Nghịch ngợm với bài toán multi level query.
Bài đăng này đã không được cập nhật trong 5 năm
Mọi chuyện bắt đầu từ câu hỏi của bạn này : Tối ưu laravel . Hôm đó mọi người bàn luận cũng hăng, cuối cùng thành ra hơi loằng ngoằng xong cuối cùng anh em đều lười, chả ai vào viết câu trả lời cả (yaoming). Trước tin xin tag tạm bạn kia vào đây @tinhtn89 , cũng cám ơn bạn gợi ra đề tài hay ho cho anh em có cái chém gió. Đơn giản hóa đề bài lại một chút cho mọi người tiện bàn luận, thì tình huống của chúng ta đang đặt ra ở đây là :
- Hệ thống của chúng ta có nhiều user.
- Mỗi user có 1 người giới thiệu. Người này cũng đồng thời là 1 user khác trong hệ thống. Mỗi user có thể giới thiệu nhiều người. Chuỗi người giới thiệu - người được giới thiệu này có thể kéo dài tùy ý, không bị giới hạn về mặt level.
- Chúng ta đang cần ở đây, là lấy ra thông tin về 1 user cùng tất cả các user là cấp dưới của user này. Performance thì dĩ nhiên càng ngon càng tốt, nhưng ít nhất cũng phải đảm bảo hoạt động được ở điều kiện vừa phải. Hiện bài toán đã được giải nhưng với lượng query rất loằng ngoằng, chúng ta cần cải thiện nó.
Xong, đề bài đã được đặt ra, giờ bắt tay vào giải. Thật ra, bài toán "đa cấp" này cũng không phải là quá hiếm gặp. Dạng thường thấy nhất của nó chính là quan hệ giữa bài viết và comment. Quan hệ này có thể tổng kết thành 2 dạng : Nếu làm như Facebook ( hay Viblo ), ta cho mỗi bài viết (Post) sẽ có bình luận (Comment) của nó, và mỗi bình luận lại có trả lời (comment) của nó. Giới hạn ở 2 level như thế này là hướng giải quyết theo kiểu làm tinh giản giải pháp của mình, buông nặng nắm nhẹ, tránh việc phải xử lí kĩ thuật phức tạp. Thực sự mình cũng nghĩ đây là hướng giải quyết tốt nhất, vì không phải lúc nào cũng nên chăm chăm tìm giải pháp kĩ thuật cho ý tưởng đầu tiên mà mình nghĩ ra. Nếu có thể mang lại trải nghiệm người dùng tương tư chỉ với effort tối thiểu bỏ ra, thì việc lựa chọn hướng đi thay thế là một cách tiếp cận vấn đề rất tốt. Tuy nhiên, sẽ có những trường hợp như tình huống chúng ta đặt ra, hay một số trang khác muốn cho phép chuỗi comment dài vô hạn như Reddit chẳng hạn, lúc đó buộc lòng chúng ta phải đi tìm cách giải bài toán này. Đánh trực diện thì như ta đã thấy, số câu truy vấn tăng đệ quy theo số lượng user phụ thuộc và cấp độ phụ thuộc, vậy chúng ta phải làm thế nào.
Giải pháp
1.Dựa vào một trường định danh mới của user.
Cách làm này, có lẽ là cách làm phổ biến nhất, và có thể nó cũng là cách đơn giản nhất luôn. Với mỗi một user, bạn có thêm một trường nữa, unique, chứa thông tin về phả hệ của nó. Thông tin này thường được tạo ra dưới dạng một chuỗi, chứ tất cả các id của các cấp trên của nó và chính nó. Miêu tả thì hơi dông dài, xin mượn tạm một chút dữ liệu mẫu của dự án đang chạy thật ra để minh họa.
| id | post_id | ancestor_id | ancestor_path |
|---|---|---|---|
| 13881 | 1321 | 0000013881 | |
| 13918 | 1321 | 13888 | 0000013881.0000013888.0000013918 |
| 13990 | 1321 | 0000013990 | |
| 13888 | 1321 | 13881 | 0000013881.0000013888 |
| 13997 | 1321 | 13990 | 0000013990.0000013997 |
| 13999 | 1321 | 13918 | 0000013881.0000013888.0000013918.0000013999 |
| 14054 | 1321 | 13997 | 0000013990.0000013997.0000014054 |
| 14063 | 1321 | 14054 | 0000013990.0000013997.0000014054.0000014063 |
| 28114 | 1321 | 0000028114 | |
| 28115 | 1321 | 28114 | 0000028114.0000028115 |
| 28119 | 1321 | 28115 | 0000028114.0000028115.0000028119 |
| 28137 | 1321 | 28119 | 0000028114.0000028115.0000028119.0000028137 |
Đơn giản và dễ hiểu phải không. Việc truy vấn lúc này trở nên khá nhẹ nhàng, ví dụ như bạn muốn tìm tất cả user được user có id 13881 giới thiệu, bạn chỉ cần tìm kiến theo điều kiện users.ancestor_path LIKE '0000013881%' , khá nhẹ nhàng phải không ? Trường ancestor_id ở đây, được thêm vào để giúp thuận lợi hơn trong quá trình xử lí ( vì nghiệp vụ cần lấy ra cấp trên trực tiếp của một Post là tương đối phổ biến ) Tất nhiên, nó cũng tồn tại một vài nhược điểm :
- Việc xây dựng chuỗi phụ thuộc
ancestor_pathnhư thế này, về mặt lí thuyết thì hoàn toàn làm được và không có rủi ro gì, nhưng trên thực tế không phải lúc nào cũng suôn sẻ. Việc trường này được xây dựng dựa trên những "ngầm hiểu" từ bên ngoài ( chuỗi bao gồm các user_id nối với nhau, ngăn cách bởi kí tự phân cách tự chọn - ở đây là.- theo thứ tự user cấp liền trên đứng trước, user cấp liền dưới đứng sau ), nhưng những ngầm hiểu này không thể được chuyển thành constraint trong database, chúng ta sẽ không thể đảm bảo dữ liệu trong database là dữ liệu sạch như mình mong muốn. Tất nhiên, nói ra thì nghe hơi lo viển vông, ai rỗi hơi vào database mà sửa dữ liệu, nhưng chắc cũng có những bạn từng làm việc với những dự án tương đối cũ, dữ liệu trải qua nhiều đời, áp tỉ thứ tính năng thử nghiệm vào rồi lại bỏ ra, không seeder không migrations, việc kiểm soát dữ liệu không phải lúc nào cũng được như ý mình muốn. Nên về phía cá nhân mà nói, mình khá ngại khi phải làm việc với dữ liệu "ngầm hiểu" kiểu này. - Nếu một ngày đẹp trời, bạn bỗng nhận ra cách mình xây dựng
ancestor_pathkhông còn phù hợp nữa ( ở đây đang pad cho mỗi id dài ra trước khi đưa vàoancestor_pathchính là vì đang nghĩ tới chuyện lỡ sau này lượng id lớn quá thì sao. Đó là 1 tình huống khá dễ dự đoán, còn tất nhiên lúc nào cũng có những rủi ro mà mình chưa lường trước tới ). Lúc đó, việc update thông tin của một trường hoàn toàn không có ràng buộc gì, chỉ dựa vào "ngầm hiểu" kiểu này sẽ tương đối đau đầu đấy.
