NoSQL là gì? Bước Ngoặt Của Dữ Liệu Lớn Và Ứng Dụng Trong Thực Tiễn
🌐 Nếu bạn quan tâm đến NoSQL và muốn tìm hiểu thêm, bạn có thể khám phá nhiều bài viết chi tiết tại blog của mình: Quan Notes
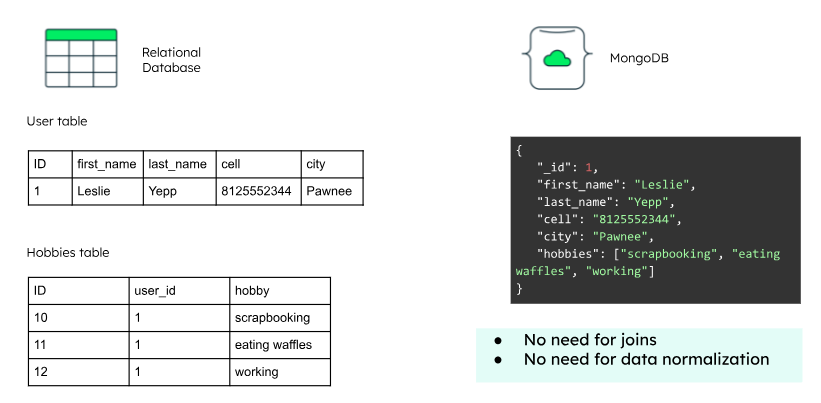
NoSQL là một loại thiết kế cơ sở dữ liệu lưu trữ và truy xuất dữ liệu khác với cấu trúc dựa trên bảng của cơ sở dữ liệu quan hệ truyền thống (Relational Database).
Không giống như cơ sở dữ liệu quan hệ, tổ chức dữ liệu thành hàng và cột như bảng tính, NoSQL sử dụng một cấu trúc dữ liệu duy nhất như cặp khóa - giá trị, cột rộng, đồ thị để lưu trữ thông tin.
NoSQL ra đời khi các nguyên tắc thiết kế cơ sở dữ liệu truyền thống không còn đủ để đáp ứng quy mô khổng lồ và tính linh hoạt mà ứng dụng Web 2.0 đòi hỏi.
Trong bài viết này, chúng ta sẽ tìm hiểu nguồn gốc hình thành NoSQL, khám phá các mô hình và đặc tính nổi bật, so sánh với cơ sở dữ liệu quan hệ.
I/ Lịch sử hình thành của NoSQL
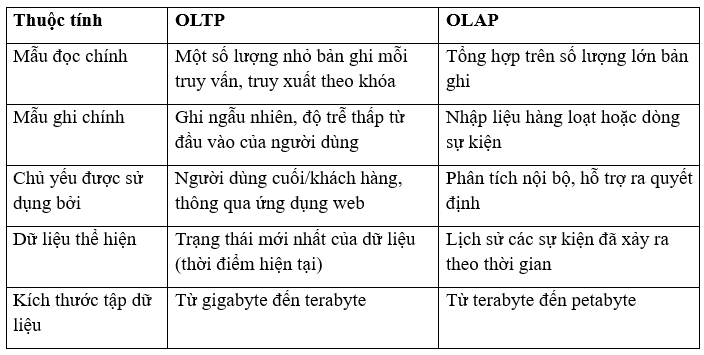
1/ OLTP và OLAP
Để hiểu sự ra đời và thuộc tính của NoSQL, trước hết cần phân biệt hai loại tải công việc chính mà cơ sở dữ liệu phải xử lý:
- OLTP (Online Transaction Processing): đặc trưng bởi số lượng lớn giao dịch từ nhiều người dùng, thường thấy ở các ứng dụng “frontend” như mạng xã hội hoặc cửa hàng trực tuyến. Truy vấn chủ yếu là tra cứu đơn giản (ví dụ: tìm người dùng theo ID, lấy giỏ hàng) và nhiều thao tác cập nhật (đăng tweet, thêm sản phẩm vào giỏ). Do tính chất quan trọng, mọi truy vấn, thêm và cập nhật đều được thực hiện như một giao dịch để đảm bảo tính nhất quán.
