Nhận diện khuôn mặt sử dụng KNN AutoFaiss
Bài đăng này đã không được cập nhật trong 4 năm

1. Ý tưởng
Bài toán nhận diện khuôn mặt là một bài toán phổ biến trong AI, nó có tên tiếng anh thường gọi là Face recognition:
- Input: 1 ảnh chứa mặt người (có thể là một người hoặc nhiều hơn)
- Output: xuất ra tên của người tương ứng có trong k người ở cơ sở dữ liệu.
Thường thì những bài toán nhận diện khuôn mặt sẽ có nhiều phương pháp phân loại quen thuộc như sử dụng VggFace, Facenet, Openface. Trong bài viết này, mình sẽ không dùng phân loại mà dùng phương pháp tìm kiếm. Tức là với ảnh đầu vào, sau khi phát hiện được khuôn mặt, ta sẽ so sánh độ tương đồng của nó với các khuôn mặt có trong cơ sở dữ liệu, cái nào giống nhất thì lấy ra. Phương pháp sẽ detect face bằng MTCNN và dùng AutoFaiss như flowchat sau:
 Đọc qua thì thấy là chúng ta cần phải so sánh vector đặc trưng của ảnh khuôn mặt đầu vào với cả trăm chục nghìn bức ảnh trong database, so sánh và tìm kiếm như thế rất lâu và mất thời gian. Tuy nhiên với AutoFaiss điều thì nhược điểm đó khắc phục được. Để lý giải cho điều đó chúng ta hãy đọc phần giới thiệu về AutoFaiss ở dưới đây.
Đọc qua thì thấy là chúng ta cần phải so sánh vector đặc trưng của ảnh khuôn mặt đầu vào với cả trăm chục nghìn bức ảnh trong database, so sánh và tìm kiếm như thế rất lâu và mất thời gian. Tuy nhiên với AutoFaiss điều thì nhược điểm đó khắc phục được. Để lý giải cho điều đó chúng ta hãy đọc phần giới thiệu về AutoFaiss ở dưới đây.
2. Giới thiệu về AutoFaiss
Autofaiss tạo và điều chỉnh các index (chỉ mục) KNN được lượng tử hóa để tìm kiếm một cách hiệu quả độ tương đồng với mức sử dụng bộ nhớ thấp.

- KNN-k near-Neighbor (K láng giềng): Một thuật toán đơn giản bao gồm việc tìm kiếm k vectơ tương đồng gần nhất với một vectơ truy vấn dựa trên điểm số được đưa ra bởi một hàm tính độ tương đồng.
- Index: Một cấu trúc dữ liệu chứa một phiên bản đã được biến đổi của các vectơ ban đầu. Chỉ số KNN được thiết kế để chạy thuật toán KNN một cách tối ưu.
- Faiss: một thư viện (nằm trong autofaiss) để tìm kiếm độ tương đồng hiệu quả và phân cụm các dense vector (vector dày đặc). Nó triển khai nhiều thuật toán hiện đại lập chỉ mục (index) KNN khác nhau có khả năng điều chỉnh cao.
2.1 Vấn đề và giải pháp
Để tìm kiếm các vector tương đồng nếu so sánh vector truy vấn với toàn bộ tất cả các vector thì chi phí tìm kiếm sẽ vô cùng lớn về thời gian chạy, về không gian bộ nhớ. KNN ước lượng tìm kiếm láng giềng gần nhất để giảm độ phức tạp của thuật toán. Tìm kiếm xấp xỉ láng giềng gần nhất trong một thời gian thích hợp, thì lượng dữ liệu được lưu trữ trong RAM có thể bị cấm và không tương thích với các ứng dụng có thể mở rộng với hàng trăm nghìn vector.
Và để giải quyết vấn đề này, Faiss triển khai lượng tử hóa (quantize) dựa trên các thuật toán, là các loại thuật toán mới có thể làm giảm đáng kể bộ nhớ RAM đã sử dụng trong khi vẫn cân bằng tốt recall score và thời gian truy vấn.
Lượng tử hóa (quantize): chia không gian vector ban đầu thành nhiều không gian con (sub space) nhỏ hơn. Sau đó, đối với mỗi không gian con này, chúng ta sẽ tìm thấy 256 tâm cụm sẽ đại diện tốt cho dữ liệu bên trong. Mỗi phần của vector con (sub vector) trong không gian con sẽ được liên kết với số tương ứng với cụm gần nhất. Do đó, thay vì lưu trữ một floating-point sub-vector, ta chỉ cần lưu trữ một số nguyên và thủ thuật này làm giảm rất nhiều dung lượng RAM cần thiết để lưu trữ các vector.
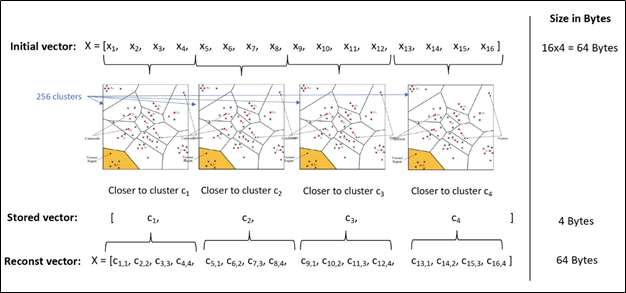
2.2 Sử dụng AutoFaiss
Có hàng trăm tổ hợp thuật toán có thể được sử dụng trong Faiss và mỗi tổ hợp có thể yêu cầu tối đa 6 hyperparameters để xác định cách xây dựng index. Ngoài ra, có những hyperparameters khác cần được thiết lập để tối ưu hóa sự cân bằng giữa recall và thời gian tìm kiếm trên index. Đây là một điều phức tạp và khó khăn. Các nghiên cứu đã được thực hiện để điều chỉnh các thuật toán tạo lập index, mục tiêu tìm ra sự cân bằng tốt nhất giữa tốc độ truy vấn, kích thước index, recall và thời gian xây dựng index. Và Autofaiss được tạo ra, một thư viện tạo lập index, nhằm xây dựng các index tối ưu với tốc độ truy vấn và RAM. Lệnh và parameters điều chỉnh autofaiss:

- embeddings path: đường dẫn đến thư mục img_emb có chứa file img_emb_0.npy gồm các ảnh database được embedding dưới dạng numpy
- index_path: đường dẫn đến thư mục để lưu ra file knn.index chứa chỉ mục các ảnh database.
