Pandas tutorial
Bài đăng này đã không được cập nhật trong 2 năm
Hôm nay, mình sẽ giới thiệu cho các bạn về việc sử dụng thư viện Pandas.
Mục tiêu của bài viết này bao gồm:
- Tạo cấu trúc dữ liệu Series và DataFrame
- Sử dụng hàm toán học pandas, cũng như
broadcasting features - Sử dụng thư viện Pandas để nhập và thao tác với dữ liệu
Pandas là gì ?
Thư viện Pandas được xây dựng trên NumPy và cung cấp các cấu trúc dữ liệu và các công cụ phân tích dữ liệu dễ sử dụng cho ngôn ngữ lập trình Python.
Khi bạn muốn sử dụng khai báo đơn giản như sau:
import pandas as pd
The series data structure
Series là một trong những cấu trúc dữ liệu chính của Pandas. Bạn có thể coi nó như một dạng kết hợp giữa List và Dictionary của Python. Mọi dữ liệu được lưu trữ theo thứ tự và có label để bạn có thể gọi chúng. Một Pandas Series là một mảng được gắn nhãn một chiều có khả năng chứa bất kỳ loại dữ liệu nào với nhãn trục hoặc chỉ mục. Một cách dễ hình dung, ta có dữ liệu gồm 2 cột. Cột đầu tiên là Index, nó giống như Keys trong Dictionary. Cột thứ 2 mới là dữ liệu. Ta phải chú ý là cột dữ liệu có label riêng của nó và có thể gọi bằng thuộc tính .name. Điều này khác với Dictionary và rất hữu ích khi nó hợp nhất với nhiều cột dữ liệu.

Ta có thể khởi tạo một series bằng việc truyền vào một list có giá trị. Khi đó hàm panda sẽ tự động gán chỉ số bắt đầu bằng 0 và đặt tên chuỗi là None. Ví dụ :
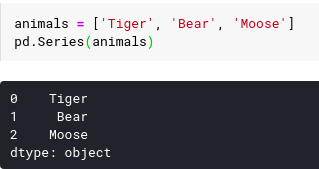
Chúng ta thấy ở đây hàm pandas tự động xác định kiểu dữ liệu được tổ chức trong list, trong ví dụ trên chúng ta thực hiện trong danh sách các string và hàm pandâ đặt kiểu là 'object'.
Nếu chúng ta thực hiện trong danh sách tất cả các số như ví dụ sau thì hàm panda sẽ đặt kiểu là int64.

Bên dưới hàm panda lưu trữ các giá trị đã nhập trong series sử dụng thư viện numpy. Điều này cung cấp tăng tốc độ khi xử lý dữ liệu so với python List truyền thống. Vì lý do tại sao thì bạn có thể xem lại phần ndarray bài viết NumPy trước của mình.
Có một số loại chi tiết tồn tại cho hiệu suất mà rất quan trọng để biết. Điều quan trọng nhất là numpy và hàm panda xử lí dữ liệu bị thiếu thế nào. Trong pyhton chúng ta có kiểu none để chỉ ra việc thiếu dữ liệu. Nhưng chúng ta làm gì nếu chúng ta muốn có một danh sách định kiểu giống như chúng ta làm trong hàng loạt đối tượng?
Bên dưới hàm panda thực hiện một số loại chuyển đổi. Nếu chúng ta tạo ra list string và chúng ta có một phần tử, một kiểu None, hàm panda chèn nó là None và sử dụng loại đối tượng này cho hàng nằm bên dưới.

Nếu chúng ta tạo ra list các số, các số nguyên và đặt vào loại None, hàm panda tự động chuyển điều này thành một giá trị số thực động đặc biệt được xác định là NaN, viết tắt của not a number.

