
Một số khái niệm cốt lõi trong RAG
Tổng quan
Xin chào tất cả mọi người, RAG từ lâu đã trở thành một công nghệ quan trọng trong lĩnh vực AI, đặc biệt là trong việc tối ưu hóa cách chúng ta khai thác và sử dụng dữ liệu. Với sự kết hợp độc đáo giữa khả năng truy xuất thông tin chính xác (retrieval) và sức mạnh sáng tạo của các mô hình ngôn ngữ lớn (LLM), RAG đã chứng minh hiệu quả vượt trội trong việc giải quyết các bài toán phức tạp liên quan đến xử lý dữ liệu.

RAG tuy không còn xa lạ nhưng cho đến thời điểm hiện tại thì nó chưa bao giờ là lỗi thời. Hãy thử tưởng tượng, thay vì mất hàng giờ để tìm kiếm thông tin từ hàng triệu tài liệu, RAG có thể nhanh chóng lọc ra những nội dung quan trọng nhất, sau đó sử dụng LLM để tổng hợp thành câu trả lời đầy đủ và thuyết phục. Hoặc nếu ta chỉ phụ thuộc hoàn toàn vào LLM và ngồi đợi với hy vọng rằng nó sẽ luôn cho ra một phản hồi chính xác thì lại càng phi thực tế hơn ⛔️
Trước tiên, chúng ta hãy cùng điểm lại một số hạn chế của LLM nhé!
Nhắc lại một số nhược điểm của LLM
👉️ Mình sẽ liệt kê ra một số nhược điểm cố hữu điển hình của các mô hình ngôn ngữ lớn:
- (1) Hiện tượng ảo giác - Hallucination: Đại khái là hiện tượng LLM đưa ra 1 câu trả lời cực kỳ tự tin và trôi chảy nhưng bản chất lại hoàn toàn sai. Mình xin phép nói thêm và hallucination một chút:
Có lẽ mọi người cũng đã biết, LLM được đào tạo chủ yếu bởi thông tin thu thập từ Internet, và thật không may, và đây chính là nơi tiềm ẩn đủ loại thông tin sai lệch nguy hiểm 🤧😵💫, và LLM thì không được trang bị bất kỳ cơ chế nào để có thể kiểm duyệt tính đúng-sai của thông tin mà nó nạp vào, từ đó LLM có thể tạo ra các câu trả lời sai và thậm chí có hại. Đó chính là triệu chứng của "căn bệnh ảo giác" - hallucination.
Ngoài ra, còn một vài nguyên nhân dẫn đến hiện tượng hallucination như: LLM chưa thực sự hiểu câu hỏi của người dùng; Bị overfitting và bias trong quá trình training; Kiến thức và thông tin không được update kịp thời do được training từ static data;... Nhìn chung, đây vẫn là một vấn đề lớn đối với hầu hết, nếu không muốn nói là tất cả các LLM hiện nay. Okay, tiếp tục với những nhược điểm khác nào!
- (2) Dùng static data để training >> LLM bị outdated: LLM sẽ chỉ nắm được các thông tin, sự kiện xảy ra trước 1 mốc thời gian cố định. Ví dụ như ảnh dưới đây 👇️
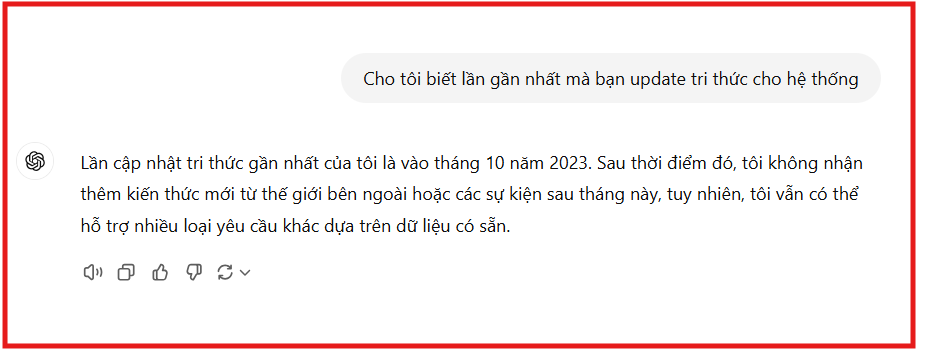
- (3) Không được kết nối với dữ liệu nội bộ: LLM sẽ không thể nào biết được nội dung trong các tài liệu nội bộ của công ty nào đó chẳng hạn,... Lỡ mà biết chắc báo động toàn công ty 👀⁉️⚠️.
- (4) Model adaptation required: Điển hình chính là việc tinh chỉnh mô hình - fine-tuning (đào tạo bổ sung cho mô hình với tập dữ liệu để thực hiện các tác vụ cụ thể hơn). Công việc này đòi hỏi rất nhiều thời gian, công sức, chi phí và cả kinh nghiệm của người thực hiện.
Vì sao lại chọn RAG?
