Optimizing MySQL Queries With Indexes
Bài đăng này đã không được cập nhật trong 4 năm
Abstract
Với sự bùng nổ của dữ liệu hiện nay , các dịch vụ ngày càng trở lên chậm chạp và không đáp ứng được mong muốn của người sử dụng, có rất nhiều nguyên dẫn đến sự chậm chạp trên tuy nhiên có 1 nguyên chính đó là sự phát triển quá lớn của dữ liệu dẫn đến việc truy suất ngày càng chậm và không còn độ ổn định như trước nữa. Để giải quyết vấn đề trên có một cách mà được lập trình viên rất ưu chuộng và cũng là giải pháp đế tăng hiệu suất của dịch đó là Indexes.

What is an index
Indexes là cấu trúc dữ liệu (data structures) được các DB-Engines sử dụng để tìm một cách nhanh chóng các dòng trong bảng dữ liệu. Indexes giúp gia tăng hiệu suất của các câu truy vấn dữ liệu một cách đáng kể và đóng vai trò quan trọng khi dữ liệu trong bảng phát triển quá lớn. Thông thường việc xây dựng ứng dụng lúc ban đầu chỉ chạy thực nghiệm với dữ liệu rất nhỏ, nhẹ và thấy rằng ứng dụng chạy tốt là có thể chấp nhận được. Tuy nhiên dữ liệu sẽ gia tăng một số lượng rất lớn trong thời gian sử dụng như thể hiệu suất sẽ bị giảm đi một cách rõ rệt. Chính vị vậy mình muốn viết bài này để cũng nhau bàn luận về cách tôi ưu hóa câu lệnh query với Indexes.
- An index is quick lock up data structure for finding rows in a table
Cách đơn giản nhất để hiểu index hoạt động như thế nào trong MySQL đó là việc sử dụng các mục lục trong các từ điển để tìm các từ cần tra nghĩa, để tìm từ một từ cụ thể trong từ điển trước tiên cần phải nhìn mục lục để biết từ cần tìm nằm trong khoảng từ trang số bao nhiêu. MySQL cũng sử dụng cách tương tự như vậy để tìm kiếm với index. Sau khi đánh index MySQL sẽ thực hiện tìm kiếm trên cấu trúc vừa được xây dựng để tìm kiếm giá trị được yêu cầu. Ví dụ:
mysql> SELECT first_name FROM sakila.actor WHERE actor_id = 5;
Cột actor_id đã được đánh tạo index, như vậy MySQL sẽ xây dựng lại bảng actor theo cột actor_id đã được đánh index sau khi thực hiện câu lệnh trên MySQL sẽ tìm kiếm trong mục lục với actor_id = 5 để trả về tên của diễn viên đó .
- May be separate from the table or the way of organizing the data itself
Việc đáng index vào một cột có thể được hiểu rằng với một bảng actor chứa các actor_id không được sắp xếp sau khi tạo index cho cột actor_id, MySQL đã xây dựng lại bảng actor được sắp xếp theo thứ tự các actor_id.
Có một điều cần lưu ý đó là phải phân biệt được cơ chế lưu trữ của MySQL. Có 2 cơ chế lưu trữ chính đó là MyISAM và InnoDB và cơ chế này xây dựng indexes theo các cách khác nhau do đó ảnh hưởng cũng khác nhau. Ví dụ MyISAM sử dụng kĩ thuật nén do đó indexes nhỏ hơn. Hay InnoDB sử dụng indexes có cấu trúc dạng B-Tree còn MyISAM thì sử dụng index có cấu trúc khác nhưng cả 2 đều tuân thử theo các quy tắc nhất định.
