Những góc nhìn đầu tiên về IPFS ?
Bài đăng này đã không được cập nhật trong 6 năm
Ở thời điểm hiện tại đóng vai trò chính trên Internet là giao thức HTTP vs vai trò là giao thức truyền tải siêu văn bản ( HyperText Transfer Protocol ) với mô hình chính là Client - Server .Cho tới gần đây một cái tên mới nổi được cho rằng sẽ có thể thay thế giao thức này đó chính là IPFS . Vậy IPFS là gì ? nó hoạt động như thế nào ? đó chính là những câu hỏi các bạn sẽ tìm được lời giải đáp thông qua bài viết này, hãy cùng tìm hiểu thôi .
IPFS là gì ?
Những hạn chế mà HTTP hiện tại đang gặp phải đó là phụ thuộc rất nhiều vào server ( đại diện cho mô hình client-server ) . Và chính vì phụ thuộc vào server mà nó có những hạn chế như nếu server sập client sẽ ko thể truy cập vào , hay server nắm quá nhiều data của người dùng dẫn đến những bê bối liên quan đến dữ liệu cá nhận ,... Chính vì thế IPFS được sinh ra với tư tưởng về mô hình P2P thay vì Client-server . IPFS (viết tắt của InterPlanetary File System) là một giao thức phân phối mã nguồn của giao thức hypermedia hoạt động dựa trên nội dung và danh tính. Là sự kết hợp của rất nhiều công nghệ như DHT , Git và BitTorrent
Để dễ hình dung chúng ta có thể hiểu bình thường chúng ta tải một thông tin lên mạng, dữ liệu sẽ đc tải lên server để lưu trữ, điều đó tiềm ẩn rủi ro nếu server gặp sự cố. Nhưng với IPFS bạn sẽ tải nó lên các máy tính khác cùng tham gia với mạng ( tất nhiên là dữ liệu đã được mã hóa rồi ) , như vậy sẽ ko phải lo nếu máy chủ bị sập thì sẽ ko vào được nhé . Hơn nữa nó cũng sẽ nhanh hơn do mạng sẽ tính toán băng thông vì thế việc tải dữ liệu sẽ từ máy chứa dữ liệu gần nhất chứ ko bị cố định như trong mô hình client server .
Chúng ta có thể tổng hợp lại một số lợi ích sau :
- Tránh sự phụ thuộc vào máy chủ
- Không còn mô hình tập trung
- Giảm bớt chi phí ( cho cả nhà phát triển ví dụ tiền server ,...)
- Cải tiến về tốc độ ( cái này càng nhiều ng dùng thì càng nhanh giống như BitTorrent ý )
Nó hoạt động như thế nào ?
Đầu tiên chúng ta sẽ phải nhìn nhận lại mọi thứ đó là thay vì các kiểu đối tượng mà server lưu trữ như ảnh, text, videos ,... thì trên IPFS chúng sẽ được lưu dưới dạng mã hash hết ( còn gọi là đối tượng IPFS ). Ý tưởng đó là nếu trình duyệt của bạn muốn truy cập một trang nào đó trên IPFS thì chỉ cần đưa ra mã hash rồi mạng sẽ tìm máy có lưu trữ dữ liệu vs cùng mã hash và sau đó tải trang đó về từ máy tính đấy về cho bạn .
Vì thế IPFS sẽ có 2 phần :
- Xác định tệp có địa chỉ nội dung (giá trị hash của tệp đó )
- Tìm nó ( khi bạn có đoạn hash của file hay trang cần tải mạng sẽ tìm và connect tới máy tốt nhất để tải xuống cho bạn )
Đó là kết quả của một P2P overlay cung cấp cho bạn khả năng định tuyến nhanh
Sâu hơn thì các đối tượng IPFS tạo thành một cấu trúc dữ liệu được xác thực bằng mật mã được gọi là DAG Merkle và cấu trúc dữ liệu này có thể được sử dụng để mô hình hóa nhiều cấu trúc dữ liệu khác. Mình sẽ giới thiệu các đối tượng IPFS và Merkle DAG và đưa ra các ví dụ về các cấu trúc có thể được mô hình hóa bằng IPFS.