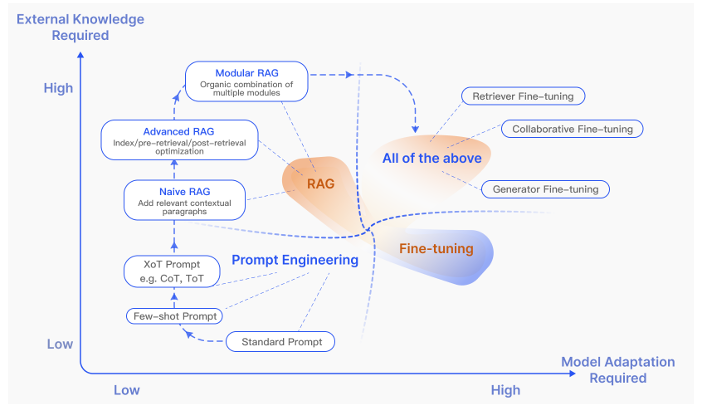
Khi đối mặt với bài toán lựa chọn giữa RAG (Retrieval-Augmented Generation) và fine-tuning, RAG tỏ ra là giải pháp phù hợp hơn trong nhiều trường hợp nhờ các ưu điểm về tính linh hoạt và khả năng cập nhật dữ liệu. Fine-tuning có thể mang lại kết quả chính xác và tốc độ cao hơn, nhưng nhược điểm lớn là chi phí cao, đòi hỏi thời gian huấn luyện dài và sự bất khả thi trong việc cập nhật dữ liệu thường xuyên. Mỗi lần cần cập nhật thông tin mới, fine-tuning phải đào tạo lại toàn bộ mô hình, điều này không khả thi khi dữ liệu thay đổi liên tục.
Ngược lại, RAG cho phép sử dụng thông tin từ các cơ sở dữ liệu hoặc tài liệu được cập nhật thường xuyên mà không cần phải huấn luyện lại mô hình. Quy trình triển khai RAG nhanh chóng và dễ dàng hơn, đồng thời việc kiểm soát dữ liệu đầu vào cũng đơn giản hơn. Đặc biệt, với các bài toán đòi hỏi khả năng truy xuất thông tin động hoặc làm việc với tập dữ liệu lớn thay đổi liên tục, RAG mang lại sự linh hoạt vượt trội. Dù tốc độ xử lý của RAG chậm hơn do cần thêm các bước tiền xử lý và hậu xử lý, nhưng lợi ích từ khả năng cập nhật và mở rộng nhanh chóng khiến nó trở thành lựa chọn tối ưu trong môi trường yêu cầu sự thích nghi cao.
Những khái niệm quan trọng trong RAG
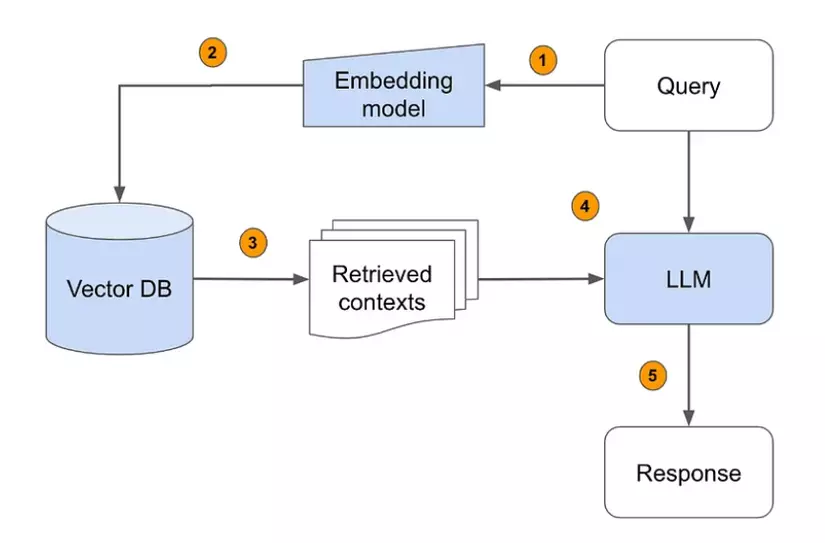
⏩️ Trước hết, chúng ta cần nắm sơ qua pipeline của RAG 👇️:
Nguồn: https://learn.deeplearning.ai/courses/building-evaluating-advanced-rag/lesson/1/introduction
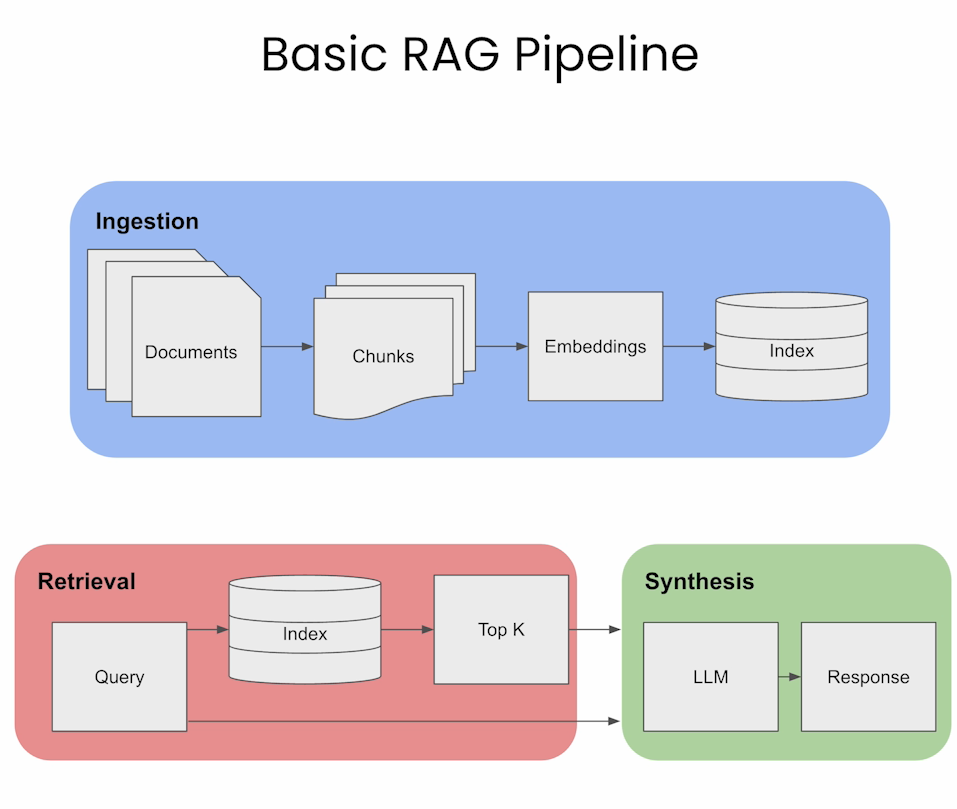
⏩️ RAG pipeline được chia thành 3 quá trình chính: Ingestion, Retrieval, và Synthesis. Sau đây, mình sẽ mô tả sơ qua một chút:
i. Ingestion (Giai đoạn xử lý và nạp dữ liệu)
🔅Mục đích: Chuẩn bị dữ liệu để phục vụ cho quá trình truy xuất thông tin.