Còn tất nhiên, ưu điểm thì đã quá rõ ràng : Việc tìm kiếm đơn giản, dễ hiểu, bất kì ai nhìn vào cũng có thể đọc ra ý đồ muốn làm ở đây. Khi được implement ngay từ đầu cũng không tốn công sức gì, độ phức tạp của query gần như bằng 0, tốc độ chắc chắn tốt. Nói chung nếu là giải pháp được xây dựng từ giai đoạn đầu, hoàn toàn ủng hộ theo hướng đi này.
2. Query trâu.
Đứng từ cách làm thứ nhất, anh em đặt ra câu hỏi là, liệu ở đây chúng ta có thể có hướng giải quyết thuần túy về sql không ? Và liệu rằng chúng ta có thể cải thiện được chút nào trong số những nhược điểm đã kể trên hay không ? Trong quá trình đó, liệu có phải đánh đổi lấy điều gì khác, vì trên nguyên tắc, hầu như bất kì giải pháp nào cũng là 1 sự đánh đổi giữa các yếu tố, được cái này thường là phải mất cái khác? Câu trả lời là, với cấu trúc dữ liệu hợp lí thì cũng có thể. Vì cách này hơi phức tạp hơn một chút, và cũng (theo quan điểm cá nhân) có phần thú vị hơn, nên xin được trình bày chi tiết hơn ở đây, để nếu người đọc thích thì có thể tham gia bàn luận cùng.
Trước tiên, làm cái gì cũng thế, có ví dụ trực quan thì sẽ dễ hơn là nói lí thuyết suông. Để phục vụ cho việc đánh giá performance, thì chúng ta cũng cần tạo ra bộ dữ liệu lớn một chút, nên ở đây mình thử tạo một tập dữ liệu :
- Bao gồm 2 bảng
userschứa các thông tin :id,namevà để phục vụ cho việc thực hiện truy vấn, sẽ cần có thêm 1 trường làlevelmiêu tả về cấp độ của mỗi user. Khi một user xuất hiện cấp dưới, thì anh ta và tất cả cấp trên của mình sẽ tăng thêm 1 level ( user đầu tiên của hệ thống sẽ có level 1. Khi anh ta giới thiệu 1 người, người này sẽ là level 1 và user đầu tiên thành level 2 ... cứ tiếp tục như thế . Đây là một điều mà mình nghĩ là có thể implement ở tầng application, với điều kiện là chúng ta có thể giải bài toán lấy ra tất cả cấp trên của 1 user ) . Thêm vào đó là bảngsubordinates, miêu tả mối quan hệ phụ thuộc giữa các user, bao gồm thông tinid,user_id( id của cấp trên ) vàsub_id( id của cấp dưới trong mối quan hệ ). - Sẽ có 10 level phụ thuộc giữa các user, ở mỗi level phụ thuộc có tất cả 4 lũy thừa số level user, phụ thuộc vào random 1 trong số những user của cấp trên. Theo cách này chúng ta sẽ có khoảng hơn 1 triệu bản ghi, với độ ngẫu nhiên tương đối đủ để đảm bảo tính khách quan của kết quả test. Bộ dữ liệu cũng hơi to, nên nếu bạn nào muốn dùng thử thì down file
sqlỞ ĐÂY về mà import, hoặc tự nghĩ ra cách nào đó generate dữ liệu. Nghiêm túc khuyên không nên làm theo cách mình đã dùng, vì nó siêu lâu luôn, mất tầm 10', còn tưởng treo máy luôn. - Ở đây mình muốn tách ra làm 2 bảng như vậy, để có thể biểu thị rõ ràng về mặt ý nghĩa hơn. 1 bảng mô tả cho thực thể, 1 bảng mô tả cho mối quan hệ, tuy nhiên bạn hoàn toàn có thể chỉ dùng một bảng
users( thêm một trường chứa id của cấp trên, nullable là được ). Về mặt bản chất mà nói, nó cũng sẽ không làm thay đổi gì nhiều những gì mình định trình bày phía sau.
Với bộ dữ liệu đó, chúng ta có thể thí nghiệm 1 chút. Về bản chất thì vẫn là đệ quy thôi, đi từ case đơn giản nhất, thử lấy ra 1 user và những user trực tiếp được user đó giới thiệu ( 1 level phụ thuộc ).