- Các loại cấu trúc indexes
- B - Tree
- Hash
- Log - Structure Merge
- Other (full-text, spatial, skiplist)
A Table Index
Ví dụ bảng dữ liệu với dữ liệu được thêm vào ngẫu nhiên và sau đó tạo index ở cột B
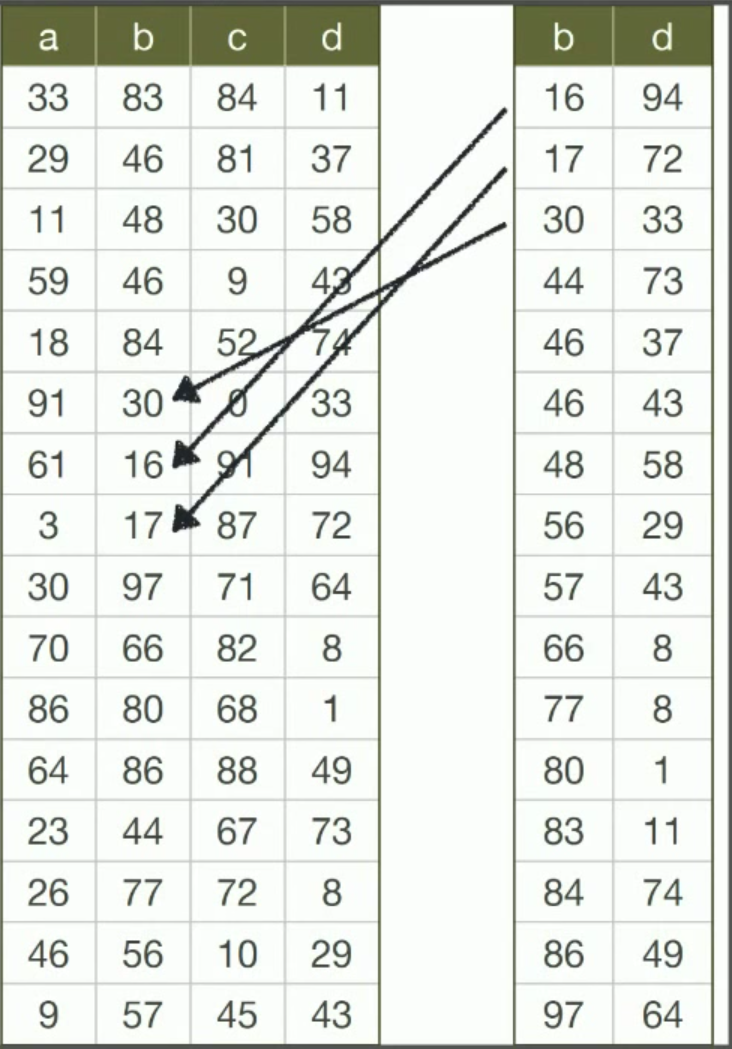
Dữ liệu được gán index trở thành key của bảng và được sắp xếp theo thứ tự nhất định
Example
Giả sử ta có bảng actor như sau :

Kiểm tra bảng actor xem đã có index nào được tạo chưa:

Như vậy bảng actor chỉ có duy nhất một cột được tạo index là cột actor_id cũng là khóa chính của bảng actor. Tuy nhiên với các ứng dụng thông thường sẽ không thể tìm kiếm theo id của actor được do đó yêu cầu đặt ra là phải tìm kiếm theo last_name của actor đó, câu lệnh sẽ thực hiện như sau:
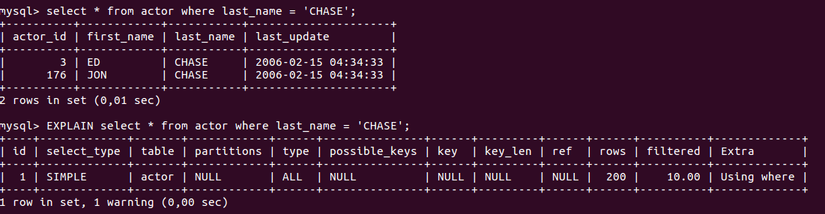
Sau khi thực hiện câu lệnh select, sử dụng lệnh explain để giải thích câu lệnh thì có thể thấy rằng ở cột 'row' là số dòng mà mysql phải duyệt trong bảng actor để tìm last_name = 'CHASE'; type là kiểu duyệt giá trị 'ALL' có nghĩa là MySQL đã phải duyệt tất cả dữ liệu trong bảng. Tuy nhiên nếu dữ liệu