Node.js vs Java: 5 câu hỏi dễ nhầm lẫn về Runtime, Event Loop và I/O
Node.js và Java khác nhau như thế nào? Bài viết này phân tích 5 câu hỏi thực tế về Event loop, Cluster, Cold Start, WebFlux, Virtual Threads, và Frontend/Backend runtimes.
Nếu thấy hay, kết nối với mình tại LinkedIn.
Tiếp nối mấy bài trước về Process, Thread và Virtual Thread trong Java, mình càng thấy Java, nhất là từ Java 21, đã trở nên rất đáng gờm cho backend hiện đại. Nếu nhìn lại khoảng hơn 10 năm trước, Java gần như là lựa chọn mặc định của rất nhiều hệ thống backend. Nhưng vài năm gần đây, thị trường đã thay đổi khá nhiều, và cũng có thêm nhiều ngôn ngữ/runtime mới giúp phát triển nhanh hơn, nhẹ hơn, và linh hoạt hơn.
Một trong những cái tên nổi bật nhất là Node.js — runtime của JavaScript. Đến bây giờ, Node.js vẫn là một lựa chọn rất phổ biến cho backend, đặc biệt khi cần xử lý I/O tốt, khởi động nhanh, hoặc muốn tận dụng chung hệ sinh thái JavaScript từ frontend đến backend. Còn ở frontend thì khỏi phải bàn, JavaScript vẫn gần như là “ông vua”.
Bài viết này không phải để giới thiệu Node.js từ con số 0, mà là để đi vào những câu hỏi mình nghĩ khá nhiều anh em từng tự hỏi: Node.js hoạt động thế nào, mạnh ở đâu, yếu ở đâu, và đằng sau những điều “trông có vẻ đơn giản” đó thực ra là gì. Bắt đầu thôi  .
.
1. Node.js xử lý hàng triệu request đồng thời như thế nào?
Câu trả lời ngắn là: còn tuỳ.
Node.js có thể xử lý rất tốt lượng request đồng thời rất lớn, nhưng điều đó chỉ đúng khi workload của bạn chủ yếu là I/O Bound — tức là phần lớn thời gian hệ thống không phải để tính toán, mà để chờ đợi những tác vụ như:
- Chờ database trả kết quả
- Chờ đọc/ghi file.
- Chờ gọi API bên thứ ba
- Chờ network phản hồi
Ngược lại, nếu ứng dụng của bạn chủ yếu là CPU-Bound — tức là phải tính toán nặng, xử lý video, nén dữ liệu, mã hoá, giải thuật phức tạp — thì Node.js không phải lựa chọn lý tưởng nếu bạn để mọi thứ chạy trực tiếp trên event loop.
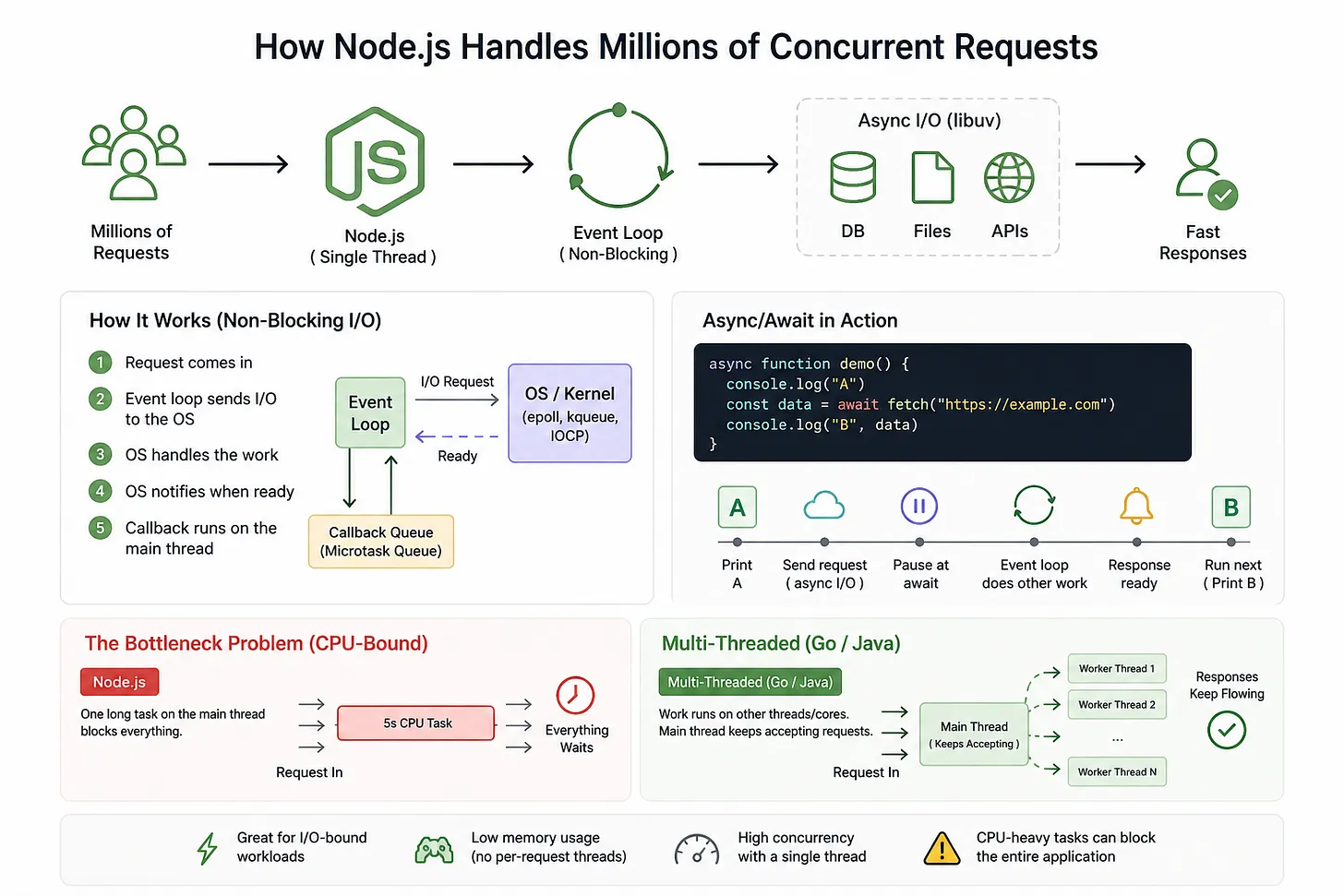
Single Thread và Event Loop
Hầu hết các framework truyền thống (như Java -version < 21, đều sử dụng mô hình Multi-thread). Có nghĩa là, khi có một request tới, thì nó sẽ tạo ra một luồng riêng để xử lý request đó. Nếu có 1 triệu request, thì cũng đồng thời tạo ra 1 triệu thread, và máy tính phải cấp phát bộ nhớ cho tất cả các thread đó, dẫn tới cạn kiệt RAM. Ngoaì ra chi phí cho Context Switching giữa các thread đó cũng làm cho ứng dụng trở nên chậm chạp thay vì làm việc có ích.
