# [Open source] #19 Omnivore: Kiến trúc Content Ingestion Pipeline và giải pháp đọc Offline-first hiện đại
Trong kỷ nguyên quá tải thông tin, việc quản lý nội dung để "đọc sau" (Read-it-later) trở thành nhu cầu thiết yếu. Omnivore nổi lên như một nền tảng mã nguồn mở mạnh mẽ nhất hiện nay, cho phép lập trình viên không chỉ sở hữu dữ liệu của mình qua việc tự vận hành (Self-hosted) mà còn cung cấp một bộ API GraphQL và hệ thống đồng bộ hóa (Syncing) vô cùng tinh tế giữa Web, Mobile và Browser Extension.
🛠️ 1. Hệ sinh thái công nghệ: Monorepo và Đa ngôn ngữ
Github: https://github.com/omnivore-app/omnivore
Omnivore không chỉ là một ứng dụng; nó là một hạ tầng phân tán được quản lý dưới dạng Monorepo (sử dụng Lerna):
- Backend Orchestrator: Chạy trên Node.js với Apollo GraphQL Server. Đây là trung tâm điều phối mọi giao tiếp giữa các client và dịch vụ worker.
- Content Processing Engine: Sử dụng Puppeteer (để render các trang web SPA phức tạp) kết hợp với Mozilla Readability để trích xuất nội dung sạch (loại bỏ "rác" giao diện).
- Database Hybrid:
- PostgreSQL: Lưu trữ dữ liệu quan hệ. Đặc biệt tích hợp
pgvectorđể hỗ trợ tìm kiếm ngữ nghĩa (Semantic Search) bằng AI. - Redis (BullMQ): Hệ thống hàng đợi (Queue) cực kỳ quan trọng để xử lý các tác vụ nặng như tải PDF, trích xuất ảnh thumbnail.
- PostgreSQL: Lưu trữ dữ liệu quan hệ. Đặc biệt tích hợp
- Cross-platform Clients:
- Web: Next.js với Radix UI.
- Android: Native Kotlin với Jetpack Compose.
- iOS: SwiftUI nguyên bản.
🏗️ 2. Trụ cột kiến trúc: Queue-driven và Offline-first
Kiến trúc của Omnivore được thiết kế để giải quyết bài toán: Làm sao để trích xuất nội dung từ bất kỳ nguồn nào một cách trung thực nhất?
Content Ingestion Pipeline (Luồng nạp nội dung)
Thay vì xử lý trực tiếp trên API server (dễ gây treo server khi gặp trang web nặng), Omnivore đẩy mọi yêu cầu vào một hệ thống Worker-based:
- API server nhận URL -> Đẩy vào Redis Queue.
- Worker nhặt task -> Khởi động Chromium (Puppeteer) để nạp trang -> Trích xuất HTML sạch.
- Metadata (ảnh, tác giả, tag) được phân tích và lưu trữ vào Postgres.
Kiến trúc Mobile Offline-first
Omnivore Mobile áp dụng triệt để Clean Architecture:
- Single Source of Truth: Ứng dụng luôn hiển thị dữ liệu từ Local DB (Room trên Android, SQLite trên iOS).
- Sync Status Logic: Mỗi bản ghi có trạng thái đồng bộ (
NEEDS_SYNC,SYNCING,IS_SYNCED). Một tiến trình chạy ngầm sẽ tự động đẩy các thay đổi (như highlight, note) lên Server qua GraphQL Mutation khi có mạng.
🔄 3. Phân tích chuyên sâu Luồng hoạt động (Data Lifecycle)
Sơ đồ dưới đây mô tả quá trình từ lúc người dùng nhấn nút "Save" trên extension cho đến khi bài viết xuất hiện sẵn sàng để đọc offline trên điện thoại:
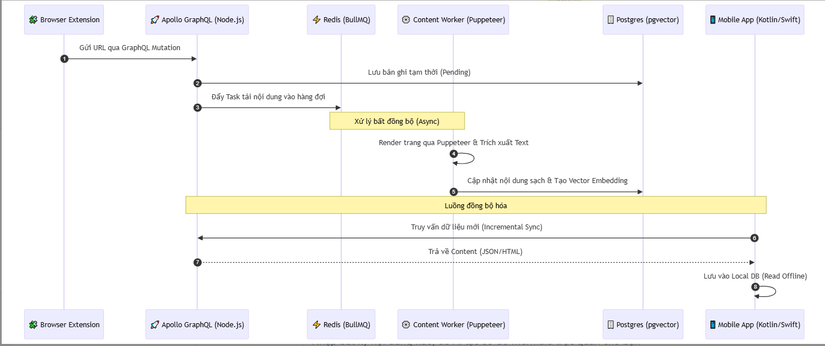
Giải mã các kỹ thuật "Pro-level" trong mã nguồn:
- Semantic Search với
pgvector: Thay vì tìm kiếm từ khóa khô khan, Omnivore cho phép bạn tìm kiếm theo ý nghĩa (ví dụ: "công nghệ xanh" sẽ ra các bài về năng lượng mặt trời dù bài đó không chứa từ "xanh"). Điều này đạt được bằng cách convert bài viết sang vector và so sánh khoảng cách trong Postgres. - Custom Content Handlers: Omnivore xây dựng các parser chuyên biệt cho từng loại nguồn khó nhằn như Substack (email newsletter), Twitter (threads), và YouTube (trích xuất mô tả).
- Conflict Resolution (Xử lý xung đột): Khi bạn highlight một câu trên web và một câu khác trên mobile cùng lúc, Omnivore sử dụng kỹ thuật Merge Highlights dựa trên timestamp và vị trí index của văn bản để đảm bảo không mất dữ liệu.
⚖️ 4. So sánh chiến lược
| Tiêu chí | Omnivore | Pocket / Instapaper | Wallabag |
|---|---|---|---|
| Quyền riêng tư | Tuyệt đối (Self-host) | Nằm trên cloud của họ | Tuyệt đối |
| Tìm kiếm AI | Có (Semantic Search) | Không | Không |
| Kiến trúc | Hiện đại (GraphQL/Node) | Đóng | Cũ (PHP/Symfony) |
| Trải nghiệm đọc | Cực tốt (Clean view) | Tốt | Trung bình |
| Tích hợp | Obsidian, Logseq, Readwise | Hạn chế | Trung bình |
✅ Kết luận: Tại sao nên chọn Omnivore?
Omnivore là minh chứng cho việc một ứng dụng "Personal Productivity" có thể đạt đến trình độ kỹ thuật của một hệ thống Enterprise. Sự kết hợp giữa Puppeteer để nạp dữ liệu, GraphQL để đồng bộ, và Native Mobile Apps để trải nghiệm mượt mà khiến nó trở thành tiêu chuẩn vàng cho các giải pháp lưu trữ kiến thức cá nhân (PKM).
Tag gợi ý cho bài viết trên Viblo:
Open SourceTypeScriptGraphQLMobile DevelopmentArchitectureArtificial Intelligence
Hy vọng bản phân tích chuyên sâu này mang lại giá trị thực tế cho bạn. Đừng quên Upvote và Follow mình để đón xem những dự án kỹ thuật thú vị tiếp theo!
All rights reserved