- index_infos_path: đường dẫn đến thư mục để lưu ra file infos.json chứa thông tin của knn.index.
- metric_type: độ đo tương đồng có thể là "ip" cho inner product, "l2" cho euclidian distance
- max_index_query_time_ms: thời gian truy vấn tối đa (ms)
- max_index_memory_usage: kích thước tối đa của file index đã tạo.
3. Code nhận diện khuôn mặt với AutoFaiss
3.1 Tập ảnh cơ sở dữ liệu
Bộ dữ liệu ở đây mình sử dụng là Celebrity dataset gồm 150 thư mục với mỗi thư mục là ảnh chân dung của một người nổi tiếng. Thư mục train như sau:
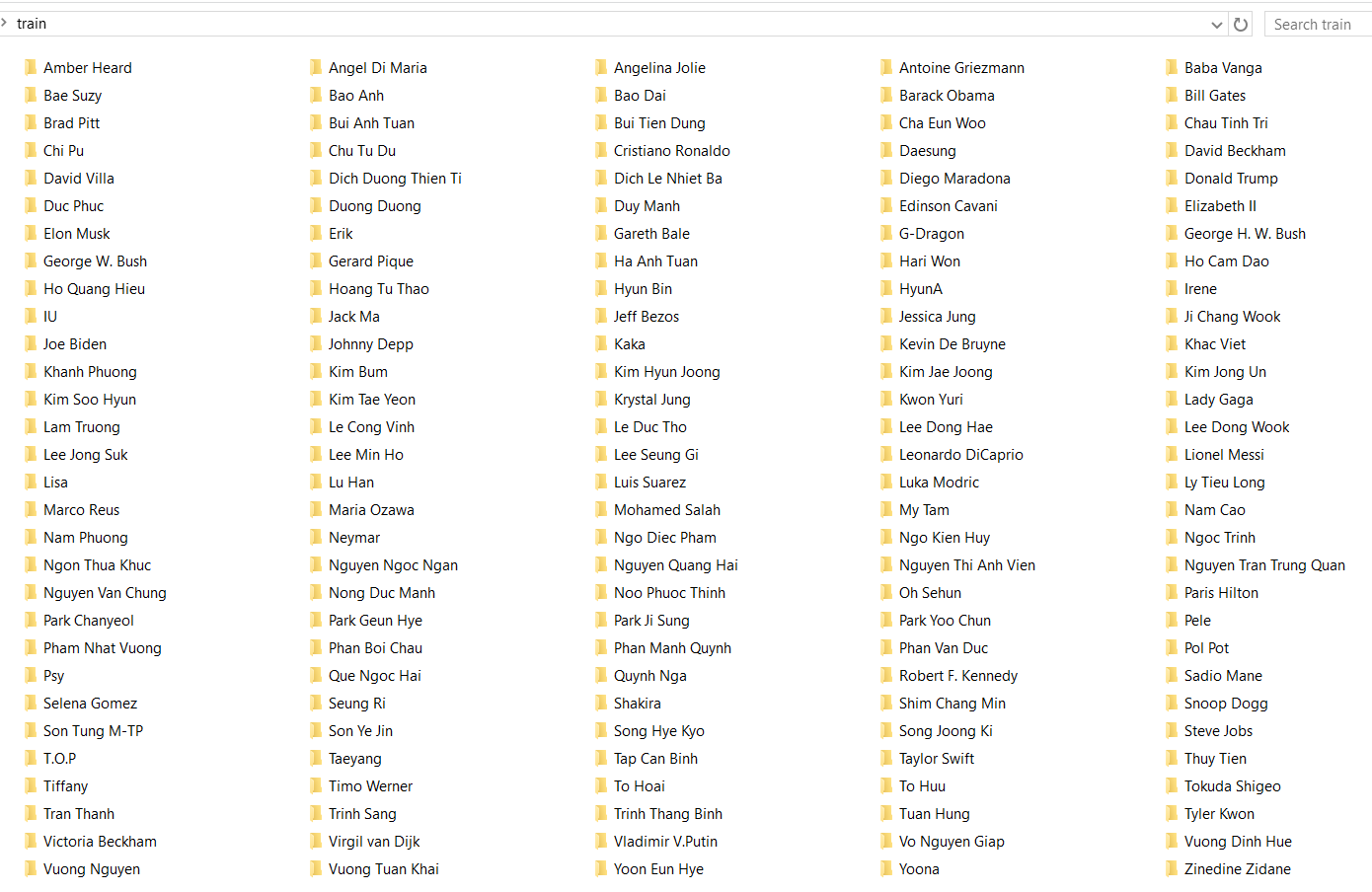
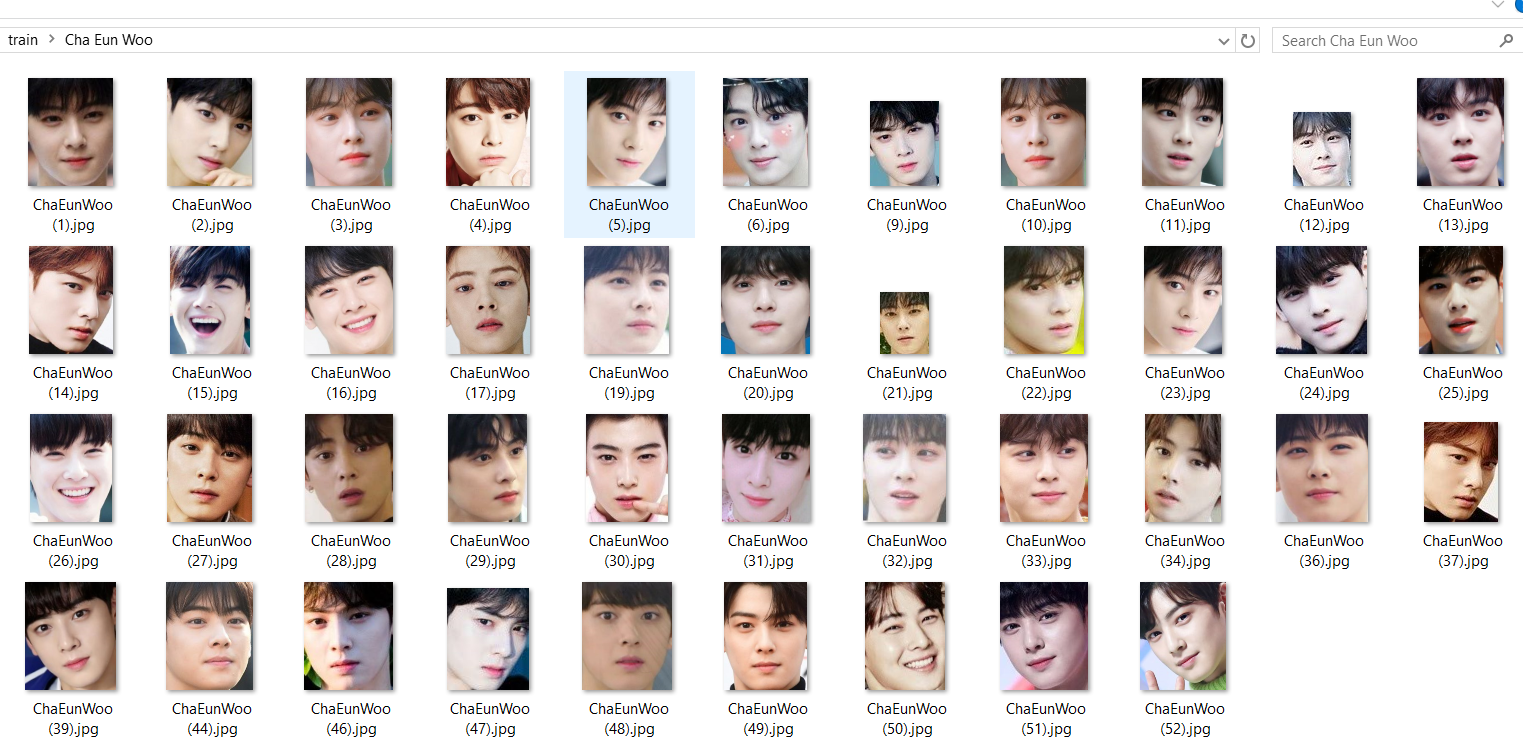
 Mỗi bức ảnh chúng ta sẽ tiền xử lý ảnh, cắt sát phần khuôn mặt của người trong ảnh như dưới đây:
Mỗi bức ảnh chúng ta sẽ tiền xử lý ảnh, cắt sát phần khuôn mặt của người trong ảnh như dưới đây:
Để tiền xử lý dữ liệu ảnh kiểu này một cách dễ dàng hơn , ta có thể sử dụng tool tự động cắt khuôn mặt từ ảnh: https://viblo.asia/p/xay-dung-cong-cu-tu-dong-cat-anh-chi-chua-khuon-mat-su-dung-mtcnn-va-pyqt5-ORNZqpd8K0n#_22-giao-dien-ung-dung-voi-pyqt5-3