NaN không phải là None và khi chúng ta thử kiểm tra, nó sai. Ta không thể tự động làm kiểm tra NaN với chính nó. Khi ta làm, câu trả lời luôn là sai. Ta cần phải sử dụng các hàm đặc biệt để kiểm tra.
import numpy as np
np.nan == None # False
np.nan == np.nan # False
np.isnan(np.nan) # False
Một series có thể được tạo ra từ dictionary. Nếu ta tạo bằng cách này, index được gán tự động là các key của dictionary mà ta đã cung cấp mà không phải là các chỉ số tăng như trên. Ví dụ như sau:

Ta cũng có thể khởi tạo đích danh index bắng cách truyền truyền chỉ số như một list string như sau:

Điều gì xảy ra nếu danh sách các giá trị index của ta không liên kết với với các key trong từ điển ? Hàm panda sẽ chỉ lấy các phân từ có key là các giá trị index được truyền vào. VÍ dụ:

Querying a Series
Một hàm panda Series có thể được truy vấn theo vị trí index hoặc index label.Như ta thấy ở trên, nếu ta không đưa ra một index vào series, index và label là các giá trị giống nhau. Để truy vấn bởi định vị số bắt đầu ở 0, sử dụng thuộc tính iloc. Để truy vấn label index, ta có thể sử dụng thuộc tính 'loc'. Ta có ví dụ như sau:
sports = {'Archery': 'Bhutan',
'Golf': 'Scotland',
'Sumo': 'Japan',
'Taekwondo': 'South Korea'}
s = pd.Series(sports)
print(s.iloc[3]) # 'South Korea'
print(s.loc['Golf'] # 'Scothland'
print(s[3]) # 'South Korea'
Với 2 cách dưới bạn thấy ở trên, thì ta có thể hiểu là hàm pandas cố gắng tạo ra mã có thể đọc được và cung cấp các loại cú pháp thông minh sử dụng toán tử chỉ số trực tiếp trên các chuỗi. Ví dụ ta truyền vào một số nguyên, toán tử sẽ hoạt động như thể bạn muốn truy vấn qua thuộc tính iloc. Nếu ta truyền vào một đối tượng 'string', nó sẽ truy vấn như kiểu bạn muốn sử dụng thuộc tính 'loc' dựa trên label.
Điều gì sẽ xảy ra nếu index của ta là một list số nguyên? Điều này hơi phức tạp và hàm panda không thể xác định tự động liệu bạn đang dự định truy vấn bằng ví trí index hay index label. Ví thế ta cần phải cẩn thận khi sử dụng toán tử chỉ số trên chính các series. Và lựa chọn an toàn hơn cả là sử dụng iloc hoặc loc. Ví dụ ta muốn truy xuất phần tử đầu tiên:
s = {99: 'a',
100: 'b',
101: 'c',
102: 'd'}
s = pd.Series(s)
print(s[0]) # lỗi
print(s.iloc[0]) # 'a'
Bây giờ ta đã biết cách lấy dữ liệu ra khỏi series. Bây giờ, chúng ta tập chung về làm việc với dữ liệu. Một số nhiệm vụ phổ biến là muốn xem dữ liệu bên trong series và làm một số phép toán. Tương tự như thư viện NumPy thì Pandas bên dưới hỗ trợ phương pháp tính toán gọi là vectorization.
Ví dụ tính tống các số trong series ta làm như sau:
s = pd.Series([100.00, 120.00, 101.00, 3.00])
total = np.sum(s)
print(total) # 324
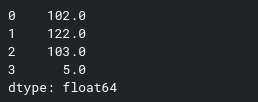
Tiếp theo cộng 2 vào giá trị mỗi hàng như sau:
s+=2 #adds two to each item in s using broadcasting
s.head()
Ta cũng có thể thêm một giá trị mới chỉ bằng cách gọi toán tử chỉ số .loc:

