[Nodejs] Dùng selenium, cheerio để crawl dữ liệu
Bài đăng này đã không được cập nhật trong 4 năm
Dạo này từ khóa "Crawler" đang "hot" trên blog nên mình thực hiện bài viết này để ăn theo 
Crawl dữ liệu
Crawl là một vấn đề hay gặp trong quá trình làm software. Ví dụ lấy tin tức, thông tin sản phẩm, vé xem phim…. Một cách khá đơn giản đó là phân tích HTML, đọc các thẻ và rút trích dữ liệu. Thư viện trên Nodejs mình hay dùng đó là cheeriojs.
Tuy nhiên việc crawl một trang bằng đọc HTML thuần sẽ rất khó khăn trong một số trường hợp như: dữ liệu được load bằng ajax(lúc đọc HTML sẽ chỉ thấy wrapper chứ không thấy dữ liệu, dữ liệu ajax trả về bị encode) hay muốn vào được trang cần crawl thì phải qua bước login,...
Trong bài này mình sẽ lấy một ví dụ, mình muốn crawl lấy những sản phẩm trong category của Taobao.
Trang này javascript sẽ xử lý đổ dữ liệu và sau đó mới đổ vào cây DOM. Khi dùng request đọc HTML thì sẽ không thấy được các thẻ div như khi inspect element.
Với những loại như thế này, mình sử dụng selenium để chạy web trên browser thật, thực hiện thao tác để được trang HTML fully load rồi mới trích xuất dữ liệu.
Selenium khá nổi tiếng trong lĩnh vực automation test. Nó cho phép mình chạy script test trên browser thật. Cách làm của mình sẽ là: Dùng selenium chạy trang Taoabo lên, đợi javascript load xong và sau đó crawl dữ liệu bình thường.
Vì Selenium chạy trên nền JVM (máy tính cần cài đặt môi trường Java), nên mình tìm trên mạng giải pháp bằng docker: Selenium docker
(Cách mình trình bày không phải là cách tốt nhất trong trường hợp này, bằng các biện pháp nghiệp vụ các bạn sẽ thấy trang này không sử dụng Ajax để load thông tin danh sách sản phẩm, nội dung này được lưu trong 1 biến javascript, wrapper đã có thể lấy được ở dạng json. Nhưng vì để chống đối nên mình vẫn lấy để demo (bow)).
Selenium grid
Hệ thống Selenium grid chuyên dùng cho việc thực hiện test tự động: Thực hiện nhiều test case, trên nhiều trình duyệt, version trình duyệt khác nhau, trình duyệt chạy trên các hệ điều hành khác nhau. Hệ thống selenium grid bao gồm một hub và một hoặc nhiều node (không phải nodejs ). Hub là trung tâm tiếp nhận các yêu cầu thực hiện test, thông tin này bao gồm test case, loại trình duyệt, hệ điều hành nơi các test sẽ được chạy. Các nodes sẽ kết nối vào Hub nhận các request từ Hub. Như vậy node sẽ là nợi chạy các trình duyệt và thực hiện các test case.
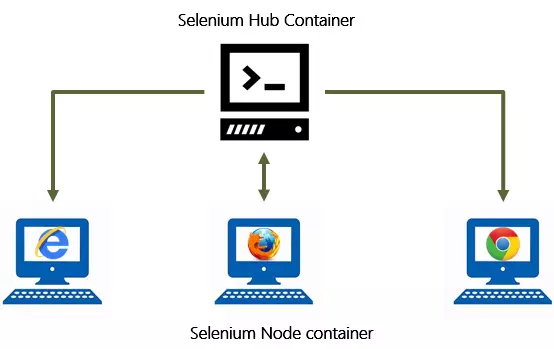 Với mục đích của mình chúng ta chỉ cần Hub và một node là đủ:
Với mục đích của mình chúng ta chỉ cần Hub và một node là đủ:
- Selenium hub
$ docker run -d --name selenium-hub -p 4444:4444 selenium/hub
cổng 4444 là cổng chương trình node sẽ kết nối và thực hiện các action.
- Firefox Node
$ docker run -d -P --link selenium-hub:hub selenium/node-firefox
Container này kết nối tời selenium-hub ở trên.
Code
Tài thư viện:
$ npm install selenium-webdriver -S
Khởi tạo driver kết nối tới Selenium hub
const {Builder, until} = require('selenium-webdriver');
let driver = new Builder()
.forBrowser('firefox')
.usingServer(process.env.SELENIUM_REMOTE_URL || 'http://localhost:4444/wd/hub')
.build();
Url cần lấy thông tin các sản phẩm:
const shoes_bags_url = "https://s.taobao.com/search?spm=a21wu.241046-global.6977698868.96.73b52f60D9FfWb&q=%E9%9E%8B%E5%8C%85&acm=lb-zebra-241046-2058600.1003.4.1797247&scm=1003.4.lb-zebra-241046-2058600.OTHER_14950684615043_1797247";
Thực hiện tải trang:
driver.get(shoes_bags_url)
.then(() => driver.wait(until.titleIs('鞋包_淘宝搜索'), 1000))
.then(() => driver.getTitle())
.then((title) => {
console.log(title);
})
.then(() => {
driver.quit();
});
Chúng ta có thể sử dụng driver để bóc tác dữ liệu html, nhưng như thế code sẽ khá dài và phức tạp (tìm kiếm một phần tử theo css class cũng trả lại một promise ). Webdriver có một function là getPageSource() thần thánh, có thể lấy toàn bộ html như lúc chúng ta inspect.