Sau đó chúng ta kiểm tra lại và xóa đi những hình ảnh mà tool cắt bị lỗi, thường có thể 2,3 hình trong một folder có nhiều hình:

3.2 Tạo chỉ mục KNN cho tập ảnh dữ liệu
Với phần tạo KNN index này mình sẽ code trên Google Colab. Đầu tiên là nén tập ảnh dữ liệu và tải lên Google drive, sau đó kết nối Google Colab và Google drive. Đổi tên thư mục mặc định "sample_data" thành "data":
Thực hiện giải nén tập ảnh dữ liệu vào thư mục data ở trên:
from google.colab import drive
drive.mount('/content/drive/', force_remount=True)
from google.colab import drive
drive.mount('/content/drive')
!pip install unrar
!unrar x "/content/drive/MyDrive/train.rar" "./data"
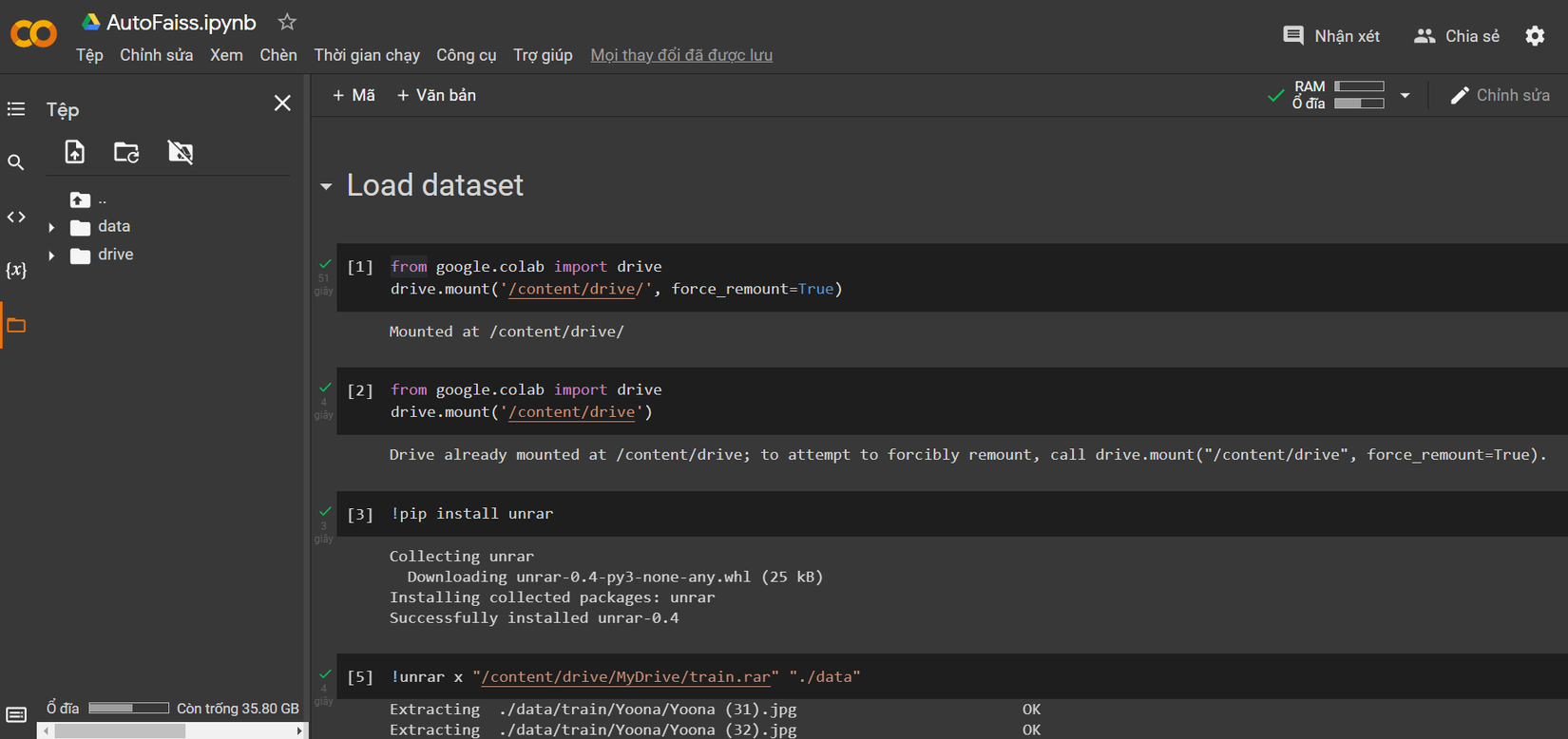
Sau đó, tạo Image Embedding, để embedding cho hình ảnh AutoFaiss sử dụng Clip Retrieval của Clip OpenAI. Install Clip Retrieval và AutoFaiss và thực hiện embedding, chọn thư mục input là tập ảnh đầu vào, và nơi lưu thư mục embedding_folder :
