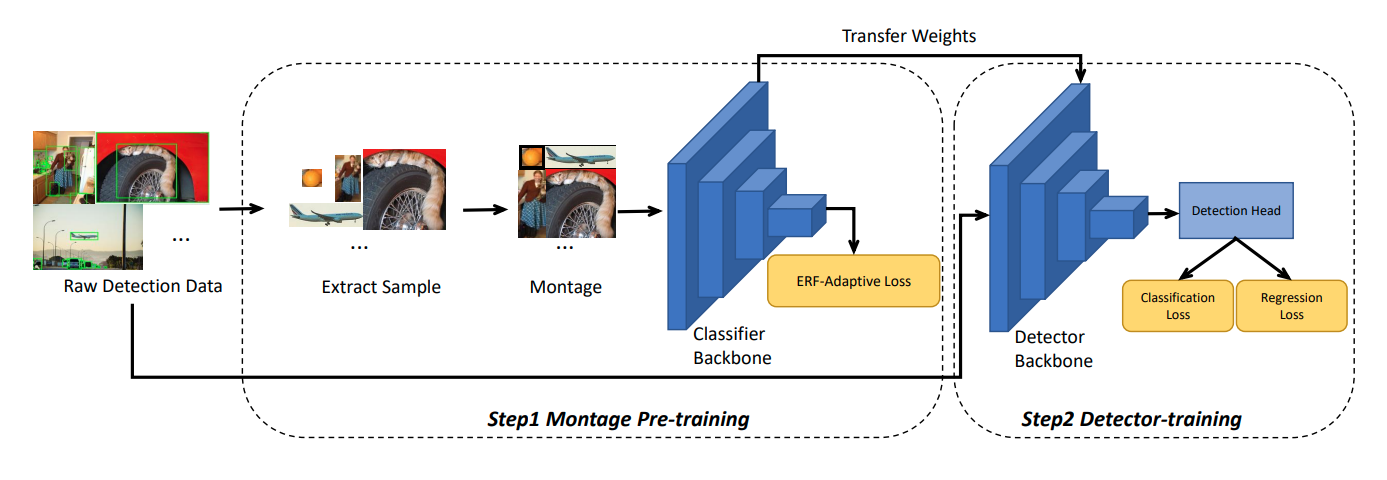
Với đầu vào là một bộ dữ liệu detection D, positive và negative sample sẽ được extract từ ảnh gốc trong tập dữ liệu D và sau đó được lưu lại như bộ bộ dữ liệu dùng để phân loại. Tiếp đến dữ liệu extracted sẽ được xử lý bằng cách cho qua một phương pháp Montage Manner. Phương pháp này sẽ nắp ráp 4 đối tượng vào thành một ảnh duy nhất, tiếp đến nó sẽ được đưa qua một backbone classifier và được tối ưu bằng ERF-adaptive loss. Cuối cùng ta sẽ thu được Montage pre-training, và model này sẽ được fine-tuned bằng chính tập data D cho task detection.
Oke. Tiếp theo cùng xem chúng nó nắp ráp object vào với nhau và cho qua ERF-adaptive như thế nào nhé.
Sample Selection
Với việc lựa chọn dữ liệu cân bằng là rất quan trọng, nó quyết định đến hiệu suất của pre-training model. Nên việc lựa chọn cẩn thận các mẫu positive và negative là rất quan trọng, nó giảm thiểu tối ta các đặc trưng dư thừa từ ảnh gốc.
Với positive sẽ là những sample mà vùng đó chưa đối tượng nằm trong detection dataset, còn negative sample là những khu vực chứa background. Để giúp cho việc lựa chọn các sample hiệu quả tác giả tuân theo một vài quy tắc nhất định.
- Thứ nhất, đối với positive samples, sẽ được extract từ gảnh gốc bằng ground-truth bounding boxes. Với việc các bounding boxes sẽ được thay đổi kích thước một cách ngẫu nhiên để thu được nhiều thông tin ngữ cảnh hơn.
