[Mysql] Đánh Index cho hiệu năng cao
Bài đăng này đã không được cập nhật trong 4 năm
Index còn được gọi là key trong MySQL là một dạng data structure được storage engine sử dụng để tìm kiếm cho nhanh. Chúng có còn một vài lợi ích khác chúng tôi sẽ nói về sau.
Index là 1 tiêu chí để đánh giá good performance, và trở nên quan trọng hơn nữa nếu data của bạn bắt đầu phình to ra. Database nhỏ thường load nhanh và có performance tốt khi không sử dụng index, nhưng với lượng dataset lớn, performance có thể tụt xuống rất nhanh. Thật không may, index thường bị quên lãng và hiểu nhầm, có ít index sẽ dẫn tới vấn đền performance. Đó là lý do tại sao chapter này xuất hiện sớm trong cuốn sách, thậm chí sớm hơn cả query optimization.
Index optimization có thể là phương pháp hữu hiệu nhất để tăng query performance. Index có thể tăng hiệu năng lên 10 lần, và index đã đc tối ưu có thể tăng hiệu năng gấp 100 lần so với những index đc coi là tốt. Việc tạo ra những index thực sự tối ưu yêu cầu bạn phải viết lại câu query, cho nên chapter này và chapter sau có liên hệ gần với nhau.
Indexing Basics
Cách đơn giản nhất để hiểu cách hoạt động của index trong MySQL là so sánh nó với mục lục của quyển sách. Để tìm một topic nào đó trong cuốn sách, bạn phải mở mục lục ra và tìm trang của topic đó.
Trong MySQL, storage engine sử dụng index theo cách tương tự. Nó tìm kiếm trong một data structure lưu trữ index. Khi nó tìm thấy index trong structure -> nó có thể refer đến row đang chứa index đó. Ví dụ:
mysql> SELECT first_name FROM sakila.actor WHERE actor_id = 5;
Column actor_id đã được đánh index. Khi tìm row thì MySQL sẽ sử dụng index structure để tìm actor_id = 5. Một index có thể bao gồm nhiều giá trị của một hoặc nhiều cột, nếu index nhiều hơn 1 cột, thứ tự cột là rất quan trọng, bởi vì MySQL chỉ hiệu quả nhất từ bên trái index -> bên phải index. Index cho 2 columm thì khác với 2 index cho 2 column.
If I Use an ORM, Do I Need to Care?
Câu trả lời ngắn gọn: YES. Bạn vẫn phải cần học về indexing, ngay cả khi bạn đang sử dụng ORM tool.
ORM đưa ra logic và syntax cho query, nhưng hiếm khi hỗ trợ query + index, trừ khi bạn sử dụng chúng trong hầu hết các trường hợp thông thường của query, giống như primary key lookup. Bạn không thể mong chờ ORM bởi vì sự phức tạp, sự xử lý tinh tế của index. Hãy đọc phần còn lại của chapter này nếu bạn phản đối ý kiến đó! Thỉnh thoảng thật là khó để mong chờ mọi người làm hết cho mình, cho nên hãy bỏ qua ORM đi.
Types of Indexes
Có rất nhiều loại index, mỗi loại được thiết kế để thực hiện tốt theo những mục đích khác nhau. Index được cài đặt trong storage engine layer, không phải server layer. Do đó, chúng không có tiêu chuẩn chung nào cả: công việc đánh index gần như khác nhau ở mỗi engine, và không phải tất cả engine đều support tất cả các loại index. Kể cả đối với nhiều engine support chung 1 kiểu index, chúng có thể implement khác nhau.
Hãy cùng tìm hiểu các loại index trong MySQL đang đc support, lợi ích và điểm yếu của chúng.
B-Tree indexes
Khi mọi người nói về index mà không nhắc đến kiểu gì, thì có thể hiểu là họ đang nói về B-Tree index - sử dụng B-Tree data structure để lưu trữ index. Hầu hết MySQL storage engine đều support loại này. Archive engine là một trường hợp đặc biệt, nó không support index 1 chút nào cho đến MySQL 5.1, khi bắt đầu nó chỉ support duy nhất 1 column có autor_increment.
Chúng tôi nói chung chung là sử dụng “B-Tree” nhưng có thể khác nhau với từng storage engine. Ví dụ NDB cluster storage enige sử dụng T-Tree structure để lưu index, kể cả khi chúng đc đánh nhãn là BTREE, và InnoDB sử dụng B+Tree. Các biến thể của structure và algorithm không phải là vấn đề đề cập trong cuốn sách này.
Storage engine sử dụng B-Tree index theo nhiều cách, mà theo đó hiệu năng sẽ khác nhau. Ví dụ, MyISAM sử dụng nén index làm cho index kích thước nhỏ hơn, nhưng InnoDB để nguyên không làm gì cả. Và MyISAM index refer đến row thông qua physical location của nó. Còn InnoDB refer bằng primary key value. Mỗi biến thể đều có ưu nhược điểm.
Ý tưởng chung của B-Tree là tất cả các dữ liệu được sắp xếp theo một trật tự, và mỗi leaf page có khoảng cách đến root giống nhau. Hình 5-1 minh họa B-Tree index, và nhìn vào đấy ta có thể thấy cách hoạt động của index trong InnoDB. MyISAM sử dụng cấu trúc khoác, nhưng vẫn chung nguyên lý cơ bản.
Một B-Tree index sẽ tăng tốc truy cập dữ liệu vì storage engine không phải scan cả table để tìm giá trị mong muốn. Thay vì đó, nó bắt đầu từ root node. Root node chứa đường đi tới các child node, và storage engine đi theo đường đi để tìm node kết quả. Mỗi node cha có giá trị lớn hơn node con này và nhỏ hơn node con khác. Thậm chí storage engine còn xác định đc hay không giá trị đó có còn tại hay không.