- OLAP (Online Analytical Processing): tập trung vào các truy vấn đọc dữ liệu quy mô lớn, thường đi kèm nhiều phép nối và tổng hợp để phục vụ phân tích, hỗ trợ quyết định (ví dụ: tổng doanh thu theo cửa hàng, khu vực, sản phẩm, thời gian).
Dữ liệu sẽ được chuyển từ hệ thống OLTP sang OLAP theo chu kỳ thông qua quy trình ETL (Extract – Transform – Load).
2/ NoSQL: Mở rộng cơ sở dữ liệu cho Web 2.0
Vào thời Web 2.0, khối lượng dữ liệu người dùng tạo ra (bài đăng, ảnh, video, like, vote,...) quá lớn, các cơ sở dữ liệu quan hệ khó mở rộng vì phải duy trì tính nhất quán mạnh, nhiều ràng buộc và chức năng phức tạp.
NoSQL xuất hiện bằng cách đơn giản hóa mô hình dữ liệu, giảm chức năng, nới lỏng đảm bảo nhất quán, từ đó xử lý khối lượng truy vấn và cập nhật dễ dàng hơn, phù hợp cho mở rộng ngang (scale-out) trên nhiều máy chủ.
Câu hỏi đặt ra là: Làm thế nào việc đơn giản hóa mô hình dữ liệu và giảm chức năng của cơ sở dữ liệu cho phép NoSQL mở rộng tốt hơn so với các cơ sở dữ liệu quan hệ truyền thống?
Chúng ta có thể minh họa câu trả lời cho những câu hỏi này thông qua lịch sử các kỹ thuật mở rộng cơ sở dữ liệu quan hệ.
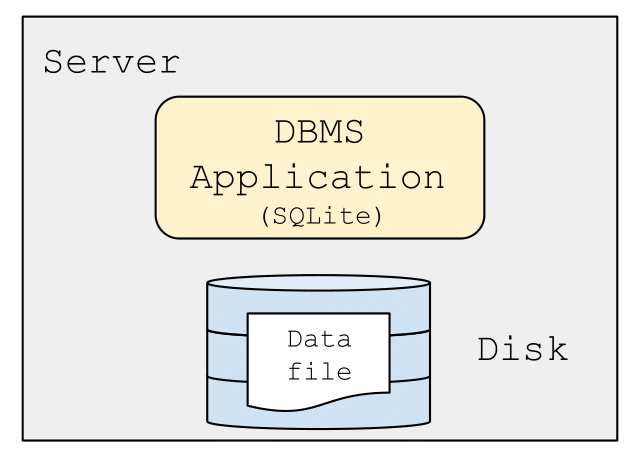
a/ Kiến trúc một tầng (One-tier architecture)
Trong kiến trúc một tầng, một máy chủ chứa cả cơ sở dữ liệu (tệp) và ứng dụng.
Việc chỉ có một máy chủ giúp dễ dàng mở rộng bằng cách nâng cấp phần cứng để tăng dung lượng lưu trữ hoặc tốc độ xử lý giao dịch.
- Ưu điểm: Kiến trúc này đảm bảo tính nhất quán dễ dàng cho khối lượng công việc OLTP, do chỉ có một ứng dụng truy cập một cơ sở dữ liệu (như SQLite), giảm nhu cầu kiểm soát đồng thời.
- Khuyết điểm: Kiến trúc này chỉ phù hợp cho ứng dụng đơn giản, một người dùng, không đáp ứng được khi nhiều ứng dụng hay người dùng cần truy cập đồng thời.