- Thứ 2, đối với negative samples nó được tạo ra ngẫu nhiên từ các vùng của background và tất cả những negative samples phải tuân thủ theo yêu cầu chỉ số IoU(pos, neg) = 0. Trong đó IoU là Intersection-over-Union. Trong thí nghiệm tác giả có để tỉ lệ của positive so với negative sample là 10:1
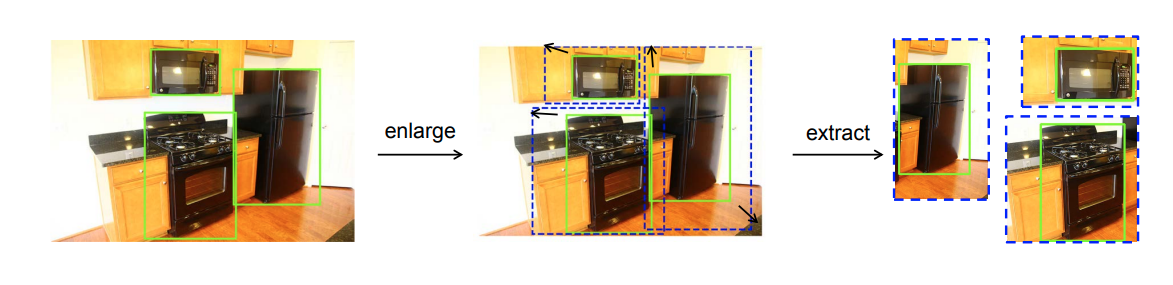
Tác giả đã tăng góc trên bên trái và góc dưới bên phải của bounding boxes lên một khoảng, ngoài ra tác giả cũng có thay đổi kích thước chiều ngang và chiều cao lên 2 lần so với ảnh gốc. Bằng thực nghiệm cho thấy việc thêm ngữ cảnh vào cho đối tượng giúp tăng 1.6% mAP khi train mô hình Faser R-CNN với backbone là ResNet 50.
Montage Assembly
Sau khi mà chúng ta đã có các mẫu phẩm ngon lành rồi nhưng có một vấn đề là input của model luôn cần một size nhất định và mọi input phải giống nhau, nhưng mẫu phẩm ta thu được thì không phải vậy. Vậy giờ làm sao để cho chúng nó vào model pre-training để đạt được hiệu quả tối đa đây?
Có 2 cách đơn giản để ráp các mâu phẩm này vào với nhau đó chính là warping và padding chúng nó về cùng một size ví dụ như 128, 224. Tuy nhiên, nhược điểm của thằng warping chính là nó làm thay đổi hình dáng của ảnh dẫn đến việc các thông tin ngữ cảnh bị sai lệch, trong khi đó thì thằng padding lại tốn quá nhiều khu vực thông tin dư thừa (cái khu vực màu đen được padding xì đó, chẳng làm cái quái gì) làm cho tài nguyên tính toán tăng lên. Vậy nên để có được một cái input perfect tác giả đã sử dụng Montage manner để tính toán quy mô và tỉ lệ của tối tượng. 4 đối tượng sẽ được ghép lại theo những quy tắc khác nhau để tạo thành input cho pre-training.
Tạm thời chúng ta hãy xem xét qua ưu điểm của Montage so với 2 thằng warp và padding.

Việc lắp ráp các sample lại với nhau sẽ phụ thuộc vào tỉ lệ kích thước của chúng. Để làm được điều này, các sample đã chia làm 3 nhóm: Group S (square), T (tall) và W (wide). Đối với các mẫu trong nhóm S sẽ giao động từ 0.5 và 1.5, trong khi đó nhóm T và W sẽ có tỉ lệ nhỏ hơn 0.5 và lớn hơn 1.5.
Như ở hình bên dưới chúng ta có thể thấy rằng ảnh đã được Montage với 2 S sample, 1 T sample và 1 W sample được lựa chọn ngẫu nhiên từ 3 nhóm và sắp xếp lại với nhau thành 4 vùng tương ứng. Đặc biệt có thể thấy, vùng S có diện tích bounding box nhỏ hơn nên đặt ở phía trên bên trái, trong khi đó S sample lớn hơn nên đặt ở phía dưới bên phải.