Mặc định, một tiến trình Node.js chạy JavaScript trên một luồng chính, và điều này giúp event loop rất hiệu quả cho I/O-bound workload. Tuy nhiên, Node.js vẫn có các cơ chế nội bộ khác và có thể được mở rộng để dùng nhiều core khi cần.
Luồng chính duy nhất sẽ xử lý tất cả các yêu cầu được gửi tới, nên không mất chi phí bộ nhớ và chi phí context switching. Event loop (vòng lập sự kiện) sẽ liên tục đẩy các tác vụ vào trong luồng chính duy nhất này để xử lý. Cho dù server của bạn , CPU có nhiều core, thì Node.js cũng chỉ có 1 thread chính duy nhất, hoạt động trên một core duy nhất.
Non-Blocking I/O
Phần lớn thời gian của một webserver là để chờ: như chờ DB trả kết quả, chờ đọc file, chờ API của bên thứ 3. Với Java (version <21), khi đó thì luồng sẽ đứng yên đợi (Blocking), mà không làm gì cả. Bao giờ có kết quả thì xử lý tiếp.
Với Node.js, khi yêu cầu I/O được gửi đi tác vụ đó sẽ được event loop chuyển xuống lớp async I/O bên dưới của runtime, chứ không chạy trực tiếp trên luồng của Javascript.
Với các thao tác như đọc file, truy vấn mạng, gọi database, Node.js dựa vào cơ chế I/O bất đồng bộ của runtime và kernel. Trên Linux, cơ chế thường được nhắc tới là epoll; trên macOS là kqueue, trên Windows là IOCP, các cơ chế này cho phép Node đăng ký quan sát các file descriptor / socket, rồi chờ kernel báo khi chúng sẵn sàng thay vì block luồng JS.
Điểm quan trọng là: OS không “đẩy dữ liệu trực tiếp vào event loop” theo kiểu ma thuật.Thực tế là Node/libuv đăng ký chờ sự kiện I/O, kernel theo dõi trạng thái I/O, rồi khi socket/file đã sẵn sàng, kernel đánh thực hoặc thông báo cho event loop biết rằng có thể tiếp tục xử lý.
OS báo cho Node.js bằng cách nào ?
Cách diễn đạt chính xác hơn là:
- Node/libuv đưa yêu cầu I/O xuống tầng hệ điều hành
- Hệ điều hành theo dõi trạng thái I/O đó
- Khi I/O hoàn tất hoặc có dữ liệu sẵn sàng, kernel trả tín hiệu “ready”
- Event loop nhận tín hiệu này, lấy callback / contunuation tương ứng ra khỏi hàng đợi và chạy trên luồng chính
Vì thế, không phải là file hay database tự nói chuyện với Javascript, mà là kernel + cơ chế event notification báo với runtime răng tài nguyên đã sẵn sàng.