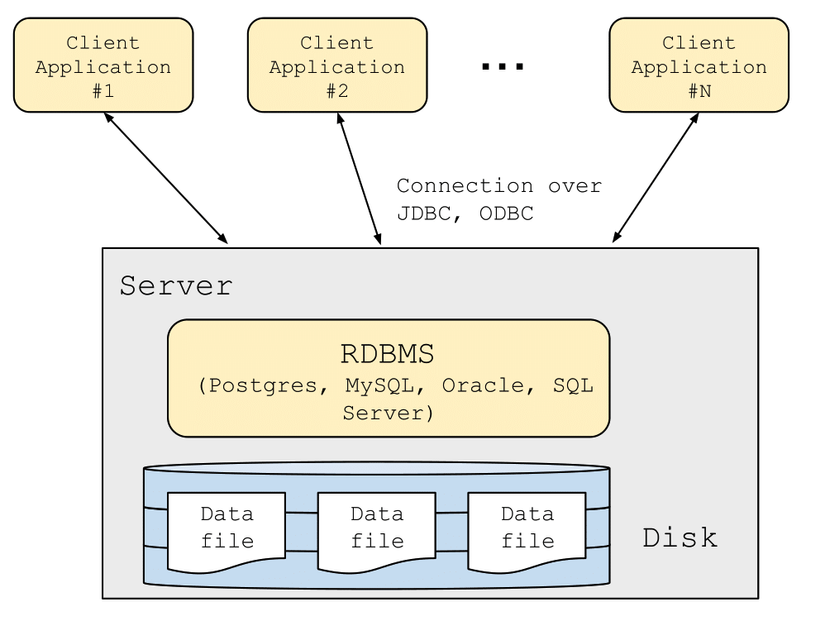
b/ Kiến trúc hai tầng (Two-tier architecture)
Trong kiến trúc hai tầng, cơ sở dữ liệu được lưu trữ trên một máy chủ mạnh hoặc dịch vụ đám mây, cho phép nhiều ứng dụng khách truy cập đồng thời thông qua các API như JDBC hoặc ODBC.
- Ưu điểm: Kiến trúc này cho phép nhiều ứng dụng cùng khai thác một cơ sở dữ liệu chung, đảm bảo dữ liệu tập trung và thống nhất. Các giao dịch (transactions) đảm bảo tính nhất quán, hỗ trợ thông lượng giao dịch lớn, giúp hệ thống xử lý nhiều yêu cầu cùng lúc.
- Hạn chế: Kiến trúc này vẫn chỉ có một máy chủ cơ sở dữ liệu và một máy chủ ứng dụng cho mỗi ứng dụng , khó đáp ứng khi tải tăng đột biến.
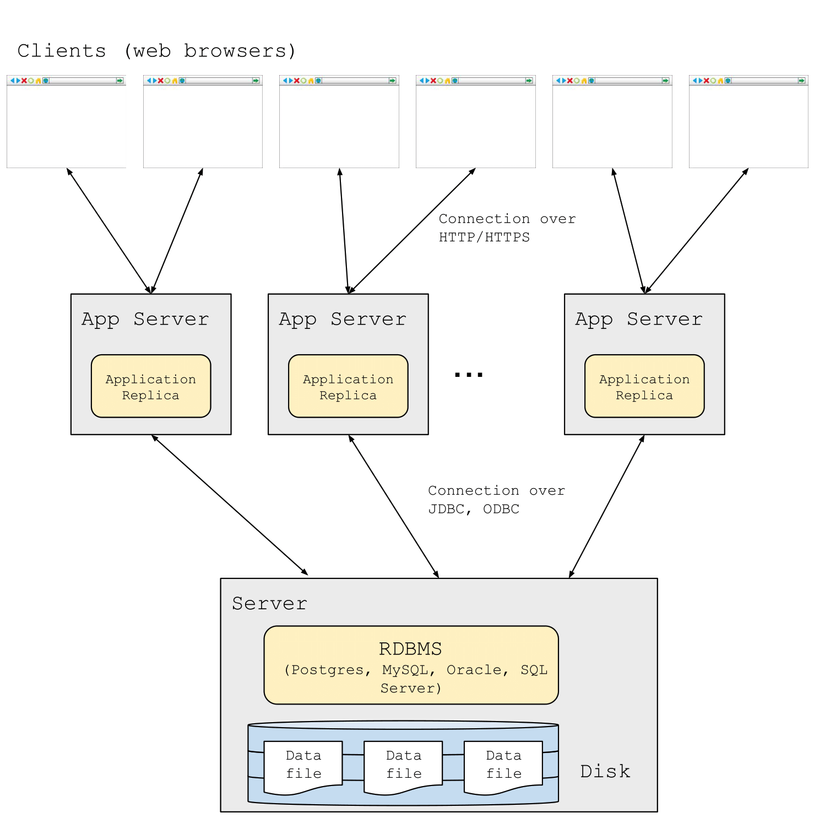
c/ Kiến trúc ba tầng (Three-tier architecture)
Trong kiến trúc ba tầng, máy chủ cơ sở dữ liệu riêng biệt với các máy chủ ứng dụng frontend, phục vụ lưu lượng người dùng trực tiếp. Frontend có thể được mở rộng bằng cách thêm nhiều máy chủ ứng dụng hơn.