tăng từ 4 -5 lần thì việc duyệt cũng phải tăng với một số lương như vậy dẫn đến hiệu năng giảm một cách đáng kể. Để cải thiện vấn đề trên sử dụng index cho cột last_name như sau:

Thử explain lại với câu truy vấn trên:

Index Tree
Trong môn CTDL & GT có một cấu trúc rất nổi tiếng là cây nhị phân cấu trúc nay có đặc điểm tìm kiếm rất nhanh so với các cấu trúc dữ liệu khác do đó Index thông thường được xây dựng trên cấu trúc ví dụ: B- Tree. Đặc điểm của B- Tree như sau
- B- Tree se có các nút cha/con có mối quan hệ với nhau ví dụ: nút cha có giá trị 5 thì nút con sẽ có giá trị nhỏ hơn 5...
- Nút cha sẽ chỉ giới hạn của các nút con, và giới hạn của nút con.
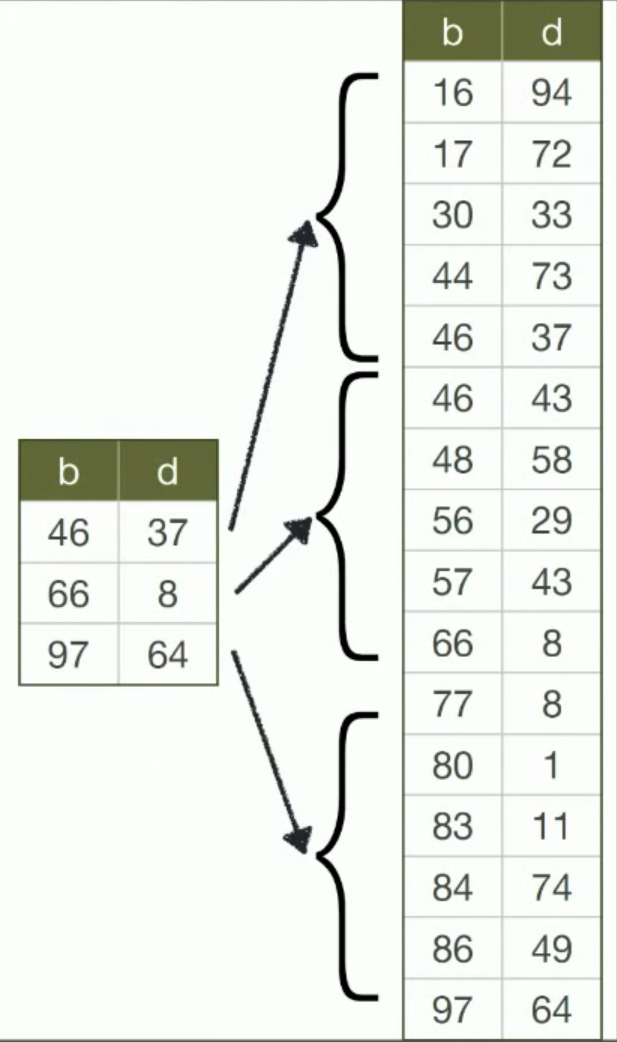
Việc xây dựng theo cấu trúc B- Tree tăng tốc độ tìm kiếm các giá trị hoặc khoảng giá trị. B- tree là một trong những cấu trúc thường được sử dụng trong index. Đặc điểm của B-Tree: các nút cha/con đều được sắp xếp theo thứ tự, hỗ trợ cả về tìm kiếm 1 giá trị cụ thể, hoặc các giá trị nằm trong một khoảng cố định, đặc biệt đối với các lệnh GROUP BY, ORDER BY...