🔅 Quy trình:
- Documents: Các tài liệu hoặc dữ liệu ban đầu được đưa vào hệ thống.
- Chunks: Các tài liệu được chia nhỏ thành từng đoạn (chunks) để dễ quản lý và xử lý.
- Embeddings: Sử dụng mô hình nhúng (embedding models) để chuyển các đoạn dữ liệu này thành vector số, biểu diễn ý nghĩa nội dung dưới dạng toán học.
- Index (Vector Database): Các vector nhúng được lưu trữ trong cơ sở dữ liệu chỉ mục (index) để tối ưu hóa việc truy xuất thông tin sau này.
ii. Retrieval (Giai đoạn truy xuất thông tin)
🔅 Mục đích: Lấy ra những thông tin liên quan nhất từ chỉ mục dựa trên câu truy vấn (query) của người dùng.
🔅 Quy trình:
- Query: Người dùng đưa ra một câu hỏi hoặc yêu cầu thông tin.
- Index (Vector Database): Câu hỏi này được chuyển đổi thành vector nhúng và so sánh với các vector trong chỉ mục.
- Top K: Các đoạn dữ liệu có điểm tương đồng cao nhất (thường là top K kết quả) được lấy ra để làm đầu vào cho quá trình tổng hợp.
iii. Synthesis (Giai đoạn tổng hợp)
🔅 Mục đích: Tạo ra câu trả lời hoàn chỉnh và dễ hiểu cho người dùng dựa trên dữ liệu truy xuất được.
🔅 Quy trình:
- LLM (Large Language Model): Mô hình ngôn ngữ lớn sử dụng các đoạn thông tin truy xuất để tạo ra phản hồi tự nhiên, chính xác và sát với ngữ cảnh câu hỏi.
- Response: Câu trả lời cuối cùng được gửi đến người dùng.
👇️👇️👇️
🎯⛳️ Ngay sau đây, mình sẽ tập trung trình bày nhiều hơn về 3 khái niệm chính: Prompt Engineering, Vector Search và Vector Database.
1. Prompt engineering
a. Định nghĩa
Prompt Engineering là kỹ thuật tối ưu hóa các câu lệnh (prompt) gửi đến các mô hình ngôn ngữ lớn (LLM) nhằm khai thác khả năng của mô hình để tạo ra đầu ra mong muốn mà không cần phải thay đổi hoặc huấn luyện lại mô hình.
Thay vì điều chỉnh tham số nội bộ như trong quá trình fine-tuning, prompt engineering tập trung vào việc thiết kế đầu vào sao cho mô hình hiểu đúng ý định và trả lời chính xác.
So sánh với Fine-Tuning:
Tiêu chí |
Prompt Engineering |
Fine-Tuning |
|---|---|---|
Tác vụ chính |
Tối ưu hóa đầu vào để cải thiện đầu ra của mô hình |
Điều chỉnh trọng số của mô hình |
Tốc độ |
Nhanh chóng và dễ triển khai |
Tốn nhiều thời gian và chi phí huấn luyện |
Data training |
Chỉ cần một lượng nhỏ |
Thường cần ít nhất vài trăm samples |
Độ khó |
Dễ dàng nắm bắt |
Cần có kiến thức sâu về NLP và training model |
Độ chính xác |
Kém chính xác hơn trong một số trường hợp phức tạp |
Chính xác hơn khi được huấn luyện đầy đủ, hoặc với các tasks cụ thể |
Độ linh hoạt |
Cho phép kết hợp domain knowledge và thông tin theo ngữ cảnh để cải thiện độ chính xác và mức độ phù hợp |
Mỗi khi domain hoặc bài toán thay đổi thì phải tiến hành training lại |
Chi phí |
Rẻ hơn |
Chi phí cao |
b. Vai trò của Prompt Engineering
Vai trò nói chung: Prompt Engineering đóng vai trò cầu nối giữa người dùng và mô hình, đảm bảo rằng LLM hiểu được yêu cầu một cách chính xác và hiệu quả. Đây là một giải pháp linh hoạt để tối ưu hóa kết quả phản hồi mà không cần điều chỉnh sâu bên trong model.
