
Nhận dạng tiếng Việt cùng với Transformer OCR
Bài đăng này đã không được cập nhật trong 5 năm
1. Lời nói đầu
Nếu các bạn đã quá ngán ngẩm xử lý bằng RNN, LSTM vì thời gian training quá lâu và đôi khi không hiệu quả đối với những câu dài đòi hỏi phụ thuộc (long-range dependencies), thì chúc mừng Transformer chính là câu trả lời cho bạn. Xuất phát ý tưởng từ paper Attention Is All You Need, Transformer đã thực sự tạo nên một kiến trúc đột phá giúp giải quyết nhiều vấn đề tồn tại trong việc xử lý ngôn ngữ tự nhiên và gần đây đã mở rộng nhiều lĩnh vực trong đó có Computer Vision. Hôm nay, mình sẽ cùng các bạn tìm hiểu về lý thuyết cũng như ứng dụng Transformer trong nhận dạng tiếng Việt qua thư viện VietOCR của anh Phạm Quốc.
2. Vấn đề của RNN ?
Khi bắt đầu học về NLP, chắc hẳn các bạn đã quen với các lớp quen thuộc như RNN hay LSTM. Tuy nhiên những lớp đó lại có những nhược điểm như sau :
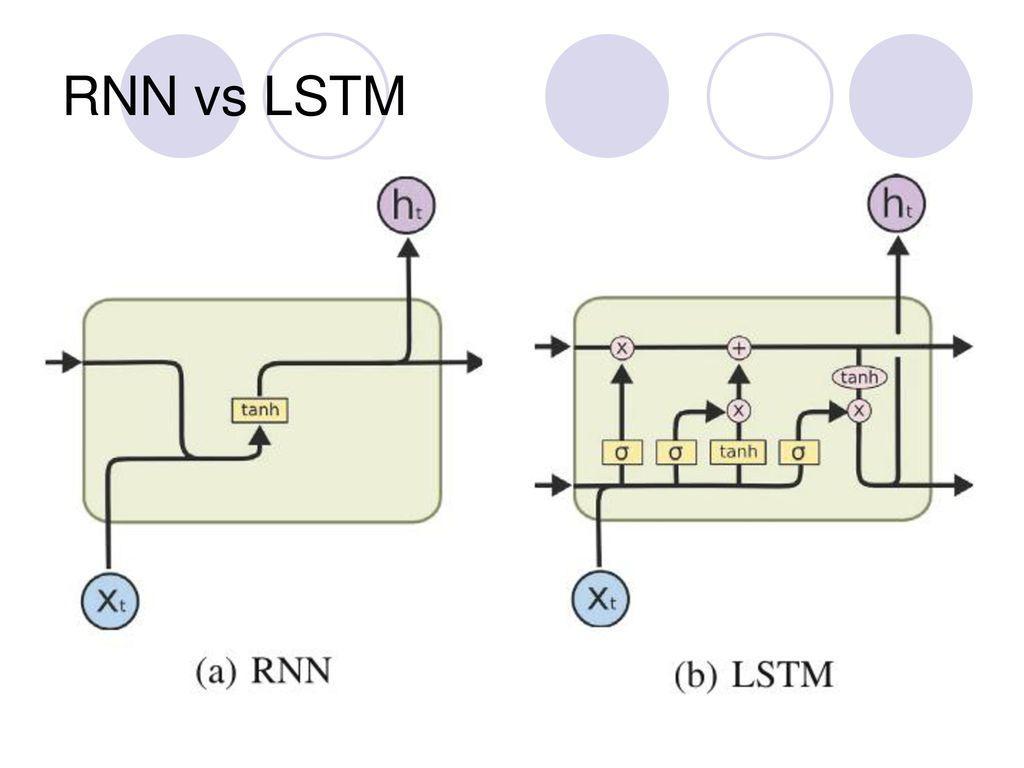
-
Thời gian huấn luyện lâu : Khi bạn xử lý một câu văn bằng RNN thì mô hình xử lý câu văn một cách tuần tự theo từng timestep do đó hidden state sau phải phụ thuộc vào hidden state trước thực hiện xong mới tính toán được. Điều này khiến mô hình không thể thực hiện tính toán song song, không tận dụng được khả năng tính toán của GPU khiến thời gian training lâu hơn nhiều so với cấu trúc như CNN.