- Ưu điểm: Việc tách biệt frontend và backend cho phép dễ dàng tăng số lượng máy chủ ứng dụng để đáp ứng lưu lượng lớn, đặc biệt phù hợp với các ứng dụng web hiện đại như mạng xã hội, thương mại điện tử hoặc nền tảng trực tuyến có hàng triệu người dùng đồng thời.
- Hạn chế: Cơ sở dữ liệu “backend” quản lý trạng thái chung thế nên có thể gây tải OLTP lớn, nhanh chóng vượt quá khả năng của một máy chủ cơ sở dữ liệu duy nhất.
Bây giờ chúng ta phải xem xét cách mở rộng cơ sở dữ liệu vượt ra ngoài một máy chủ duy nhất trong khi vẫn đảm bảo tính nhất quán cần thiết cho các khối lượng công việc OLTP.
II/ Phương pháp Mở rộng Cơ sở Dữ liệu
1/ Phân vùng (Partitioning)
Phân vùng là chia cơ sở dữ liệu thành các đoạn nhỏ hơn, được phân bố trên nhiều máy.
Phân vùng giúp cải thiện hiệu suất theo hai cách chính:
- Thực hiện truy vấn song song: Các truy vấn có thể được xử lý đồng thời trên nhiều máy nếu chúng truy cập các phần khác nhau của cơ sở dữ liệu.
- Tối ưu hóa bộ nhớ: Mỗi phân vùng có thể được thiết kế để vừa với bộ nhớ, giảm chi phí đọc/ghi đĩa (I/O).
Phân vùng đặc biệt hiệu quả với các tải công việc ghi nhiều, vì các thao tác như chèn hay cập nhật thường chỉ ảnh hưởng đến một máy duy nhất.
Tuy nhiên, với lưu lượng tải đọc nhiều, hiệu suất có thể giảm khi truy vấn cần dữ liệu từ nhiều máy.
2/ Sao chép (Replication)
Trong cả ba kiến trúc, cơ sở dữ liệu vẫn là điểm tắc ngẽn duy nhất: nếu nó ngừng, toàn bộ hệ thống dừng. Với sao chép, dữ liệu được lưu trên nhiều máy, giúp xử lý tốt tải đọc vì các truy vấn có thể chạy song song trên các bản sao.
Sao chép không chỉ phục vụ mở rộng cơ sở dữ liệu, mà còn giúp hệ thống và ứng dụng duy trì hoạt động khi xảy ra sự cố hoặc gián đoạn.
Tuy nhiên, càng nhiều bản sao thì việc ghi càng tốn kém, do cần cập nhật đồng bộ trên tất cả. Mỗi phân vùng thường có một bản sao chính và nhiều bản sao phụ.
Thực tế, phân vùng và sao chép thường kết hợp để vừa tăng hiệu suất vừa tăng khả năng chịu lỗi.