Vai trò trong RAG: Trong hệ thống RAG, prompt engineering là thành phần quan trọng ở bước Synthesis, khi LLM tổng hợp thông tin từ dữ liệu truy xuất (retrieval). Các lý do chính khiến Prompt Engineering đặc biệt quan trọng trong RAG bao gồm:
- Tối ưu hóa sự kết hợp giữa retrieval và generation: Prompt cần hướng dẫn LLM sử dụng dữ liệu được truy xuất một cách chính xác thay vì tạo ra nội dung từ trí nhớ của mô hình, tránh hiện tượng "hallucination".
- Cải thiện tính tương thích: Thiết kế prompt hiệu quả giúp LLM dễ dàng xử lý thông tin dạng kết quả truy vấn và tích hợp chúng vào đầu ra.
- Giảm chi phí và thời gian: Prompt Engineering giúp tận dụng sức mạnh của các LLM hiện có, hạn chế việc phụ thuộc vào fine-tuning.
c. Ưu - Nhược điểm của một số kỹ thuật Prompt Engineering phổ biến
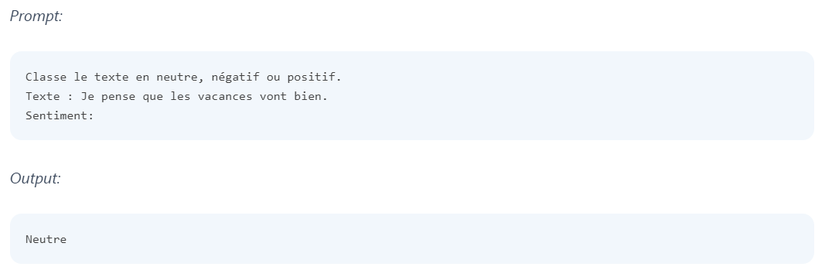
i. Zero-Shot Prompting
- Ưu điểm: Không cần thêm dữ liệu mẫu, nhanh chóng triển khai.
- Nhược điểm: Độ chính xác thấp trong các bài toán phức tạp hoặc đòi hỏi nhiều ngữ cảnh.
👉️ Ví dụ:
ii. Few-Shot Prompting
- Ưu điểm: Cung cấp một vài ví dụ để cải thiện khả năng hiểu của mô hình, hiệu quả hơn zero-shot.
- Nhược điểm: Cần thiết kế ví dụ phù hợp; tốn dung lượng token, ảnh hưởng đến hiệu suất.
👉️ Ví dụ:
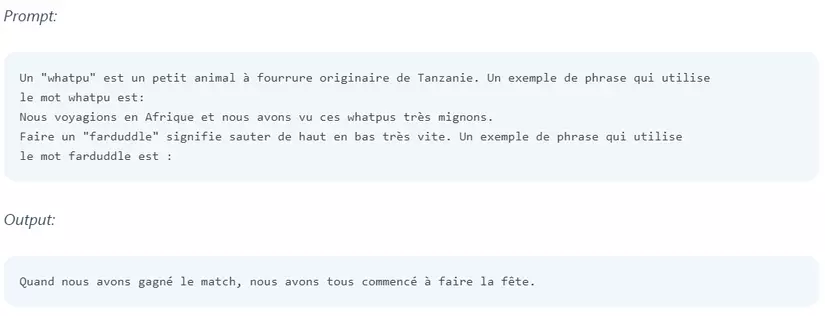
iii. Chain-of-Thought (CoT) Prompting
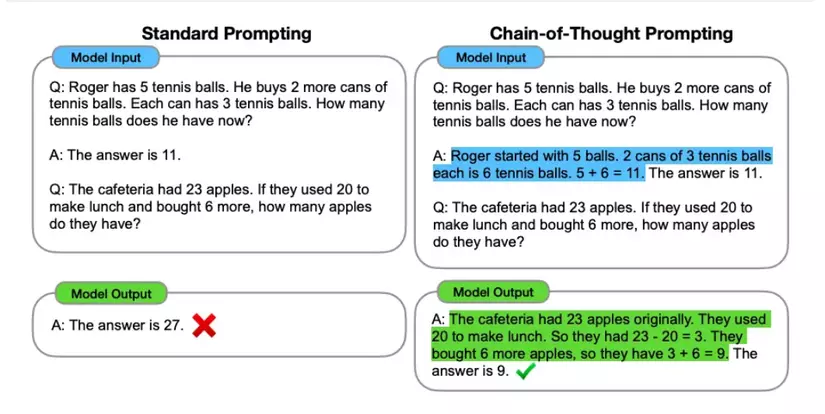
- Ưu điểm: Khuyến khích mô hình suy luận từng bước, phù hợp với bài toán logic hoặc toán học.
- Nhược điểm: Phức tạp trong thiết kế; cần thử nghiệm nhiều lần.