Trực quan hơn, chúng ta lấy ví dụ với Promise, async, await. Khi Promise được resolve, phần code đang chơ await không nhảy thẳng vào chạy ngay giữa lúc event loop đang bận. Nó thường được đưa vào promise queue / mỉcortask queue, rồi được ưu tiên chạy sau khi callback hiện tại kết thúc, trước khi event loop chuyển sang pha tiếp theo.
async function demo() {
console.log(”A”)
const data = await fetch(”https://example.com”)
console.log(”B”, data)
}
Thực tế là:
In ra A
-> Gửi request network xuống tầng async I/O
-> Hàm demo tạm dừng tại await
-> Event loop tiếp tục xử lý việc khác
-> Khi response về, Promise resolve
-> phần console.log ("B", data) được xếp vào hàng đợi chạy tiếp
Hãy tưởng tượng như trong 1 nhà hàng, chỉ có một người phục vụ duy nhất (Single Thread). Khi nhân viên lấy order xong, đẩy order( request) xuống bếp (OS) để xử lý, trong thời gian đó, nhân viên này qua bàn khác để lấy order hoặc phục vụ bàn khác chứ không ngồi chờ bếp làm xong để phục vụ duy nhất một bàn. Nào món ăn sẵn sàng, nhà bếp gửi tín hiệu cho nhân viên như gõ chuông và đẩy đồ ăn vào vị trí chờ tới lượt mang đi (Event loop Queue). Một nhân viên như vậy có thể phục vụ cả trăm bàn nếu anh ta có đủ sức khoẻ.
Hiện tượng “Nghẽn cổ chai” (Blocking the Loop)
Vì Node.js chỉ có một luồng chính, nếu luồng đó bận thực hiện một phép tính mất 5 giây, thì trong 5 giây đó:
- Nó không thể nhận thêm request mới
- Nó không thể trả lời các tác vụ mà đã “forward” xuống OS rồi OS epoll lên lại hàng đợi của event loop
- Toàn bộ ứng dụng sẽ bị “đứng hình”
Trong khi đó, các ngôn ngx Multi-Thread như Go, Java, có thể đẩy bài toán đó sang một luồng khác trên một nhân CPU khác, giúp luồng chính tự do đón khách.
2. Node Cluster có giải quyết được vấn đề với các bài toán CPU Bound không ?
Mặc định, Node.js chạy Javascript trên một luồng chính trong mỗi process, nên một process đơn lẻ không thể tự động tận dụng hết toàn bộ các core CPU. Nếu máy chủ của bạn có 10 cores, thì 9 cores còn lại phần lớn sẽ ngồi chơi xơi nước, không làm ăn gi cả.
Cluster Module là một tính năng tích hợp sẵn cho phép bạn khởi tạo nhiều tiến trình (worker processes) chạy song song. Các tiến trình này chia sẽ cùng một cổng (port) mạng, nhờ đó có thể phân phối tải lên nhiều core hơn.
- Master Process: Đóng vai trò “quản lý”, theo dõi và điều phối các worker.
- Worker Process: Là các bản sao của ứng dụng, trực tiếp xử lý các request
Cluster giải quyết vấn đề gì ?
Thay vì lãng phí tài nguyên, Cluster cho phép bạn chạy số lượng tiến trình tương ứng với số core của CPU. Hiệu năng tổng thể của hệ thống có thể tăng lên gấp nhiều lần.
Nếu một Worker bị crash do lỗi code, các Worker khác vẫn hoạt động bình thường để phục vụ khách. Master process có thể được cấu hình để tự động “hồi sinh” (fork lại) một Worker mới thay thế ngay lập tức.
Khi có nhiều Worker, nếu một Worker đang bận “vật lộn” với một phép tính nặng (CPU-bound), hệ điều hành và Cluster Master sẽ điều phối các request mới sang các Worker còn đang rảnh rỗi.
Lưu ý: Node Cluster không làm cho phép tính đó nhanh hơn, nhưng nó ngăn việc một phép tính nặng làm tê liệt toàn bộ server.
Hạn chế
Dù mạnh mẽ, Cluster vẫn có những hạn chế mà bạn cần lưu ý:
- Không chia sẻ bộ nhớ: Mỗi Worker là một tiến trình riêng biệt với vùng nhớ (RAM) riêng, vì nó là process mà. Bạn không thể lưu một biến global ở Worker A rồi bắt Worker B đọc nó. Để chia sẻ dữ liệu, bạn phải dùng các công cụ bên ngoài như Redis hoặc Database
- Quản lý phức tạp: Việc quản lý session (phiên đăng nhập) trở nên khó hơn vì request của một người dùng có thể nhảy giữa các Worker khác nhau (cần giải quyết bằng Sticky Sessions hoặc Centralized Session Store).