SELECT users.id, users.name, subordinates.sub_id as subordinate
FROM users INNER JOIN subordinates ON users.id = subordinates.user_id
WHERE users.id = 1;
Cũng khá là dễ hiểu phải không, không phải giải thích gì nhiều. Để áp dụng cho level tiếp theo, thật ra cũng không có gì cao siêu hết, chỉ có 1 cái, gọi là trick thì cũng không đúng lắm, là một tính năng mình có thể làm trong đa số các ngôn ngữ truy vấn ( không chỉ với MySQL, lúc trước khi mình làm việc với database Oracle cũng làm trò này khá nhiều ) mà bình thường mọi người ít để mắt tới, đó là một bảng có thể join với chính nó, hoặc có thể join với cùng một bảng khác nhiều lần. Nó sẽ thành ra dạng như này
SELECT users.id, users.name, s1.sub_id as 1st_sub, s2.sub_id as 2nd_sub
FROM users INNER JOIN subordinates s1 ON users.id = s1.user_id
INNER JOIN subordinates s2 ON s1.sub_id = s2.user_id
WHERE users.id = 1
ORDER BY 1st_sub, 2nd_sub;
Như trên là chúng ta đã có câu query lấy ra thông tin của user mang id 1, và những user phụ thuộc vào user đó cho đến 2 cấp độ, cũng khá đơn giản đúng không. Và ở đây chúng ta đã nhìn ra sự hao hao giống nhau giữa 2 câu query, và giống như trong đệ quy, ta chứng minh cho n và n+1 sau đó suy ra tất cả, cùng với cách diễn dịch này, ta có thể suy ra cho tất cả mọi trường hợp rồi đúng không. Ví dụ như với bộ dữ liệu của chúng ta, cần lấy ra đến 9 level phụ thuộc phía dưới, query sẽ trở thanhf
SELECT
u.id
, u.name
, s1.sub_id as 9th_level_sub
, s2.sub_id as 8th_level_sub
, s3.sub_id as 7th_level_sub
, s4.sub_id as 6th_level_sub
, s5.sub_id as 5th_level_sub
, s6.sub_id as 4th_level_sub
, s7.sub_id as 3rd_level_sub
, s8.sub_id as 2nd_level_sub
, s9.sub_id as 1st_level_sub
FROM users u, subordinates s1, subordinates s2, subordinates s3, subordinates s4, subordinates s5, subordinates s6, subordinates s7, subordinates s8, subordinates s9
WHERE u.id = 1
AND u.id = s1.user_id
AND s1.sub_id = s2.user_id
AND s2.sub_id = s3.user_id
AND s3.sub_id = s4.user_id
AND s4.sub_id = s5.user_id
AND s5.sub_id = s6.user_id
AND s6.sub_id = s7.user_id
AND s7.sub_id = s8.user_id
AND s8.sub_id = s9.user_id;
Và kết quả thì có vẻ cũng không tồi. Mất khoảng gần 7s cho truy vấn này, thực sự cũng là một con số chấp nhận được.
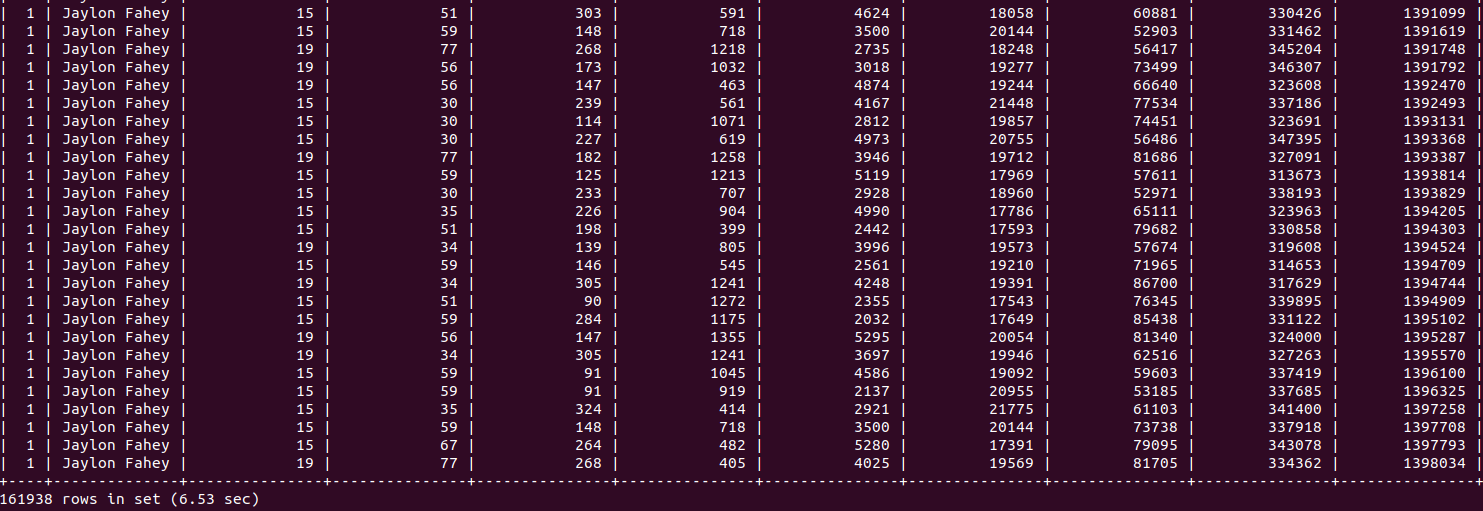
Lời kết.
Đọc đến đây, thật sự mình rất mong là, trong số các bạn, sẽ có 1 ai đó đang tự hỏi mấy câu sau :
- WTF, 7s ông bảo là kết quả chấp nhận được ???
- WTF, câu query cuối nhìn sai sai kiểu gì ...
