Những Khái Niệm Căn Bản và Cốt Lõi về Neural Networks
Các Ý Tưởng Cốt Lõi Của Mạng Nơ-ron Nhân Tạo
Một hành trình khám phá cách trí tuệ nhân tạo "học" từ dữ liệu
Trong thập kỷ qua, mạng nơ-ron nhân tạo (Artificial Neural Networks - ANN) đã trở thành nền tảng của những đột phá trong lĩnh vực trí tuệ nhân tạo (AI), từ nhận dạng hình ảnh đến xử lý ngôn ngữ tự nhiên. Dù phức tạp, chúng đều xây dựng trên những nguyên lý cơ bản. Bài viết này sẽ giải mã các ý tưởng chính giúp mạng nơ-ron hoạt động, phù hợp cho độc giả muốn hiểu sâu hơn về AI mà không cần kiến thức chuyên sâu về toán học.
Mở Đầu: Bức Tranh Về Một Bộ Não Kỹ Thuật Số
Bạn có bao giờ thắc mắc: "Làm thế nào một cỗ máy có thể nhận diện khuôn mặt bạn chỉ trong 0.1 giây, dịch thuật cả trang sách tiếng Pháp sang tiếng Việt, hay thậm chí... sáng tác thơ?" Câu trả lời nằm ở mạng nơ-ron nhân tạo – công nghệ mô phỏng não người đang định hình tương lai của AI.
Trong bài viết này, chúng ta sẽ cùng "mổ xẻ" những nguyên lý cốt lõi giúp mạng nơ-ron hoạt động: từ cách chúng "nhìn" dữ liệu, "học" từ sai lầm, đến bí quyết tối ưu hóa để trở nên thông minh hơn. Đừng lo – bạn không cần là thiên tài toán học để hiểu những khái niệm này!
🔜 Ở các bài sâu hơn, mình sẽ cùng bạn "đào" vào từng lớp kiến trúc mạng, phân tích, và khám phá những điều "điên rồ" nhất của ANN. Hãy subscribe để không bỏ lỡ!
1. Mạng Nơ-ron: Mô Phỏng Não Người Một Cách Đơn Giản
Mạng nơ-ron lấy cảm hứng từ cấu trúc sinh học của não người, nơi các tế bào thần kinh (nơ-ron) kết nối với nhau để xử lý thông tin. Trong AI, mạng nơ-ron là tập hợp các "nơ-ron ảo" (đơn vị tính toán) liên kết thành nhiều lớp:
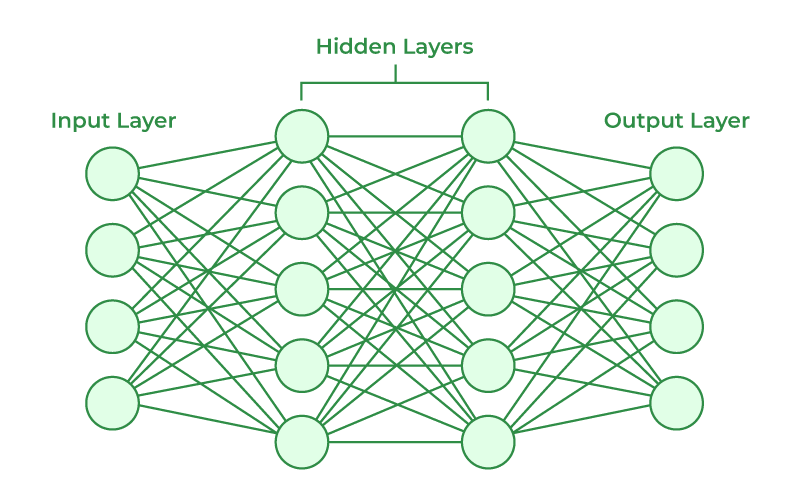
- Lớp đầu vào (Input Layer): Tiếp nhận dữ liệu (ví dụ: pixel ảnh, văn bản).
- Lớp ẩn (Hidden Layer): Phân tích đặc trưng từ dữ liệu thông qua phép toán và hàm kích hoạt.
- Lớp đầu ra (Output Layer): Đưa ra kết quả dự đoán (ví dụ: nhãn phân loại ảnh).