Giải pháp thay thế: Worker Threads
Nếu Cluster tạo ra nhiều tiến trình (process) độc lập, thì Worker Threads (ra đời từ Node.js v10.5.0), cho phép bạn tạo ra nhiều luồng (Thread) trong cùng một tiến trình.
- Cluster: Tốt nhất để tăng tải (Scaling) cho HTTP Server (I/O Bound)
- Worker Threads: Tốt nhất để xử lý các bài toán tính toán cực nặng (CPU Bound) ngay bên trong một instance vì chúng có thể chia sẻ bộ nhớ (
SharedArrayBuffer) giúp trao đổi dữ liệu cực nhanh.
Tóm lại, nếu bạn muốn ứng dụng Node.js thực hiện các tác vụ CPU-Bound mà không làm nghẽn server, thì nên dùng Worker Threads hoặc tách tác vụ đó ra một Service riêng bằng ngôn ngữ khác mạnh về tính toán hơn.
3. Vì sao Node.js khởi động nhanh hơn Java?
Nếu nhìn từ trải nghiệm thực tế, Node.js thường khởi động nhanh hơn Java, đặc biệt là khi so với các ứng dụng Java dùng framework nặng như Spring Boot. Điều này không có nghĩa Java “chậm” mà là vì Java và Node.js có mô hình khởi động khác nhau, mức độ chuẩn bị ban đầu khác nhau và triết lý thiết kế khác nhau.
Có thể hình dung đơn giản như sau:
- Node.js giống một chiếc xe máy: bật máy là đi được ngay.
- Java giống một chiếc xe buýt: trước khi lăn bánh, nó cần nhiều bước chuẩn bị hơn.
So sánh này không phải để nói công nghệ nào “tốt hơn tuyệt đối”, mà chỉ để nhấn mạnh rằng, Node.js thường có độ trễ khởi động thấp hơn.
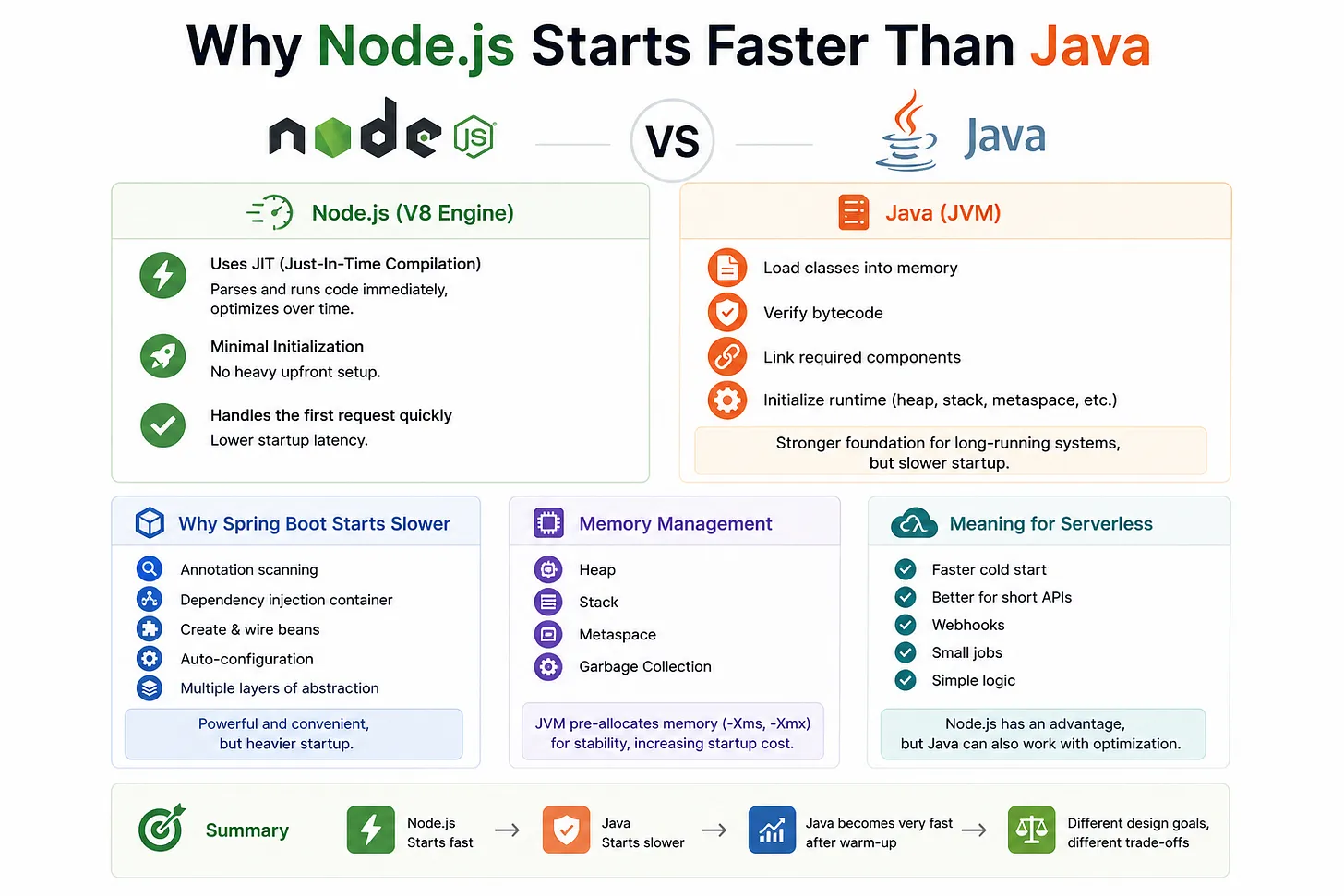
Cơ chế Thông dịch (Interpreted) vs Biên dịch (Compiled)
Node.js chạy Javascript trên V8 engine. V8 không chỉ đơn giản là “đọc code rồi chạy”, mà nó dùng cơ chế JIT (Just-In-Time Compilation). Khi ứng dụng bắt đầu, V8 có thể parse và thực thi code khá sớm, sau đó mới dần tối ưu những đoạn code chạy nhiều.