!pip install clip-retrieval autofaiss
!clip-retrieval inference --input_dataset ./data/train/ --output_folder ./data/embedding_folder
Sau khi thực hiện xong, ta sẽ có được thư mục embedding_folder gồm 2 thư mục nhỏ chứa các file:
- img_emb/img_emb_0.npy: chứa hình ảnh nhúng dưới dạng numpy
- metadata/metadata_0.parquet: chứa đường dẫn hình ảnh, chú thích và siêu dữ liệu
![image.png]()
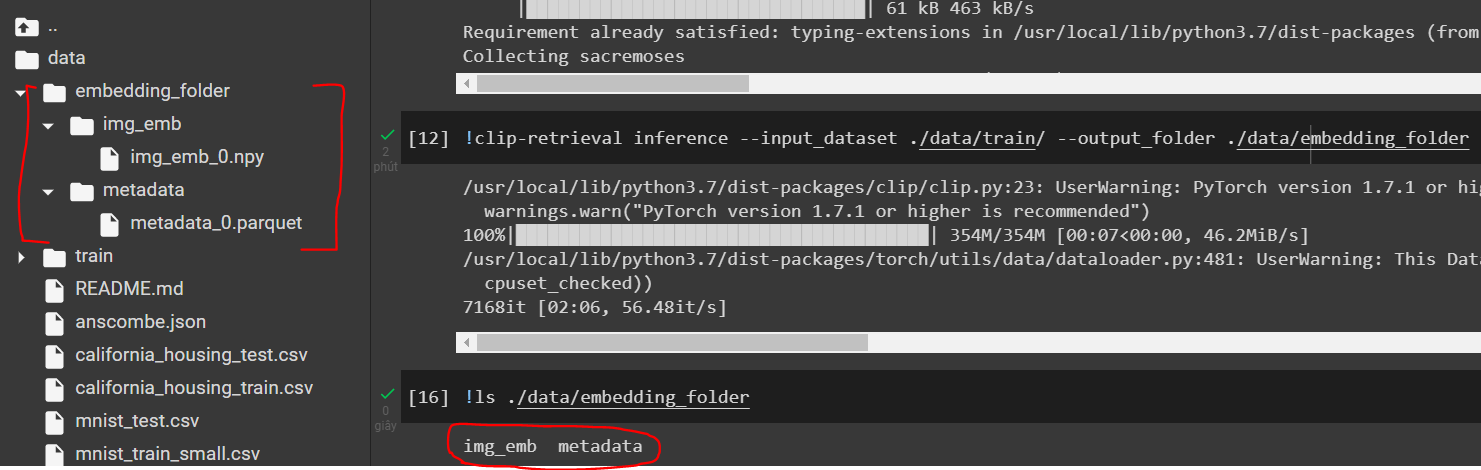
Cuối cùng là xây dựng chỉ mục KNN với AutoFaiss cho tập ảnh, lựa chọn đường dẫn và các thông số phù hợp:
!autofaiss build_index --embeddings="./data/embedding_folder/img_emb" \
--index_path="./data/knn.index" \
--index_infos_path="./data/infos.json" \
--metric_type="ip" \
--max_index_query_time_ms=10 \
--max_index_memory_usage="4GB"
Ta sẽ được 2 file knn.index và infos.json trong thư mục data.