Vì thực sự là mấy câu đó hoàn toàn là hợp lí. Thứ nhất là trong câu query cuối, thật ra nó cũng hoàn toàn tương đương nhau thôi, nhưng syntax viết kiểu kia không phải là cách được khuyến khích, mọi người nên chuyển nó về cách viết dùng INNER JOIN, mình paste vào vì đây là version draft đầu tiên. Nó vẫn chạy được, nhưng ko phải là best practice. Thứ 2 nữa là nếu query mất đến 7s, thì thực sự là không dùng được trong thực tế đâu  còn phải cải thiện thêm nữa. Và sẽ còn vui hơn nữa, nếu có bạn nào bảo rằng : "WTF, tôi làm theo có chạy được đéo đâu????" , vì đây chính là tình trạng bọn mình đã gặp trong lúc thảo luận. Thằng viết ra thì hớn hở bảo chạy ngon rồi anh em ơi, hội làm theo thì toàn kêu toáng lên là làm không được. Cái này về sau tìm ra nguyên nhân là, với MySQL version cũ, bản 5.x, query trên sẽ không chạy được, nó sẽ đứng im cho dù bạn có chờ bao lâu đi chăng nữa. MySQL mới hơn, version 8.x thì không bị lỗi và cho ra kết quả sau gần 7s như trong hình. Đây có lẽ là do một trong những setting mặc định bị thay đổi giữa các bản, hoặc là một tính năng mới, hỗ trợ tốt hơn cho các query lớn hay cải thiện performance được đưa vào ở các phiên bản sau của MySQL, bọn mình cũng chưa ai nghiên cứu docs và đưa ra được câu trả lời chính xác. Còn nguyên nhân tại sao lại như thế, là vì ở đây, các bạn có thể thấy chúng ta hoàn toàn chưa có index gì hết, performance chắc chắn sẽ kém hơn. Xin mời cùng đi tiếp những thí nghiệm tiếp theo mà bọn mình đã thực hiện. Trước tiên là tạo index, ở đây chúng ta thấy đang thực hiện tìm kiếm so sánh trên 2 trường
còn phải cải thiện thêm nữa. Và sẽ còn vui hơn nữa, nếu có bạn nào bảo rằng : "WTF, tôi làm theo có chạy được đéo đâu????" , vì đây chính là tình trạng bọn mình đã gặp trong lúc thảo luận. Thằng viết ra thì hớn hở bảo chạy ngon rồi anh em ơi, hội làm theo thì toàn kêu toáng lên là làm không được. Cái này về sau tìm ra nguyên nhân là, với MySQL version cũ, bản 5.x, query trên sẽ không chạy được, nó sẽ đứng im cho dù bạn có chờ bao lâu đi chăng nữa. MySQL mới hơn, version 8.x thì không bị lỗi và cho ra kết quả sau gần 7s như trong hình. Đây có lẽ là do một trong những setting mặc định bị thay đổi giữa các bản, hoặc là một tính năng mới, hỗ trợ tốt hơn cho các query lớn hay cải thiện performance được đưa vào ở các phiên bản sau của MySQL, bọn mình cũng chưa ai nghiên cứu docs và đưa ra được câu trả lời chính xác. Còn nguyên nhân tại sao lại như thế, là vì ở đây, các bạn có thể thấy chúng ta hoàn toàn chưa có index gì hết, performance chắc chắn sẽ kém hơn. Xin mời cùng đi tiếp những thí nghiệm tiếp theo mà bọn mình đã thực hiện. Trước tiên là tạo index, ở đây chúng ta thấy đang thực hiện tìm kiếm so sánh trên 2 trường user_id và sub_id của bảng subordinates, chúng ta hãy tạo index mặc định ( là loại BTREE) cho 2 trường này
SELECT
CREATE INDEX idx_user_id ON subordinates (user_id);
CREATE INDEX idx_sub_id ON subordinates (sub_id);
Đến đây chạy thử lại xem, chắc là đã được cải thiện rõ rệt, nhưng có thể vẫn còn cao đấy. Của mình là chạy mất hơn 2 giây. Đến điểm tiếp theo ở trên mà mình nói, các viết join bảng dựa trên điều kiện như trên, ở trong MySQL mà nói, thì hoàn toàn không phải là best practice, mặc dù với query không tốn nhiều thời gian để truy vấn thì bạn sẽ không nhận ra điều gì khác biệt. Thử viết lại query trên theo đúng kiểu dùng INNER JOIN
SELECT
u.id
, u.name
, s1.sub_id as 9th_level_sub
, s2.sub_id as 8th_level_sub