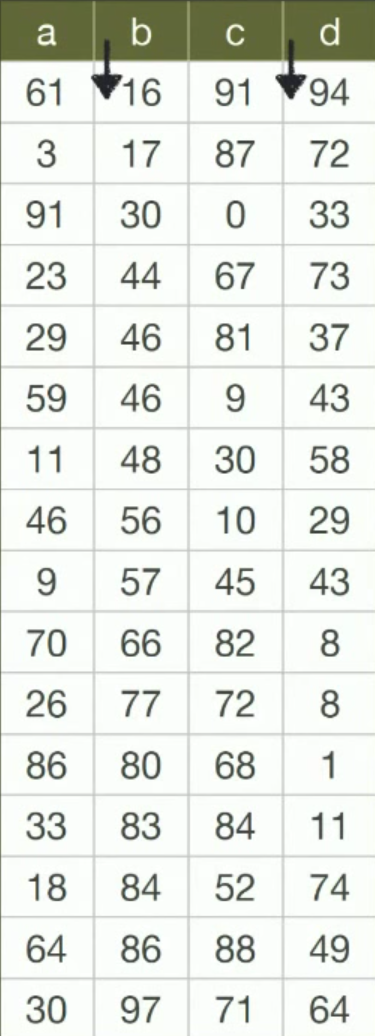
Trong trường hợp có nhiều trường được đánh index thì B- Tree chỉ thực sự hữu dụng khi search từ phía trái của index ví dụ
key( column b, column d)
Index được đánh như trên thì câu lệnh chỉ được tối ưu như sau:
select * from table where b=’16’ and d=’94’ #index sẽ được sử dụng
Indexing Goals
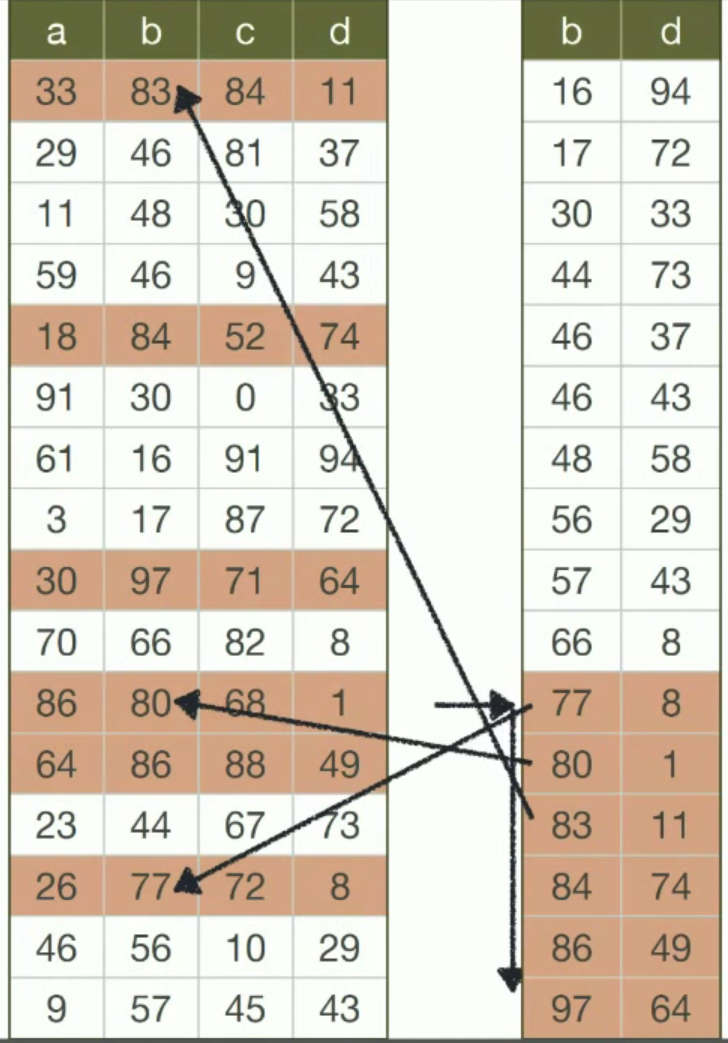
- Read less data Với câu lệnh select có thể thấy được với index có thể đọc được nhiều cột thảo mãn câu lệnh where hơn. Tránh phải duyệt toàn bộ dữ liệu trong bảng chỉ đơn giản thực hiện đọc giá trị từ giá trị index đầu tiên thỏa mãn.