Nói cách khác, Node.js không cần phải chuẩn bị quá nhiều thứ trước khi bắt đầu xử lý request đầu tiên. Nó có thể vào việc khá sớm, rồi tối ưu dần trong quá trình chạy.
Trong khi đó, Java chạy trên JVM, và JVM thường phải làm nhiều công việc hơn lúc khởi động:
- Nạp class vào bộ nhớ.
- Xác thực bytecode.
- Liên kết các thành phần cần thiết.
- Khởi tạo runtime, heap, stack, metaspace và các cấu trúc nội bộ khác.
Những bước này giúp Java có nền tảng rất mạnh cho hệ thống chạy lâu dài, nhưng đổi lại thời gian khởi động thường dài hơn Node.js.
Vì sao Spring Boot lại khởi động chậm hơn ?
Khi so sánh giữa Express (Node.js) với Spring Boot (Java), thì sự khác biệt càng rõ rệt:
- Node.js: đi theo triết lý tối giản. Bạn cần cái gì thì require cái đó. Mọi thứ đều nhẹ và tách biệt. Thành phần nào không dùng thì không cần phải khởi tạo sớm và có ít lớp nền hơn lúc khởi động.
- Java: Các Framework như Spring Boot thường sử dụng kỹ thuật Annotation Scanning, và Dependency Injection (DI). Khi khởi động, nó phải “quét” toàn bộ Project để tìm xem cái nào được đánh dấu là
@Service,@Controller,@Component. Dựng dependency injection Container, sau đó tạo vào write các bean. Áp dụng auto-configuration. Thiết lập nhiều tầng abstraction của framework.
Chính vì lý do đó, quá trình khởi động của Spring Boot thường nặng hơn. Điều quan trọng là: đây không phải là lỗi, mà là cái giá của một framework enterprise rất mạnh và rất tiện. Java sinh ra cho các hệ thống cần chạy lâu dài, ổn định, có khả năng mở rộng tốt, và xử lý lượng tải lớn trong thời gian dài.
Vì vậy, JVM chập nhận bỏ thêm chi phí lúc khởi động để đổi lấy khả năng tối ưu tốt về sau. Sau khi warm up, JVM có thể rất mạnh, nhất là với các workload chạy lâu và có tính lặp lại cao.
Quản lý bộ nhớ
Một lý do nữa khiến Java thường có cảm giác “nặng” hơn khi khởi động là cách nó quản lý bộ nhớ. JVM thường khởi tạo những vùng nhớ như:
- Heap
- Stack
- Metaspace
- và các cấu trúc phục vụ Garbage Collection
Ngoài ra, trong nhiều hệ thống production, Java còn được cấu hính trước với các tham số như -Xms và -Xmx để xác định vùng nhớ ban đầu và vùng nhớ tối đa. Điều này giúp hệ thống ổn định hơn khi chạy lâu, nhưng cũng khiến thời gian khởi động và mức tiêu thụ tài nguyên ban đầu cao hơn.
Node.js thường có lượng tài nguyên cần thiết để khởi động nhẹ hơn, nhất là với các ứng dụng nhỏ hoặc vừa. Tuy nhiên, mức RAM thực tế vẫn phụ thuộc vào code, dependency, cache và workload. Nói “Node.js luôn nhẹ” là quá tuyệt đối, nhưng nói “Node.js thường nhẹ hơn lúc startup” thì hợp lý hơn.