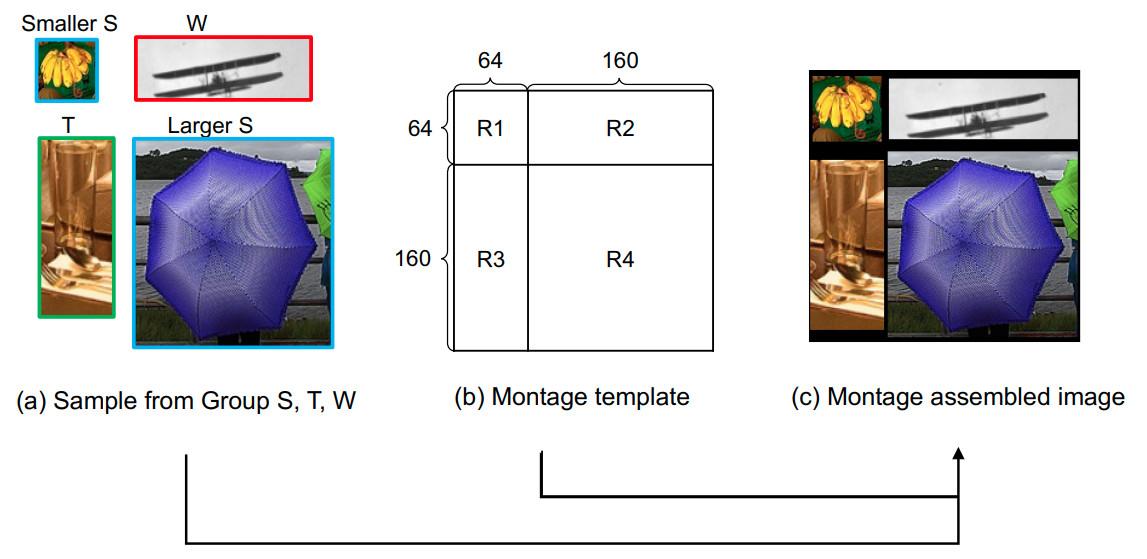
Tuy nhiên. Trong quá trình Montage assembled generation thì tác giả vẫn điều chỉnh kích thước của sample để cho phù hợp. Các sample này sẽ được crop và zero-padding một cách ngẫu nhiên, nó được điều chỉnh với kích thước của chúng sẽ lớn hơn hoặc nhỏ hơn kích thước trước đó.

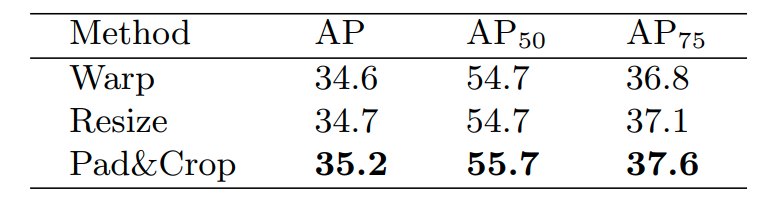
Chúng ta có thể thấy được kết hợp với pad&Crop có hiệu suất cao hơn hẳn so với Wrap và Resize
ERF-adptive Dense Classification
Ảnh sau khi Montage sẽ được đưa qua một backbone network để tạo ra tập feature map (ở đây tác giả không nói đến là gì, nhưng mình đoán nó là tỉ lệ của kích thước thay đổi của feature map sau khi đi qua backbone so với kích thước ảnh montage gốc, với tỉ lệ này < 1) trước khi cho qua average pooling. Đối với Montage pre-training có nhiều chiến lược learning khác nhau từ 4 sample được lắp rap thành ảnh. Có 2 chiến lược cho việc này là Global classification và Block-wise classification, nhưng trong phạm vi bài viết mình sẽ không đi chi tiết vào 2 chiến lược trên.
Note: Trước khi đi vào chi tiết chiến lược này các bạn hãy đọc qua bài Receptive field là gì? Tại sao nó lại quan trọng đối với CNN? này của mình để có thể hiểu rõ hơn phần tiếp theo nhé.
ERF-adaptive Dense strategy: Tác giả đã cung cấp một phương pháp giúp triển khai phân loại trên mỗi pixel của features . Trong đó, mô hình sử dụng soft labels và được tính toán dựa trên Effective receptive field tương ứng.