Mỗi kết nối giữa các nơ-ron có một trọng số (weight), đại diện cho "mức độ quan trọng" của thông tin. Quá trình "học" của mạng nơ-ron chính là việc điều chỉnh các trọng số này để tối ưu hóa kết quả.
2. Lan Truyền Tiến (Forward Propagation): Từ Dữ Liệu Đến Dự Đoán
Giả sử bạn đưa vào mạng một bức ảnh chó. Lan truyền tiến là quá trình tính toán để mạng đưa ra dự đoán "đây có phải chó không?" Cụ thể:
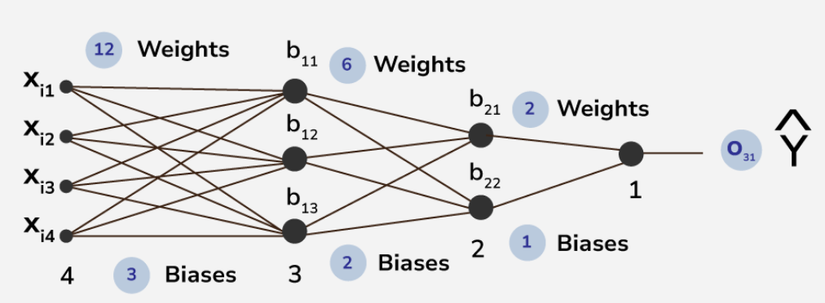
- Dữ liệu đầu vào được nhân với trọng số.
- Kết quả đi qua hàm kích hoạt (activation function) như Sigmoid, ReLU, để thêm tính phi tuyến, giúp mạng học các mẫu phức tạp.
- Quá trình lặp lại qua các lớp ẩn đến khi cho kết quả đầu ra.
Ví dụ: Hàm ReLU (Rectified Linear Unit) chuyển giá trị âm thành 0 và giữ nguyên giá trị dương, giúp mạng tập trung vào thông tin quan trọng.
3. Hàm Mất Mát (Loss Function) và Lan Truyền Ngược (Backpropagation): Học Từ Sai Lầm
Sau khi có dự đoán, mạng cần đánh giá độ chính xác. Hàm mất mát (ví dụ: Mean Squared Error, Cross-Entropy) đo lường sự khác biệt giữa dự đoán và giá trị thực.
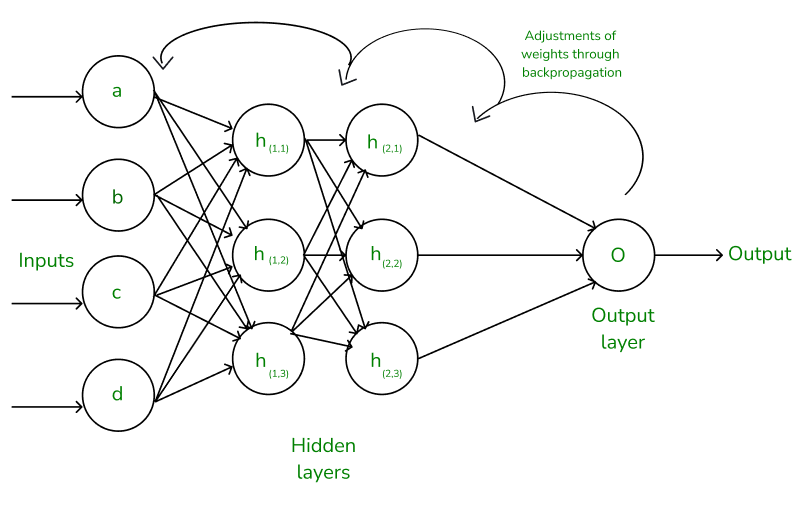
Để cải thiện, mạng sử dụng lan truyền ngược:
- Tính đạo hàm của hàm mất mát theo từng trọng số sử dụng quy tắc chuỗi (Chain Rule).
- Cập nhật trọng số bằng phương pháp Gradient Descent: điều chỉnh theo hướng giảm thiểu sai số.
Quá trình này lặp lại qua nhiều epoch (lần học) cho đến khi mạng đưa ra dự đoán chính xác.
