Nghệ thuật xử lý background job
Bài đăng này đã không được cập nhật trong 6 năm
Đây thực chất là phần tiếp theo của câu chuyện anh chàng buôn chuối trong bài viết này

First things first
Yeah, lại là mình đây, Minh Monmen trong vai trò chàng trai buôn chuối rảnh rỗi ngồi viết lách linh tinh. Sau khi thu thập được rất nhiều kinh nghiệm từ việc bán chuối bán chuối, mình tự nhận thấy một số người coi trọng những kỹ sư thực thụ hơn những con buôn trái nghề. Nên là trong lần này mình sẽ hóa thân thành 1 kỹ sư phần mềm giả trang để tìm hiểu về background job và tiếp tục câu chuyện còn dang dở lần trước ở mức độ sâu hơn.
Trong bài viết này, ngoài việc tổng hợp thông tin từ một số nguồn tin chính thống, mình cũng sẽ chia sẻ thêm về những cách thiết kế và xử lý job, queue, batch processing,... mà mình đã thực hiện sau nhiều thương vụ buôn chuối của mình.
Tuy nhiên, để có thể đọc hiểu trôi chảy những thứ mà mình nêu ra ở đây thì các bạn nên có 1 số kiến thức nền tảng về:
- Background job
- Queue
- Event-driven
- Cronjob
- Batch processing
- Concurrency and lock
Nhiêu đó đã, giờ bắt đầu nào.
Các loại job và usecase của chúng
Trong 1 bài viết rất chi tiết và cụ thể của bác Bill về vấn đề này đã đề cập rõ từng loại job cũng như usecase của chúng rồi, mình sẽ chỉ tóm tắt lại cho các bạn thôi. (Nhưng hãy đọc bài viết kia để có cái nhìn chi tiết hơn)
Trên khía cạnh trigger thì background job có thể xuất phát từ 2 loại trigger sau:
- Event-driven trigger: Là job được khởi chạy dựa trên 1 event nào đó xảy ra trong hệ thống. Có thể là việc 1 API được gọi, 1 Object được lưu vào DB,...
- Schedule-driven trigger: Là job khởi chạy dựa trên thời gian. Đó có thể là job định kỳ (hàng ngày, hàng giờ,...) hoặc job vào một thời điểm hay sau 1 thời điểm nhất định nào đó.
Event-driven job
Bạn sẽ sử dụng event-driven job khi nó phụ thuộc vào việc xuất hiện của những sự kiện không biết sẽ xảy ra khi nào như:
- Gửi email cho user khi họ đăng ký
- Xử lý video sau khi user upload lên
- Tạo report cho user sau khi họ submit yêu cầu ...
Event-driven job thường được trigger thông qua hệ thống job queue và worker. Mỗi khi có event, job,... được đẩy vào job queue thì worker sẽ lắng nghe và xử lý lần lượt.
Mô hình của event-driven job là xử lý hàng loạt cùng lúc dựa trên nhiều worker chạy song song. Do đó loại job này có tính scalable
Schedule-driven job
Schedule-driven được sử dụng cho các tác vụ thường xuyên, xác định được trước thời gian chạy hoặc lặp đi lặp lại như:
- Publish bài post đã được lên lịch sẵn
- Dọn dẹp file tạm hàng ngày
- Gửi email báo cáo hàng tuần ...
Schedule-driven job thường được trigger thông qua crontab, interval hay forever repeat code.
Mô hình của schedule-driven job thường là một job được xử lý tại 1 thời điểm theo thời gian được đặt sẵn. Vì vậy loại job này KHÔNG có tính scalable
Cách giao lưu phối kết hợp
Chắc vậy là đủ để các bạn hình dung sơ sơ về ứng dụng của 2 loại hình background job này rồi nhỉ? Trong khuôn khổ hạn hẹp của bài viết này thì mình sẽ giới thiệu cho các bạn 1 vài cách kết hợp 2 loại background job trên và tình huống sử dụng cụ thể khi mình xây dựng các ứng dụng.
Bài toán 1: Đếm số lượng view trang web / sản phẩm
Đây tưởng chừng là một bài toán có yêu cầu đơn giản mà việc thực hiện cũng lại đơn giản luôn. Cứ mỗi lần có 1 lượt view trang web hay 1 sản phẩm của bạn thì cộng cho sản phẩm đó 1 lượt view.
Điểm quan trọng nhất của việc scale background job chính là xử lý đồng thời nhiều job cũng 1 lúc. Do vậy vấn đề về Atomic operation phải được đặt lên hàng đầu. Chi tiết bạn có thể google search thêm. Ở đây mình sẽ bỏ qua việc các vấn đề liên quan tới Atomic operation trong việc lưu trữ data của các bạn.
1. Cách nông dân
Đơn giản là mỗi khi API view product được gọi thì bạn cộng thêm 1 view vào database