-
Khả năng ghi nhớ kém : Đây là vấn đề muôn thuở đối với mạng có kiến trúc tuần tự như RNN. Nói đơn giản là mô hình sẽ chỉ học được các từ ở đầu câu, càng về sau những đặc trưng học được càng ít do gradient biến mất (vanishing gradient). Kể cả kiến trúc LSTM hay GRU được giới thiệu là giải quyết được điều này nhờ kiến trúc đặc biệt tuy nhiên việc học được những câu dài luôn luôn là một thách thức.
-
Khả năng chú ý kém : Các lớp RNN học các đặc trưng theo từng timstep sau đó sẽ mã hóa (encode) input sequence đó thành một context vector, tuy nhiên trong context vector đó từ nào cũng giống từ nào . Nhưng trong một câu xét về mặt ngữ nghĩa có những từ có vai trò quan trọng có những từ ít quan trọng hơn do đó việc coi các từ giống nhau sẽ làm giảm độ chính xác của mô hình. Trong mô hình xử lý ngôn ngữ, có ba loại quan hệ cần chú ý:
- Quan hệ giữa các token giữa input và output
- Quan hệ giữa các token ở input
- Quan hệ giữa các token ở output
Cơ chế attention truyền thống đánh lại trọng số (reweight) của context vector( còn được gọi là attention weight) nhờ đó giúp phần giải mã biết timestep nào cần được chú ý (attention), mô hình hóa được mối quan hệ ngữ nghĩa giữa input và output. Attention weight bản chất chính là độ liên quan của các encoder hidden states trong khi giải mã decoder hidden state. Các bạn có thể tìm hiểu thêm về cơ chế Attention qua bài viết [Machine Learning] Attention, Attention, Attention, ...! của tác giả Huy Hoàng. Vậy có một ý tưởng là Tại sao không để input/output attention đến chính nó? ( self-attention ). Và Transformer chính là câu trả lời cho câu trả lời này.