, s3.sub_id as 7th_level_sub
, s4.sub_id as 6th_level_sub
, s5.sub_id as 5th_level_sub
, s6.sub_id as 4th_level_sub
, s7.sub_id as 3rd_level_sub
, s8.sub_id as 2nd_level_sub
, s9.sub_id as 1st_level_sub
FROM users u INNER JOIN subordinates s1 ON u.id = s1.user_id
INNER JOIN subordinates s2 ON s1.sub_id = s2.user_id
INNER JOIN subordinates s3 ON s2.sub_id = s3.user_id
INNER JOIN subordinates s4 ON s3.sub_id = s4.user_id
INNER JOIN subordinates s5 ON s4.sub_id = s5.user_id
INNER JOIN subordinates s6 ON s5.sub_id = s6.user_id
INNER JOIN subordinates s7 ON s6.sub_id = s7.user_id
INNER JOIN subordinates s8 ON s7.sub_id = s8.user_id
INNER JOIN subordinates s9 ON s8.sub_id = s9.user_id
WHERE u.id = 1
Có vẻ đã khá hơn khá nhiều, ở đây câu truy vấn cuối cùng đã chịu xuống dưới mức 1 giây, là chuẩn mà mình tự đặt ra, ở mức "có thể chấp nhận"
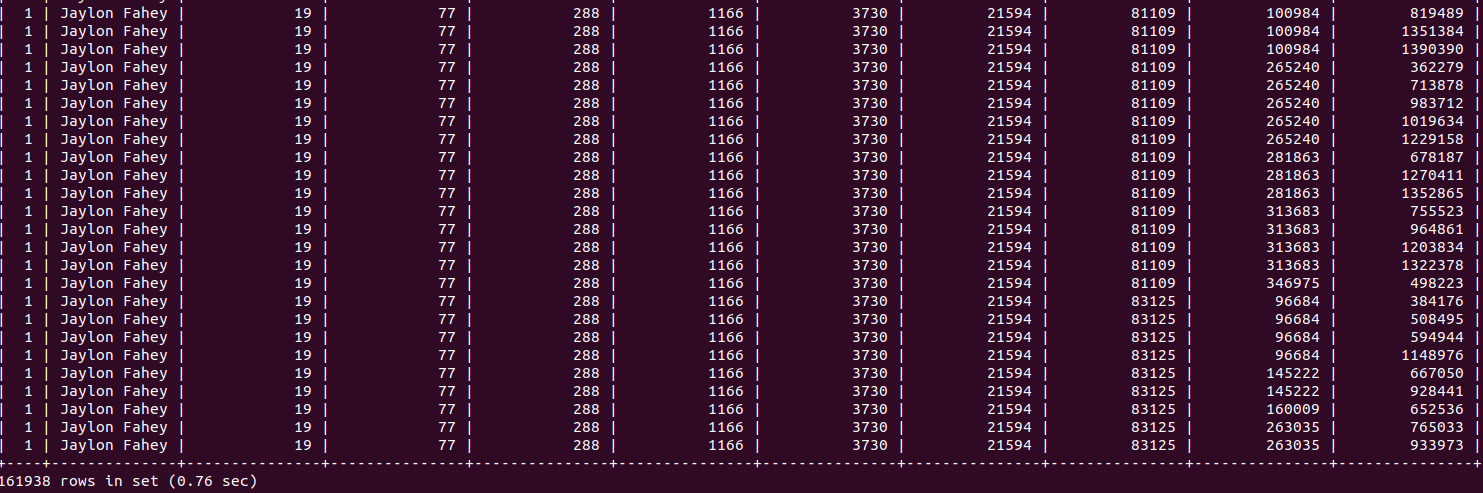 Kết quả này có vẻ khác biệt cũng tương đối lớn giữa những người thử làm theo. Mức thấp nhất mà mình nhận được là 0,187s , nhưng tất cả đều dưới 1 giây hết. Hi vọng các bạn làm theo sẽ không có gì khác biệt lắm. Đây cũng là điểm cả nhóm chưa tìm ra nguyên nhân. Tuy nhiên, đến đây chúng ta cũng có thể thực sự khép lại lời giải này, và nhìn lại để nhận xét vài điều về nó. Trước tiên, hãy nói về ưu điểm của nó :
Kết quả này có vẻ khác biệt cũng tương đối lớn giữa những người thử làm theo. Mức thấp nhất mà mình nhận được là 0,187s , nhưng tất cả đều dưới 1 giây hết. Hi vọng các bạn làm theo sẽ không có gì khác biệt lắm. Đây cũng là điểm cả nhóm chưa tìm ra nguyên nhân. Tuy nhiên, đến đây chúng ta cũng có thể thực sự khép lại lời giải này, và nhìn lại để nhận xét vài điều về nó. Trước tiên, hãy nói về ưu điểm của nó :
- Đầu tiên, có thể nói là nó là một giải pháp tương đối hoàn thiện hơn trong khuôn khổ sql thuần túy. Nếu như theo cách 1, chúng ta phải phụ thuộc vào một trường thông tin "ngầm hiểu", và trường này là cốt lõi cho giải pháp của chúng ta, thì ở đây, chúng ta vẫn phụ thuộc một chút vào trường thông tin ngầm hiểu (
level), nhưng trường này chỉ mang tính chất bổ trợ, cho chúng ta biết chính xác phải đệ quy bao nhiêu lần, ngoài ra nó không có ý nghĩa gì khác. Hơi hack 1 chút, nhưng với trường hợp cụ thể này, khi mà chúng ta dùngINNER JOIN, với bộ dữ liệu không có khoảng trống như thế này, chúng ta có thể thay nó bằngLEFT JOIN, và khi đó , việc bạn có đệ quy thừa ra vài lần cũng không làm ảnh hưởng đến kết quả. Các bạn có thể thử bằng cách tự viết thêm 1~2 level nữa, thayINNER JOINbằngLEFT JOIN, kết quả trả về vẫn thế, chỉ có chậm đi thôi ( vì chúng ta đã join bảng nhiều hơn ). Tùy theo hoàn cảnh cụ thể, đôi khi có thể đây cũng là 1 yếu tố đáng để đánh đổi. - Tiếp theo, nó khá là linh hoạt. Với cách làm này, việc bạn muốn lấy phụ thuộc trên hay phụ thuộc dưới, hay cả phụ thuộc trên lẫn dưới, lấy mỗi chiều theo bao nhiêu level, về bản chất là làm như nhau cả, không khác gì mấy. Cũng như trên, áp vào bài toán cụ thể, đây có khi lại là điều bạn cần hơn.
Nhược điểm thì kể ra nó cũng nhiều :
- Performance, dù chúng ta đã cố hết sức, nhưng về bản chất mà nói thì, đã join nhiều bảng như thế, kiểu gì cũng sẽ chậm hơn truy vấn trong 1 bảng như cách đầu tiên. Bộ dữ liệu 1 triệu bản ghi, nghe thì to chứ thật ra trong thực tế, nó chỉ là dạng tôm tép, việc bạn gặp bộ dữ liệu lớn hơn thế này vô số lần là chuyện tương đối phổ biến. Lúc đó thì thật sự là không cưỡng được đâu.