Đến đây chúng ta có thể sử dụng một thư viện phổ biến là cheerio với "cú pháp" đơn giản để bóc tách dữ liệu.
Tải cheerio:
npm install cheerio
Load html source vào đối tượng Cheerio:
.then(() => driver.getPageSource())
.then((source) => {
const $ = require('cheerio').load(source);
})
Những thông tin sẽ lấy của một sản phầm sẽ là: Ảnh sản phẩm, giá, tiêu đề, đường link chi tiết
- Thông tin các sản phẩm nằm ở:
#mainsrp-itemlist > div > div > div:nth-child(1) > div
const getProductElements = ($) => {
let productEles = [];
$('#mainsrp-itemlist').find('> div > div > div:nth-child(1) > div').each((_, ele) => {
productEles.push($(ele));
});
return productEles;
};
- Thông tin của từng sản phẩm:
(Selector tương đối với element chứa thông tin sản phẩm)
- Tiêu đề sản phẩm:
.row.row-2.title > a - Giá sản phẩm:
.price.g_price.g_price-highlight - Ảnh sản phẩm:
.pic > a > img - Link sản phẩm:
.pic > a
- Tiêu đề sản phẩm:
const extractProductInfo = ($) => {
let title = $.find('.row.row-2.title > a').text();
let price = $.find('.price.g_price.g_price-highlight').text();
let thumb = $.find('.pic > a > img').attr('src');
let link = $.find('.pic > a').attr('href');
return {
title,
price,
thumb,
link
};
};
Chạy thử:
.then((source) => {
const $ = require('cheerio').load(source);
getProductElements($).map((ele) => {
console.log(extractProductInfo(ele));
});
})
Có vẻ "ngon"
{ title: '\n \n YT鞋子收纳袋旅行装鞋袋防水鞋包防尘袋装鞋子鞋套旅游收纳包\n ',
price: '\n ¥9.90\n ',
thumb: '//g-search2.alicdn.com/img/bao/uploaded/i4/i1/2149663944/TB1HReua2MTUeJjSZFKXXagopXa_!!0-item_pic.jpg_180x180.jpg',
link: '//detail.tmall.com/item.htm?id=522686804765&ad_id=&am_id=&cm_id=140105335569ed55e27b&pm_id=&abbucket=0' }
chỉ cần chuẩn "làm đẹp" lại dữ liệu một chút là được. Mà khoan đã, hình như có gì không ổn: Chỉ những sản phẩm đầu mới có đủ thông tin. À trang này thực hiện lazy load người dùng phải cuộn xuống thì mới load thông tin sản phẩm để hiển thị. Ok! chúng ta thực hiện một đoạn script trên "trình duyệt" để scoll xuống dưới cùng.
.then(() => driver.executeScript("window.scrollTo(0, document.body.scrollHeight);"))
.then(() => driver.getPageSource())
Dữ liệu title và price đang bị thừa "vài" ký tự, chúng ta cần loại bỏ chúng:
const extractProductInfo = ($) => {
let title = normalizeText($.find('.row.row-2.title > a').text());
let price = normalizeText($.find('.price.g_price.g_price-highlight').text());
let thumb = $.find('.pic > a > img').attr('src');
let link = $.find('.pic > a').attr('href');
return {
title,
price,
thumb,
link
};
};
const normalizeText = (text) => {
return text.replace(/\\n/g, '').trim();
};
{ title: '3个旅行鞋袋子可视鞋子收纳袋透明鞋袋防水透气牛津布可水洗鞋罩',
price: '¥28.63',
thumb: '//g-search1.alicdn.com/img/bao/uploaded/i4/imgextra/i3/256127111/TB2dXS5XqzyQeBjSszfXXX7OVXa_!!256127111.jpg_180x180.jpg',
link: '//item.taobao.com/item.htm?id=558766998204&ns=1&abbucket=0#detail' }
Cuối cúng là lưu thông tin những sản phẩm lại: Chúng ta sẽ lưu vào file với định dạng json
const saveText2File = (filepath, text) => {
fs.writeFile(filepath, text, 'utf8', function (err) {
if (err) {
return console.log(err);
}
console.log("The file was saved!");
});
};
.then((source) => {
const $ = require('cheerio').load(source);
let prods = getProductElements($).map(ele => extractProductInfo(ele));
saveText2File('./products.json', JSON.stringify(prods));
})
Tổng kết
Sử dụng phương pháp này chúng ta có thể giải quyết nhiều bài toán crawl dữ liệu.
Trong quá trình mình chạy thấy tốc độ hơi chậm và thỉnh thoảng Webdriver bị request timeout, phải restart các container(mình dùng Windows 10 và Docker toolbox ).
Hy vọng bài viết có ích cho các bạn!
SourceCode
Bài viết được đăng bởi cùng tác giả tại Link
All rights reserved