IPFS Objects
Phần này có thực hành một chút chút vì thế bạn có thể tại IPFS tại đây
Một đối tượng IPFS là một cấu trúc dữ liệu với hai trường:
- Data : một đống dữ liệu nhị phân không cấu trúc có kích thước <256 kB.
- Links : một mảng các cấu trúc Links. Đây là các liên kết đến các đối tượng IPFS khác.
Cấu trúc của Link có ba trường :
- Name : Tên của Link
- Hash : hàm băm của đối tượng IPFS được link đến
- Size : kích thước tích lũy của đối tượng IPFS được liên kết, bao gồm cả các liên kết sau của nó ( Trường size chủ yếu được sử dụng để tối ưu hóa mạng P2P )
Các đối tượng IPFS thường được gọi bằng hàm băm Base58 của chúng .
Hình minh họa
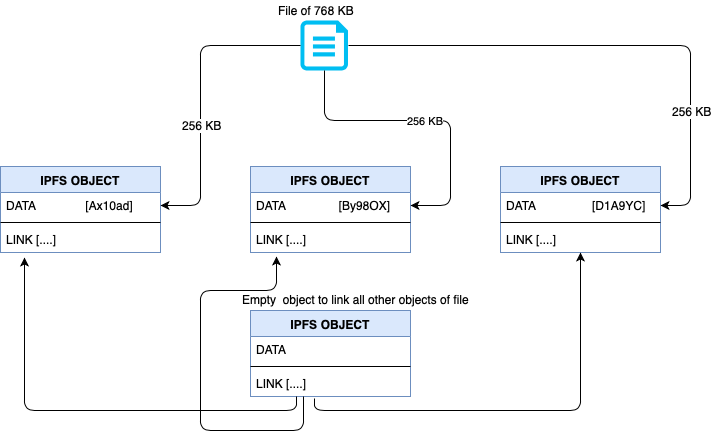
Merkle DAG
DAG ( Direct Acyclic Graph ) là một dạng graph mà mỗi node sẽ link tới node khác và ko cho phép việc nối các node thành vòng . Ví dụ A->B->C là một thể hiện của DAG mà trong đó B là con của A hoặc có thể nói rằng A liên kết với B . Chúng ta nói node mà không là con của một node nào khác là DAG root nodes .
Merkle-DAG là DAG trong đó mỗi nút có một id danh và đây là kết quả của việc hash nội dung của node đó . Điều này mang lại một số điều cần chú ý :
- Các node con sẽ phải được sinh ra trước thì node cha mới có id để link đến .
- Mỗi node trong Merkle-DAG là gốc của một sub Merkle-DAG
- Các nút Merkle-DAG là không thể thay đổi . Bất kỳ thay đổi nào trong một nút sẽ làm thay đổi id của nó và do đó ảnh hưởng đến tất cả các phần tử trong DAG
Các bạn có thể xem qua vè hình minh họa về merkle tại đây
Thực hành một chút cho dễ hiểu :
Khi các bạn cài đặt thành công ipfs về máy mình . Sau đó hãy thử tải cái gì đó lên mạng nào . Mình sẽ tải đúng cái ảnh bìa của bài này lên xem .
