[Open Source] #34 - Firecrawl: Đỉnh cao kiến trúc Web Scraping cho kỷ nguyên LLM và sự kết hợp hiệu năng giữa Node.js, Rust & Go
Trong kỷ nguyên AI, dữ liệu chính là "dầu mỏ". Tuy nhiên, việc thu thập dữ liệu từ thế giới web đầy rẫy rào cản (chống bot, SPA, cấu trúc hỗn loạn) để đưa vào các mô hình ngôn ngữ lớn (LLM) là một bài toán cực khó. Firecrawl xuất hiện không chỉ như một công cụ cào dữ liệu thông thường, mà là một Data Pipeline hiện đại, biến toàn bộ website thành dữ liệu Markdown hoặc JSON "sạch" sẵn sàng cho AI.
Dưới góc độ kỹ thuật, Firecrawl là một minh chứng tuyệt vời cho kiến trúc Polyglot (đa ngôn ngữ), nơi mà sức mạnh điều phối của Node.js kết hợp hoàn hảo với hiệu năng xử lý chuỗi cực hạn của Rust và Go.
Github: https://github.com/mendableai/firecrawl
🛠️ 1. Nền tảng công nghệ: Kỹ thuật Native Bridge đỉnh cao
Firecrawl không chọn giải pháp "thuần" một ngôn ngữ, mà tối ưu hóa từng thành phần dựa trên đặc thù tác vụ:
- Orchestrator (Node.js/TypeScript): Đóng vai trò bộ não điều phối API, quản lý hàng đợi BullMQ/Redis và xác thực người dùng. Node.js vượt trội trong việc xử lý các tác vụ I/O bất đồng bộ và hệ sinh thái thư viện web đồ sộ.
- The Muscle (Rust via napi-rs): Đây là điểm sáng kỹ thuật. Các logic nặng nề nhất như duyệt Sitemap, lọc link, dọn dẹp HTML và chuyển đổi file Office (Docx/Xlsx) được viết bằng Rust. Thông qua
napi-rs, Node.js gọi trực tiếp các module native này với tốc độ gần như không có độ trễ. - String Processing (Go): Firecrawl tích hợp các thư viện xử lý HTML-to-Markdown viết bằng Go (thông qua Shared Libraries
.so), tận dụng khả năng xử lý văn bản và quản lý bộ nhớ ưu việt của Go để đảm bảo đầu ra chuẩn xác nhất cho LLM. - Browser Automation: Sử dụng Playwright để đối phó với các trang web Single Page Application (SPA) nặng JavaScript mà các bộ cào truyền thống "bó tay".
🏗️ 2. Trụ cột kiến trúc: Distributed Worker & Job-based Processing
Hệ thống được thiết kế theo mô hình Distributed Worker Architecture, cho phép mở rộng không giới hạn:
Chiến lược xử lý bất đồng bộ (Async Strategy)
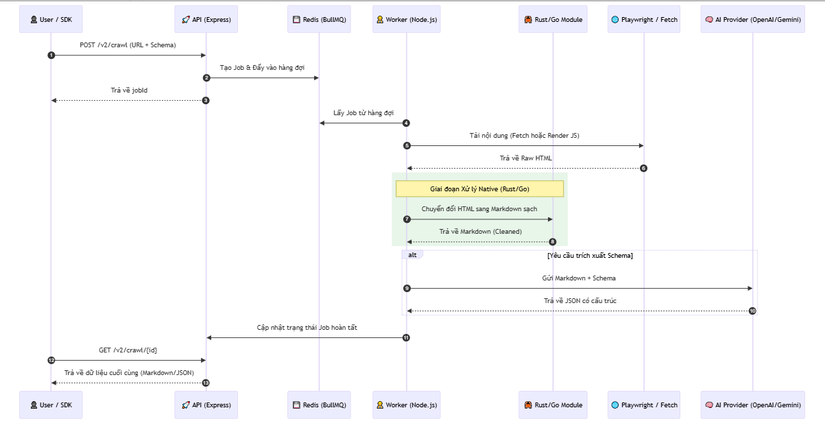
Mọi yêu cầu cào dữ liệu quy mô lớn (Crawl) đều được xử lý qua cơ chế Job-based. API nhận yêu cầu -> Đẩy vào Redis -> Trả về jobId. Các Worker độc lập sẽ lấy Job ra xử lý. Điều này giúp hệ thống không bị quá tải và cho phép người dùng theo dõi tiến độ thời gian thực (Polling).