3. Tại sao lại là Transformer ?
Transformer giải quyết được nhược điểm của mô hình tuần tự truyền thống nhờ chủ yếu vào hai cấu trúc là Multi-head attention & Positional encoding
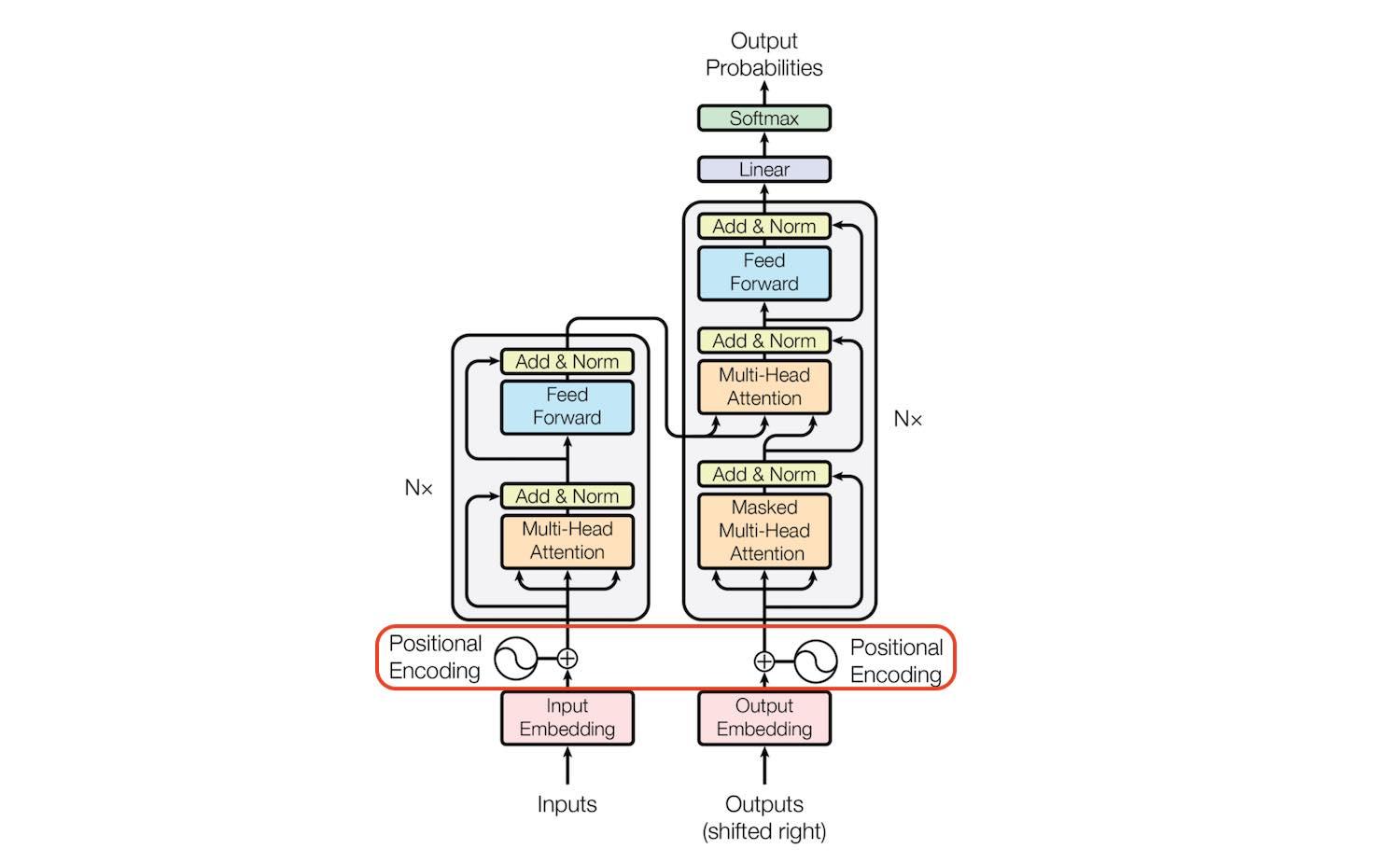
Nói sơ qua một chút, kiến trúc transformer cũng giống với các mô hình sequence-to-sequence bao gồm hai phần encoder ( trái ) và decoder (phải ).
- Phần Encoder, Gồm N block, mỗi block bao gồm hai sub-layer: Multi-Head Attention và Feed forward network. Tác giả dùng một residual connection ở mỗi sub-layer này. Theo sau mỗi sub-layer đó là một lớp Layer Norm có ý nghĩa tương tự như lớp Batch Norm trong CNN. Residual connection cũng góp phần giúp mô hình có thể sâu hơn , deep hơn nhờ giảm tác động của vanishing gradient.
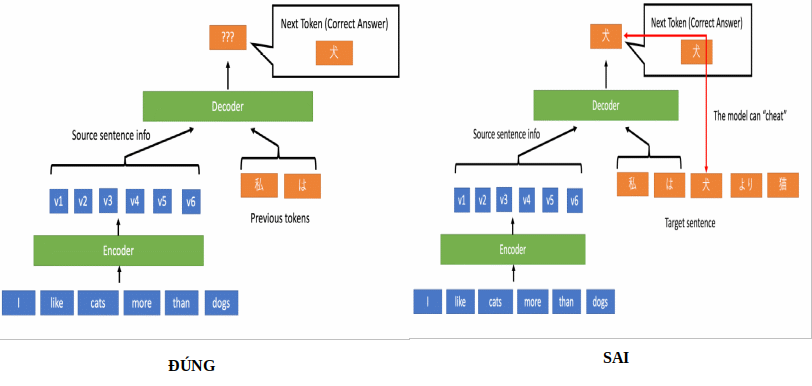
- Phần Decoder cũng tương tự như encoder gồm N block, mỗi block gồm 2 sub-layer. Tuy nhiên, nó có một lớp Masked Multi-Head Attention. Lớp này chính là lớp Multi-Head Attention. Nó có chức năng chú ý đến toàn bộ những decoder hidden state trước. Lý do mà nó lại được đặt tên như vậy là khi huấn luyện Transformer, ta đưa toàn bộ câu vào cùng một lúc nên nếu ta đưa toàn bộ target sentence cho decoder trước thì mô hình sẽ chẳng học được gì cả (biết hết rồi ai học làm gì
 ) Do đó phải che (mask) bớt một phần token ở decoder hidden state sau trong quá trình decode.