SELECT c FROM table WHERE b >70
 2. Read in Bulk
2. Read in Bulk
Với mong muốn đọc dữ liệu một cách liên tục hơn là việc đọc dữ liệu một cách ngẫu nhiên, có nghĩa là việc đọc theo từng vùng đã được sắp xếp sẽ hiệu quả hơn đọc dữ liệu bị phân tán.
Để thực hiện được mong muốn trên có thể sử dụng clustered indexes để sắp xếp lại dữ liệu trong bảng. Ví dụ;
 3. Exploit Ordering
Vì các cột indexes đã được sắp xếp do đó MySQL sẽ tránh được rất nhiều công việc phức tạp khi ta sử dụng các câu lệnh ví dụ : GROUP BY, ORDER BY, DISTINCT. Ví du: với câu lệnh group by cột b MySQL se chỉ đơn giản thực hiện tìm giá trị tương ứng và kiểm tra các giá trị tiếp theo cho đến khi phát hiện có giá trị khác điều kiện.
Một số các câu lệnh khác : count, sum, average;
3. Exploit Ordering
Vì các cột indexes đã được sắp xếp do đó MySQL sẽ tránh được rất nhiều công việc phức tạp khi ta sử dụng các câu lệnh ví dụ : GROUP BY, ORDER BY, DISTINCT. Ví du: với câu lệnh group by cột b MySQL se chỉ đơn giản thực hiện tìm giá trị tương ứng và kiểm tra các giá trị tiếp theo cho đến khi phát hiện có giá trị khác điều kiện.
Một số các câu lệnh khác : count, sum, average;
5 Rules for getting the most from indexes
- Isolating the Column: có nghĩa là câu truy vấn sql sẽ không phải là một phần của biểu thức. Nếu câu truy vấn được nhúng vào một biểu thức hoặc một hàm tính toán bất kì sẽ khiến cho index không còn tác dụng:
Bad:
mysql> SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
Good:
mysql> SELECT actor_id FROM sakila.actor WHERE actor_id < 5 - somthing();
- Left prefix rule: nếu có nhiều cột được tạo index thì MySQL sẽ sắp xếp ưu tiên bắt đầu từ cột bên tay trái, trong trường hợp có các giá trị bằng nhau thì mới tiếp tục sắp xếp theo cột bên cạnh
- Covering index: là index chứa tất cả hoặc nhiều nhất các cột cần có trong câu truy vấn thực hiện.
- Clustered Index: khi tạo clustered index thì bản thân nó trở thành một cây index, với các node lá chứa khóa là các trường được index và cũng đồng thời chứa tất cả các trường còn lại của bảng. Vì các bản ghi chỉ có thể được sắp xếp trên cây index theo một thứ tự nhất định nên mỗi bảng chỉ có thể có tối đa một clustered index
- Don't over index: tạo index cho một cột đồng nghĩa với việc thêm chi phí tính toán lưu trữ cho các câu lệnh, do đó cần hạn chế câc indexes dư thừa hoặc bị trùng lặp, loại bỏ các index không dùng.
Reference
- How index works in mysql
- High.Performance.MySQL.3rd.Edition
All rights reserved