Decoupled Scraper Engine
Kiến trúc tách biệt giữa logic nghiệp vụ và "Engine" thực thi. Tùy vào độ phức tạp của trang web, hệ thống tự động quyết định sử dụng fetch (nhanh, tiết kiệm tài nguyên) hoặc playwright (render đầy đủ JS, vượt cơ chế chống bot) để tối ưu hóa chi phí và tốc độ.
🔄 3. Các kỹ thuật "Pro-level" xử lý dữ liệu cho AI
1. LLM-First Transformation
Thay vì trả về HTML thô đầy rác (ads, footer, scripts), Firecrawl sử dụng các bộ lọc thông minh để trích xuất nội dung cốt lõi và chuyển đổi sang Markdown. Đây là định dạng tối ưu nhất cho các mô hình AI vì nó giữ được cấu trúc phân cấp (header, table, link) mà lại cực kỳ tiết kiệm Token.
2. AI-Powered Extraction (Structured Data)
Firecrawl tích hợp trực tiếp với các LLM (OpenAI, Anthropic) để thực hiện Schema-based Extraction. Người dùng chỉ cần định nghĩa một Schema (ví dụ: thông tin sản phẩm, giá cả), Firecrawl sẽ tự động "hiểu" nội dung trang web và trả về JSON chuẩn xác, ngay cả khi trang web đó không có cấu trúc rõ ràng.
3. Anti-Bot & Stealth Mode
Tích hợp cơ chế xoay vòng Proxy, giả lập Browser Headers và kỹ thuật "Stealth mode" của Playwright. Hệ thống có khả năng vượt qua các lớp bảo vệ cơ bản, giả lập hành vi cuộn trang (scroll) và chờ đợi (wait) như một người dùng thật.
📊 4. Workflow: Luồng xử lý dữ liệu từ URL đến JSON/Markdown
Dưới đây là sơ đồ trình tự mô tả cách Firecrawl xử lý một yêu cầu cào dữ liệu phức tạp:
⚖️ 5. So sánh chiến lược
| Tiêu chí | Firecrawl | Scrapy / Puppeteer thuần |
|---|---|---|
| Đầu ra cho AI | Markdown / JSON Schema (Mặc định) | HTML thô (Cần tự xử lý) |
| Hiệu năng | Cực cao (Kết hợp Rust/Go) | Phụ thuộc vào Python/JS thuần |
| Xử lý tài liệu | Hỗ trợ PDF, Docx, Xlsx sang Text | Thường chỉ xử lý HTML |
| Kiến trúc | Worker phân tán (Scale dễ dàng) | Thường chạy đơn nhiệm hoặc cần tự dựng queue |
| Sẵn sàng cho LLM | Tích hợp sẵn AI Extraction | Phải code thêm pipeline phức tạp |
✅ Kết luận: Tại sao Firecrawl là hình mẫu?
Firecrawl không chỉ đơn giản là một bộ cào (Scraper), nó là một bài học về hệ thống phân tán và tối ưu hóa hiệu năng lai. Việc sử dụng Node.js để quản lý luồng công việc phức tạp và đẩy các tác vụ nặng xuống tầng Rust/Go giúp Firecrawl đạt được sự cân bằng hoàn hảo giữa tính linh hoạt và tốc độ. Đối với các kỹ sư AI và Data Engineer, đây chính là "mảnh ghép" còn thiếu để xây dựng các ứng dụng RAG (Retrieval-Augmented Generation) chất lượng cao.
Hy vọng bản phân tích chuyên sâu này mang lại giá trị thực tế cho bạn trên con đường làm chủ dữ liệu web. Đừng quên Upvote và Follow mình để đón xem những dự án kỹ thuật đỉnh cao tiếp theo!
All rights reserved