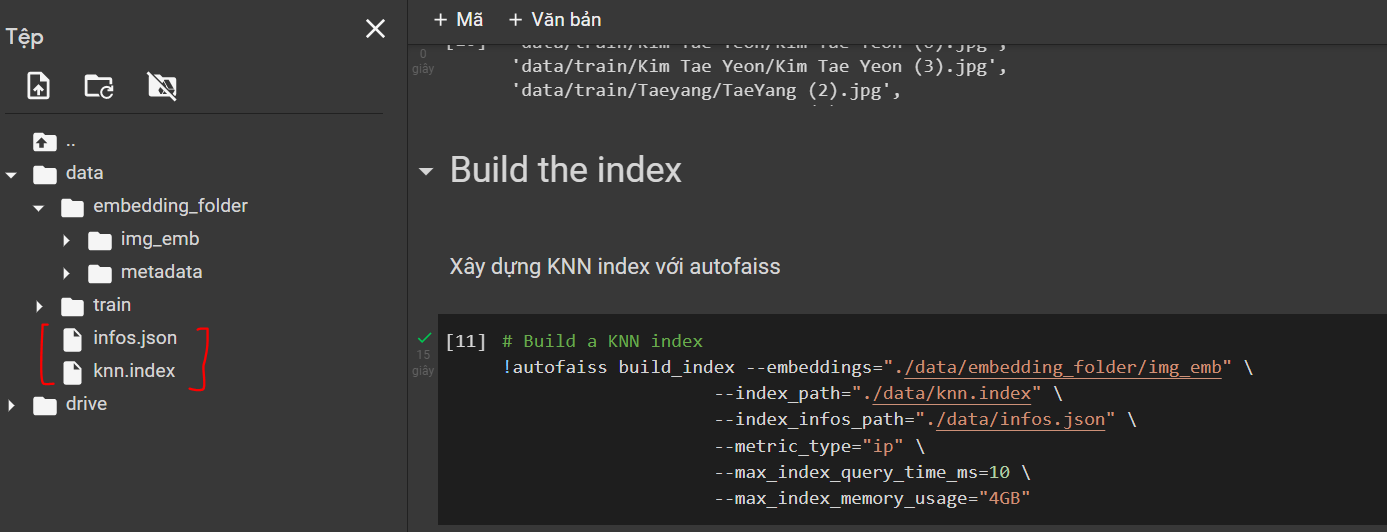
3.3 Phát hiện khuôn mặt và tìm kiếm
Với việc đã có được các file cần thiết được tạo ở trên, bây giờ chúng ta sẽ sử dụng Visual Studio Code để thực hiện project với các folder và file sau:
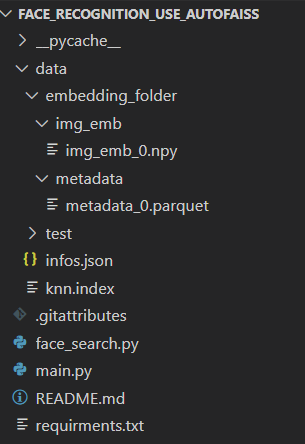
Ta tạo thư mục data y hệt thư mục trên Google Colab ở trên, mục đích để đường dẫn ảnh lưu trữ không bị sai lệch, ta sẽ lấy đường dẫn tương đối bắt đầu từ ./data/.. để thực hiện lấy ra hình ảnh trong dataset có kết quả giống nhất với ảnh truy vấn. Tiến hành download 4 file metadata_0.parquet, img_emb_0.npy, knn.index và infos.json, tải cả 4 file với mục đích lưu trữ lại kết quả của quá trình build KNN index, còn bây giờ chúng ta sẽ chỉ sử dụng đọc 2 file là metadata_0.parquet và knn.index: ind chứa chỉ mục KNN ảnh database được tạo bởi AutoFaiss, image_list chứa đường dẫn hình ảnh.
# Read file KNN index
df = pd.read_parquet(".\data\embedding_folder\metadata\metadata_0.parquet")
image_list = df["image_path"].tolist()
ind = faiss.read_index(".\data\knn.index")
Đầu vào là một ảnh có chứa người (có thể 1 hoặc nhiều người), việc của chúng ta là nhận biết những khuôn mặt người đó là ai tương ứng trong cơ sở dữ liệu mà ta có. Sau khi phát hiện được khuôn mặt rồi ta đưa khuôn mặt đó vào tìm kiếm trong cơ sở dữ liệu. Đầu tiên là phải preprocess, encode image và image embeddings cho ảnh khuôn mặt truy vấn, ta sử dụng model Clip OpenAI:
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
Viết hàm search_face() thực hiện tìm kiếm ảnh khuôn mặt trong database tương đồng với ảnh khuôn mặt truy vấn. Dùng phương thức search() của KNN index, tìm ra ảnh tương đồng nhất với ảnh truy vấn. Giá trị D là độ tương đồng của ảnh tìm được với ảnh truy vấn, giá trị I là đường dẫn của ảnh đó trong database. Đặt điều kiện nếu tìm được ảnh kết quả có độ tương đồng lớn hơn 0.8 thì sẽ cho ra kết quả. Trả về kết quả là tên thư mục ảnh(tên người) của ảnh kết quả.
# Search image
def search_face(image):
image_tensor = preprocess(image)
image_features = model.encode_image(torch.unsqueeze(image_tensor.to(device), dim=0))
image_features /= image_features.norm(dim=-1, keepdim=True)