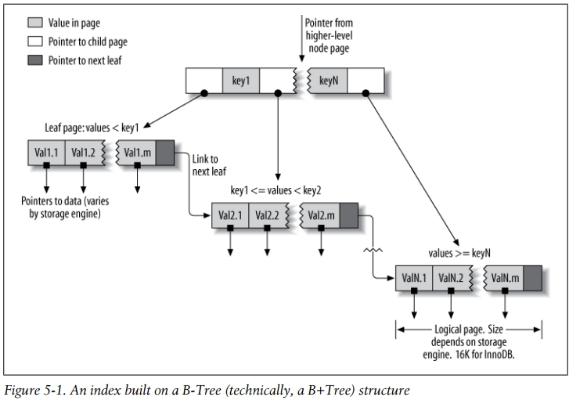
Leaf page đặc biệt, bởi vì nó trỏ tới index data thay vì next page. Hình minh họa của chúng tôi chỉ show mỗi một node page và leaf page của nó nhưng thật ra là có rất nhiều level, rất nhiều node, độ sâu của tree phụ thuộc vào độ lớn của table.
Bởi vì B-Tree chứa index theo 1 thứ tự nào đó cho nên chúng hữu dụng khi tìm kiếm theo range. Ví dụ khi tìm kiếm người có tên giữa chữ I và K, gỉa sử ta có bảng:
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f')not null, key(last_name, first_name, dob) );
Index chứa giá trị từ lastname + firstname + dob. Hình 5-3 miêu tả cách sắp xếp của index.
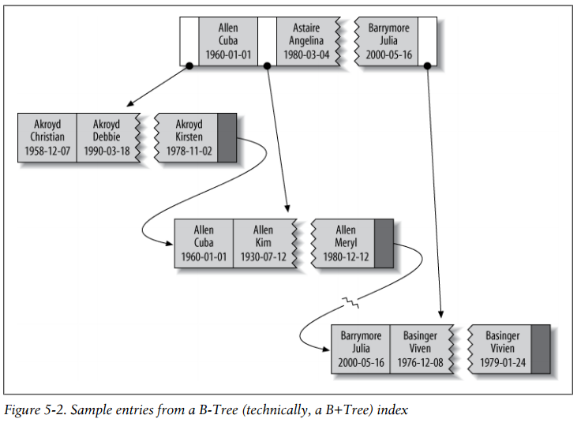
Chú ý rằng index sắp xếp dữ liệu theo thứ tự của cột trong bảng của câu CREATE TABLE. Hãy nhìn vào 2 entry cuối, 2 người có tên trùng nhau nhưng ngày sinh khác nhau, nó sẽ được sắp xếp theo ngày sinh.
Types of queries that can use a B-Tree index. B-Tree index làm việc rất tốt với tìm kiếm full value, key range, hoặc key prefix. Nó chỉ hữu dụng khi tìm kiếm theo phần bên trái nhất của index. Index loại này hữu dũng cho những loại query sau:
Match the full value: Tìm kiếm khớp sử dụng full value của index. Bạn có thể tìm người last name: Cuba, first name: Allen, sinh ngày: 1960-01-01
Match a leftmost prefix: Bạn có thể tìm kiếm người có last name là Allen.
Match a column prefix: Bạn có thể tìm kiếm người có last name bắt đầu từ chữ J.
Match a range of values: Bạn có thể tìm kiếm những người có last name từ Allen -> Barymore.
Match one part exactly and match a range on another part: Bạn có thể tìm người có last name Allen, và first name bắt đầu bằng K
Index-only queries: B-Tree index có thể support bình thường index-only query, là những query chỉ access vào index, không phải row. Chúng ta sẽ nói về vấn đề này sau.
Bởi vì tree node được sắp xếp, chúng có thể đc sử dụng cho cả 2 tìm kiếm và sắp xếp. Nhìn chung nếu B-Tree có thể giúp bạn tìm kiếm row theo một cách nào đó, nó có thể giúp bạn sắp xếp bằng cách tương tự. Sau đây là một số hạn chế của B-Tree:
- Chúng không hữu dụng khi lookup không bắt đầu từ phía bên trái cùng của index. Ví dụ, index kiểu này không giúp bạn tìm người nào mà first name là Bill hoặc những người sinh vào ngày nào đó, bởi vì những column vừa rồi không nằm trong bên trái cùng. Tương tự, bạn không thể dùng index để tìm người nào mà có last name kết thúc bằng ký tự nào đó được.
- Bạn không thể bỏ qua những column tồn tại trong index. Ví dụ, k có tác dụng khi tìm người có last name Smith và được sinh vào ngày nào đó. Nếu không xác định được first name, MySQL không thể sử dụng được column đầu tiên của index.
- Storage engine không thể tối ưu access khi tìm theo range ở bên phải. Ví dụ:
WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23'
Index chỉ có thể sử dụng column đầu tiên bởi vì like là range condition. Với những column mà chỉ có giới hạn nhỏ giá trị. Có thể sử dụng lần lượt từng giá trị một 
Bây giờ bạn biết vì sao mà chúng tôi nói thứ tự column là cực kỳ quan trọng, sự hạn chế của index phụ thuộc vào thứ tự column. Cho hiệu năng tối ưu, bạn có thể cần tạo các index riêng cho mỗi column để đáp ứng nhiều loại query.
Một số sự hạn chế không phải do B-Tree index, nhưng mà do cách MySQL query optimizer và storage engine sử dụng index. Một số chúng có thể sẽ bị loại bỏ trong tương lai.
(tobe continue)
All rights reserved