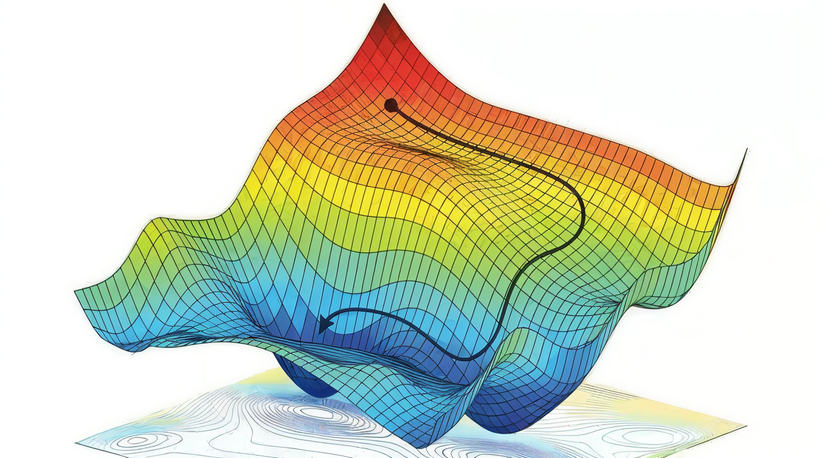
4. Tối Ưu Hóa (Optimization): Tìm Đường Đi Nhanh Nhất Xuống Núi
Gradient Descent giống như việc "xuống núi mù" – tìm đường dốc nhất để đến thung lũng (điểm mất mát thấp nhất). Tuy nhiên, có nhiều biến thể hiệu quả hơn:
- Stochastic Gradient Descent (SGD): Cập nhật trọng số sau mỗi mẫu dữ liệu, tránh bị kẹt ở điểm tối ưu cục bộ.
- Adam: Kết hợp động lượng và tốc độ học thích ứng, giúp hội tụ nhanh hơn.
5. Kiến Trúc Mạng: Từ Đơn Giản Đến Phức Tạp
- Mạng Nơ-ron Truyền Thẳng (Feedforward Neural Networks): Cơ bản nhất, dữ liệu đi một chiều từ đầu vào đến đầu ra.
- Mạng Tích Chập (CNN): Sử dụng bộ lọc (filter) để phát hiện đặc trưng hình ảnh (ví dụ: cạnh, màu sắc).
- Mạng Hồi Quy (RNN): Xử lý dữ liệu chuỗi (ví dụ: văn bản, âm thanh) bằng cách lưu trữ trạng thái ẩn.
- Transformer: Dựa trên cơ chế self-attention, tạo bước nhảy vọt trong xử lý ngôn ngữ (ví dụ: GPT, BERT).
6. Ứng Dụng và Thách Thức
- Ứng dụng: Xe tự lái, dịch máy, chẩn đoán y tế, hệ thống đề xuất, …
- Thách thức:
- Cần lượng dữ liệu huấn luyện lớn.
- Hiện tượng overfitting (mạng học thuộc dữ liệu huấn luyện nhưng kém trên dữ liệu mới).
- "Hộp đen" (Black Box): Khó giải thích cách mạng đưa ra quyết định.
Kết Luận: Khởi Đầu Cho Một Cuộc Cách Mạng
Mạng nơ-ron nhân tạo không chỉ là những dòng code lạnh lùng – chúng là bản giao hưởng của toán học, dữ liệu và sự sáng tạo. Những ý tưởng cơ bản như lan truyền ngược, hàm kích hoạt, hay tối ưu hóa... chính là "nguyên liệu thô" để xây dựng nên các hệ thống AI đỉnh cao như ChatGPT hay Tesla Autopilot.
Nhưng đây mới chỉ là bề nổi!
- 🔎 Trong bài tiếp theo, chúng ta sẽ "zoom" vào Quy Tắc Chuỗi (The Chain Rule) – mắt xích quan trọng giúp mạng nơ-ron tính toán gradient và 'nhìn' dữ liệu một cách hiệu quả.
- 💡 Bạn có tò mò về cách mạng nơ-ron "đọc hiểu" cảm xúc trong văn bản? Series về Transformer và cơ chế Attention sẽ khiến bạn bất ngờ!
Hãy comment chủ đề bạn muốn mình phân tích sâu nhất – mình sẽ ưu tiên viết về nó trước!
"Trí tuệ nhân tạo không thay thế con người – nó là tấm gương phản chiếu khát vọng khám phá của chúng ta."
All rights reserved