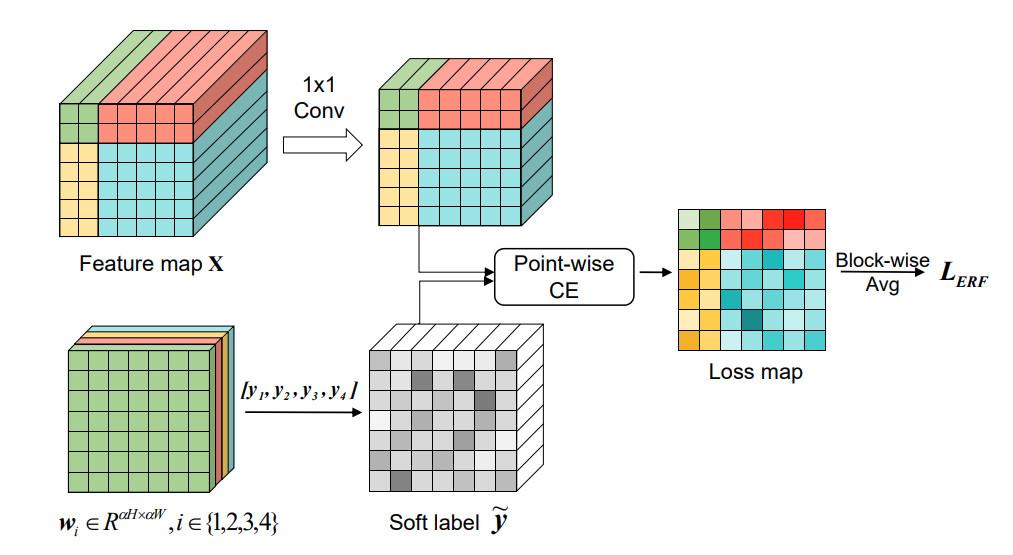
Ở đây, 4 màu khác nhau đại diện cho 4 khu vực tương ứng, giả sử màu xanh lục sẽ đại diện cho khu vực , và cường độ sáng khác nhau trên soft labels matrix và loss map sẽ đại diện cho các giá trị độ lớn khác nhau. Feature map được convolved bởi một 1x1 kernel để nhằm giảm số chiều của channels C. Tiếp đến có với của label sẽ cung cấp được một soft label tensor tương ứng tại mỗi điểm. Sau đó thì sẽ cho và soft labels qua cross-entropy loss, hàm loss sẽ tính toán trên từng vị trí và tạo ra một loss map tương ứng (loss map này sẽ có kích thước ). Tiếp đến loss map sẽ được đi qua một block-wise average để tạo ra average losses cho từng khu vực (ở đây chúng ta hiểu nó chư là average pooling vậy). Cuối cùng ERF-adaptive loss sẽ được ùng để tính trung bình cho 4 khu vực losses phía trước đó.
Với 4 vùng được định nghĩa ở Montage Assembly phía trên, sẽ được định nghĩa hard label tương tứng , . Tại điểm của feature map . Khi đó soft label tổng trọng số của 4 labels, được tính theo công thức sau:

Trong đó, giá trị của trọng số phụ thuộc vào điểm ERF tương ứng của nó. Tại điểm của feature map , chúng ta sẽ thu được ERF map tương tứng . Theo đó nếu như tại vị trí mà nằm trong khu vực của vùng R_i, thì tác giả có thiết lập một ngưỡng cho trọng số để làm cho chiếm ưu thế đến việc tác động lớn tại khu vực .
Tại mỗi vị trí thuộc vùng ta có trọng số của label được tính như sau:
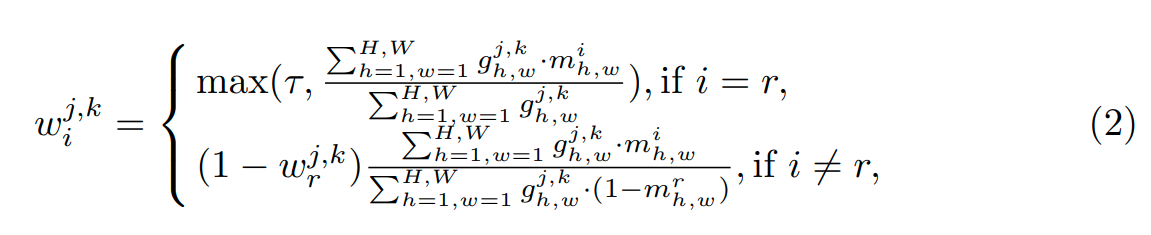
Trong đó là phần tử ở vị trí tương ứng của ERF matrix , đại diện cho giá trị tại vị trí trong ma trận binary mask ( là ma trận nhị phân được sử dụng để lựa chọn ERF pixel). Sau đó mô hình sẽ được tính toán như hình minh họa phí bên trên, có một lưu ý rằng trọng số w của soft labels ở công thức (1) sẽ được update sau mỗi 5k iterations thay vì update liên tục tại mọi iteration. Do vậy nó sẽ không làm ảnh hưởng nhiều đến thời gian training của mô hình.
Ở đây chúng ta có thể thấy được rằng ERF của vùng với phương pháp ERF-adaptive có diện tích là lớn nhất và mức độ contribute của các pixel trong ERF là tương đồng.