👉️ Ví dụ:
⛳️🎯 Trong bài viết lần này, mình sẽ chỉ trình bày về khái niệm Prompt Engineering và một số vai trò, ví dụ nổi bật,.. chứ không đi sâu vào việc thiết kế và cách tối ưu. Nếu ai có hứng thú thì có thể mày mò ở đây nha 👇️: https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-the-openai-api
2. Vector search
a. Embedding Vector và Vector Search
Embedding Vector: Embedding vector là biểu diễn số học của dữ liệu (ví dụ như văn bản, hình ảnh, hoặc âm thanh,...) trong không gian nhiều chiều. Các mô hình deep learning (như BERT, SentenceTransformer,...) sẽ chuyển đổi dữ liệu ban đầu thành các vector, sao cho: những dữ liệu tương đồng thì sẽ có vị trí gần nhau trong không gian vector. Ví dụ, hai câu có ý nghĩa tương tự sẽ được ánh xạ thành hai vector sao cho khoảng cách giữa chúng sẽ nhỏ hơn so với các câu không liên quan.
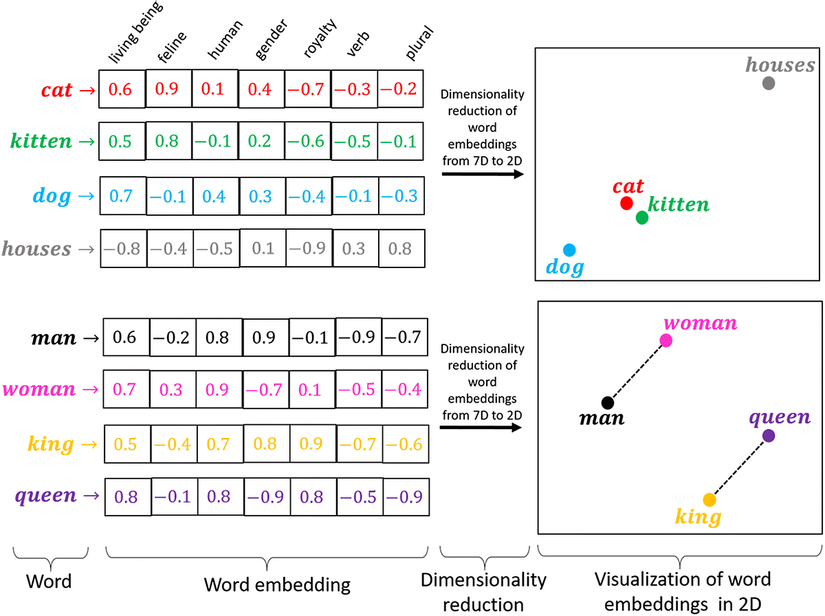
Nguồn: https://medium.com/@hari4om/word-embedding-d816f643140
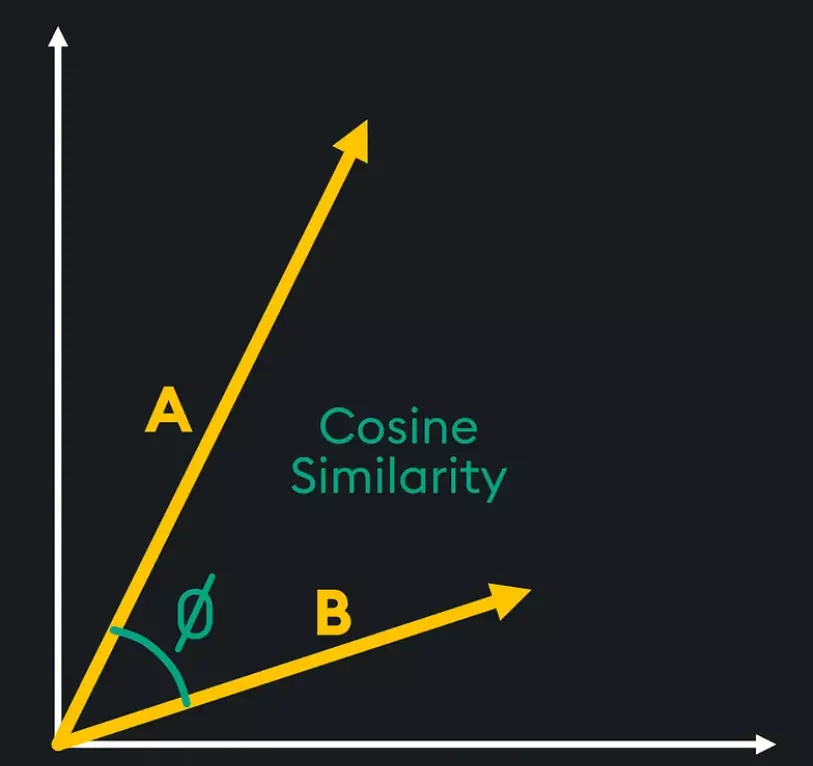
Vector Search: Vector search là 1 kỹ thuật truy vấn và tìm kiếm dựa trên việc so sánh độ tương đồng giữa các vector trong không gian vector. Khi thực hiện vector search, thay vì so khớp từ khóa, hệ thống so sánh các vector embedding thông qua các phép tính như:
- Cosine Similarity: Đo góc giữa hai vector. 👇️
- Dot Product Similarity: Đo khoảng cách thông qua tích vô hướng giữa hai vector. 👇️
