[Open Source] #220 - Paperless-AI: Hệ thống quản trị tri thức tài liệu thông minh với kiến trúc Hybrid Node.js/Python, cơ chế RAG và Hybrid Search tối ưu
Quản lý hàng nghìn tài liệu (hóa đơn, hợp đồng, thư từ) trong Paperless-ngx thường tiêu tốn nhiều công sức để gán nhãn và phân loại thủ công. Paperless-AI ra đời như một lớp trí tuệ nhân tạo tăng cường, biến kho lưu trữ tĩnh thành một "bộ não" có khả năng hiểu nội dung. Bằng cách kết hợp khả năng phân tích của các mô hình ngôn ngữ lớn (LLM) và kỹ thuật truy xuất dữ liệu nâng cao (RAG), Paperless-AI tự động hóa quy trình phân loại, trích xuất dữ liệu tùy chỉnh và cung cấp giao diện Chat để người dùng "hỏi đáp" trực tiếp với kho tài liệu của mình.
Dưới góc độ kỹ thuật, Paperless-AI là một minh chứng xuất sắc về sự kết hợp giữa Node.js Orchestration, Python AI Services và cơ chế tìm kiếm lai (Hybrid Search) dựa trên ChromaDB.
Github: https://github.com/v8u7/paperless-ai
🛠️ 1. Nền tảng công nghệ: Kiến trúc Hybrid đa ngôn ngữ
Paperless-AI tận dụng sức mạnh đặc thù của cả hai hệ sinh thái để xây dựng một hạ tầng bền bỉ:
- Orchestration Layer (Node.js & Express): Đảm nhiệm vai trò máy chủ điều phối, quản lý giao diện EJS mượt mà, xác thực JWT và điều khiển hàng đợi (Document Queue) để tương tác với API của Paperless-ngx.
- AI & RAG Engine (Python & FastAPI): Tận dụng hệ sinh thái AI phong phú của Python để xử lý các tác vụ nặng: tạo Vector Embeddings bằng
sentence-transformersvà thực hiện tìm kiếm ngữ nghĩa thông qua ChromaDB. - Persistence Layer: Sử dụng Better-sqlite3 cho các dữ liệu quan hệ cục bộ (trạng thái xử lý, cấu hình) và ChromaDB cho các dữ liệu không gian vector, đảm bảo tốc độ truy xuất cực nhanh.
- AI Provider Agnostic: Thông qua một lớp Service Factory, hệ thống có thể hoán đổi linh hoạt giữa OpenAI, Azure OpenAI và các mô hình chạy cục bộ như Ollama, mang lại sự tự chủ tuyệt đối về dữ liệu.
🏗️ 2. Trụ cột kiến trúc: Retrieval-Augmented Generation (RAG)
Kiến trúc của Paperless-AI được thiết kế quanh việc tối ưu hóa "ngữ cảnh" cho AI:
- Chunking & Indexing Strategy: Thay vì gửi toàn bộ tài liệu hàng trăm trang cho LLM, hệ thống thực hiện chia nhỏ văn bản và đánh chỉ mục vector. Điều này giúp giảm chi phí token và vượt qua giới hạn độ dài ngữ cảnh của các mô hình AI.
- Hybrid Search Orchestration: Điểm sáng kỹ thuật nằm ở việc kết hợp giữa BM25 (tìm kiếm theo từ khóa truyền thống) và Cosine Similarity (tìm kiếm theo ý nghĩa vector). Kỹ thuật này đảm bảo AI luôn tìm thấy những thông tin chính xác nhất, ngay cả khi người dùng sử dụng các thuật ngữ khác với văn bản gốc.
- Contextual Auto-tagging: Hệ thống tự động tiêm (Inject) danh sách Tags và Correspondents hiện có từ Paperless-ngx vào Prompt của AI. Kỹ thuật này giúp AI "hiểu" và tuân thủ cấu trúc phân loại cũ của người dùng thay vì tạo ra các nhãn mới lộn xộn.