Vấn đề gặp phải:
- Blocking IO: Việc +1 view vào database làm chậm response của người dùng, mặc dù người dùng không cần thiết phải chờ hành động này
- Performance: Khi số lượng người dùng sản phẩm lớn, ví dụ có 1000 người cùng view tại 1 thời điểm thì DB của bạn sẽ phải chịu 1000 câu query update 1 lúc. Oh...
2. Sử dụng event-driven job
Giờ thay vì API gọi thẳng vào DB thì ta đẩy nó vào 1 cái Job Queue. Sẽ có 1 cơ số worker ở phía sau chờ sẵn để xử lý những cái job này.

Vấn đề đã giải quyết:
- Non-blocking IO: Việc +1 view bây giờ đã gần như không ảnh hưởng tới thời gian response của người dùng do thời gian để đẩy job queue thường nhỏ hơn nhiều so với thời gian query update
- Throttling: Giờ nếu bạn có 10 worker, tại 1 thời điểm 1 worker chỉ xử lý 1 job. Vậy thì cùng lúc bạn sẽ chỉ có 10 job chạy song song, tức là dù bạn có 1000 view sản phẩm cùng lúc thì tại 1 thời điểm cũng chỉ có 10 câu lệnh update db được chạy.
Vấn đề còn tồn tại:
- Performance: Vâng vẫn là cái vấn đề về performance, chỉ là ở 1 cấp độ khác mà thôi. Thay vì DB của các bạn phải chịu tải lớn, thì các bạn đã đánh đổi điều đó bằng việc xử lý được ít job hơn. Và vì xử lý ít job hơn nên các bạn sẽ dễ dẫn tới trường hợp bị dồn job do worker không xử lý kịp.
- Busy IO: 1 vấn đề mà giải pháp này vẫn còn đó là nó vẫn còn rất gánh nặng về mặt IO cho DB. Với 1000 view, DB của các bạn vẫn phải chịu 1000 câu lệnh update liên tục. Điều đó làm ảnh hưởng rất nhiều tới hiệu năng của những tác vụ khác.
3. Sử dụng kết hợp 2 loại job
Để giải quyết vấn đề về DB bottle neck thì ta sẽ nghĩ ngay tới tầng đệm (caching). Tầng caching là tầng xử lý tốt phần IO hơn rất nhiều so với các loại DB cơ bản. Do vậy chúng ta sẽ đẩy gánh nặng này cho tầng caching bằng cách tạo ra 1 scheduled job lặp đi lặp lại để ghi data từ cache xuống DB.

Như các bạn thấy, khi các event job +1 view cho sản phẩm thì kết quả này được ghi vào tầng cache. Sau đó các scheduled job sẽ định kỳ lấy tổng số view chưa được đếm này (n view) từ trong cache ra để ghi vào DB (+n view)
Vấn đề đã giải quyết:
- Performance: Do view được lưu tạm thời vào trong cache, do vậy ta có thể tận dụng sức mạnh IO của cache để nâng số worker đồng thời cũng như giảm được thời gian xử lý từng event job. Do đó tình trạng dồn queue sẽ được xử lý.
- Throttling hơn nữa: Việc phát sinh query update vào DB chỉ xảy ra trên các scheduled job, do vậy ta đã giảm thiểu số lần update DB thành 1 con số cố định và có thể cân đối được. Ví dụ nếu scheduled job chạy 10s 1 lần thì trong 1 phút sẽ chỉ có tối đa 6 query update DB được tạo ra (thay vì cả 1000 query update như trước)
Vấn đề còn tồn tại:
- Delay data: Dữ liệu view của sản phẩm sẽ không được update theo thời gian thực mà sẽ có độ trễ tùy theo tần suất scheduled job. Tuy nhiên độ trễ này thường là chấp nhận được khi so sánh với những lợi ích nó mang lại.
Tips: Như mình đã nói ở trên, việc xử lý atomic operation là rất quan trọng trong việc xây dựng background job. Các bạn có thể thấy trong ảnh mình sử dụng operation -n và +n do cộng và trừ thường là atomic operation trên hầu hết các loại db/cache. Đây là 1 tip cho các bạn. Không nên get rồi set counter bằng 0 mà nên get rồi trừ counter đi giá trị hiện tại của nó để đảm bảo không bị mất dữ liệu view khi đang reset counter nhé.
Tips 2: Với redis thì các bạn không cần phải chơi trick trừ như trên, vì nó có sẵn 1 cái atomic operation là GETSET để các bạn reset counter rồi.
Bài toán 2: Gửi email thông báo hàng loạt
Đây là bài toán thường gặp ở các hệ thống tin tức, báo cáo,... khi mà định kỳ (hàng ngày, hàng tuần) phải gửi nội dung được tổng hợp tới nhiều người dùng. Vậy background job sẽ xử lý trường hợp này như thế nào?
1. Cách nông dân