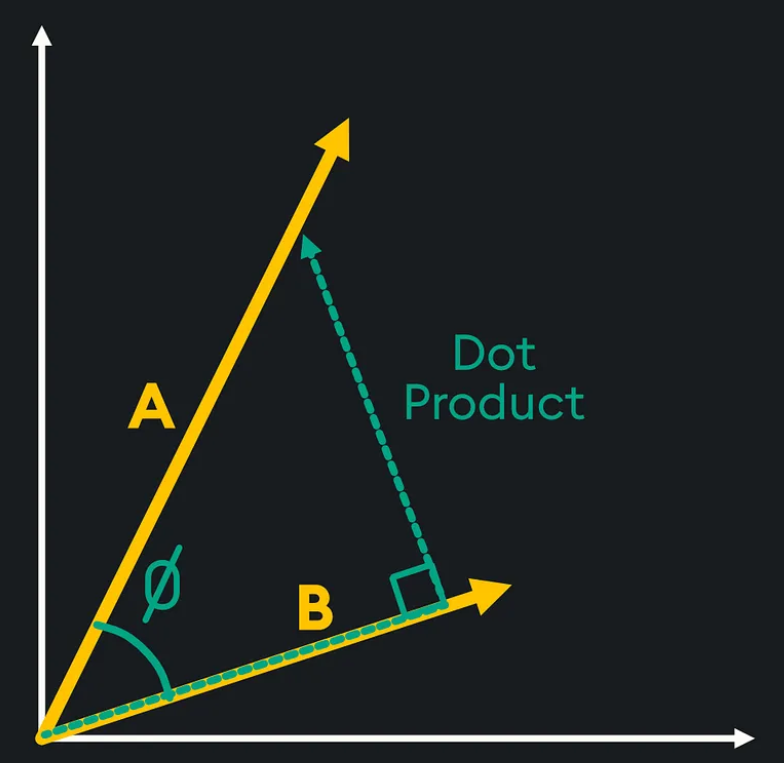
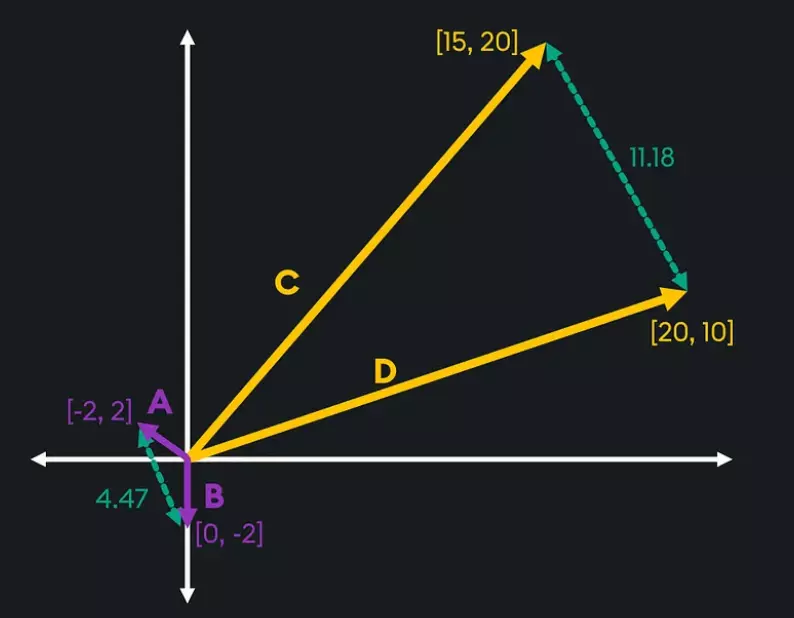
- Euclidean Distance: Đo khoảng cách hình học trực tiếp giữa hai vector trong không gian đa chiều. 👇️
Có hai chiến lược chính để vận hành vector search là: Bi-encoder và Cross-encoder:
Bi-encoder:
Đầu tiên, các đoạn tài liệu (document chunks) sẽ được lưu dưới dạng vector trong Vector Database (nôm na thì Vector Database như 1 cái kho chứa các vector). Sau đó, mô hình embedding sẽ tạo vector cho cả truy vấn (Query) và các đoạn tài liệu (Document Chunks).
Khi có truy vấn, hệ thống tính toán độ tương đồng giữa vector truy vấn và document vector bằng các phương pháp như cosine similarity, euclidean distance,... rồi trả về top k tài liệu có chỉ số similarity score cao nhất.
- Ưu điểm: Tốc độ nhanh, hiệu quả cho tìm kiếm quy mô lớn.
- Nhược điểm: Độ chính xác có thể không bằng cross-encoder.
Cross-encoder:
Thay vì tách riêng Query và Document như Bi-encoder, phương pháp này sẽ ghép chúng thành một chuỗi duy nhất. Sau đó đưa chuỗi này qua một mô hình encoder với self-attention, tận dụng sự tương tác giữa Query và Document. Tính toán score (0 đến 1) cho từng cặp Query-Document để xếp hạng độ liên quan.
- Ưu điểm: Độ chính xác rất cao.
- Nhược điểm: Chạy chậm hơn Bi-encoder, thường dùng ở bước re-ranking sau Bi-encoder.