Ý nghĩa trong serveless
Đây là nơi Node.js thường có lợi thế rất rõ. Với serverless như AWS Lambda, thời gian khởi động ban đầu, hay còn gọi là cold start, ảnh hưởng trực tiếp đến trải nghiệm của người dùng. Vì Node.js thường khởi động nhanh hơn, nên nó hay được chọn cho:
- API ngắn
- Webhook
- Job nhỏ
- Logic đơn giản cần phản hồi sớm
Tuy vậy, cũng không nên nói Node.js “vô địch” hay “luôn tốt nhất”. Java vẫn hoàn toàn có thể dùng trong serverless, đặc biệt khi được tối ưu đúng cách. Hiện này còn có những kỹ thuật giúp giảm cold start trong Java rất mạnh, nên Java không còn là lựa chọn “quá chậm” như trước. Mọi người có thể tìm hiểu thêm về Quarkus hay GraalVM, 2 giải pháp làm giảm thời gian khởi động cho các ứng dụng serverless được viết bằng Java nhe
4. Java đã có những cải tiến gì có thể so được với Node.js về các tác vụ I/O Bound
Nếu trước đây Node.js thường được xem là lựa chọn rất mạnh cho các bài toán I/O-bound, thì Java ngày nay đã có nhiều cải tiến đáng kể để thu hẹp khoảng cách, thậm chí vượt trội trong một số trường hợp. Hai hướng cải tiến nổi bật nhất là Reactive Programming với WebFlux và Virtual Threads trong Java 21.
Reactive Programming
Webflux là một mô hình non-blocking reactive trong hệ sinh thái Spring. Mục tiêu của nó là xử lý nhiều request đồng thời mà không cần giữ một thread blocking cho mỗi request như mô hình truyền thống.
Điểm mạnh của Webflux là:
- Phù hợp với hệ thống có nhiều I/O
- Tận dụng tài nguyên của hệ thống cực kỳ tốt (OS Thread)
- Tăng khả năng chịu tải khi số lượng kết nối đồng thời lớn
- Rất hợp với các luồng xử lý dạng streaming hoặc gọi qua lại nhiều service.
Cách hoạt động của Webflux có thể khiến chúng ta liên tưởng tới Node.js vì đều theo hướng event-drivent và non-blocking. Tuy nhiên, Webflux không phải là '“Node.js trong Java”. Nó là một cách tiếp cận reactive dựa trên hệ sinh thái Spring, thường chạy các runtime non-blocking như Netty.
Điều quan trọng là Webflux không tự động giải quyết bài toán CPU-Bound. Nếu bạn đưa những tác vụ tính toán nặng lên cùng event loop hoặc xử lý reactive pipeline một cách không hợp lý, bạn vẫn có thể làm nghẽn hệ thống. Vì vậy, Webflux mạnh ở I/O bound, nhưng không phải là lời gian cho mọi loại workload.
Nói ngắn gọn, Webflux phù hợp khi bạn cần:
- Số lượng request đồng thời lớn
- I/O nhiều hơn tính toán
- Mô hình non-blocking end-to-end
- Tối ưu số lượng thread sử dụng.
Tuy nhiên, cái giá phải trả là độ phức tạp cao hơn. Code reactive thường khó đọc hơn, khó debug hơn, và đòi hỏi team phải quen với tư duy luồng dữ liệu, backpressure, và bất đồng bộ.
Virtual Thread
Kể từ Java 21, Java đã cho ra đời Virtual Thread, một trong những tính năng gần như đỉnh nhất kể từ thời Java 8, đặb biệt là đã tích hợp sâu vào Spring Boot 3.2, một bước tiến rất quan trọng trong việc xử lý đồng thời.
Virtual Threads cho phép bạn tạo ra rất nhiều luồng ứng dụng, nhưng các luồng này không tương ứng 1-1 với OS thread (carrier thread). Thay vào đó, chúng được JVM Scheduler quản lý và chia sẻ trên một số lượng nhỏ OS thread bên dưới.
