Mô tả về Data Models trong MongoDB
Bài đăng này đã không được cập nhật trong 4 năm
I. Khái niệm MongoDB
1. Collections
- Dữ liệu trong MongoDB được lưu trữ tại Collection, mà lần lượt các Collection sẽ được lưu trữ trong cơ sở dữ liệu.
- Dữ liệu được giới hạn khoảng 2GB trên hệ thống 32 bit, vì MongoDB sử dụng ánh xạ tập tin trong bộ nhớ khi chúng có sẵn một địa chỉ trong bộ nhớ.
- Mặc định giới hạn về số lượng của không gian tên (namespace) cho mỗi cơ sở dữ liệu là 24.000 (bao gồm tất cả các collection, các chỉ số index). Do đó với tối đa là 40 chỉ số được index cho mỗi collection, bạn có thể có 585 collection trong một cơ sở dữ liệu.
- Ví dụ
{
_id: ObjectId(7df78ad8902c5r345324e234e3)
title: 'Tìm hiểu collections',
description: 'Test',
comments: [
{
user:'dovv',
email: 'dovv1987@gmail.com'
dateCreated: '2015-06-26 12:30:50',
like: 0
},
{
user:'chu_thi_hai',
email: 'haict1212@gmail.com'
dateCreated: '2015-06-26 12:31:15',
like: 3
}
]
}
2. Data Format
- Dữ liệu được lưu trữ và truy vấn trong BSON nó cũng gần giống nhu JSON, những nét đặc trưng là một siêu JSON, hỗ trợ thêm các biểu thức thông thường, date, binary data, object id, tất cả các chuỗi được lưu trữ trong UTF-8.
- Documents được xác định bởi một ID đơn giản và cũng có thể là một loại object ID, tối ưu hóa cho việc lưu trữ và lập chỉ mục (điều này mặc định) nhưng người dùng vẫn có thể gán bất kì giá trị gì muốn là ID của documents.
3. References
- Documents có thể nhúng (embed) một cây dữ liệu liên quan ví dụ: tags, comments… thay vì lưu trữ chúng trong các documents khác.
- Khi sử dụng deferences các đối tượng được lồng nhau bằng dấu chấm. blog.post.comments.body và chỉ số với các kí hiệu tương tự.
4. Indexes
- Mỗi documents được đánh một chỉ số mặc định trên thuộc tính _id
- Có thể đánh chỉ số cho các thuộc tính bất kì hoặc thuộc tính embed và các documents khác, thuộc tính cũng có thể tạo ra trên nhiều thuộc tính và có thể bổ sung thêm về quy định thứ tự sắp xếp
- Nếu một thuộc tính kiểu mảng được lập chỉ mục, MongoDB sẽ lập chỉ mục của tất cả các giá trị trong nó.
II. Data Modeling Introduction
1. References
- Sử dụng lưu trữ dữ liệu kiểu references chúng ta sẽ phải thiết kế 2 Collections để lưu trữ dữ liệu
- Tạo Collections user
user= {
"_id" : ObjectId("5285a6449df8156c1b0002ed")
"name" : "Vo Van Do",
"message" : [{
"message_id" : ObjectId("5285a6449df8156c1b0002ed")
}, {
"message_id" : ObjectId("5285a6669df8156012000be0")
},
{
"message_id" : ObjectId("5285a6669df8156012000be2")
},
]
}
- Tạo Collections message
message = {
"_id" : ObjectId("5285a6449df8156c1b0002ed"),
"message" : "test 01",
"date" : I"2015-06-26 12:45:50",
},
2. Embedded Data
- Cách sử dụng lưu trữ dữ liệu kiểu Embed
{
"_id" : ObjectId("5285a6449df8156c1b000fa3")
"name" : "Vo Van Do",
"message" : [{
"_id" : ObjectId("5285a6449df8156c1b0002ed"),
"message" : "test 01",
"date" : "2015-06-26 12:45:50",
}, {
"_id" : ObjectId("5285a6669df8156012000be0"),
"message" : "test 02",
"date" : "2015-06-26 12:50:23",
}, {
"_id" : ObjectId("5285a6669df8156012000be2"),
"message" : "message N",
"date" : "2015-06-26 12:56:23",
}]
}
-
Khi thiết kế dữ liệu kiểu Embed thì chúng ta không phải tạo ra nhiều Collections để lưu trữ. Ở ví dụ trên chúng ta đã gộp lại 2 Collections thành 1 Collections.
