[Open Source] #56 - Katana: Framework Spidering & Crawling thế hệ mới với Engine kép và khả năng bóc tách JS chuyên sâu
Việc khám phá toàn bộ bề mặt tấn công của một ứng dụng web hiện đại (Single Page Apps, ứng dụng giàu JavaScript) là thử thách lớn đối với các công cụ spidering truyền thống. Các công cụ cũ thường bỏ lỡ các endpoint ẩn trong code JS hoặc không thể tương tác với các form phức tạp. Katana từ ProjectDiscovery xuất hiện như một "thanh kiếm" sắc bén, kết hợp giữa tốc độ của HTTP thuần và khả năng render mạnh mẽ của trình duyệt Headless.
Dưới góc độ kỹ thuật, Katana là một ví dụ điển hình về việc tối ưu hóa hiệu suất quét quy mô lớn (mass scanning) bằng Golang, đồng thời cung cấp khả năng tùy biến sâu vào từng khâu của quá trình crawl.
Github: https://github.com/projectdiscovery/katana
🛠️ 1. Nền tảng công nghệ: Hệ sinh thái PD và Engine kép
Katana không chỉ đứng một mình; nó tận dụng những tinh hoa từ hệ sinh thái mã nguồn mở của ProjectDiscovery để đạt tới hiệu năng cực hạn:
- Engine lai (Hybrid Engine):
- Standard Mode: Sử dụng thư viện HTTP của Go, cực nhanh và tốn ít tài nguyên, phù hợp cho việc thu thập link tĩnh ở quy mô hàng triệu URL.
- Headless Mode (go-rod): Sử dụng trình duyệt Chromium thực để thực thi JavaScript, bắt các yêu cầu XHR/AJAX và tương tác với DOM.
- JS Parsing chuyên sâu (jsluice): Một kỹ thuật đặc biệt giúp Katana "đọc" mã nguồn JavaScript để trích xuất các đường dẫn ẩn mà không nhất thiết phải chạy code đó, giúp tăng tốc độ khám phá endpoint.
- Networking Stack: Sử dụng
fastdialerđể tùy biến quá trình phân giải DNS và bắt tay TLS, giúp giảm đáng kể độ trễ khi kết nối tới hàng nghìn mục tiêu khác nhau.
🏗️ 2. Trụ cột kiến trúc: Thiết kế cho Pipeline và Kiểm soát Scope
Katana được thiết kế với tư duy "Unix Philosophy": làm tốt một việc duy nhất và dễ dàng kết nối với các công cụ khác.
- Pipeline-ready: Hỗ trợ nhận đầu vào từ
STDINvà xuất raJSONL. Điều này cho phép xây dựng chuỗi công cụ mạnh mẽ:subfinder (tìm domain) | httpx (kiểm tra sống) | katana (quét link) | nuclei (tìm lỗ hổng). - Scope-First Logic: Một trong những lỗi lớn nhất khi crawl là rơi vào "vòng lặp vô tận" hoặc crawl nhầm sang trang khác. Katana cung cấp bộ lọc Scope cực kỳ chặt chẽ dựa trên FQDN, RDN (Root Domain Name) và Regex.
- Module hóa Engine: Phần xử lý logic quét được tách biệt hoàn toàn với phần quản lý vòng đời ứng dụng (Runner), cho phép cộng đồng dễ dàng đóng góp các module parser mới.