Thử tải gì đó lên mạng
ipfs add ipfs.jpeg
## ket qua
added QmVMFbKgoG2r1BZQW5hpiYUAt2ZTJFFBs6tW6UCRqeKRrM ipfs.jpeg
Giờ thì file ảnh đã được upload lên mạng và các máy khác có thể tải về bằng lệnh
ipfs cat QmVMFbKgoG2r1BZQW5hpiYUAt2ZTJFFBs6tW6UCRqeKRrM
hoặc có thể xem online bằng cách vào bằng các gateway với path cuối là mã hash :
ví dụ : https://gateway.ipfs.io/ipfs/QmVMFbKgoG2r1BZQW5hpiYUAt2ZTJFFBs6tW6UCRqeKRrM
( đại loại họ có máy chủ để mình vào xem mà người dùng ko cần phải tải ipfs, cũng do cách tiếp cận cồng kềnh nên ít ng dùng quá mà  . hơn nữa việc queri cũng hay bị timeout lắm )
. hơn nữa việc queri cũng hay bị timeout lắm )
Về cơ bản để ra được đến đoạn mã hash sẽ như thế này :

Có 2 bước chạy ngầm ở dưới đó là Raw và Digest
Khi chúng ta tải một hình ảnh lên đầu tiên ảnh sẽ chuyển thành dữ liệu RAW ( dạng nhị phân ) mà máy tính có thể hiểu được. Bây giờ, để làm cho nó có thể đánh địa chỉ dựa vào nội dung ( content-addressable) , vì thế phải đưa ra một phương pháp để chúng ta có thể chuyển đổi dữ liệu hình ảnh này thành id xác định duy nhất cho nội dung của nó.
Công việc tiếp theo là của hàm băm . Hàm băm lấy dữ liệu (bất kỳ dữ liệu nào từ văn bản, ảnh, v.v.) làm đầu vào và cung cấp cho chúng ta một đầu ra (Digest) duy nhất . Nếu chúng ta thay đổi ngay cả một pixel trong hình ảnh này thì đầu ra sẽ khác. Điều này cho thấy thuộc tính chống giả mạo của nó. Vì vậy, nếu bạn chuyển hình ảnh này cho bất kỳ ai, anh ấy / cô ấy có thể kiểm tra xem ảnh nhận được có bị giả mạo hay không .
Sau khi chúng ta chuyển dữ Raw vào hàm băm SHA256 và nhận được Digest duy nhất. Bây giờ, chúng ta cần chuyển đổi Digest này thành CID (Content Identifier). CID này là những gì IPFS sẽ tìm kiếm khi chúng ta cố gắng download lại hình ảnh. Để làm điều này, IPFS sử dụng một thứ gọi là Multihash. Để nói nhiều hơn về nó mình sẽ đề cập trong bài viết sau .
Quay lại chút để minh họa cho các trường lý thuyết bên trên chúng ta thử chạy lệnh
ipfs object get <hash>
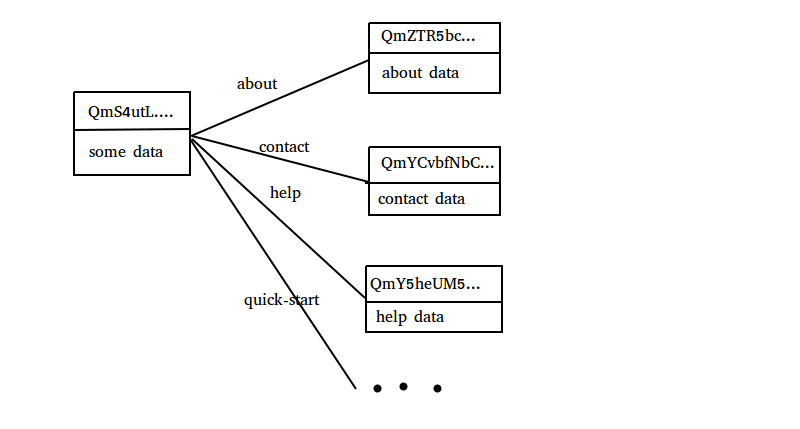
đối vs cái ảnh chúng ta vừa tải lên thì nó ko đc link nhiều nên sẽ chỉ thấy trường "Data" thôi còn "Links" thì rỗng Nhưng đối vs những hash như phần readme ban đầu khi ta init thành công
ipfs object get QmS4ustL54uo8FzR9455qaxZwuMiUhyvMcX9Ba8nUH4uVv
Bạn sẽ thấy phần Link sẽ rất dài vì mỗi file trong đấy như about , contact ,... đc link đến những file khác nhau trên mạng .