Trong cách này thì chúng ta sẽ có 1 scheduled job siêu to khổng lồ chạy để lấy danh sách người dùng từ trong database, sau đó dùng danh sách này để gửi email cho tất cả user.
Vấn đề gặp phải:
- Thời gian xử lý lâu: Đương nhiên với duy nhất 1 scheduled job xử lý việc gửi email cho toàn bộ người dùng thì thời gian để xử lý hết được sẽ lâu đúng không? Tưởng tượng trong job này bạn phải lấy email, tạo content cho email đó, gửi email,... lần lượt cả ngàn lần.
- Khó retry: Với 1 job siêu to khổng lồ như này thì việc gặp lỗi giữa quá trình chạy sẽ rất khó để giải quyết do việc chạy lại job sẽ buộc phải xử lý mọi thứ từ đầu, xử lý trùng lặp,...
2. Cách bớt nông dân

Ở đây scheduled job sẽ không đảm nhận việc thực hiện nhiệm vụ nữa mà sẽ đóng vai trò là người quản lý - tạo task cho nhiều event worker chạy song song thông qua Job queue
Vấn đề đã giải quyết:
- Scalable: Chúng ta đã giải quyết được tính chất không scale được của scheduled job khi mà giờ đây nó chỉ đóng vai trò tạo task và đẩy vào job queue cho các event worker xử lý.
- Thời gian xử lý nhanh:: Do có thể xử lý đồng thời qua các event worker nên thời gian xử lý tổng thể sẽ giảm xuống theo cấp số nhân
- Dễ dàng retry: Việc xử lý lỗi giờ đây dễ dàng hơn rất nhiều vì từng job sẽ handle việc gửi email cho 1 user cụ thể. Do đó nếu có lỗi thì cũng không ảnh hưởng tới user khác. Ngoài ra từng job nhỏ còn tự retry được luôn mà không phải chạy lại toàn bộ từ đầu.
Bài toán 3: ETL process
Nói qua 1 chút về thuật ngữ ETL (Extract Transform Load) thì đây là thuật ngữ để chỉ 1 quá trình xử lý xử liệu từ hệ thống nguồn tới hệ thống đích. Mà thật ra là quá trình này thường là để chuyển dữ liệu từ các hệ thống hoạt động (Operation) sang hệ thống phân tích và báo cáo (Analytic and Reporting).
Có rất nhiều tool được sinh ra cho quá trình này tuy nhiên có thể vì kiến thức của mình lúc ấy còn hạn chế hoặc do hệ thống của bên mình chưa khủng tới mức dùng những giải pháp đồ sộ đó mà mình đã chọn giải pháp đơn giản hơn là tự viết những tiến trình đồng bộ dữ liệu từ các hệ thống Operation tới hệ thống Analytic bằng Scheduled job.
Tất cả job và dữ liệu xử lý trong quá trình ETL phải được thiết kế để có thể retry hoặc chạy lại mà không bị trùng lặp hay dẫn tới sai sót.
1. Cách nông dân

Trong cách này, mình có duy nhất 1 job được scheduled để làm cả 3 quá trình Extract, Transform, Load. Idea thì rất đơn giản, cứ 1 tiếng bạn chạy 1 cái job lấy hết data từ DB nguồn trong thời gian vừa rồi, làm 1 số thao tác magic trên đống dữ liệu đó, rồi đẩy vào 1 DB đích. Hết
Cách xử lý này có 1 cái tiện là bạn có thể tạo 1 cái pipeline đơn giản để data lần lượt được xử lý qua cả 3 quá trình một cách tuần tự mà không phải lo nghĩ gì. Tuy nhiên đời không như là mơ. Bạn sẽ gặp các vấn đề tương tự như vụ gửi email ở trên, mà còn ở mức độ nghiêm trọng hơn vì:
- Thời gian xử lý lâu: Để dữ liệu chạy qua tất cả các quá trình này 1 lúc sẽ tốn thời gian và tài nguyên. Nếu để interval dài thì dữ liệu của bạn quá outdate. Nếu interval thấp thì job sau dễ chồng chéo lên job trước do job trước chưa chạy xong,...
- Retry: Again, vấn đề không retry được sẽ là vấn đề rất nhức nhối. Với multi-step job như này thì việc fail 1 step cuối sẽ khiến toàn bộ các step trước phải chạy lại, và... boom
Hãy cùng tìm hiểu cách tiếp cận tiếp theo
2. Cách bớt nông dân