-
Như vậy cách tạo dữ liệu kiểu Embedded giúp cho việc thiết lập dữ liệu theo hướng đối tượng tốt hơn so với thiết kế dữ liệu kiểu References
3. Kiểu dữ liệu One-to-One Relationships with Embedded
- Xét ví dụ dưới dây
user = {
_id: "3r23423er2243234f23f2",
name: "Vo Van Do"
}
patron = {
patron_id: "3r23423er2243234f23f2",
street: "Mỹ Đình, Nam Từ Liêm, Hà Nôi",
city: "Hà Nội",
state: "HN",
zip: "10000"
}
- Qua đó ta thấy dữ liệu giữa 2 Collections là kiểu One-To-One (1-1), 1 user ta lấy được 1 địa chỉ của user đó.
4. Dữ liệu kiểu Tree Structures with Child References
- Xét mô hình dữ liệu sau:
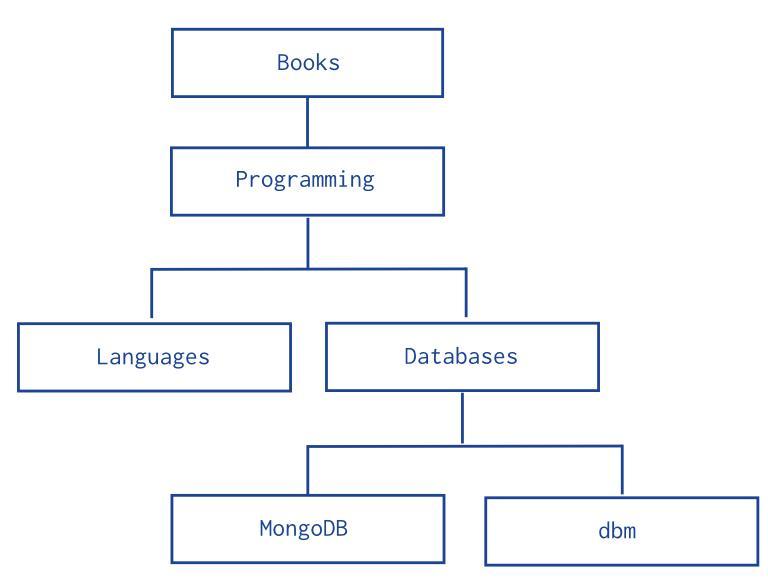
- Cập nhât dữ liệu cho các Collections
db.categories.insert( { _id: "MongoDB", children: [] } )
db.categories.insert( { _id: "dbm", children: [] } )
db.categories.insert( { _id: "Databases", children: [ "MongoDB", "dbm" ] } )
db.categories.insert( { _id: "Languages", children: [] } )
db.categories.insert( { _id: "Programming", children: [ "Databases", "Languages" ] } )
db.categories.insert( { _id: "Books", children: [ "Programming" ] } )
- Truy vấn dữ liệu
db.categories.findOne( { _id: "Databases" } ).children
- Kết quả trả về
patron = {
[
_id: "MongoDB",
children: "",
],
[
_id: "dbm",
children: "",
],
[
_id: "Databases"
children: [
{"MongoDB"},
{"dbm"}
}
],
[
_id: "Languages",
children: "",
],
[
_id: "Programming",
children: [
{"Databases"},
{"Languages"},
]
],
[
_id: "Books",
children: [{'Programming'}]
],
}
- Quá ví dụ trên ta thấy được sức mạnh truy vấn và liên kết câu trúc dữ liệu mạnh mẽ của MongoDB. Từ đó tạo cho kết quả truy vấn nhanh chóng.
5. Dữ liệu kiểu Atomic Operations
- Thưc hiện truy vấn
db.collection.update(),
db.collection.findAndModify(), db.collection.remove(),
- Ghi lại các hoạt động của user 1 cách nhanh chóng. Ví dụ:
store = {
_id: 5r234324232423rf24d2323,
title: "Buy TV Samsng F450",
author: [ "Vo Van Do", "Chu thi Hai" ],
published_date: "2015-06-26",
pages: 0,
language: "Vietnamese",
publisher_id: "098342f234dd4f421c",
available: 1,
checkout: [ { by: "dovv", date: "2015-06-26", } ]
}
III. Tổng kết
- MongoDB là một cơ sở dữ liệu đang có tốc độ phát triển tốt và được sử dụng cho rất nhiều dự án công nghệ hiện nay.
- Với ưu điểm là một hệ cơ sở dữ liệu mã nguồn mở, nên tiềm năng ứng dụng phát triển của MongoDB là rất lớn.
Tài liệu tham khảo:
All rights reserved
