Một số thủ thuật khi sử dụng xpath trong selenium
Bài đăng này đã không được cập nhật trong 6 năm
Khi làm việc với Automation Test Coding, chúng ta quá quen thuộc với việc xác định các element có trên web page thông qua các thuộc tính của nó như id, name, class,.... việc sử dụng những thuộc tính này giúp cho việc tìm kiếm trở nên rất dễ dàng và nhanh chóng. Tuy nhiên, có một số element chúng ta không thể tìm kiếm nó thông qua các thuộc tính vừa kể trên được và cũng có một số element có thuộc tính động, không cố định theo thời gian. Trong trường hợp này chúng ta cần sử dụng một cách định vị element thông minh hơn, phù hợp với các element có yếu tố phức tạp và thay đổi linh hoạt. Trong bài này, mình sẽ chia sẽ với mn về 15 cách để tìm kiếm element thông qua XPath locators.
XPath Selenium Selectors
Chúng ta có thể tìm kiếm vị trí của bất kì element nào nằm trên web page sử dụng biểu thức XML path. Cú pháp cơ bản của nó như sau:
Syntax = //tagname[@attribute='value']
Example = //input[@id='user-message']
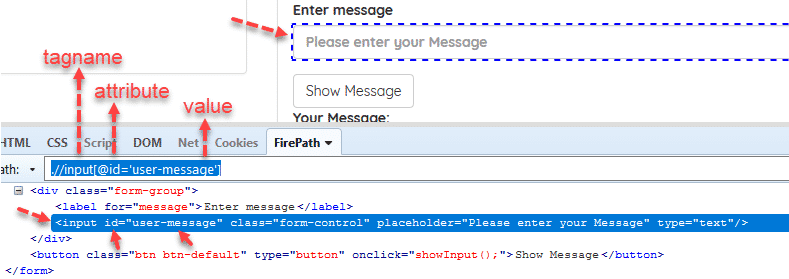
Absolute and Related Path
Thông thường, khi mà phỏng vấn về Automation Test sẽ có một vài người sẽ hỏi về sự khác nhau giữa 2 loại này. Dưới đây mình sẽ điểm qua một số điểm khác biệt giúp mn có thể dễ dàng phân biệt được 2 loại này.
Absolute XPath
- Đó là một cách trực tiếp để xác định vị trí của một element
- Bắt đầu bằng dấu "/" đơn, có nghĩa là bắt đầu tìm kiếm từ gốc
- Bởi vì nó tìm kiếm trực tiếp nên nó rất là cứng
Example: /html/body/div[2]/div/div[2]/div[1]/div[2]/form/div/input
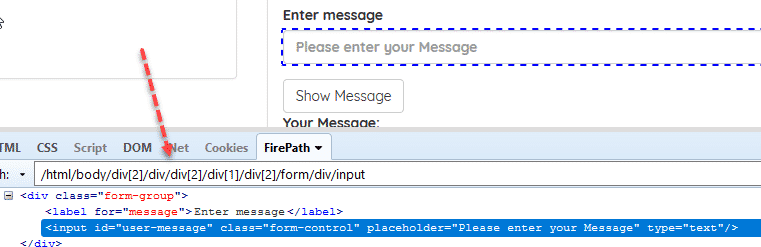
Thông qua ví dụ trên các bạn sẽ hiểu rõ hơn vì sao nó cứng rồi nhé. Thử lấy ví dụ: Nếu như mình thêm vào một thẻ div vào vị trí đầu tiên trong thẻ body thì /html/body/div[2]/div/div[2]/div[1]/div[2]/form/div/input sẽ trả về một phần tử khác phần tử ban đầu mà ta mong muốn.
Related XPath
- Có thể bắt đầu bất kì từ vị trí nào bạn muốn, chứ không nhất thiết phải từ gốc như Absolute XPath
- Bắt đầu bằng dấu "//" đôi
- Ngắn hơn Absolute XPath
- Linh hoạt hơn
Example: //div[@class=’form-group’]//input[@id=’user-message’]
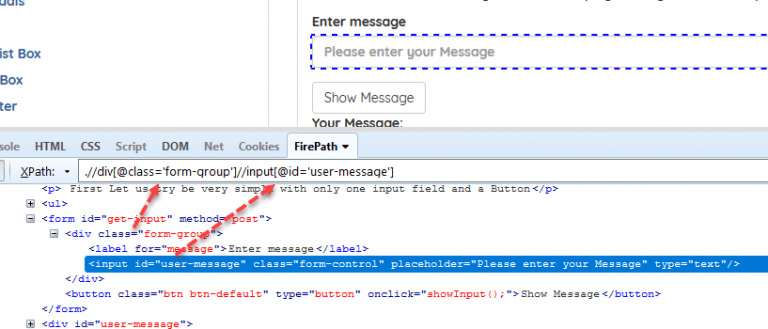
Example: //*[@class=’panel-body’]//li[contains(text(),’entered in input field’)]
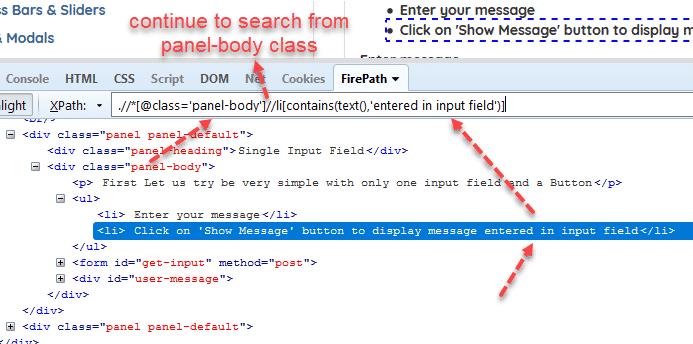
Dấu * có nghĩa là tất cả các loại tag, có thể là input, div, button,...