⛔️⏩️ Vector Search chỉ là 1 trong số các phương pháp để truy xuất thông tin (information retrieval), sẽ còn một số phương pháp search khác như: Full-Text Search, Hybrid Search,... Nhưng mình sẽ chưa vội đề cập đến các khái niệm này trong bài viết hôm nay 😚.
b. Cách thức hoạt động của Vector Search trong RAG
Trong hệ thống RAG, vector search là thành phần cốt lõi trong bước Retrieval, với quy trình như sau:
-
Xử lý dữ liệu nguồn: Dữ liệu lớn (ví dụ: tài liệu, trang web) được chia thành các đoạn nhỏ (document chunks). Các đoạn này được chuyển thành vector embedding bằng mô hình Bi-encoder hoặc SentenceTransformer.
-
Lưu trữ vector: Các vector embedding được lưu trữ trong cơ sở dữ liệu vector (Vector Database) như FAISS, Pinecone, hoặc Milvus.
-
Tìm kiếm: Khi nhận truy vấn từ người dùng, truy vấn được chuyển đổi thành embedding vector. Lúc này, các phép đo Cosine Similarity, Dot Product, Euclidean Distance,... sẽ được sử dụng để tính toán độ tương đồng giữa các vector. Sau đó, sẽ là công đoạn ranking - một số thuật toán như KNN, HNSW,... sẽ được áp dụng để tìm các đoạn tài liệu gần nhất với truy vấn (top-k documents).
c. Ranking trong Vector Search:
Ở phía trên, mình đã nhắc đến việc ranking trong vector search, và sau đây sẽ là sự so sánh nhỏ giữa 2 thuật toán KNN và HNSW:
Tiêu chí |
Exhaustive KNN |
HNSW (Hierarchical Navigable Small World) |
|---|---|---|
Cách thức hoạt động |
Tính toán khoảng cách giữa tất cả các điểm dữ liệu và vector truy vấn. Chọn ra k điểm gần nhất dựa trên độ đo tương đồng (cosine, Euclidean,...). "Điểm dữ liệu" ở đây nhằm chỉ các vector embedding được sinh ra từ các document chunks. | Tạo cấu trúc đồ thị phân cấp trong quá trình indexing. Sử dụng thuật toán điều hướng qua đồ thị để tìm các điểm gần nhất. |
Yêu cầu tài nguyên |
Yêu cầu cao, vì phải tính toán tất cả khoảng cách giữa các vector với nhau. | Yêu cầu thấp hơn vì chỉ truy cập một phần dữ liệu qua cấu trúc đồ thị, nhưng cần thêm tài nguyên để xây dựng index ban đầu. |
Hiệu suất (tốc độ) |
Chậm, đặc biệt với dữ liệu lớn do tính toán toàn diện. | Nhanh, thích hợp cho dữ liệu lớn nhờ vào cấu trúc đồ thị. |
Độ chính xác |
Cao nhất: Đảm bảo tìm chính xác top-k điểm gần nhất. | Tùy chỉnh: Có thể đạt độ chính xác cao nhưng không tuyệt đối, phụ thuộc vào việc cấu hình các tham số để cân bằng giữa latency, throughput, và recall. |
👉️👉️👉️ Từ một vài so sánh nhỏ trên, có thể rút ra các kết luận sau:
Về KNN:
- Phù hợp với việc nghiên cứu, phân tích dữ liệu - khi độ chính xác quan trọng hơn tốc.
- Không phù hợp với các bộ dữ liệu lớn hoặc hệ thống thời gian thực.
Về HNSW:
- Thích hợp với hầu hết các kịch bản thực tế.
- Phù hợp với hệ thống gợi ý, tìm kiếm thông tin với cơ sở dữ liệu lớn, hoặc các ứng dụng yêu cầu phản hồi nhanh, như e-commerce,...
3. Vector database
a. Định nghĩa
Vector Database: Là cơ sở dữ liệu được thiết kế để lưu trữ, quản lý và truy vấn các vector embedding. Khác với cơ sở dữ liệu truyền thống chỉ lưu trữ dữ liệu dạng bảng, Vector Database cho phép lưu cả vector embedding và các metadata liên quan, giúp dễ dàng tích hợp vào các ứng dụng như hệ thống tìm kiếm thông tin (Information Retrieval) hoặc các hệ thống Recommendation.
b. Vector Database với Vector Search, Vector Index
(i) Phân biệt với Vector Search:
Tiêu chí |
Vector Database |
Vector Search |
|---|---|---|
Chức năng chính |
Lưu trữ vector và metadata, hỗ trợ CRUD và thực hiện truy vấn vector. |
Tìm kiếm và truy vấn vector embedding dựa trên độ đo tương đồng. |
Hỗ trợ CRUD |
Có. |
Không |
Real-time search |
Cho phép cập nhật và xóa dữ liệu ngay cả khi quá trình nhập liệu đang diễn ra. Thậm chí, có thể thực hiện truy vấn trong khi đang upload hàng triệu data. |
Không thể cập nhật hoặc xóa dữ liệu sau khi tạo. Chỉ có thể truy vấn sau khi chờ quá trình nhập liệu hoàn tất. |
Mục tiêu sử dụng |
Quản lý dữ liệu vector linh hoạt và hỗ trợ các thao tác phức tạp trên dữ liệu. |
Tìm kiếm vector nhanh và hiệu quả. |
Hạn chế |
Phức tạp hơn trong triển khai và tối ưu hóa. |
Không linh hoạt khi cần thay đổi dữ liệu. |
(ii) Phân biệt với Vector Index:
Vector Index là cấu trúc dữ liệu hoặc thuật toán (như IVF, HNSW) được sử dụng để tổ chức vector, tăng tốc độ tìm kiếm. Vector Database bao gồm cả chức năng indexing và quản lý dữ liệu vector cùng metadata.