image_embeddings = image_features.cpu().detach().numpy().astype('float32')
D, I = ind.search(image_embeddings, 1)
if D[0][0] > 0.8:
name = os.path.basename(os.path.dirname(image_list[I[0][0]]))
print("Name:",os.path.basename(os.path.dirname(image_list[I[0][0]])))
print("path:",image_list[I[0][0]])
print("Similarity:",D[0][0])
return name
- Code hoàn chỉnh của file face_search.py:
import faiss
import torch
import clip
import os
import pandas as pd
# Read file KNN index
df = pd.read_parquet(".\data\embedding_folder\metadata\metadata_0.parquet")
image_list = df["image_path"].tolist()
ind = faiss.read_index(".\data\knn.index")
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# Search image
def search_face(image):
image_tensor = preprocess(image)
image_features = model.encode_image(torch.unsqueeze(image_tensor.to(device), dim=0))
image_features /= image_features.norm(dim=-1, keepdim=True)
image_embeddings = image_features.cpu().detach().numpy().astype('float32')
D, I = ind.search(image_embeddings, 1)
if D[0][0] > 0.8:
name = os.path.basename(os.path.dirname(image_list[I[0][0]]))
print("Name:",os.path.basename(os.path.dirname(image_list[I[0][0]])))
print("path:",image_list[I[0][0]])
print("Similarity:",D[0][0])
return name
Phần tìm kiếm khuôn mặt như vậy là xong, giờ chúng ta chỉ việc detect face từ ảnh và gọi hàm search_face() lấy kết quả tên người và display hình ảnh output. Do preprocess model Clip openAI sử dụng PIL để đọc ảnh mà MTCNN() lại sử dụng Opencv để đọc ảnh nên chúng ta sẽ đọc ảnh truy vấn bằng cả PIL.Image và cv2. Sau đó detect faces với MTCNN, có được tọa độ (x,y), (width,height) của khuôn mặt truy vấn và vẽ ô chữ nhật phát hiện khuôn mặt. Ta dùng PIL.crop để cắt ra ảnh khuôn mặt truy vấn với tọa độ đã được xác định và cho vào hàm search_face() ở trên để lấy ra kết quả tên người và putText lên ảnh output. Hàm tagging_image() thực hiện phần này sẽ như sau:
# Detect face, search face and display reuslts
detector = MTCNN()
def tagging_image(path):
im = Image.open(path)
image = cv2.imread(path)
faces = detector.detect_faces(image)
print("Results:")
for face in faces:
if face['confidence'] > 0.8:
bounding_box = face['box']