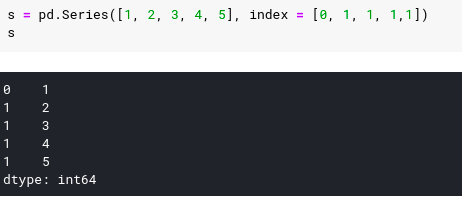
Chúng ta thấy rằng các loại kết hợp cho các kiểu giá trị dữ liệu hoặc index label đều không thành vấn đề với Pandas. Như các ví dụ ở trên thì mỗi dữ liệu chỉ có 1 chỉ số duy nhất, ta có một ví dụ nơi các giá trị chỉ sô không phông phải là duy nhất :

Phần tiếp theo chúng ta sẽ học về DataFrame, nó tương tự như đối tượng series nhưng bao gồm các cột dữ liệu và là cấu trúc ta sẽ dành thời gian làm việc khi làm sạch và tập hợp dữ liệu.
The DataFrame Data Structure
Cấu trúc dữ liệu DataFrame là trọng tâm của thư viện panda. Nó là phần quan trọng mà ta sẽ làm việc trong phân tích dữ liệu và các nhiệm vụ làm sạch dữ liệu. DataFrame là khái niệm về một đối tượng series 2 chiều, có một chỉ mục và các cột, mỗi cột có một label. Thực tế sự khác nhau giữa cột và hàng chỉ là phân biệt về khái niệm. Ta có thể coi DataFrame là một mảng được dán nhãn hai trục.

Ta có thể tạo ra DataFrame bằng nhiều cách khác nhau. Ví dụ ta có thể sử dụng một nhóm cái series, mỗi series đại điện cho một hàng dữ liệu, hoặc ta có thể sử dụng một nhóm các dictionary, mỗi dictionary đại diện cho một hàng dữ liệu. Ta có ví dụ như sau:
import pandas as pd
purchase_1 = pd.Series({'Name': 'Chris',
'Item Purchased': 'Dog Food',
'Cost': 22.50})
purchase_2 = pd.Series({'Name': 'Kevyn',
'Item Purchased': 'Kitty Litter',
'Cost': 2.50})
purchase_3 = pd.Series({'Name': 'Vinod',
'Item Purchased': 'Bird Seed',
'Cost': 5.00})
df = pd.DataFrame([purchase_1, purchase_2, purchase_3], index=['Store 1', 'Store 1', 'Store 2'])
df.head()

Tương tự như series, chúng ta có thể trích xuất dữ liệu sử dụng thuộc tínhiloc và loc. Bởi vì DataFrame là hai chiều, thực hiện đơn với toán từ lock sẽ trả ra 1 series là một hàng. Ví dụ như ta muốn lấy dữ liệu của Store 2, ta làm như sau, lưu ý rằng tên của series sẽ quay lại là chỉ số của hàng, trong khi kết quả bao gồm cột tên:

Ta có thể kiểm tra loại dữ liệu trả về bằng việc sử dụng hàm type trong python.

Một điều quan trọng để ghi nhớ là các chỉ số, tên cột có thể không phải là duy nhất. Ví dụ:

Trong ví dụ trên, ta thấy 2 hồ sơ mua bán cho Store 1 là các hàng khác nhau. Nếu chúng ta sử dụng một giá trị đơn với thuộc tính Lock của DataFrame, nhiều hàng của DataFrame được trả ra thì đó không phải là một Series mới mà là một DataFrame mới.

Một trong những tính năng của Panda's DataFrame là ta có thể nhanh chóng lựa tập dữ liệu trên nhiều nhiều trục. Ví dụ như ta muốn danh sách giá của cửa hàng 1, ta sẽ cúng cấp 2 tham số đến .loc, một là chỉ số hàng, 1 là tên cột như sau:
df.loc['Store 1', 'Cost']

Nếu chúng ta chỉ muốn lựa chọn cột và lấy ra danh sách tất cả các chi phí thì sao ? Cách đơn giản nhất sẽ như sau:
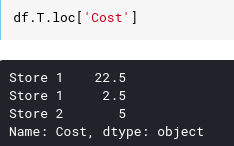
Nó hoạt động nhưng nó khá là xấu, vì iloc và loc được sử dụng cho việc chọn hàng, vì vậy các nhà phát triển Pandas sử dụng toán tử chỉ số trực tiếp DataFrame cho việc chọn cột, vì các cột luôn luôn có tên. Những điều này quen thuộc với cơ sở dữ liệu quan hệ, toán tử này tương tự với ánh xạ cột.