- Cái này thì không hơn không kém so với cách đầu tiên, nó vẫn là một giải pháp kết hợp giữa cả 2 tầng appiication và database, nên một mục tiêu tương đối tổng quát trong lập trình, đó là độc lập về mặt trách nhiệm giữa từng khâu, từng bộ phận là không thể đạt được. Vẫn cứ phải do 1 người vừa đảm nhận phần code app, vừa làm truy vấn query thực hiện, không thể do 2 team không quen biết nhau, 1 bên làm app, 1 bên làm query ngồi ghép lại mà thành được
- Và thật sự mà nói thì, cách làm này tương đối khó đọc hiểu hơn, nhất là trong tình trạng hiện nay khi mà ( cá nhân mình đánh giá, hơi phiến diện ), các lập trình viên trẻ thật sự không mạnh lắm về mảng database so với thế hệ của 5~7 năm trở về trước.
- Nếu đang tiện có MySql phiên bản mới, các bạn chạy thử
ANALYZE EXPLAINvới query trên, cũng có thể thấy nó không được tối ưu cho lắm đâu, còn tồn tại nested inner join loop khác nhiều. Nhưng để optimize nó hơn nữa, nếu có thể làm được thì chắc cũng cần đầu tư thêm nhiều thời gian. Tạm thời vì mục đích tìm hiểu, thì cả hội thấy đến đây cũng là tạm đủ, nên cũng chưa ai đi sâu hơn. Nếu thấy có hứng thú, dữ liệu sample đã có, các bạn hoàn toàn có thể tự đi tiếp
| -> Nested loop inner join (cost=74182.36 rows=162854) (actual time=0.302..288.469 rows=161938 loops=1)
-> Nested loop inner join (cost=18049.27 rows=39624) (actual time=0.275..76.380 rows=40328 loops=1)
-> Nested loop inner join (cost=4391.73 rows=9641) (actual time=0.249..20.997 rows=10063 loops=1)
-> Nested loop inner join (cost=1068.76 rows=2346) (actual time=0.227..5.803 rows=2505 loops=1)
-> Nested loop inner join (cost=260.26 rows=571) (actual time=0.199..1.819 rows=638 loops=1)
-> Nested loop inner join (cost=63.54 rows=139) (actual time=0.174..0.583 rows=168 loops=1)
-> Nested loop inner join (cost=15.68 rows=34) (actual time=0.152..0.229 rows=43 loops=1)
-> Nested loop inner join (cost=4.03 rows=8) (actual time=0.126..0.136 rows=9 loops=1)
-> Index lookup on s1 using user_id_sub_id_index (user_id=1) (cost=1.20 rows=2) (actual time=0.080..0.082 rows=2 loops=1)
-> Index lookup on s2 using user_id_sub_id_index (user_id=s1.sub_id) (cost=1.21 rows=4) (actual time=0.022..0.025 rows=4 loops=2)
-> Index lookup on s3 using user_id_sub_id_index (user_id=s2.sub_id) (cost=1.06 rows=4) (actual time=0.006..0.010 rows=5 loops=9)
-> Index lookup on s4 using user_id_sub_id_index (user_id=s3.sub_id) (cost=1.02 rows=4) (actual time=0.005..0.008 rows=4 loops=43)
-> Index lookup on s5 using user_id_sub_id_index (user_id=s4.sub_id) (cost=1.01 rows=4) (actual time=0.005..0.007 rows=4 loops=168)
-> Index lookup on s6 using user_id_sub_id_index (user_id=s5.sub_id) (cost=1.01 rows=4) (actual time=0.004..0.006 rows=4 loops=638)
-> Index lookup on s7 using user_id_sub_id_index (user_id=s6.sub_id) (cost=1.01 rows=4) (actual time=0.005..0.006 rows=4 loops=2505)
-> Index lookup on s8 using user_id_sub_id_index (user_id=s7.sub_id) (cost=1.01 rows=4) (actual time=0.004..0.005 rows=4 loops=10063)
-> Index lookup on s9 using user_id_sub_id_index (user_id=s8.sub_id) (cost=1.01 rows=4) (actual time=0.004..0.005 rows=4 loops=40328)
|
Chốt lại một câu thì, nếu bạn gặp bài toán này, xem cách 1 mà giải quyết. Nếu bạn thích nghiềm ngẫm thêm một chút, thì cách 2 tương đối lạ hơn, cũng đáng để xem.
Đang vui, ngồi lại làm chén nữa đã
Đến đây, có thể coi là đã giải được bài toán bọn mình tự đặt ra ban đầu, là truy vấn với bộ dữ liệu có nhiều level phụ thuộc vào nhau. Không chỉ trong framework laravel, mà mình tin là dù sử dụng bất cứ ngôn ngữ gì, công cụ framework nào, miễn là bạn sử dụng một hệ quản trị dữ liệu quan hệ tương tự như MySQl, bạn đều có thể áp dụng 1 trong 2 giái pháp nêu trên vào trong dự án của mình. Có điều, câu chuyện muốn vẽ ra vẫn chưa thực sự kết thúc. Xem lại câu hỏi đầu tiên gợi ra đề tài này cho bọn mình, thì cấu trúc mà bạn đó đang có không có những yếu tố cần có trước để áp dụng cả 2 cách được nêu ra, đồng thời bạn đó cũng nói, sản phẩm đã chạy, không tính đến chuyện đập đi làm lại được. Đây là một tình huống cực kì hợp lí và rất phổ biến, vậy liệu chúng ta có thực sự phải bó tay ở đây không ? Hi vọng là không. Bài toán của chúng ta đơn giản là tiến thêm 1 bước nữa : với bộ dữ liệu không như ý, liệu chúng ta có quy được nó về 1 trong 2 cách giải trên kia không.
Xác định yêu cầu bài toán.