cv2.rectangle(image,(bounding_box[0], bounding_box[1]),
(bounding_box[0]+bounding_box[2], bounding_box[1]+bounding_box[3]),
(0,204,0),2)
crop_img = im.crop((bounding_box[0], bounding_box[1],
bounding_box[0]+bounding_box[2], bounding_box[1]+bounding_box[3]))
name = search_face(crop_img)
cv2.putText(image,name, (bounding_box[0], bounding_box[1]),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)
print("---------------")
img = ResizeWithAspectRatio(image, width=640)
cv2.imshow("Face Recognition", img)
cv2.waitKey(0)
Trong tập ảnh test, ảnh input có thể to nhỏ không đồng đều. Vậy nên để phù hợp hơn với khung nhìn, ta có thể viết thêm một hàm ResizeWithAspectRatio() để resize lại ảnh với để điều chỉnh chiều cao và rộng của ảnh mà vẫn giữ nguyên được tỷ lệ ban đầu :
#Resize Image
def ResizeWithAspectRatio(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
return cv2.resize(image, dim, interpolation=inter)
Cuối cùng ta kiểm tra kết quả với các ảnh test, trong thư mục test. Viết một vòng for lấy đường dẫn của từng ảnh trong thư mục test và gọi hàm tagging_image() để thực hiện face recognition:
image_folder_in = "./data/test/"
for image_name in os.listdir(image_folder_in):
image_path = os.path.join(image_folder_in,image_name)
tagging_image(image_path)
Hoặc có thể test riêng 1 một ảnh bằng cách đưa đường dẫn riêng của ảnh đó vào hàm tagging_image():
# Test with one image
tagging_image("./data/test/52.jpg")
- Code hoàn chỉnh cho file main.py:
from mtcnn import MTCNN
import cv2
from PIL import Image
from PIL import Image
from face_search import search_face
import os
#Resize Image
def ResizeWithAspectRatio(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
return cv2.resize(image, dim, interpolation=inter)
# Detect face, search face and display reuslts
detector = MTCNN()
def tagging_image(path):
im = Image.open(path)
image = cv2.imread(path)
faces = detector.detect_faces(image)
print("Results:")
for face in faces:
bounding_box = face['box']
cv2.rectangle(image,(bounding_box[0], bounding_box[1]),
(bounding_box[0]+bounding_box[2], bounding_box[1]+bounding_box[3]),
(0,204,0),2)
crop_img = im.crop((bounding_box[0], bounding_box[1],