Khi hệ thống mở rộng, vấn đề đặt ra là cách nó phản ứng khi máy hỏng hoặc mạng không đảm bảo truyền tin ổn định.
3/ Định lý CAP
Trong hệ thống phân tán, ba đặc tính mong muốn là:
- Tính nhất quán (Consistency): Đảm bảo các máy khách thấy cùng dữ liệu dù truy cập bản sao khác nhau, khác với tính nhất quán trong ACID (duy trì ràng buộc cơ sở dữ liệu).
- Tính khả dụng (Availability): Mọi yêu cầu hợp lệ nhận phản hồi không lỗi.
- Khả năng chịu phân vùng (Partition Tolerance): Hệ thống hoạt động dù mạng bị gián đoạn hoặc mất tin nhắn.
Định lý CAP chỉ ra hệ thống phân tán chỉ đạt được tối đa hai trong ba đặc tính trên. Vì sự cố mạng khó tránh, hầu hết hệ thống ưu tiên khả năng chịu phân vùng, dẫn đến đánh đổi giữa tính nhất quán và tính khả dụng khi mạng bị phân vùng.
Nhiều hệ thống chọn tính nhất quán cuối cùng, đảm bảo các bản sao đồng bộ sau khi cập nhật lan truyền không đồng bộ, cải thiện hiệu suất nhưng cần giải quyết xung đột cập nhật đồng thời.
Do khó khăn trong mở rộng hệ thống quan hệ, các mô hình dữ liệu NoSQL được xem xét.
III/ Các mô hình dữ liệu NoSQL
1/ Mô hình Key-Value
Cách thức hoạt động: Dữ liệu được lưu trữ dưới dạng các cặp khóa-giá trị, trong đó mỗi khóa là duy nhất và tương ứng với một giá trị cụ thể.
Ưu điểm: Thiết kế đơn giản, tốc độ truy xuất cực nhanh, lý tưởng cho các ứng dụng cần bộ nhớ đệm hoặc lưu trữ thông tin phiên.
Ví dụ: Redis, Amazon DynamoDB, Riak.
Ứng dụng: Quản lý giỏ hàng trong thương mại điện tử, lưu trữ cấu hình hệ thống, hoặc ứng dụng trong lĩnh vực IoT.
2/ Mô hình Document-oriented
Cách thức hoạt động: Dữ liệu được lưu dưới dạng các tài liệu, thường sử dụng định dạng JSON. Mỗi tài liệu bao gồm các cặp trường-giá trị, với giá trị có thể là chuỗi, số, boolean, mảng hoặc thậm chí các đối tượng lồng nhau.
Ưu điểm: Linh hoạt, dễ dàng xử lý các truy vấn phức tạp, phù hợp cho các ứng dụng web hiện đại.
Ví dụ: MongoDB, CouchDB, Firestore.
Ứng dụng: Quản lý nội dung (CMS), lưu trữ hồ sơ khách hàng, hoặc quản lý thông tin sản phẩm.
3/ Cơ sở dữ liệu Wide-Column
Cách thức hoạt động: Dữ liệu được tổ chức theo cột thay vì hàng, tối ưu hóa cho việc phân tích khối lượng dữ liệu lớn và xử lý các truy vấn trên tập dữ liệu quy mô lớn.
Ưu điểm: Hiệu suất vượt trội khi làm việc với dữ liệu lớn, khả năng mở rộng dễ dàng.
Ví dụ: Apache Cassandra, Hbase,…
Ứng dụng: Phân tích nhật ký hệ thống, xử lý dữ liệu chuỗi thời gian, hoặc các ứng dụng yêu cầu truy xuất dữ liệu lớn.