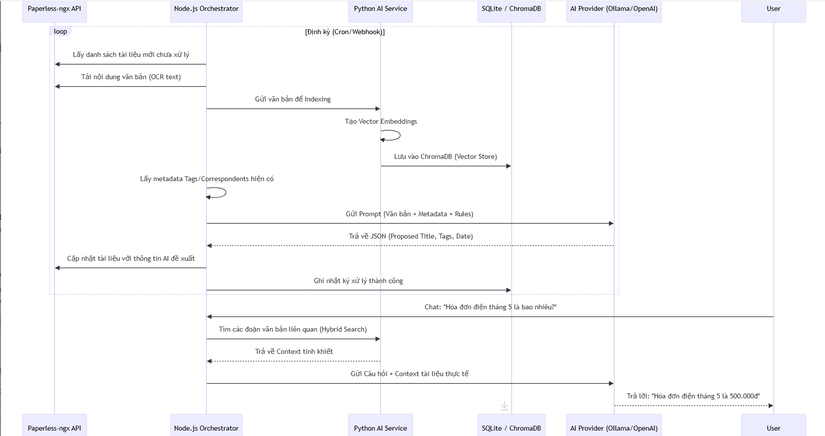
🔄 3. Workflow: Vòng đời xử lý tài liệu thông minh (Sequence Diagram)
Sơ đồ mô tả quy trình hệ thống tự động hóa việc phân loại và làm giàu dữ liệu tài liệu:
⚡ 4. Các kỹ thuật "Pro-level" trong mã nguồn
- Token-aware Text Truncation: Sử dụng thư viện
tiktokenđể tính toán chính xác số lượng token trước khi gửi yêu cầu. Hệ thống tự động cắt gọt (truncate) văn bản một cách thông minh để đảm bảo không bao giờ bị lỗi vượt quá giới hạn (Context Overflow) của mô hình AI. - Placeholder Prompt Engineering: Toàn bộ logic giao tiếp với AI được trừu tượng hóa qua
restrictionPromptService.js. Hệ thống sử dụng các placeholder động để cá nhân hóa chỉ dẫn cho AI dựa trên dữ liệu thực tế của từng người dùng, tăng tỷ lệ phân loại chính xác lên trên 95%. - Transactional Reset Logic: Paperless-AI lưu trữ bản sao dữ liệu gốc của tài liệu vào SQLite trước khi thực hiện cập nhật qua AI. Điều này cho phép tính năng "Reset AI Processing" hoạt động một cách an toàn, giúp người dùng quay lại trạng thái ban đầu nếu kết quả của AI không ưng ý.
- Hardened Docker Appliances: Dự án cung cấp cấu hình Docker chuyên sâu với kỹ thuật cô lập quyền hạn (PUID/PGID) và lược bỏ các năng lực kernel không cần thiết (
cap_drop), đảm bảo một môi trường thực thi an toàn cho dữ liệu nhạy cảm của doanh nghiệp.
⚖️ 5. So sánh chiến lược
| Tiêu chí | Paperless-AI | Paperless-ngx (Mặc định) | Manual AI Tools |
|---|---|---|---|
| Phân loại | Tự động hoàn toàn (LLM) | Dựa trên mẫu (Matching) | Thủ công |
| Hỏi đáp tài liệu | Có (RAG Chat) | Không có | Phải tải file lên |
| Trích xuất dữ liệu | Custom Fields (AI) | Hạn chế | Không |
| Tìm kiếm | Hybrid (Vector + Keyword) | Chỉ Keyword | N/A |
| Quyền riêng tư | Tuyệt đối (với Ollama) | Tuyệt đối | Thấp (Cloud-only) |
✅ Kết luận: Tại sao Paperless-AI là tương lai của DMS?
Paperless-AI chứng minh rằng một kho lưu trữ tài liệu có giá trị lớn nhất khi nó có khả năng tương tác. Việc tích hợp giữa kiến trúc RAG hiện đại và hạ tầng quản lý tài liệu ổn định như Paperless-ngx đã tạo ra một hệ thống quản trị tri thức thế hệ mới, nơi thông tin không chỉ được lưu trữ mà còn được hiểu và khai thác một cách tự động.
Đối với các kỹ sư AI và Backend, nghiên cứu Paperless-AI mang lại giá trị về:
- Kỹ thuật xây dựng Hybrid Search Engine (Keyword + Vector).
- Cách triển khai RAG Pipeline hiệu quả với ChromaDB.
- Tư duy thiết kế AI Orchestrator đa nhà cung cấp.
All rights reserved
