[Open Source] #102 - Crawlee: Thư viện Web Scraping "vạn năng" với kiến trúc Autoscaled, Anti-Fingerprinting và cơ chế quản lý Session tối tân
Việc xây dựng một hệ thống cào dữ liệu (Web Scraping) quy mô lớn không chỉ đơn thuần là gửi request và lấy HTML. Những rào cản từ hệ thống chống Bot (Cloudflare, Akamai), việc rò rỉ bộ nhớ khi chạy trình duyệt, và quản lý hàng đợi dữ liệu thường khiến các dự án thất bại. Crawlee (tiền thân là Apify SDK) xuất hiện như một khung làm việc (framework) hoàn chỉnh, giúp chuyển đổi các script scraping thô sơ thành những hệ thống tự động hóa có độ tin cậy cực cao.
Dưới góc độ kỹ thuật, Crawlee là một kiệt tác về Node.js Automation, sử dụng mô hình kế thừa đa tầng và cơ chế quản lý tài nguyên dựa trên hiệu năng thực tế của phần cứng.
Github: https://github.com/apify/crawlee
🛠️ 1. Nền tảng công nghệ: Monorepo và Network Stack tùy chỉnh
Crawlee không cố gắng "tái định nghĩa bánh xe" mà thay vào đó, nó đóng gói và tối ưu hóa các công cụ tốt nhất trong hệ sinh thái Node.js:
- TypeScript-First: Hệ thống sử dụng triệt để Generics, cho phép định nghĩa kiểu dữ liệu cho kết quả scraping từ tầng Request đến khi lưu trữ vào Dataset.
- Got-scraping: Thay vì dùng thư viện HTTP chuẩn, Crawlee sử dụng một bản build tùy chỉnh của
got. Điểm đặc biệt là khả năng giả lập TLS/SSL Fingerprint, giúp các yêu cầu HTTP thô trông giống hệt như đến từ một trình duyệt Chrome thực thụ. - Browser Agnostic: Hỗ trợ song song cả Playwright và Puppeteer, cho phép lập trình viên chuyển đổi giữa các trình duyệt (Chromium, Firefox, WebKit) chỉ bằng cách đổi tên class.
- Biome & Turborepo: Đảm bảo hiệu năng build và linting trong cấu trúc Monorepo khổng lồ, nơi mỗi package (Cheerio, Playwright, Browser Pool) được quản lý độc lập.
🏗️ 2. Trụ cột kiến trúc: Sự bền bỉ và Tính trừu tượng
Kiến trúc của Crawlee xoay quanh tư duy "Resilient by Default" (Mặc định là bền bỉ):
- Kiến trúc Đa tầng (Inheritance Chain):
BasicCrawler: Xử lý logic lõi (vòng lặp, lỗi, hàng đợi).CheerioCrawler: Thêm lớp phân tích cú pháp HTML tĩnh (siêu nhanh).BrowserCrawler: Tích hợp trình duyệt không đầu (Headless Browsers) để xử lý các trang SPA (React/Angular).
- Disk-backed RequestQueue: Hàng đợi không nằm hoàn toàn trên RAM. Nếu hệ thống crash, Crawlee sẽ tự động khôi phục lại từ trạng thái cuối cùng được lưu trên ổ đĩa, đảm bảo không bỏ lỡ hoặc lặp lại URL một cách vô ích.
- AutoscaledPool: Đây là tính năng "đáng đồng tiền bát gạo" nhất. Crawlee liên tục theo dõi chỉ số CPU và RAM của hệ thống để tự động điều chỉnh số lượng luồng (concurrency), giúp khai thác tối đa sức mạnh phần cứng mà không làm treo server.