Kết quả thử nghiệm
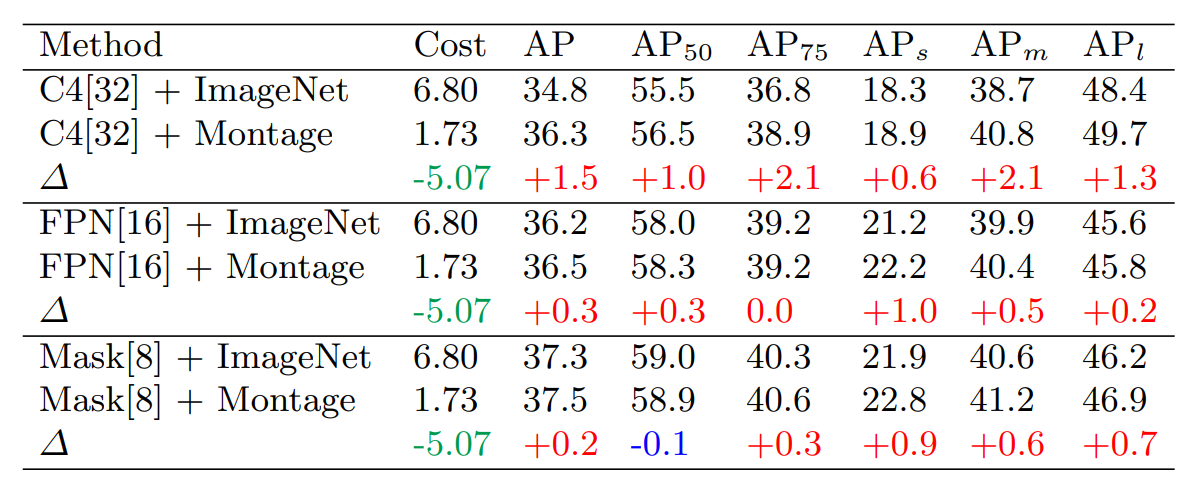
Kết quả thử nghiệm với backbone ResNet-50 và trên tập COCO val2017. C4 là Faster R-CNN với việc bỏ FPN và FPN là Faster-CNN với việc sử dụng FPN, cuối cùng Mask sẽ là Mask R-CNN sử dụng FPN. Như chúng ta có thể thấy ở đây thì khi các backbone kết hợp với montage strategy (Montage pre-trained) thì mang lại hiệu suất vượt trội hơn nhiều so với ImageNet pre-trained truyền thống.
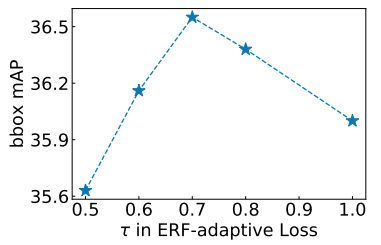
Như có thể thấy ở biểu đồ thống kê phía dưới. Khi ngưỡng càng lớn (vượt qua ngưỡng 0.7) thì có vẻ như soft labels sẽ dần chuyển thành trạng thái giống với hard labels bạn có thể thấy ở trên công thức (1) và (2). Vậy nên tác giả đã lựa chọn ngưỡng tốt nhất 0.7.
Tiếp đến để minh chứng cho việc Montage pre-training chỉ tốn 1/4 khối lượng tính toán so với ImageNet pre-training mà mang lại độ chính xác tương đương hoặc thậm chí cao hơn. Tại khoảng >60k iterations của Montage pre-training đã có hiệu suất tốt hơn đến 1.5% mAP so với ImageNet pre-training với >160k iterations.
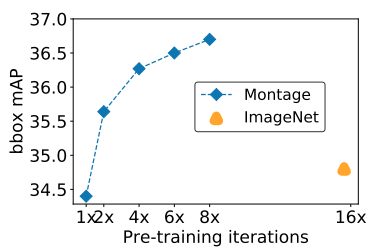
Bạn đã thấy được sức mạnh khủng khiếp của Montage pre-training chưa =))
Kết luận
Đây là một hướng nghiên cứu mới, nó không chỉ giúp tăng hiệu suất cho bài toán object detection như trong paper nghiên cứu. Mà nó là một hướng nghiên cứu mới có thể áp dụng cho rất nhiều bài toán khác giúp tăng hiệu suất của mô hình về cả tốc độ training và precision.
Oke. Nếu thấy bài explain này của mình có ích bạn hãy upvote cho mình nhé, còn nếu có bất kì thắc mắc nào thì hãy mạnh dạn comment xuống phía dưới mình sẽ cố gắng giải đáp thắc mắc của bạn trong tầm hiểu biết của mình 😄
References
[1] Cheaper Pre-training Lunch: An Efficient Paradigm for Object Detection
All rights reserved