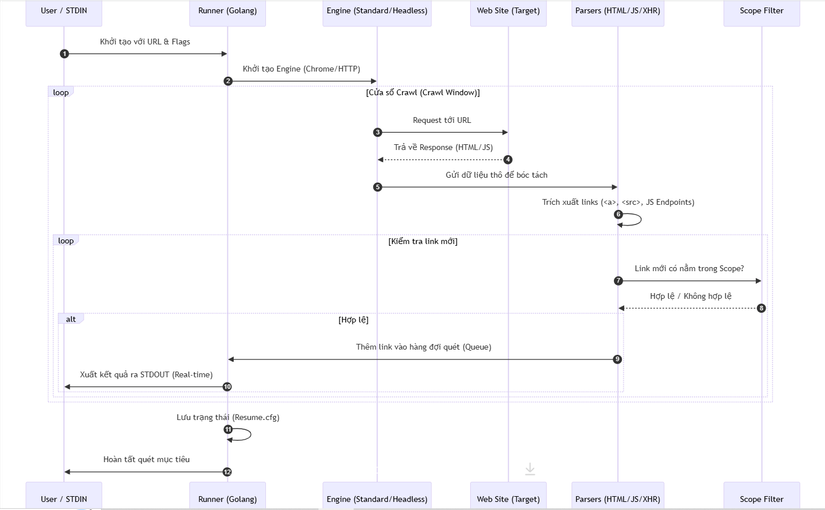
🔄 3. Workflow: Quy trình Spidering chuyên sâu (Sequence Diagram)
Sơ đồ dưới đây mô tả cách Katana điều phối giữa việc gửi request và trích xuất dữ liệu để khám phá toàn bộ website:
⚡ 4. Các kỹ thuật "Pro-level" trong mã nguồn
- SizedWaitGroup & Rate Limiting:
Để xử lý hàng nghìn URL cùng lúc mà không làm sập server đích hoặc máy của người dùng, Katana sử dụng
SizedWaitGroupđể giới hạn số luồng (parallelism) và thuật toánratelimitđể điều tiết tần suất gửi request. - Automatic Form Filling:
Katana có khả năng tự động điền dữ liệu vào các thẻ
<form>dựa trên một file cấu hình YAML. Điều này giúp công cụ có thể "vượt qua" các trang login đơn giản hoặc trang search để tìm thấy các trang nội dung bên trong. - XHR & AJAX Extraction: Trong chế độ Headless, Katana không chỉ lấy link từ HTML mà còn "lắng nghe" các request ngầm (Network Events) mà trình duyệt thực hiện, đảm bảo không bỏ sót bất kỳ API endpoint nào.
- SSRF Protection (Network Policy): Vì Katana quét link tự động, nó tích hợp chính sách mạng để từ chối kết nối tới các dải IP nội bộ (localhost, 192.168.x.x) trừ khi được phép, nhằm bảo vệ người dùng khỏi các kịch bản SSRF vô tình.
⚖️ 5. So sánh chiến lược
| Tiêu chí | Katana (ProjectDiscovery) | Gospider / Hakrawler | Burp Suite Spider |
|---|---|---|---|
| Engine | Standard & Headless (Hybrid) | Thường chỉ Standard | Headless mạnh mẽ |
| Khả năng bóc tách JS | Rất mạnh (jsluice) | Cơ bản | Khá tốt |
| Giao diện | CLI (Pipeline-first) | CLI | GUI (Khó automation) |
| Tính sẵn sàng | Tích hợp sâu vào CI/CD | Đơn lẻ | Tích hợp vào Suite |
✅ Kết luận: Tại sao Katana là hình mẫu lý tưởng?
Katana không chỉ là một công cụ crawl; nó là một bài học về Tối ưu hóa tài nguyên. Dự án chứng minh rằng việc kết hợp đúng đắn giữa "sức mạnh thô" (Go HTTP) và "trí tuệ" (Headless Browser) có thể giải quyết được những bài toán phức tạp nhất của Web Discovery.
Đối với các kỹ sư bảo mật và DevOps, nghiên cứu Katana sẽ giúp hiểu sâu về:
- Cách xây dựng một Worker pool hiệu quả trong Go.
- Kỹ thuật Headless Browser automation không gây ngốn RAM.
- Tư duy thiết kế công cụ để tương thích với các hệ thống tự động hóa (Automation-first).
Hy vọng bản phân tích này mang lại cho bạn những góc nhìn giá trị về kiến trúc công cụ spidering hiện đại. Đừng quên Upvote và Follow mình để đón chờ những "kỳ quan" mã nguồn tiếp theo nhé!
All rights reserved