Contains
Contains là một kỹ thuật rất là tiện dụng trong việc định vị vị trí element của XPath Selenium. Khi một thuộc tính của một element là thay đổi liên tục, lúc đó bạn có thể sử dụng contains() cho phần không thay đổi trong thuộc tính của element, hoặc có thể dùng cho bất kì điều kiện gì bạn muốn.
Syntax: //tag[contains(@attribute, 'value')]
Example: Tìm các thẻ input có id chứa 'er-messa' //input[contains(@id, ‘er-messa’)]
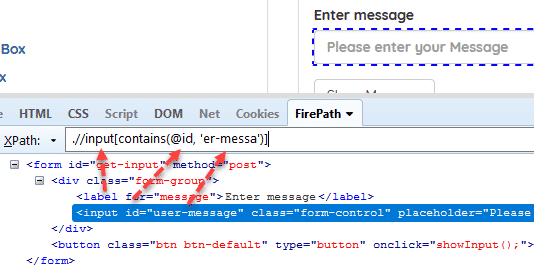
Examples:
//*[contains(@name,'btnClick')]
--> Tìm các tags có thuộc tính name chứa đoạn text "btnClick"
//*[contains(text(),'here')]
--> Tìm các tags có text chứa chữ "here"
//*[contains(@href,'swtestacademy.com')]
--> Tìm các link có url chứa "swtestacademy.com"
Operator "or"
Đôi lúc chúng ta không chỉ tìm kiếm element dựa trên một thuộc tính duy nhất được bởi vì các thuộc tính của element có thể thay đổi. Vậy nên toán tử "or" giúp ta tìm kiếm element dựa trên nhiều điều kiện. Giả sử ta có 2 điều kiện A và B và dưới đây là bảng kết quả thu được khi sử dụng toán tử "or" cho 2 điều kiện A, B:
| A | B | Result |
|---|---|---|
| False | False | No element |
| True | False | Returns A |
| False | True | Returns B |
| True | True | Returns both |
Lưu ý: toán tử "or" phải là chữ in thường
Syntax: //tag[XPath Statement 1 or XPath Statement 2]
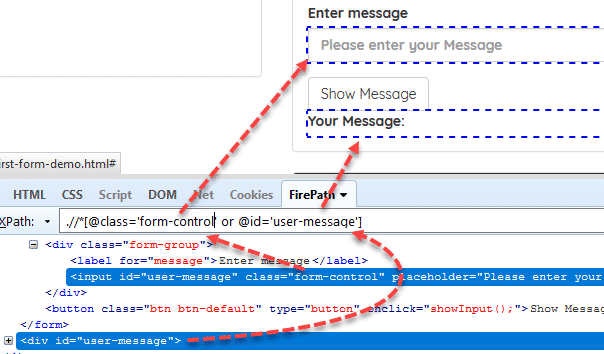
Example: //[@id=’user-message’ or @class=’form-control’]
Đoạn XPath trên dùng để tìm kiếm các thẻ tags có id='user-message' hoặc class='form-control'
Operator "and"
Một trong những toán tử quan trọng nhất trong ngôn ngữ lập trình, đối lập với toán tử "or" không ai khác ngoài toán tử "and". Toán tử and dùng để gộp nhiều điều kiện lại với nhau.
| A | B | Result |
|---|---|---|
| False | False | No elements |
| True | False | No element |
| False | True | No element |
| True | True | Returns both |
Syntax: //tag[XPath Statement-1 and XPath Statement-2]
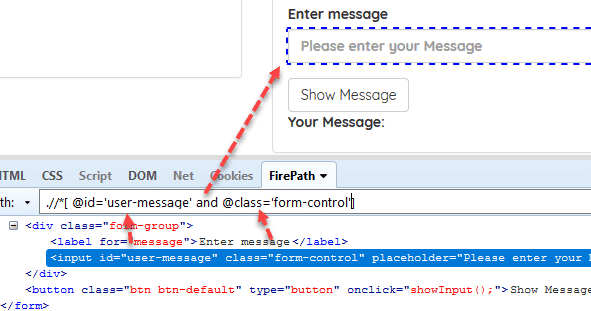
Example: //[@id=’user-message’ and @class=’form-control’]
Text
Chúng ta có thể tìm kiếm tags bằng đoạn text chính xác.