bounding_box[0]+bounding_box[2], bounding_box[1]+bounding_box[3]))
name = search_face(crop_img)
cv2.putText(image,name, (bounding_box[0], bounding_box[1]),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)
print("---------------")
img = ResizeWithAspectRatio(image, width=640)
cv2.imshow("Face Recognition", img)
cv2.waitKey(0)
# TEST
# Test with folder test
image_folder_in = "./data/test/"
for image_name in os.listdir(image_folder_in):
image_path = os.path.join(image_folder_in,image_name)
tagging_image(image_path)
# Test with one image
tagging_image("./data/test/52.jpg")
- Link file tran.rar chứa ảnh dataset: https://drive.google.com/file/d/1qDpGJxh7TysfcnV3jCoQNTNuxghZWPL2/view?usp=sharing
- Link code tạo KNN index trên Google Colab: https://colab.research.google.com/drive/11BzQ8_l0x-6TmR1G1-EwTJi-Vi0SxtRW?usp=sharing
- Link code project Face Recognition sử dụng AutoFaiss: https://github.com/nguyenthuy1681999/Face_Recognition_Use_AutoFaiss.git
4. Kết quả
Chạy file main.py với thư mục ảnh test, kết quả được hiển thị với ảnh ouput và tên cùng độ tương đồng ghi ở terminal:
Một số kết quả tốt trong tập ảnh test:
-
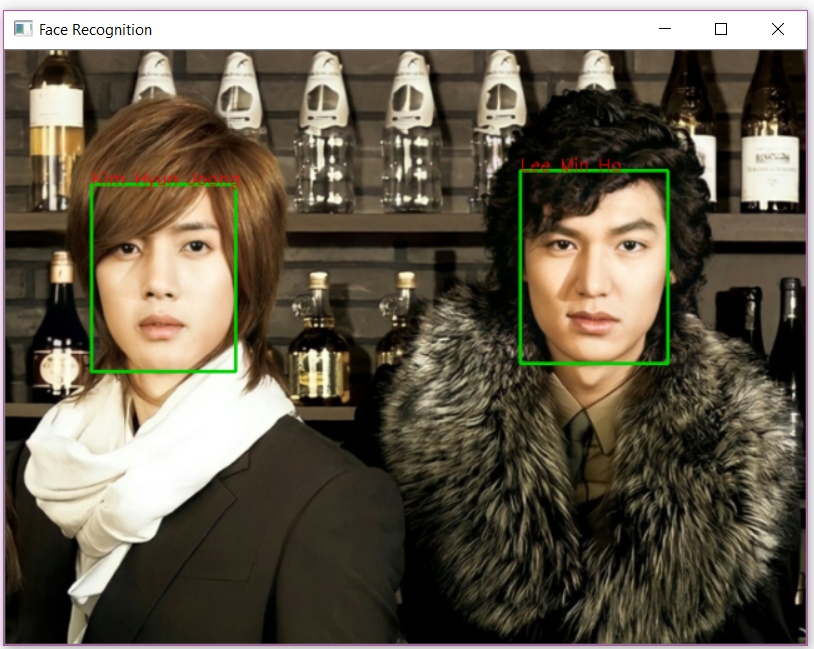
Ảnh với hai idol K-pop nam có độ tuổi giống nhau:
![image.png]()
-
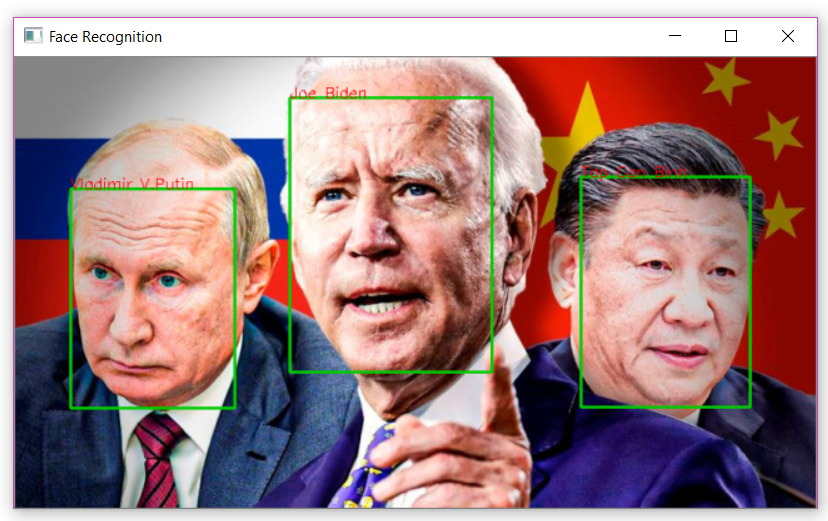
Ảnh lãnh đạo các quốc gia với nhiều độ tuổi:
![image.png]()

-
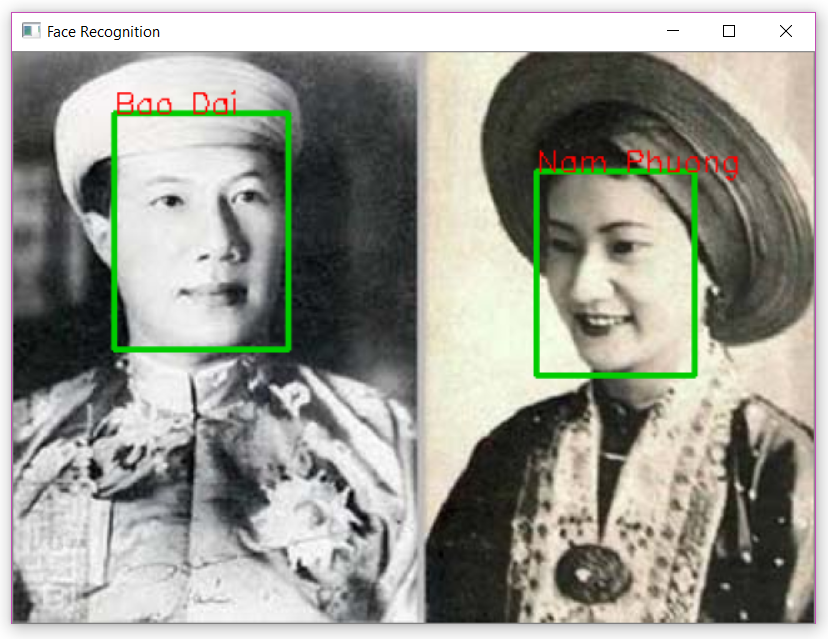
Ảnh trắng đen:
![image.png]()
![image.png]()
-
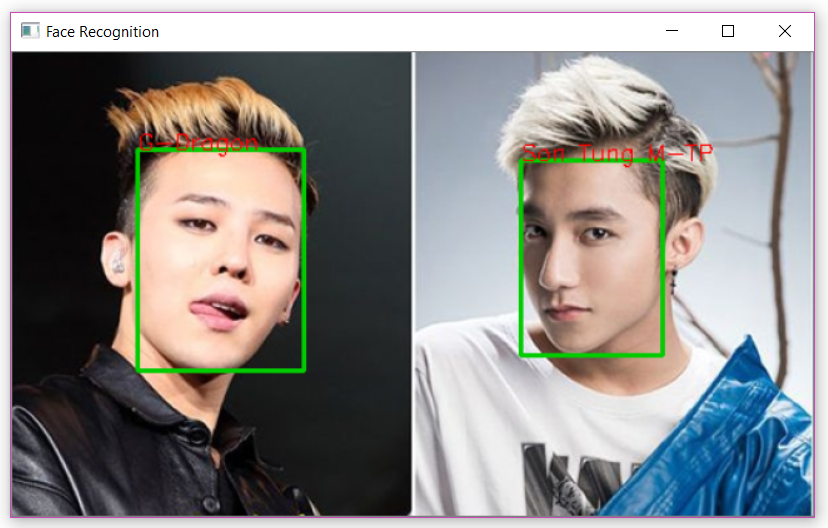
Ảnh idol K-pop và V-pop được cho là khá giống nhau:
![image.png]()
-
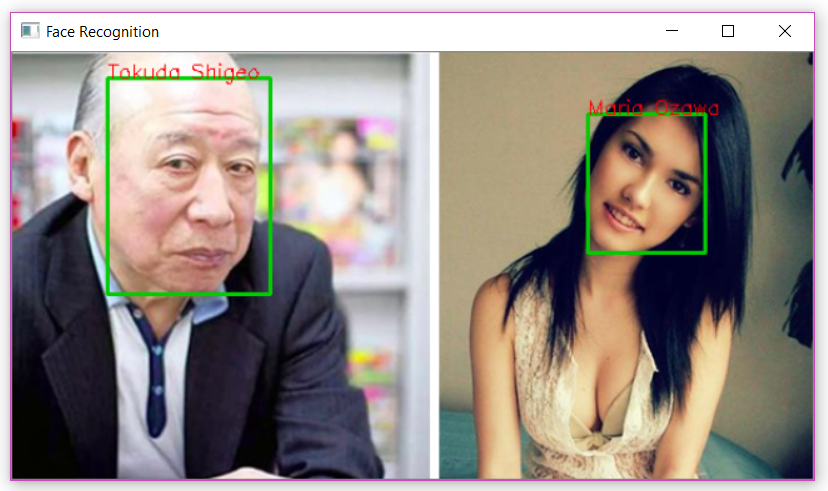
Ảnh diễn viên Nhật Bản nổi tiếng với độ tuổi và giới tính khác nhau:
![image.png]()
-
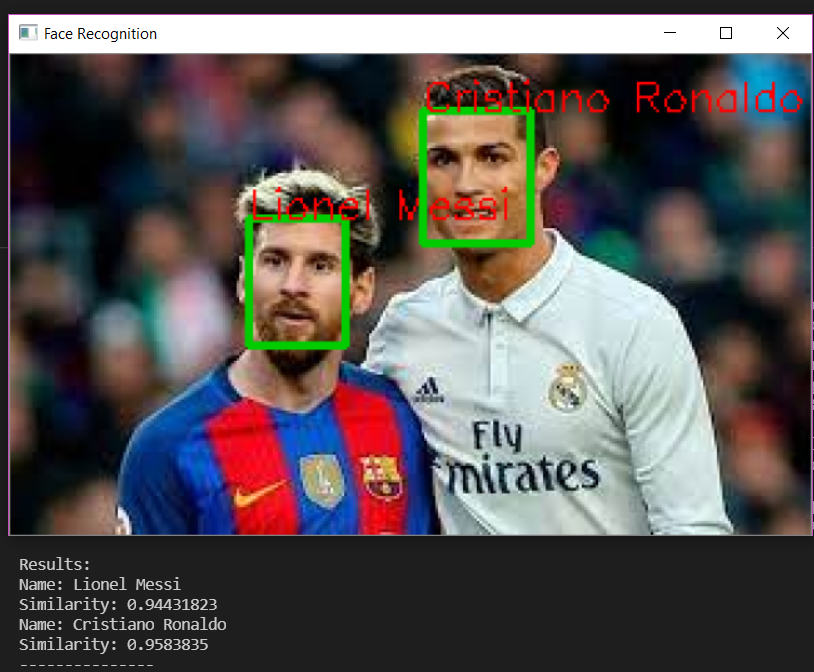
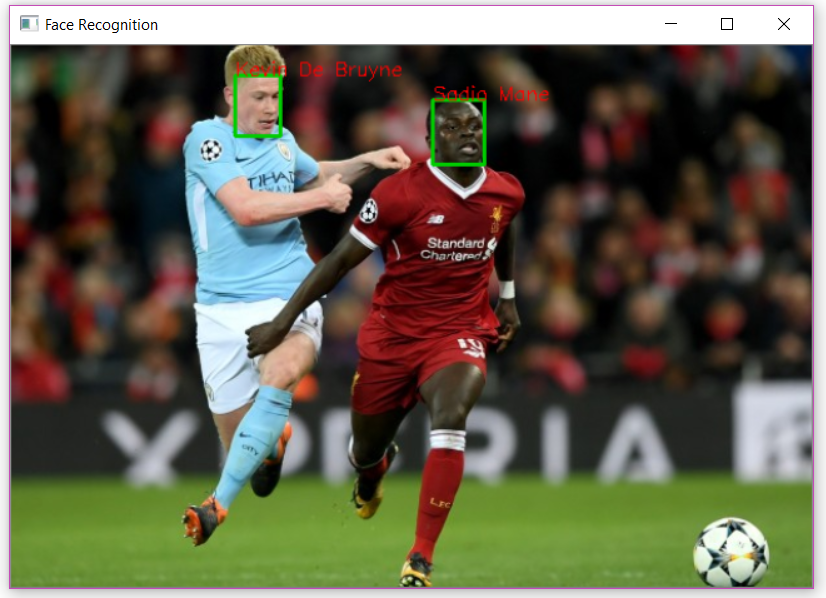
Ảnh cầu thủ khi thi đấu:
![image.png]()

Một vài kết quả sai:
-
MTCNN chưa phát hiện hết các khuôn mặt:
![image.png]()
-
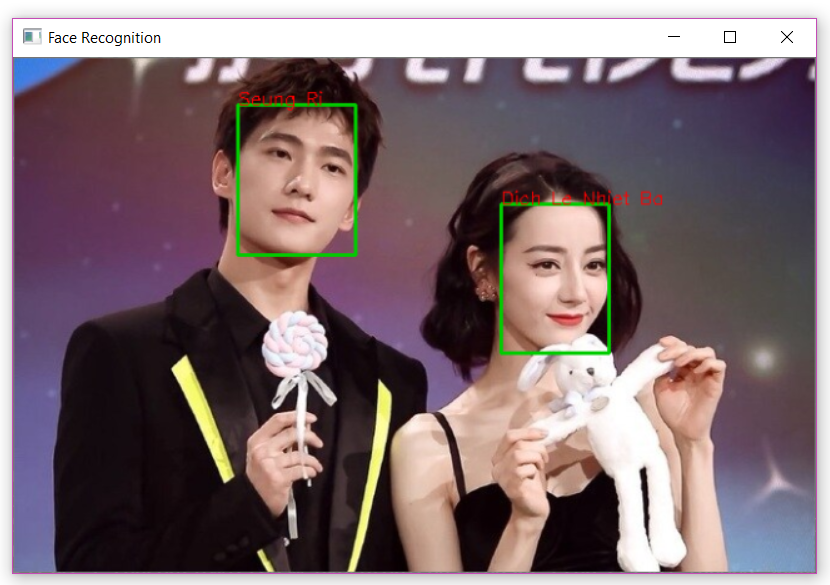
KNN index tìm kiếm sai ảnh, khi Dương Dương bị nhận nhầm là Seung Ri có thể do hai người này có ảnh trong database khá giống nhau:
![image.png]()

5. Tài liệu tham khảo
https://github.com/criteo/autofaiss
https://github.com/rom1504/clip-retrieval
All rights reserved