Tiêu chí |
Vector Database |
Vector Index |
|---|---|---|
Hỗ trợ CRUD |
Có |
Không |
Quản lý metadata |
Có thể lưu trữ và truy vấn metadata, hỗ trợ các truy vấn chi tiết và điều kiện phức tạp. | Không hỗ trợ hoặc hỗ trợ rất hạn chế việc lưu trữ và truy vấn metadata. |
Truy vấn động |
Hỗ trợ truy vấn, cập nhật và xóa dữ liệu ngay cả khi quá trình nhập liệu đang diễn ra. | Cần chờ hoàn tất nhập liệu trước khi truy vấn được dữ liệu. |
Hiệu suất truy vấn |
Chậm hơn trong các truy vấn chỉ liên quan đến tìm kiếm do tích hợp nhiều tính năng bổ sung. | Tối ưu hóa tốt hơn cho các truy vấn tìm kiếm vector đơn thuần. |
Chi phí lưu trữ và vận hành |
Yêu cầu nhiều tài nguyên hơn để hỗ trợ các tính năng nâng cao như CRUD và quản lý metadata. | Nhẹ hơn, chi phí thấp hơn vì chỉ tập trung vào tìm kiếm vector. |
Khả năng mở rộng - Sacbility |
Dễ mở rộng với kiến trúc không máy chủ hoặc phân tán, tối ưu cho khối lượng dữ liệu lớn. | Khả năng mở rộng yêu cầu cấu hình tùy chỉnh phức tạp (ví dụ: quản lý trên cụm...). |
Ecosystem integration |
Tích hợp tốt với các công cụ xử lý dữ liệu (ETL, phân tích) và framework AI (LangChain, LlamaIndex,...). | Thường không tích hợp mạnh mẽ với hệ sinh thái khác. |
Bảo mật và kiểm soát truy cập |
Cung cấp bảo mật tích hợp, kiểm soát truy cập và phân vùng dữ liệu phù hợp với môi trường doanh nghiệp. | Hạn chế hoặc không hỗ trợ bảo mật tích hợp sẵn. |
Sao lưu và khôi phục |
Hỗ trợ sao lưu và khôi phục dữ liệu dễ dàng, đảm bảo an toàn dữ liệu. | Thường không hỗ trợ hoặc yêu cầu tích hợp ngoài để sao lưu. |
Độ phức tạp hệ thống |
Phức tạp hơn do tích hợp nhiều tính năng, đòi hỏi chi phí thiết lập và bảo trì cao hơn. | Đơn giản hơn, dễ triển khai cho các ứng dụng chỉ cần tìm kiếm vector. |
Ứng dụng tối ưu |
Phù hợp với hệ thống yêu cầu quản lý dữ liệu động và phức tạp, hoặc truy vấn metadata. | Thích hợp cho tìm kiếm vector nhanh trên dữ liệu tĩnh. |
c. Vector Database hoạt động như thế nào?
Nguồn: https://medium.com/@bijit211987/rag-vs-vectordb-2c8cb3e0ee52
🎯🎯🎯Tích hợp Vector Database trong pipeline của RAG:
- Bước 1 - Chuẩn bị dữ liệu nguồn: Dữ liệu lớn (document, video, hình ảnh,...) được chunk thành các đoạn nhỏ.
- Bước 2 - Embedding generation: Tạo vector embedding từ các đoạn dữ liệu bằng cách sử dụng mô hình NLP hoặc Computer Vision.
- Bước 3 - Lưu trữ data vào Vector Database: Sau khi dữ liệu được xử lý và chuyển đổi thành vector embedding thông qua các mô hình như SentenceTransformer hoặc Bi-encoder,... các vector này được lưu trữ cùng với metadata liên quan (như ID tài liệu, title,...). Quá trình này có thể bao gồm thêm bước indexing để tối ưu tìm kiếm (Indexing vector là quá trình tái cấu trúc dữ liệu bằng các thuật toán indexing như IVF, HNSW, PQ,... giúp tăng tốc độ truy vấn mà vẫn đảm bảo độ chính xác cao).
- Bước 4 - Vector Search: Khi có truy vấn từ người dùng, query vector được tạo và sử dụng để tìm kiếm trong Vector Database để tìm ra top-k vectors gần nhất.
- Bước 5 - Synthesis - Tổng hợp thông tin: Các đoạn tài liệu được truy xuất sẽ được dùng làm input cho LLM (như GPT) để tạo phản hồi.
Tạm kết
Prompt Engineering, Vector Search, và Vector Database là 3 trụ cột quan trọng giúp hệ thống RAG hoạt động hiệu quả. Prompt Engineering tối ưu hóa cách thức LLM tương tác với thông tin, đảm bảo phản hồi chính xác và sát với nhu cầu của người dùng. Vector Search đóng vai trò như cầu nối, tìm kiếm những thông tin liên quan nhất từ không gian vector embedding. Trong khi đó, Vector Database hỗ trợ lưu trữ và quản lý dữ liệu hiệu quả, đồng thời tăng tốc quá trình truy vấn thông qua các thuật toán indexing tiên tiến.
Hy vọng bài viết lần này đã cung cấp cho mọi người những kiến thức hữu ích 😊🍀❄️
Tài liệu tham khảo:
All rights reserved