IV/ Lợi ích của NoSQL
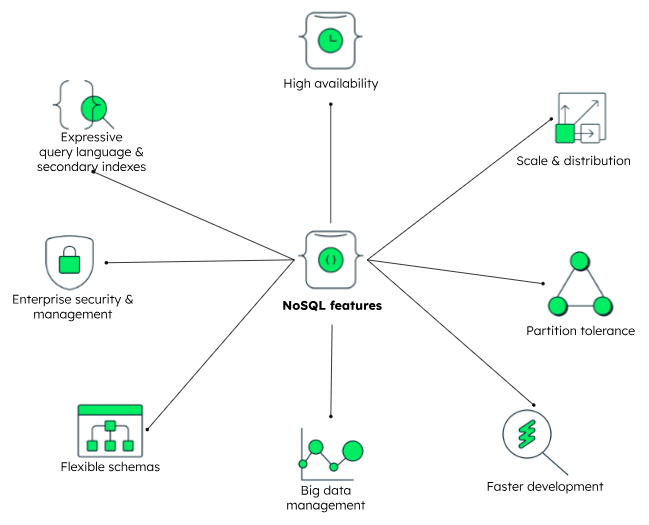
Cơ sở dữ liệu NoSQL mang lại nhiều lợi ích quan trọng, đặc biệt trong các môi trường ứng dụng hiện đại:
- Tính linh hoạt cao: NoSQL cho phép lưu trữ và xử lý nhiều loại dữ liệu khác nhau mà không cần tuân theo lược đồ cố định, dễ dàng điều chỉnh khi nhu cầu thay đổi.
- Khả năng mở rộng dễ dàng: Hỗ trợ phân tán trên nhiều máy chủ, giúp hệ thống đáp ứng tốt với sự gia tăng nhanh chóng của dữ liệu và lưu lượng truy cập mà không cần đầu tư lớn vào cơ sở hạ tầng.
- Hiệu suất vượt trội: Tối ưu cho các ứng dụng cần xử lý tức thời, chẳng hạn như thương mại điện tử, phân tích dữ liệu IoT, hay các hệ thống đề xuất nội dung.
- Tiết kiệm tài nguyên: Được thiết kế để quản lý khối lượng dữ liệu khổng lồ với tốc độ truy vấn nhanh, NoSQL giảm thiểu yêu cầu về phần cứng và tài nguyên hệ thống, đồng thời tăng khả năng chịu lỗi.
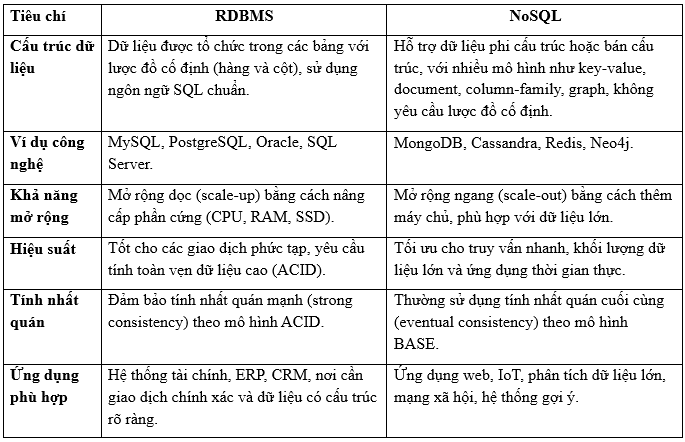
V/ So sánh RDBMS và NoSQL
VI/ Kết luận
NoSQL ra đời như một hướng tiếp cận bổ sung cho RDBMS, tập trung vào tính linh hoạt, hiệu năng và khả năng mở rộng ngang để đáp ứng nhu cầu dữ liệu khổng lồ của ứng dụng hiện đại.
NoSQL phú hợp cho hệ thống tối ưu cho tốc độ, quy mô và sự đa dạng của dữ liệu, trở thành lựa chọn quan trọng trong kỷ nguyên Web và Big Data.
📚 Nguồn tham khảo
Berkeley: NoSQL - Database System
📝 Kết nối với mình
✍️ Blog: Quan Notes
💼 Linkedin: Võ Minh Quân
All rights reserved