) Do đó phải che (mask) bớt một phần token ở decoder hidden state sau trong quá trình decode.
![]() Tại bài viết này, mình không bàn sâu về encoder và decoder mà tập trung hai cấu trúc chính là Multi-head attention & Positional encoding. Các bạn muốn tìm hiểu sâu hơn có thể xem một bài viết rất hay của tác giả Việt Anh theo link này.
Tại bài viết này, mình không bàn sâu về encoder và decoder mà tập trung hai cấu trúc chính là Multi-head attention & Positional encoding. Các bạn muốn tìm hiểu sâu hơn có thể xem một bài viết rất hay của tác giả Việt Anh theo link này.
3.1 Multi-Head Attention
Từ đầu bài viết đến rồi, ta liên tục nhấc Attention, Attention, Attention!. Vậy thực sự Attention trong Transformer là gì  input sentences sẽ được nhân tuyến tính với ba ma trận để sinh ra ba giá trị keys, values, queries. Keys và Queries gần giống nhau. Values chính là giá trị của keys. Ta có thể ví dụ, keys là mã một từ, queries là truy vấn để tìm mã từ đó (keys) và values chính là nghĩa của từ. Dựa trên ba giá trị này, ta tính attention_score. Attention score thể hiện mức liên quan giữa các values với nhau hay các nghĩa của từ với nhau. Nếu Trong mô hình, các giá trị được kí hiệu lần lượt là: {Values: V, Keys: K, Query: Q}
input sentences sẽ được nhân tuyến tính với ba ma trận để sinh ra ba giá trị keys, values, queries. Keys và Queries gần giống nhau. Values chính là giá trị của keys. Ta có thể ví dụ, keys là mã một từ, queries là truy vấn để tìm mã từ đó (keys) và values chính là nghĩa của từ. Dựa trên ba giá trị này, ta tính attention_score. Attention score thể hiện mức liên quan giữa các values với nhau hay các nghĩa của từ với nhau. Nếu Trong mô hình, các giá trị được kí hiệu lần lượt là: {Values: V, Keys: K, Query: Q}
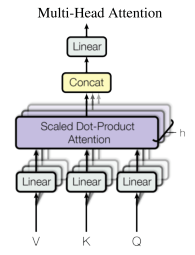
Có một khó khăn trong các mô hình truyền thống đó là rất khó khái quát được input sentences theo nhiều góc độ khác nhau vì chỉ có duy nhất một cơ chế attention. Ví dụ xử lý một câu "The animal didn't cross the street because it was too tired". Nếu ta chỉ có duy nhất một attention weights, attention có khả năng chỉ chú ý đến "animal" hay "street". Tuy nhiên , "it" trong câu là để chỉ "animal" hay "street". Do đó để nắm bắt đa chú ý, Transformer thay vì sử dụng self-attetion (1 head) đã sử dụng nhiều linear attention cùng một lúc (multi-head) để học được nhiều attention weight khác nhau giúp chú ý đến nhiều chỗ khác nhau trong cùng một câu. Các giá trị V, K, Q cùng một lúc được biến đổi tuyến tính sau đó ta dùng một cơ chế attention có tên là Scaled Dot-Product Attention để tổng hợp attention weight của cả V, Q, K. Công thức tính của Scaled Dot-Product Attention như sau:
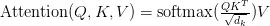
Ý tưởng đằng sau công thức này đơn giản chỉ là nhân query với key. Kết quả sẽ cho ra độ liên quan giữa các từ với nhau. Tuy nhiên kết quả này sẽ tăng phi mã theo kích thước (dimension) của query và key. Do đó cần phải chia cho căn bậc hai kích thước của keys để ngăn chặn hiện tượng số quá lớn. Hàm softmax để tính phân bố xác suất liên quan giữa các từ. Cuối cùng ta nhân thêm value để loại bỏ những từ không cần thiết trong câu (có xác suất qua hàm softmax nhỏ).