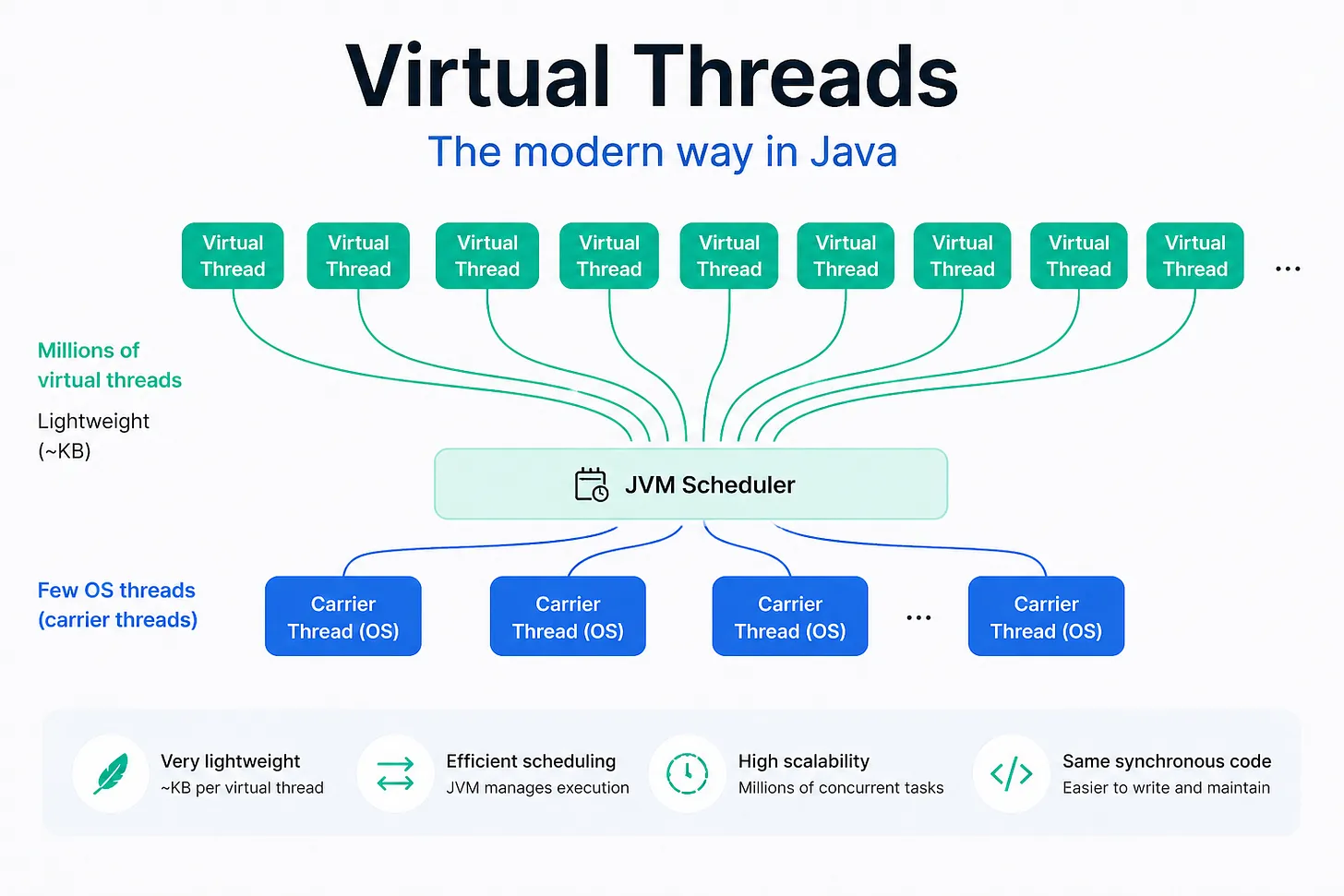
Điều này mang lại lợi ích rất lớn:
- Bạn vẫn có thể viết code theo phong cách blocking quen thuộc
- Nhưng chi phí tài nguyên thấp hơn nhiều so với thread truyền thống
- Khi gặp tác vụ I/O, virtual thread có thể được tạm ngưng để nhường carrier thread cho tác vụ khác
Điểm hay nhất của Virtual Threads là nó giúp Java giữ được sự đơn giản khi viết code mà vẫn mở rộng tốt trong các workload có nhiều I/O. Đây là lý do rất nhiều người (trong đó có mình) xem nó là một trong những cải tiến quan trọng nhất của Java trong nhiều năm gần đây.
Nếu so với reactive programming, Virtual Threads thường dễ tiếp cận hơn với đa số developer vì:
- Không cần đổi hoàn toàn tư duy sang reactive
- Không cần chain quá nhiều callback/pipeline
- Code nhìn gần giống style đồng bộ truyền thống
Tuy nhiên, Virtual Threads cũng không phải là “vũ khí tối thượng” cho mọi tình huống. Nó giúp rất nhiều cho I/O bound, nhưng với CPU-bound nặng thì bạn vẫn cần thiết kế phù hợp, tách tác vụ, hoặc dùng song song đúng cách.
So với Node.js thì sao?
Nếu so với Java hiện đại với Node.js, thì cuộc chơi không còn đơn giản là “Node.js nhanh hơn Java ở I/O-bound” nữa. Node.js vẫn rất mạnh ở:
- Startup nhanh
- Mô hình event loop đơn giản
- Hệ sinh thái Javascript thống nhất từ backend tới frontend
- Phù hợp với các service nhỏ, nhẹ và cần phản hồi nhanh
Trong khi đó, Java hiện nay đã có:
- WebFlux cho mô hình reactive-non-blocking
- Virtual Threads cho cách viết code đơn giản nhưng vẫn scale tốt
- JVM tối ưu rất mạnh cho các hệ thống chạy lâu dài
Vì vây, Java đã trở thành một lựa chọn rất cạnh tranh cho các bài toán I/O-bound, đặc biệt khi team muốn giữ code dễ đọc, dễ bảo trì và tận dụng tốt hệ sinh thái Spring.
5. Vì sao cùng là JavaScript nhưng frontend và backend lại khác nhau?
Không riêng gì các bạn, chính mình cũng đã từng đặt ra câu hỏi hơi "ngu ngốc" như vậy.