Data và Links của các đối tượng IPFS được lưu vào cấu trúc dữ liệu Merkle DAG ( viết tắt của Directed Acyclic Graph ) . Để dễ hình dung thì nó giống như thế này
hình minh họa cho get file readme ban đầu
File systems
IPFS có thể dễ dàng biểu diễn một hệ thống tệp bao gồm các tệp và thư mục
Small Files
Một file nhỏ được định nghĩa là < 256kB được biểu thị bằng một đối tượng IPFS với trường Data là nội dung tệp và mảng Links rỗng.
Lưu ý rằng tên tệp không phải là một phần của đối tượng IPFS, vì vậy hai tệp có tên khác nhau và cùng một nội dung sẽ có cùng biểu diễn đối tượng IPFS và do đó có cùng hàm băm
ví dụ chúng ta thử tải 1 file nội dung Hello World lên xem . Tương tự như trên thì chạy
ipfs object get QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG
## Ket Qua
{“Links”: [],
“Data”: “\u0008\u0002\u0012\rHello World!\n\u0018\r”}

Large Files
Được định nghĩa là những file >256kB được biểu thị bằng một danh sách các liên kết đến các file <256 kB.
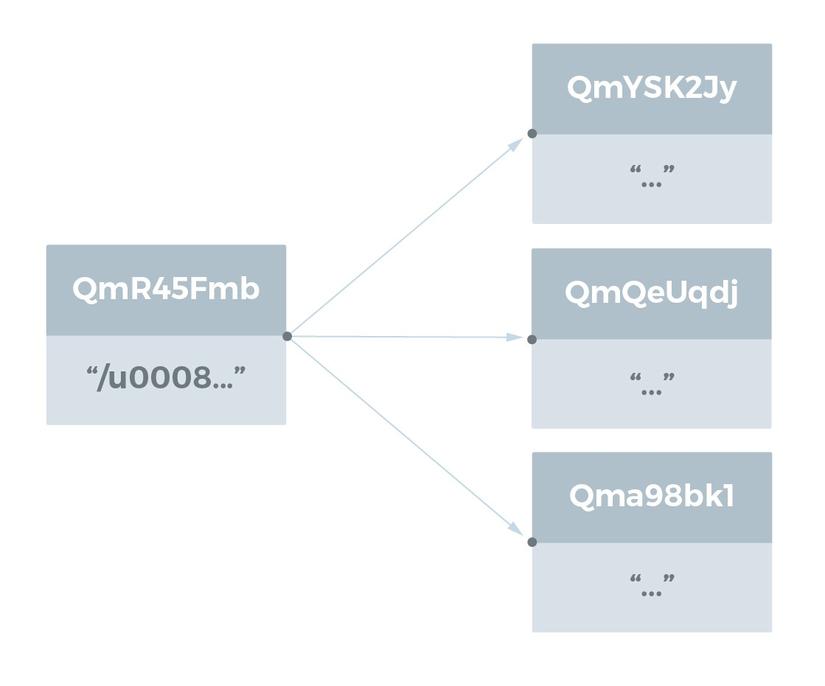
Directory Structures
Cũng giống như large file chúng ta có thể vào từng thư mục bằng cách thêm các path đến thư mục đó đằng sau hash . Tiếp tục là nếu trong một số file có cùng file có nội dung giống nhau thì sao . Đó cũng chính là cái hay của hash, những file có cùng nội dung sẽ có hash giống nhau vì thế chỉ cần link đến 1 chỗ thay vì sao lưu nhiều cái giống nhau . Ví dụ như hình bên dưới
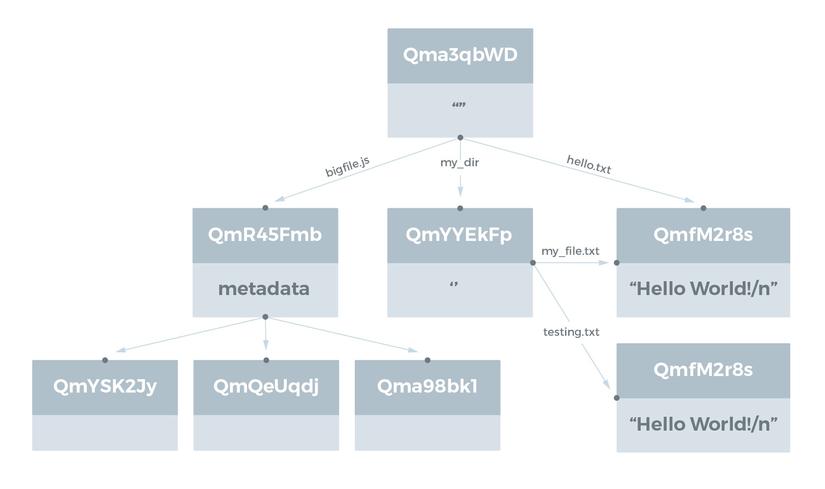
Versioned File Systems
Về cơ bản nó cũng giống git thôi khác là nó phân tán chứ ko nằm trên máy chủ của git. Ý tưởng cơ bản là nó sẽ hash các file nếu có sửa đổi nó sẽ ra một hash khác còn ko thì nó vẫn sẽ link đến chỗ file cũ .
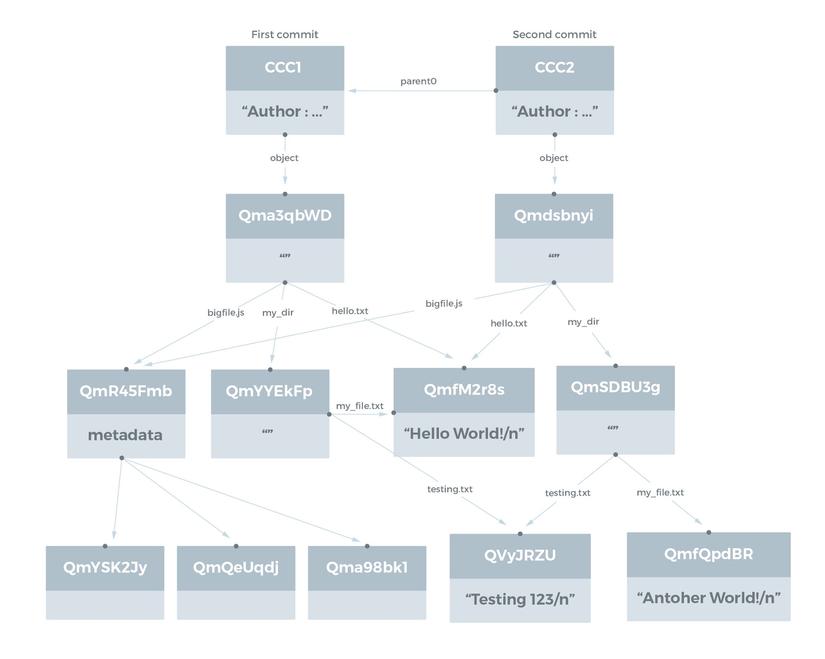
Công việc cố gắng hiểu được công nghệ của một cái gì đó giống như đào vàng vậy vì thế bài viết sau mình sẽ cố gắng đi sâu hơn vào cơ chế hoạt động ipfs cũng như các khái niệm khác của ipfs
Bài viết sau : to bi con tờ niu
Reference
All rights reserved