Cuối cùng, vì kết quả sử dụng toán tử index là DataFrame hoặc Series ta có thể sâu chuỗi các toán tử với nhau. Ví dụ ta có thể viết lại truy vấn cho truy vấn danh sách chi phí của cửa hàng 1 như sau:

Cái này nhìn khá là hợp lí và đưa ra kết quả chúng ta muốn. Nhưng việc sâu chuỗi có thể đi kèm với chi phí và tránh được tốt nhất nếu bạn có thể sử dụng cách tiếp cận khác. Cụ thể sâu chuỗi có xu hướng làm cho hàm panda trả về một bản sao của DataFrame thay vì một view của DataFrame. Với việc lấy ra dữ liệu, điều này không phải là một vấn đề lớn mặc dù nó có thể sẽ chậm hơn cần thiết. Nếu bạn đang thay đổi dữ liệu, điều này là một khác biệt quan trọng và có thể là lý do của lỗi. Đây là một phương thức khác:

Như chúng ta thấy .loc thực hiện việc chọn hàng và nó có thể lấy hai thông số, chỉ số hàng và danh sách tên cột. .loc cũng hỗ trợ slicing. Nếu chúng ta muốn chọn tất cả các hàng, chúng ta có thể sử dụng một cột để chỉ ra một mảng đầy đủ từ bắt đầu đến kết thúc. Sau đó thêm tên cột là thông số thứ hai như một chuỗi. Thực tế nếu chúng ta muốn bao gồm nhiều cột, chúng ta có thể làm trong một danh sách. Và panda sẽ mang lại các cột chúng ta yêu cầu.
Bây giờ trước khi chúng ta dừng thảo luận về truy cập dữ liệu trong DataFrame, hãy nói về việc loại bỏ dữ liệu.Rất dễ dàng để xóa dữ liệu trong Series và DataFrame và chúng ta có thể sử dung hàm drop để làm điều đó. Chức năng xóa không thay đổi khung dữ liệu theo mặc định. Thay vì thế trả lại cho bạn một bản sao của khung dữ liệu với các hàng bị gỡ bỏ. Chúng ta có thể thấy rằng khung dữ liệu gốc của chúng ta vẫn còn nguyên vẹn.

Hàm Drop có nhiều tham số lựa chọn, trong đó 2 tham số ta nên quan tâm, đầu tiền là inplace, nó được thiết lập là False, DataFrame có cập nhật tại chỗ hay là 1 bản sao sẽ được trả lại. Tham số thứ 2 là axis- trục mà ta sẽ xóa. Mặc định là 0 là trục hàng, nhưng ta có thể thay đổi thành 1 nếu ta muốn xóa hàng. Các tham số trong hàm Drop như sau:

Có cách thứ hai để xóa cột, đó là qua việc sử dụng toán tử chỉ số, sử dụng từ khóa del. Cách xóa dữ liệu này tuy nhiên ảnh hưởng ngay lập tức trên DataFrame và không trả về kết quả là 1 View (mình đã giải thích khái niệm về view và coppy trong bài NumPy).
Cuối cùng thêm một cột mới vào DataFrame dễ như việc gán nó vào một số giá trị. Ví dụ như Nếu chúng ra muốn thêm Location mới như là một cột với giá trị mặc định là None.