🔄 3. Workflow: Vòng đời của một Crawler (Sequence Diagram)
Sơ đồ dưới đây mô tả cách Crawlee điều phối giữa tài nguyên hệ thống, proxy và xử lý dữ liệu:
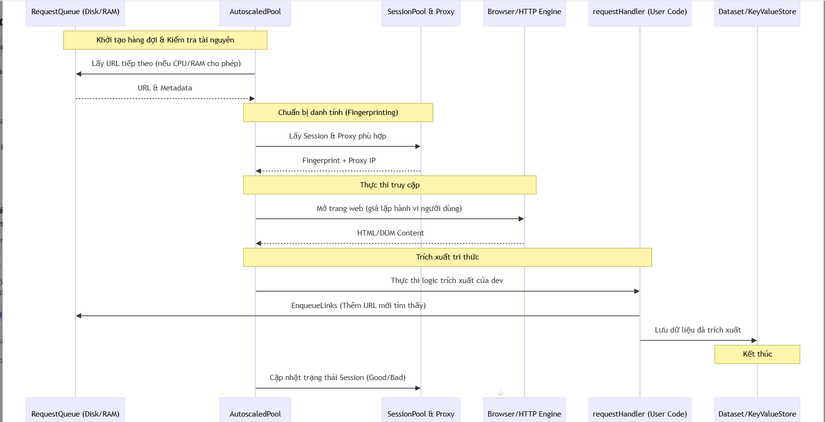
⚡ 4. Các kỹ thuật "Pro-level" trong mã nguồn
- Anti-Fingerprinting & Stealth: Crawlee tự động tạo ra các thông số phần cứng ảo (độ phân giải màn hình, danh sách font, card đồ họa) để vượt qua các thuật toán phát hiện Bot dựa trên dấu vân tay trình duyệt.
- Session Health Management: Hệ thống quản lý Cookie và IP Proxy một cách thông minh. Nếu một Session bị website chặn (403/429), Crawlee sẽ đánh dấu "tệ", loại bỏ Proxy đó và tự động thử lại yêu cầu bằng một danh tính mới.
- Browser Pool: Thay vì mở một trình duyệt mới cho mỗi trang web (gây tốn RAM), Crawlee tái sử dụng các instance trình duyệt nhưng vẫn đảm bảo sự cô lập về context dữ liệu giữa các request.
- Adaptive Retry Logic: Cơ chế thử lại không chỉ dựa trên số lần, mà còn dựa trên loại lỗi (Network error vs. Captcha error) để đưa ra chiến lược xử lý phù hợp.
⚖️ 5. So sánh chiến lược
| Tiêu chí | Crawlee | Raw Playwright/Puppeteer | Axios + Cheerio |
|---|---|---|---|
| Quản lý tài nguyên | Tự động (Autoscaled) | Thủ công (Dễ tràn RAM) | Thủ công |
| Chống chặn (Anti-bot) | Rất cao (Stealth + Fingerprint) | Trung bình | Rất thấp |
| Khả năng phục hồi | Có (RequestQueue trên ổ đĩa) | Không | Không |
| Tốc độ phát triển | Nhanh (Sẵn nhiều utility) | Trung bình | Nhanh (nhưng dễ lỗi) |
✅ Kết luận: Tại sao Crawlee là tiêu chuẩn mới?
Crawlee đã nâng tầm việc scraping từ một tác vụ "chạy rồi cầu nguyện" lên một quy trình kỹ thuật chuẩn chỉnh. Dự án chứng minh rằng trong thế giới Web hiện đại, sự thành bại không nằm ở việc bạn lấy dữ liệu nhanh thế nào, mà là bạn duy trì việc lấy dữ liệu bền bỉ ra sao trước các rào cản kỹ thuật ngày càng phức tạp.
Đối với các kỹ sư dữ liệu, nghiên cứu Crawlee sẽ giúp bạn hiểu sâu về:
- Kỹ thuật quản lý tài nguyên hệ thống thực tế trong Node.js.
- Cơ chế giả lập trình duyệt và vượt rào cản bảo mật tầng cao.
- Tư duy thiết kế hệ thống tự phục hồi (Self-healing).
All rights reserved
