Nhận diện và đối đầu với data drift trong MLOps pipeline
Có bao giờ bạn tự hỏi tại sao model machine learning có thể hoạt động cực kỳ tốt trong quá khứ, nhưng bỗng dưng lại trở nên "cùi bắp" theo thời gian không? Đó là lúc mà khái niệm data drift được ra đời trong MLOps concept, tức là dữ liệu đã bị thay đổi và không còn đúng với model cũ. Vậy thì, khi mà việc train model được thực hiện lặp đi lặp lại (trong một MLOps pipeline), bằng cách nào thì ta tự động phát hiện ra được và cảnh báo được cho các anh Data Scientist?
"Sông có lúc, data có khúc" - đúng rồi đấy, data luôn chỉ có khúc thôi, vì nó là batching/streaming mà. (j4f)

Data drift là gì nhỉ?
Cách tiếp cận đơn giản: Vạn vật luôn đổi thay và dữ liệu của ta cũng thế, trong một MLOps pipeline, mình hiểu đơn giản là quá trình lấy data mới và huấn luyện các mô hình học máy một cách tự động. Và vì bộ siêu tham số (hyper parameters) đã được tinh chỉnh để fit với một tập data duy nhất (thường các anh DS hay thực hiện trong file csv import lên notebook), nhưng data mới được cập nhật liên tục hàng năm/tháng/ngày/giờ/phút/giây, thì không có gì đảm bảo rằng tính chất toán học của tập dữ liệu mới này sẽ toàn vẹn được như cũ?
Ví dụ cho việc thay đổi:
- Dữ liệu kinh doanh bị ảnh hưởng bởi các sự kiện đột ngột (như COVID-19,...)
- Dữ liệu về chiều cao của thanh thiếu nên Việt nam năm 2000 với năm 2020 sẽ khác nhau, vì bây giờ các bạn được ăn uống đầy đủ hơn lúc trước, nên chiều cao cũng phát triển hơn.
- ... Rất nhiều trường hợp khác dữ liệu bị thay đổi về các tính chất.
Và sự thay đổi tính chất đó gọi chung là... data drift.
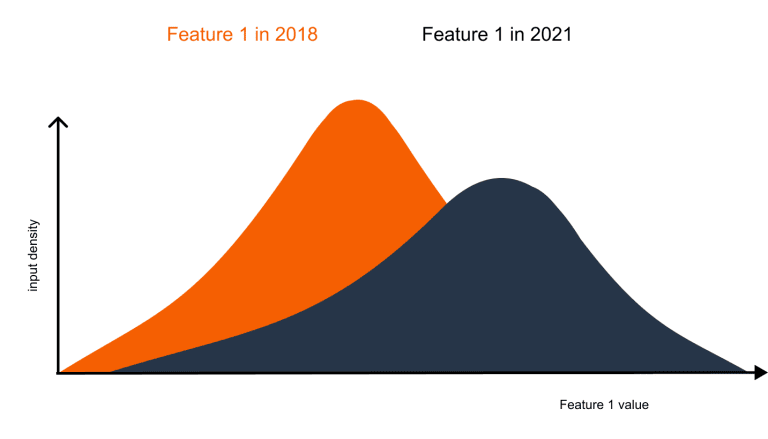
Hiểu theo mặt thống kê, data drift đơn giản là phân phối của dữ liệu bị trượt, hoặc bị thay đổi theo thời gian, ví dụ như mô hình bạn train năm 2018 hội tụ và generalize tốt với dữ liệu 2018, không có nghĩa dữ liệu sẽ có cùng ý nghĩa thống kê với của năm 2021. Và mục tiêu của mình là phải có một hệ thống tự động nhận biết được thời điểm 2021, tức là thời điểm dữ liệu bị thay đổi tính chất, và thực hiện việc cảnh báo (alert) cho các MLOps Engineer và Data Scientist.
Phương pháp tối ưu để phát hiện data drift
Có rất nhiều phương pháp để phát hiện data drift, nhưng phương pháp vừa có ý nghĩa về mặt thống kê, vừa có kết quả thực tế, hiệu quả và giải thích được đó chính là sử dụng một kiểm định tên là kiểm định Kolmogorov-Smirnov (K-S Test) , có người còn gọi là Goodness-of-Fit Test.