Lúc này, yêu cầu của chúng ta có 1 chút thay đổi. Chúng ta đã xác định là, sẽ áp dụng 1 trong 2 cách giải trên, việc chuyển đổi dữ liệu sẽ chỉ cần diễn ra 1 lần, nên yêu cầu về performance không quá cao, vì chỉ làm 1 lần nên chậm một chút cũng được, miễn sao là chạy được. Tuy nhiên, cần đảm bảo làm sao, nó sẽ vẫn tương thích được với cả code của phần application đang chạy từ trước lẫn sau này, vì nếu tránh được thì không ai muốn dừng dịch vụ lại để thực hiện bảo trì hết.
Xong, tiếp theo là đến dữ liệu mẫu. Tập dữ liệu ở trên có sẵn trường level rồi, nhưng giờ chúng ta hãy coi như chưa có nó, thì đấy sẽ là tình trạng ban đầu. Ta tạo một cột mới, tạm gọi là new_level, tạm thời là NULL hết, và mục tiêu của chúng ta là, làm sao không động đến cột level, nhưng đưa dữ liệu của new_level về thành giống y hệt như thế.
ALTER TABLE users ADD COLUMN new_level(int);
Cần lao vi tiên thủ
OK, làm thử xem sao. Có điều đến đây, thực sự là mình cũng không chắc chắn lắm về chuyện nên làm thế nào nữa. Mỗi bài toán thực tế đều có hoàn cảnh riêng của nó, và cần hướng tiếp cận riêng. Việc tìm ra lời giải, nhất là cho những trường hợp không bị ràng buộc về mặt performance như thế này là rất nhiều, mọi con đường đều dẫn tới thành Rome. Những gì sau đây chỉ là một trong những cách đó, mình sẽ cố theo mức tối đa để trình bày theo hướng thiên về hướng suy nghĩ nhiều hơn là chi tiết, cụ thể. Đầu tiên, cứ cách dễ nhất mà đi đã. Bài toán mang tính chất đệ quy, chỉ thực hiện 1 lần, nên ta cũng không cần viết cao siêu làm gì cả, viết query đơn giản mà chạy nhiều lần cũng được. Vì là đệ quy nên thường thì sẽ theo kiểu đi từ trên xuống, hoặc đi từ dưới lên, tuy nhiên ở đây ta thấy, trong bảng subordinates, những user ở level cao nhất sẽ không phụ thuộc vào ai hết, nên sẽ không bao giờ xuất hiện dưới tư cách là cấp dưới ở đây hết, như thế ta có thể xác định được họ. Vậy đi từ cao nhất xuống đi. Với level đầu tiên trước, thử xem ta có lấy ra được nó không
SELECT count(*) FROM users LEFT JOIN subordinates ON users.id = subordinates.sub_id WHERE subordinates.sub_id IS NULL
đừng nói mất bao lâu, biết rằng ta lấy ra đúng kểt quả mong muốn ở đây là 4 đã. Chứng tỏ là làm được. Tiến hành update dữ liệu mới cho tầng đầu tiên nào.
UPDATE users LEFT JOIN subordinates ON users.id = subordinates.sub_id SET users.new_level = 1 WHERE subordinates.sub_id IS NULL;
Xong level đầu tiên, lúc này ta đã có thể phân biệt giữa tầng đã được thực hiện và tầng chưa thông qua trường new_level, có vẻ khả quan. Tuy nhiên, nếu làm thử, các bạn có thể dễ dàng nhận thấy 1 điều, chỉ với bước đầu tiên này thôi, khi thực hiện việc update thông qua 2 bảng, mà trong 2 bảng đó lượng dữ liệu đều lớn, có đánh index (index làm tăng tốc độ tìm kiếm nhưng cũng làm giảm tốc độ update), thật sự là quá chậm. Đi theo hướng này tiếp cũng chưa hẳn là đã ổn lắm, trong khi đó thực ra về bản chất, công việc chúng ta cần thực hiện ở đây chỉ đơn giản là xác định xem có những users nào cần update, và cùng lắm là xác định xem đã hoàn thành việc update hay chưa. Vì thế, theo ý kiến cá nhân, mình nghĩ thay vì thao tác các bảng cồng kềnh, nên tận dụng tới mức tối đa việc tạo các bảng tạm, nhỏ hơn, chứa những thông tin chúng ta cần. Vì thực sự thì việc khai báo và sử dụng biến trong ngôn ngữ query của MySQl , mình không có nhiều kinh nghiệm và cũng không nghĩ là nó thực sự hiệu quả ở đây. OK, đi tiếp. Đầu tiên là, xem chúng ta đã xong việc chưa
SELECT count(*) FROM users WHERE new_level IS NULL;
Chừng nào còn ra con số khác 0, chừng đó việc của ta còn chưa dừng lại. Tiếp theo, để đỡ phải bận tâm tới việc chúng ta đã thực hiện bao nhiêu lần, đang ở mức level nào, nên tiến hành theo kiểu, trước khi thêm 1 level mới, ta cứ tăng cho tất cả tầng cũ thêm 1 đã, rồi những bản ghi mới được tác động sẽ có giá trị bằng 1, dễ nhớ hơn nhiều.
UPDATE users SET new_level = new_level + 1 WHERE new_level IS NOT NULL;
Xong việc ngon xơi. Cái ta cần làm tiếp theo, đại loại có thể hình dung sẽ có mấy bước :
- Lấy ra
idcủa các user, cónew_levelkhác NULL và nhỏ nhất. Đây chính là những user của tầng thấp nhất mà ta đã xử lí xong. - Lấy ra
sub_idtừ bảngsubordinatestương ứng vớiuser_idnằm trong các giá trị bên trên. Đây chính là những user của tầng tiếp theo cần xử lí. - Update bảng
users, gán cho những user cóidnằm trong các giá trị ở trên giá trị của trườngnew_levelbằng 1.