Dataframe Indexing and Loading
Luồng công việc phổ biến là đọc dữ liệu vào một DataFrame sau đó giảm khung dữ liệu này với các cột cụ thể hoặc các hàng mà bạn quan tâm. Trong bài viết này chúng ta sẽ chủ yếu sử dụng tập dữ liệu có kích thước vừa hoặc nhỏ hơn. Ở phần này, ta sẽ làm việc với file olympics.csv, đó là dữ liệu từ wikipedia chứa một danh sách tóm tắt về huy chương các quốc gia đã chiến thắng ở Olympics. Chúng ta có thể đọc file này trong DataFrame bằng cách gọi read_csv, câu lệnh df.head() sẽ xuất ra 5 phần từ đầu tiên.
df = pd.read_csv('olympics.csv')
df.head()

Khi chúng ta nhìn vào DataFrame, ta thấy rằng phần đầu tiên có phần từ NaN trong đó. Bởi vì nó là một giá trị trống và các hàng được lập chỉ số tự động cho chúng ta. Ta thấy rõ ràng hàng dữ liệu đầu tiên trong DataFrame là cái chúng ta thực sự muốn thấy như các tên cột, và cột đâu tiên trong dữ liệu là tên các quốc gia, cái mà chúng ta muốn là cột chỉ số. Ta sẽ làm như sau:
df = pd.read_csv('olympics.csv', index_col = 0, skiprows=1)
df.head()

Bây giờ, dữ liệu này đến từ tất cả các bảng huy chương Olympics trên wikipedia. Nếu chúng ta nhìn vào các cột ta có thể thấy thay vì viết là các huy chương vàng, bạc, đồng mà dữ liệu viết "01 !", "02 !", "03 !". Vì thế chúng ta sẽ làm sạch dữ liệu, ta có thể làm điều này bằng việc chỉnh sửa trên file .csv trực tiếp nhưng chúng ta cũng có thể tên các cột bằng sử dụng Pandas.
Panda lưu trữ danh sách tất cả các cột trong thuộc tính .columns.

Chúng ta có thể thay đổi các giá trị của các cột tên bằng cách lập lại danh sách này và dùng phương thức rename của DataFrame như sau:
for col in df.columns:
if col[:2]=='01':
df.rename(columns={col:'Gold' + col[4:]}, inplace=True)
if col[:2]=='02':
df.rename(columns={col:'Silver' + col[4:]}, inplace=True)
if col[:2]=='03':
df.rename(columns={col:'Bronze' + col[4:]}, inplace=True)
if col[:1]=='№':
df.rename(columns={col:'#' + col[1:]}, inplace=True)
df

Querying a DataFrame
Hàm Boolean có đầy sức mạnh và là nền tảng hiệu quả của truy vấn NumPy và panda. Kĩ thuật này được sử dụng trong các lĩnh vực khoa học máy tính, ví dụ, trong đồ họa. Nhưng nó không thực sự có sự tương tác trong các cơ sở dữ liệu quan hệ truyền thống khác vì thế tôi nghĩ nó đáng để chỉ ra ở đây.

Hàm Boolean được tạo ra với việc áp dụng các toán tử trực tiếp với các chuỗi panda hoặc các đối tượng khung dữ liệu.
Để truy vấn, chúng ta có thể sử dụng hàm where như trong thư viện NumPy. Hàm Where dùng Boolean mask như một điều kiện áp dụng với DataFrame hoặc Series và trả ra DataFrame mới hoặc Series hình dạng tương ứng.
Hãy áp dụng hàm Boolean với dữ liệu Olypics của chúng ta và tạo ra DataFrame các quốc gia dành huy chương vàng ở thế hội mùa hè. Đầu tiên ta sẽ lấy ra những quốc gia có huy chương vàng, nó.

Chúng ta thấy rằng chỉ dữ liệu từ các quốc gia mà đáp ứng điều kiện được giữ lại. Tất cả các quốc gia không đáp ứng điều kiện thì ghi là NaN. Hầu hết các hầm thống kê xây dựng trong khung dữ liệu bỏ qua các gia trị NaN. Ví dụ nếu chúng ta nhập df.count() trên khung dữ liệu trên, ta sẽ thấy 100 quốc gia có huy chương vàng được trao ở thế vận động mùa hè, trong khi nếu chúng ta đếm ở dữ liệu gốc, chúng ta thấy có tổng số 147 quốc gia.