Nghe lạ quá nhỉ? Nhưng về ý nghĩa toán học - thống kê nó không có gì cao siêu cả, chỉ đơn giản là kiểm định xem hai phân phối của hai mẫu có khác biệt tính chất với nhau không.
Ta có một metric để đo lường sự khác biệt phân phối giữa hai mẫu, biểu diễn như sau:
Trong đó:
- là hàm phân phối tích lũy của tập data trong quá khứ.
- là hàm phân phối tích lũy của tập data mới.
Nếu giá trị càng lớn, càng xảy ra data drift.
Kiểm định dành cho hai mẫu:
Vậy, data bị drift khi ta bác bỏ khi của kiểm định Kolmogorov-Smirnov (K-S) nhỏ hơn mức ý nghĩa đã chọn (ví dụ chẳng hạn). Tính liên hệ như nào với thì mình sẽ không đi sâu ở bài viết này để tránh việc dài dòng. Giờ thì... thực hành thôi!
Sử dụng Python để detect data drift
- Thư viện mà mình cần dùng ở đây hết sức quen thuộc, đó là
scipy, khỏi phải giới thiệu nhiều vì package này quá quen thuộc với các bạn data science rồi, cho những ai chưa biết thì đây là một thư viện chứa rất nhiều hàm thống kê của Python. Cách cài đặt đơn giản bằngpipthôi:
pip install scipy
- Sử dụng
ks_2sampnằm trong modulescipy.statsnhư sau:
from scipy import stats
test = stats.ks_2samp(df[column], df_new[column])
- Ở đây mình đang thực hiện việc test ở hai dataframe là
df(dữ liệu quá khứ) vàdf_new(dữ liệu nóng hổi vừa thu thập được). - Để kiểm định xem 1 feature / column có đảm bảo tính chất hay không, mình sẽ thực hiện như trên, kết quả của function
ks_2samptrả về sẽ được gán vào biếntest
test[1]chính là của kiểm định, mình đang dùng mức ý nghĩa:
Nếu , tức là sẽ bác bỏ , đồng nghĩa với việc data bị drift.
if test[1] < 0.05:
print("Data drift at column: ", column)
- Chỉ vậy thôi đó, ta có thể đóng function lại code trên để tiện dùng trong MLOps pipeline, và tiếp đến phần sau, mình sẽ ví dụ việc tích hợp detect tự động như nào nhé!
Tích hợp detect vào MLOps pipeline
Ở đây mình sẽ ví dụ như là 1 task của Airflow nhé.
- Trong task này, mình sẽ duyệt qua từng column, nếu column vào bị drift, thì ngay lập tức mail cho data scientist, để thực hiện tune parameter nếu cần thiết, hoặc train model lại với data mới,...
- Đồng thời cũng sẽ return True nếu gặp column drift, và return False nếu không gặp column drift nào.
from airflow.decorators import task
from scipy import stats
@task.python(
show_return_value_in_logs=True,
)
def detect_drift() -> bool:
# NOTE: Download new data from S3 (bước fetch df and df_new)
drift_columns = []
for column in df.columns:
test = stats.ks_2samp(df[column], df_new[column])
if test[1] < 0.05:
drift_columns.append(column)
if drift_columns:
print("Data drift detected in columns: ", drift_columns)
mail_to_data_scientist()
return True
return False
Những phương pháp cần làm sau khi đã phát hiện được data drift
Sau khi biết data bị drift thì người ta thường làm gì nhỉ, thật ra thì có nhiều cách lắm, nhưng xoay quanh vẫn là tìm cách để huấn luyện (train) lại mô hình (model):
- Train mô hình với data gộp giữa cũ và mới.
- Train mô hình với chỉ mỗi data mới.
- Train mô hình với bộ siêu tham số mới (cần được tuning lại bởi data scientist).
- ....
- Và best practice thì thường là không có, mà sẽ phụ thuộc vào quyết định của các data scientist, là những người hiểu rõ nhất về tính chất của dữ liệu mà họ đang làm.
Kết luận
Đừng quên rằng trong thế giới mà data thay đổi liên tục, hãy luôn sẵn sàng để tuning model và optimize bất cứ khi nào bị réo, vì như đã nói: "sông có lúc, data có khúc".
References
All rights reserved