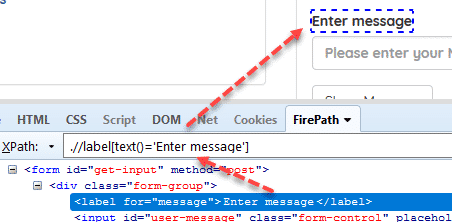
Syntax: //tag[text()=’text value‘]
Example: .//label[text()=’Enter message’]
Ancestor
Dùng để tìm tổ tiên của tag. Trước hết nó tìm kiếm element và gán cho nó là nút gốc, sau đó tìm các tag ancestry bắt đầu từ nút gốc vừa tìm được:
- Đầu tiên, tìm kiếm tag có thuộc tính class là 'container-fluid'
- Sau đó tìm các thẻ div có trong element vừa tìm được ở bước 1
Example: //[@class=’container-fluid’]//ancestor::div
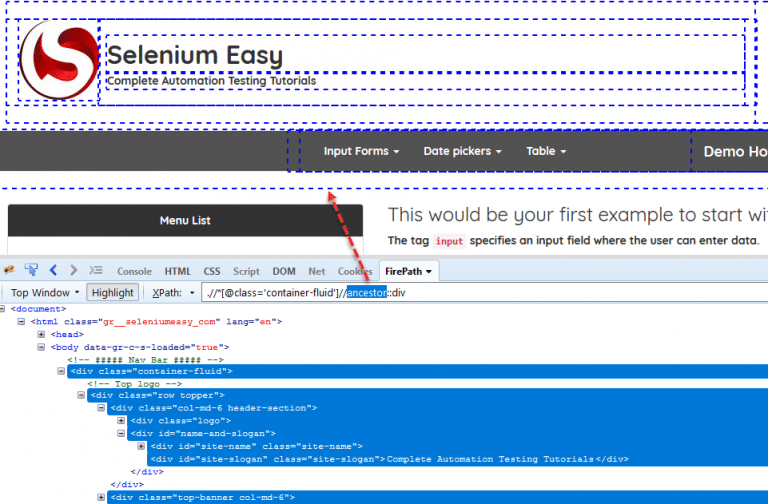
Bạn có thể tìm kiếm đến thẻ div bạn muốn bằng cách:
.//*[@class=’container-fluid’]//ancestor::div[1] – Returns 13 nodes
.//*[@class=’container-fluid’]//ancestor::div[2] – Returns 7 nodes
.//*[@class=’container-fluid’]//ancestor::div[3] – Returns 5 nodes
.//*[@class=’container-fluid’]//ancestor::div[4] – Returns 3 nodes
.//*[@class=’container-fluid’]//ancestor::div[5] – Returns 1 node
Vậy là mình đã giới thiệu sơ qua một vài thủ thuật tìm kiếm element bằng XPath, ngoài ra có một extension hỗ trợ bạn xác định XPath của một element đó là ChroPath
Sau đó sử dụng như hình:
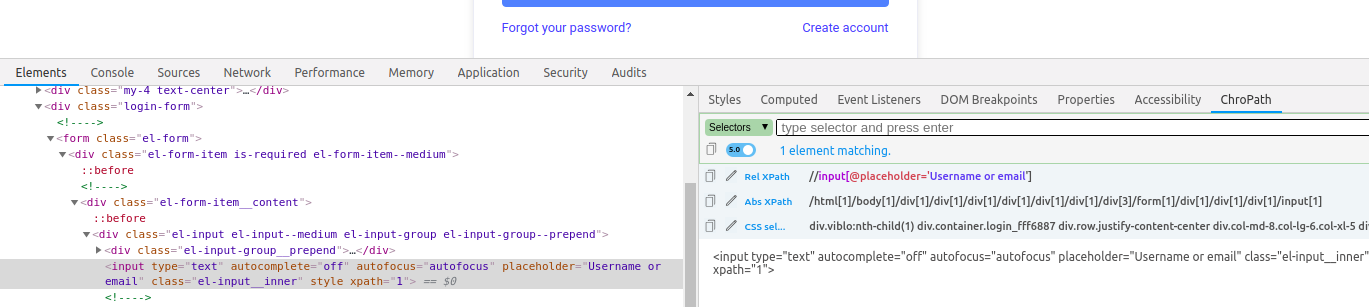
Cảm ơn mn đã đọc. Chúc mn cuối tuần vui vẻ  .
Happy coding!
.
Happy coding!
All rights reserved