Nhưng dù sao nó là một câu hỏi rất hay, vì nó chạm vào một hiểu lầm phổ biến: Nhiều người nghĩ rằng nếu cùng là Javascript thì ở đâu cũng chạy giống nhau. Thực tế thì không phải ngôn ngữ Javascript quyết định tất cả, mà còn phụ thuộc và runtime và môi thường thực thi
Javascript ở frontend và Backend dùng cùng một ngôn ngữ, nhưng chúng chạy trong hai thế giới khác nhau:
- Frontend chạy trong browser runtime
- Backend chạy trong Node.js runtime
Chính sự khác nhau này khiến chúng có khả năng và giới hạn hoàn toàn khác nhau.

Frontend và backend dùng runtime khác nhau
Khi viết frontend với React, Vue, Angular hoặc Javascript thuần, code của bạn sẽ chạy trong trình duyệt. Trình duyệt cung cấp rất nhiều API phục vụ cho giao diện và tương tác người dùng, chẳng hạn như:
alert()windowdocument- thao tác với DOM
- xử lý sự kiện chuột, bàn phím, scroll
Vì thế alert() chạy được ở frontend là chuyện bình thường. Nó là một phần của browser API, không phải của Javascript ngôn ngữ thuần tuý.
Ngược lại, khi Javascript chạy trong Node.js, nó không có các đối tượng như window hay document. Node.js được thiết kế cho môi trường server, nên nó cung cấp những API khác, chẳng hạn như:
- làm việc với file system
- xử lý network
- tạo server
- đọc environment variables
- thao tác với process
- và kết nối các thư viện server-side khác.
Do đó, bạn không thể gọi alert() trong backend Node.js, vì runtime này không hề có API đó.
Node.js không phải là “JavaScript thuần”
Một điểm dễ gây hiểu nhầm là nghĩ rằng Node.js chỉ đơn giản là “chạy Javascript”. Thực ra Node.js là một runtime environment cho Javascript. Ngoài bản thân engine xử lý Javascript, Node.js còn đi kèm với:
- runtime để chạy code (Node)
- standard library cho các tác vụ hệ thống, các module chuẩn mà Node cung cấp sẵn
- và
npmlà công cụ quản lý package đi kèm phổ biến nhất
Nhờ những thứ đó, backend Javascript có thể làm các việc mà trình duyệt không thể làm như đọc file, tạo TCP server, hoặc kết nối tới database.
Vì sao browser không kết nối database trực tiếp?
Frontend không thể hoặc không nên kết nối trực tiếp và database production vì nhiều lý do.
Lý do đầu tiên là bảo mật. Nếu browser có thể kết nối thẳng tới database, bạn sẽ phải đưa thông tin đăng nhập database xuống client. Điều đó cực kỳ nguy hiểm, vì người dùng có thể nhìn thấy, sửa hoặc khai thác thông tin đó.
Lý do thứ hai là kiến trúc hệ thống. Trong mô hình web hiện đại, frontend và database không nên nói chuyện trực tiếp với nhau. Thay vào đó:
Frontend → Backend API → Database → Backend API → Frontend
Cách làm này giúp bảo vệ những thông tin nhạy cảm, kiểm soát quyền truy cập vào hệ thống, ngoài ra có thể xử lý validation, lưu trữ log và audit tốt hơn và tách biệt trách nhiệm giữa client và server.
Vì vậy, điều đúng nhất để ghi nhớ là:
Không phải JavaScript quyết định bạn làm được gì, mà là runtime và môi trường chạy quyết định điều đó.
Kết
Nhìn lại 5 câu hỏi trên, có thể thấy điều quan trọng nhất không phải là “Node.js hay Java tốt hơn”, mà là mỗi nền tảng mạnh ở một kiểu bài toán khác nhau. Node.js nổi bật ở event loop, non blocking I/O, startup nhanh và hệ sinh thái frontend-backend thống nhất. Trong khi Java ngày nay đã tiến rất xa với WebFlux và Virtual Threads, giúp xử lý I/O-bound hiệu quả hơn nhiều so với trước đây.
Nếu hiểu đúng bản chất runtime, event loop, cluster, virtual threads và giới hạn của browser so với Node.js, bạn sẽ dễ chọn công nghệ phù hợp hơn cho từng trường hợp thực tế. Và thay vì tranh luận xem “ai hơn ai”, câu hỏi đáng giá hơn thường là: với workload này, đội ngũ này, và yêu cầu này, đâu là lựa chọn ít rủi ro nhất và dễ vận hành nhất.
Bài viết này cũng được mình dịch sang tiếng Anh trên blog substack của mình.
Mình viết lại những điều này như một cách để ghi nhớ hành trình làm nghề của mình. Nếu bạn cũng đang làm backend, devops hoặc cloud, hy vọng những chia sẻ này có thể giúp bạn một chút gì đó. Còn nếu có chỗ nào mình hiểu chưa đúng, mình vẫn luôn sẵn sàng học thêm.
All rights reserved