Sau khi tính từng attention weight bằng cơ chế Scaled Dot-Product Attention, chúng ta dùng concat chúng lại với nhau thành một ma trận rồi nhân tuyến tính với một ma trận đưa ra output cuối cùng.
3.2 Positional Encoding (Mã hóa vị trí )
Vị trí và thứ tự của các từ trong một câu là điều cần thiết đối với mọi mô hình ngôn ngữ kể cả trong NLP hay CV. Các mô hình như RNN hay LSTM sử dụng tính tuần tự để học được vị trí của các câu trong văn bản. Nhưng như mình đã vừa đề cập ở trên, để khắc phục thời gian huấn luyện quá lâu do tính tuần tự gây ra, Transfomer đã hoàn toàn loại bỏ điều này. Vậy làm thế nào để mô hình có thể học được thông tin về vị trí ? Đó chính là mã hóa thêm thông tin biểu diễn vị trí vào từng từ câu. Và người ta gọi đó là Positional Encoding.
Một positional encoding tốt được đánh giá dựa trên những tiêu chí sau:
- Mỗi time-step phải có một mã hóa (encoding) duy nhất: Nếu hai time-step khác nhau mà có cùng một mã hóa sẽ gây ra nhầm lẫn vị trí giữa các từ với nhau.
- Khoảng cách giữa hai vị trí được embedding của hai time-step giữa hai câu có độ dài khác nhau phải bằng nhau
- Có khả năng biểu diễn được vị trí cho những câu dài hơn khi huấn luyện
Và cách mà transformer mã hóa vị trí thật tuyệt vời, nó đáp ứng được hết tất cả những điều mà ta mong đợi của một positional encoding. Công thức mà trong paper, tác giả đã đề xuất như sau:
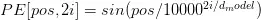
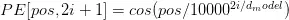
trong đó pos là vị trí hiện tại, dmodel là kích thước cố định của mô hình, i là vị trí trong dmodel.
Đặt w = , ta có
PE[pos, 2i] = sin(w * pos)
PE[pos, 2i + 1] = cos(w * pos)
Nào chúng ta cùng xét những tiêu chí ta đặt ra ở bên trên:
- Mỗi time-step phải có một mã hóa (encoding) duy nhất: Khi giá trị i càng lớn, càng sâu thì giá trị w giảm dần, dần dần tiến về 0. Do đó mỗi vị trí i sẽ có một cách biểu diễn khác nhau do pos khác nhau và mặc dù là các hàm sin, cos có chu kỳ nhưng w giảm dần không phải cố đinh nên ta sẽ nhận được giá trị khác nhau đối với mỗi giá trị i. Hơn nữa, nếu pos giống nhau trong hai câu có độ dài khác nhau vẫn có vị trí trong embeddding giống nhau.
- Khoảng cách giữa hai vị trí được embedding của hai time-step giữa hai câu có độ dài khác nhau phải bằng nhau: Bởi vì mỗi vị trí i có vị trí embedding khác nhau trong cùng một câu và giống nhau trong hai câu có độ dài khác nhau nên khoảng cách giữa chúng sẽ bằng nhau không phụ thuộc độ dài câu.
- Có khả năng biểu diễn được vị trí cho những câu dài hơn khi huấn luyện: Do hàm sin, cos là hai hàm lượng giác có chu kì 2kΠ mà chúng ta có thể dễ dàng được w và xác định giá trị pos nên có khả năng biểu diễn được những vị trí xa hơn kể cả chưa được huấn luyện
Các bạn có thể quan sát hình sau xem vị trí sau khi positional encoding:
 Khi giá trị i càng deep, càng lớn thì giá trị hàm sin và cos tiến đến 0 và 1nên các vị trí embedding sẽ gần giống nhau. Do đó càng về sau, các cột màu đều một màu, không có sự khác nhau lớn.