Sẽ rất tốt nếu ta có thể thực hiện từng đó việc bằng cách nhóm tất cả thông tin cần thiết về dạng bảng, trong đó chứa tất cả thông tin cần thiết. Khi đó chỉ cần xử lí UPDATE là xong. Nhưng việc nhóm như thế, khá khó, và mình đồ là cũng khá phức tạp. Nên suy nghĩ đầu tiên của mình ở đây là, như đã nói ở trên, thực hiện từng việc nhỏ và lưu tạm kết quả lại, dưới dạng 1 bảng tạm, chỉ tồn tại để phục vụ cho việc update dữ liệu của chúng ta.
CREATE TABLE temp AS SELECT sub_id from subordinates INNER JOIN users ON subordinates.user_id = users.id AND users.new_level = (SELECT MIN(new_level) FROM users WHERE new_level IS NOT NULL);
Mình lựa chọn cách lưu tạm dữ liệu sau 2 bước đầu vào 1 bảng temp, vì nghĩ như thế là vừa đủ về tốc độ và độ phức tạp của query, nhưng nếu bạn thích, bạn có thể lưu tạm kết quả của những bước nhỏ hơn, hay to hơn, tùy ý. Bước 3, thay vì tương tác giữa các bảng to, sẽ thành tương tác giữa 1 bảng to và 1 bảng kết quả tạm nhỏ hơn khá nhiều.
UPDATE users INNER JOIN temp ON users.id = temp.sub_id SET users.new_level = 1;
Cả 2 truy vấn đều tương đối nhanh, có lẽ là nhanh hơn rất nhiều so với việc ngồi nghĩ xem, liệu có thể làm tốt hơn được không. Cứ tuần tự mà tiến như vậy, cuối cùng chúng ta sẽ thực hiện được việc chuyển đổi toàn bộ dữ liệu. Trong suốt cả quá trình, không có trường dữ liệu cũ nào bị xóa, tất cả các trường dữ liệu mới được thêm vào đều không có ràng buộc gì đi kèm, nên xác suất xảy ra lỗi trong quá trình chuyển giao có thể đánh giá là tương đối thấp. Tất nhiên, để cho chắc chắn thì các bạn luôn luôn nên backup dữ liệu cẩn thận trước khi thao tác với database. Không như tầng app, database thường là không có các cơ chế bảo hiểm tự động cho người thích nghịch dại.
Lời kết.
Trên đây chỉ là một chút nhìn lại cả quá trình trao đổi của cả nhóm, nó hoàn toàn không phải là một giải pháp hoàn thiện cho một vấn đề nào, kể cả đề bài mà mình tự đặt ra từ đầu. Hướng giải cho một bài toán là vô tận, và chúng ta luôn luôn có thể tự đặt cho mình câu hỏi : giải pháp trong tay tôi đang có ưu điểm hay nhược điểm gì ? Liệu còn có giải pháp nào khác, ưu nhược điểm của nó ? Chẳng hạn, với lượng dữ liệu lớn và truy vấn nặng, bạn có thể nghĩ đến hướng chuyển qua dùng NoSQL, vốn có ưu thế hơn trong những tình huống kiểu này. Hoặc bạn có thể đánh giá lại profit (nâng cao trải nghiệm người dùng) của tính năng này, so với cost ( độ phức tạp để duy trì code và thời gian để triển khai ), qua đó đưa ra requirement khác phù hợp hơn ? ... Như bạn đã thấy, khởi nguồn cho bài viết này là một câu hỏi khác, tưởng chừng như khá ngắn và đơn giản. Hi vọng rằng đâu đó trong bài viết này, sẽ lại là một cảm hứng khác cho các bạn, để bắt tay vào tìm hiểu một vấn đề mà bạn thấy còn chưa thỏa đáng.
P/S Đôi dòng nhắn gửi
Thời gian để mình hoàn thành bài viết này cũng mất vài hôm, mỗi ngày làm một chút. Trước khi kịp publish bài viết, lại một Vụ việc nho nhỏ xảy ra. Cũng có đôi lời Trần tình khá cảm động được đưa ra rồi. Khá là thỏa đáng, nếu có được đề cử "Best speech of the year" mình cũng không lấy làm ngạc nhiên đâu.

Tuy nhiên, nó cũng không phải là câu chuyện mới nói lần đầu, chắc cũng không ít bạn ở đây ý thức được việc nó đã kéo dài nhiều năm nay rồi. Chuyện thanh minh thì, cũng mới cách đây không lâu đâu, content thì giờ hình như bị xóa đi rồi, mình cũng lười mò lại, ai có đọc qua vụ đó, nhìn đường link chắc vẫn nhớ mình đang nói đến chuyện gì : https://www.facebook.com/notes/nguyen-huu-binh/hãy-trả-lại-cho-topdevvn-sự-trong-sạch/10158294942824550/
Với tư cách là người dùng viblo từ những ngày đầu tiên, có được vài bài viết đếm trên đầu ngón tay, trending còn chưa bao giờ leo đến, nói thật ra câu chuyện trên nó chả ảnh hưởng gì đến mình cả. Nhưng mà nhìn vào nó bực. Đôi dòng này chủ yếu để bày tỏ thái độ thôi, với lại có đôi chút gọi là "raise awareness" . Cũng chả chắc các bạn ấy có liếc mắt đến cái bài viết này không, nhưng mà, Dăm ba cái câu chuyện trà đá thuốc lá của anh em, viết ra đây cho mọi người cùng luận bàn chém gió góp vui thôi, mình không muốn thấy bài viết này tự nhiên lại xuất hiện trên Techtalk hay TopDev.
PPS
Bài viết trên có 1 số thông tin chưa được chuẩn lắm, cụ thể là cách làm số 2 bị sai. Mình có update thêm Part II
All rights reserved