Thường chúng ta muốn xóa những dòng không có dữ liệu. Để làm điều này ta có thể dụng hàm dropna(). Bạn có thể tùy chọn cung cấp xóa Na ở những trục được xem xét. Hãy nhớ rắng các trục chỉ là định hướng cho cột hoặc hàng và mặc định là 0, có nghĩa là hàng.
only_gold = only_gold.dropna()
only_gold.head()

Cách này hơi dài dòng, dưới đây là một ví dụ ngắn gọn hơn về làm thế nào để truy vấn. Bạn sẽ thấy rằng không có NaNs khi bạn truy vấn bằng cách này, pandas tự động lọc ra những hàng không có giá trị.
only_gold = df[df['Gold'] > 0]
only_gold.head()
Ta cũng có thể nối các điều kiện bằng cách dùng or/and để tạo ra một truy vấn phức tạp và kết quả về là một Boolean đơn giản. Ví dụ chúng ta truy vấn số lượng các quốc gia dành được huy chương vàng ở 1 trong 2 thế vận hội.
len(df[(df['Gold'] > 0) | (df['Gold.1'] > 0)]) # kq:101
Hoặc ta muốn truy vấn số lượng các quốc gia có huy chương vàng ở cả 2 thế vận hội:
len(df[(df['Gold.1'] > 0) & (df['Gold'] > 0)]) #kq: 37
Một ví dụ khác cho vui  , quốc gia nào có huy chương vàng ở thế vận hội mùa đông nhưng chưa có ở thế vận hội mùa hè. Ta làm như sau:
, quốc gia nào có huy chương vàng ở thế vận hội mùa đông nhưng chưa có ở thế vận hội mùa hè. Ta làm như sau:
df[(df['Gold.1'] > 0) & (df['Gold'] == 0)]

Indexing Dataframes
Chỉ số là cần thiết cho nhãn mác định mức hàng và chúng ta biết các hàng tương ứng với trục 0. Trong dữ liệu Olimpics, chúng ta đã đặt chỉ số là tên của các tên đất nước. Chúng ta có thể đặt một cột là cột index bằng sử dụng hàm set_index. Hàm set_index là quá trình tự hủy, nó không giữ lại các chỉ mục hiện tại. Nếu bạn muốn giữ chỉ số hiện tại, bạn cần tạo ra cột mới và sao chép các giá trị từ thuộc tính chỉ mục. ví dụ như sau:
df['country'] = df.index
df = df.set_index('Gold')
df.head()
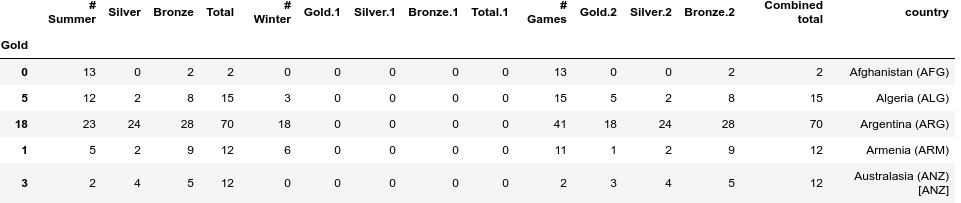
Chúng ta có thể bỏ hoàn toàn các chỉ mục đã tạo bằng cách gọi hàm reset_index. Điều này sẽ tạo ra chỉ số mặc định.
df = df.reset_index()
df.head()

Tl,dr
Bài viết đến đây là dài, bài dài nhất mình viết đến thời điểm này  , cảm ơn các bạn đã đọc. Nếu có thắc mắc gì thì bạn có thể để lại comment. Hẹn bạn ở các bài viết tiếp theo của mình.
, cảm ơn các bạn đã đọc. Nếu có thắc mắc gì thì bạn có thể để lại comment. Hẹn bạn ở các bài viết tiếp theo của mình. 
Tài liệu tham khảo
- Week 2 Introduction to Data Science in Python trên coursera
All rights reserved