Khi giá trị i càng deep, càng lớn thì giá trị hàm sin và cos tiến đến 0 và 1nên các vị trí embedding sẽ gần giống nhau. Do đó càng về sau, các cột màu đều một màu, không có sự khác nhau lớn.
4. Nhận dạng tiếng Việt cùng với Transformer OCR
Sau khi ngâm cứu những điều tuyệt vời của kiến trúc Transformer, bây giờ mình cùng thử xem sức mạnh của nó thực tế sẽ như nào ?
Ở trong bài lần này, mình giới thiệu cho các bạn một pretrained ngon ghẻ từ repo VietOCR của anh Phạm Quốc. Pretrained weight đã được huấn luyện với 10 triệu ảnh, một số lượng rất lớn nên mình khuyên các bạn không nên huấn luyện lại mà mình sẽ dùng pretrained đó và custom lại với dữ liệu của mình. Let's go
Đầu tiên, bạn cần cài đặt thư viện VietOCR và môi trường theo câu lệnh sau:
pip install --quiet vietocr==0.3.2
pip install torch
pip install torchvision
Download pretrain weight tại đây Hoặc sử dụng câu lệnh
gdown https://drive.google.com/uc?id=13327Y1tz1ohsm5YZMyXVMPIOjoOA0OaA
4.1 Train model
Chọn mô hình là VGG Transformer, tức là mô hình gồm phần backbone là mạng VGG-19 kết hợp với Transformer. Các cấu hình của model sẽ được lưu vào biến config. Lưu ý là các mô hình khác chưa có pretrained weight đâu nhé
from vietocr.tool.config import Cfg
from vietocr.model.trainer import Trainer
config = Cfg.load_config_from_name('vgg_transformer')
Sau đó các bạn chỉnh config phù hợp với bài tóan của mình. Trong đó cần lưu ý :
- data_root : chỉ thư mục cha chứa file có chứa label là train_annotation.txt và test_annotation.txt
- checkpoint: đường dẫn tới file checkpoint mà bạn định lưu
- export: đường dẫn tới pretrained weight
- device: chỉ thiết bị bạn dùng huấn luyện mô hình. Nếu dùng GPU, đặt là cuda:0. Nếu là CPU, đặt là cpu.
dataset_params = {
'name':'hw',
'data_root':'./data/',
'train_annotation':'train_annotation.txt',
'valid_annotation':'test_annotation.txt'
}
params = {
'print_every':200,
'valid_every':15*200,
'iters':60000,
'checkpoint':'./checkpoint/transformerocr_checkpoint.pth',
'export':'./weights/transformerocr.pth',
'metrics': 10000,
'batch_size': 64
}
params_opt = {
'init_lr': 0.01,
'n_warmup_steps': 4000
}
config['trainer'].update(params)
config['dataset'].update(dataset_params)
config['device'] = 'cuda:0'
Cuối cùng ta tiến hành train và chờ kết quả thôi nào
trainer = Trainer(config, pretrained=True)
trainer.train()
4.2 Test
Sau khi train xong model, bạn sẽ thu được file weight của mô hình. Hoặc bạn nào ngại train thì có thể tại trực tiếp pretrained weight dùng thử vì nó cũng tương đối ngon rồi.
Ảnh đầu vào có tên image.png:
![]()
from vietocr.tool.predictor import Predictor
from vietocr.tool.config import Cfg
import cv2
# load pretrained weight
config['weights'] = 'https://drive.google.com/uc?id=13327Y1tz1ohsm5YZMyXVMPIOjoOA0OaA'
# set device to use cpu
config['device'] = 'cpu'
config['cnn']['pretrained']=False
config['predictor']['beamsearch']=False
detector = Predictor(config)
img = cv2.ỉmread('image.png')
# predict
result = detector.predict(img)
print(result)
Kết quả

Transformer hiện đang được ứng dụng trong nhiều lĩnh vực hiện nay trong đó có cả Computer Vision. Mong bài viết của mình một phần giúp các bạn hiểu thêm về một kiến trúc tuyệt vời này. Cảm ơn các bạn đã theo dõi bài viết của mình. Hãy ấn like và share nếu bạn thấy bài viết có ích nhé
Bài viết tham khảo
All rights reserved