Ở đây mình sử dụng 1 vài DB tạm để chứa các dữ liệu trong quá trình xử lý và tách 3 quá trình ETL ra thành 3 scheduled job khác nhau. Mặc dù cách này đã cải thiện về thời gian và việc xử lý lỗi trong quá trình chạy để retry từng phần được, song nó vẫn dựa trên mô hình scheduled, tức là không scale được. Cách này có thể chạy được ổn với time interval tương đối ngắn, lượng data giữa các bước sync không quá nhiều.
Đối với 1 record dữ liệu thì việc xử lý qua từng bước sẽ là tuần tự. Tuy nhiên với nhiều record dữ liệu thì 3 quá trình này trở thành song song nhau (chạy kiểu gối đầu). Do vậy thời gian tổng thể sẽ được rút ngắn kha khá
Vấn đề duy nhất bạn phải giải quyết đó chính là tracking status của dữ liệu. Tức là dữ liệu của bạn đã đi tới bước nào, được xử lý chưa, thành công hay thất bại, và quan trọng hơi là được sắp xếp xử lý 1 cách có thứ tự.
3. Cách loằng ngoằng

Phát triển tiếp mô hình phía trên và thêm yếu tố scaling bằng event job, mình sẽ có mô hình cuối cùng này. Trông có vẻ phức tạp vậy tuy nhiên về cấu trúc lại y hệt vụ gửi email ở phía trên thôi không có gì to tát cả.
Cách này đã giải quyết được gần như tất cả các vấn đề liên quan tới performance, scale, delay time,... mà ta gặp phải phía trên. Nó phù hợp với các hệ thống sync dữ liệu có độ trễ thấp do có thể giảm được thời gian delay giữa các lần chạy.
Tuy nhiên, vinh quang nào cũng phải trả giá bằng máu và nước mắt. Các bạn sẽ phải đánh đổi bằng việc:
- Track data status: đánh dấu data đã xử lý tới bước nào
- Data paging: Các bạn phải có 1 cột id hay time đủ tin cậy để scheduled job có thể phân chia được từng khoảng dữ liệu cho event job xử lý đồng thời. Vì thế việc dữ liệu được tổ chức thế nào sẽ khá tricky đó nhé.
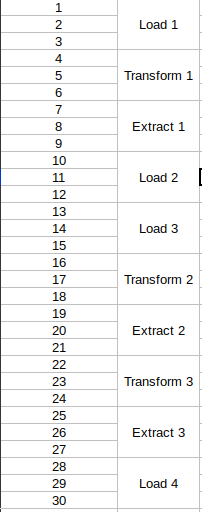
Đây là minh họa cho quá trình xử lý song song nhiều bản ghi cùng lúc bởi 3 loại job.
Tips: Tận dụng lợi thế về batch processing với từng job bằng việc tìm hiểu số record ghi đồng thời hiệu quả với từng loại DB. Ví dụ mongodb sẽ có mức ghi hiệu quả nếu mỗi job xử lý 1000 record đồng thời. Tham khảo thêm tại đây
Tổng kết
Qua bài viết trên mình đã đưa ra cho các bạn cái nhìn tổng quát về 2 loại background job cũng như 3 case ứng dụng thực tế trong việc kết hợp 2 loại job này để tăng khả năng xử lý của ứng dụng.
Mặc dù bài viết không có 1 mẩu code thực nào mà trông như thuần túy lý thuyết nhưng các bạn yên tâm rằng mọi mô hình bên trên đều đã được mình áp dụng trong thực tế và chỉ tổng kết lại kết quả và hiệu quả của nó cho các bạn mà thôi.
Có những mô hình mặc dù mình có nêu ra điểm chưa tốt nhưng nó cũng có thể xử lý khối lượng công việc khá lớn rồi đó. Ví dụ như mô hình 2 bài toán ETL đang xử lý vài chục triệu record dữ liệu hàng ngày từ 5 hệ thống với hơn 20 scheduled job có độ trễ dưới 2 phút. Hay mô hình 2 bài toán view cũng đang xử lý hơn 5 triệu job 1 ngày với 10 worker cho hệ thống notification thời gian thực mà chưa gặp vấn đề gì về performance. Do đó việc bạn chọn cách nào cho dự án của mình sẽ còn tùy vào tính chất và khối lượng công việc của các worker nữa.
Cám ơn các bạn đã quan tâm theo dõi đến đây. Hẹn gặp lại trong bài viết sau.
All rights reserved
