
Mờ Lờ Óp #2 - Quá trình Deployment
Bài đăng này đã không được cập nhật trong 3 năm
Mở bài
Như chúng ta đã biết Deploy là một bước không thể thiếu trong quá trình Đưa mô hình AI đến tay người dùng. Trong bài trước chúng ta đã tìm hiểu đến bước deployment với ví dụ của hệ thống Speech Recognition và trong bài này chúng ta sẽ đi chi tiết hơn vào nó nhé. OK bắt đầu thôi
Các vấn đề chính trong Deployment
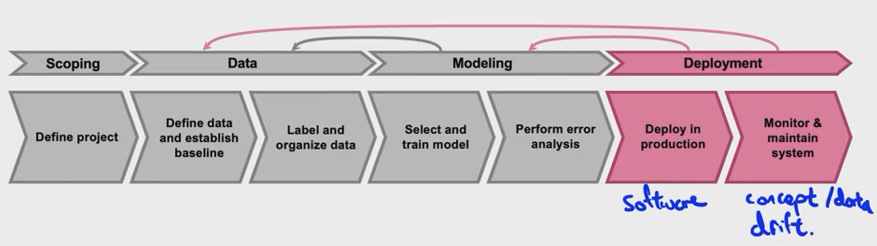
Thường sẽ phải đối mặt với hai thử thách lớn đó là ML & statistical issues ( Concept & Data drift) và software engine issues
Vấn đề Data Drift / Concept Drift
- Dữ liệu huấn luyện: khá sạch và cố định các distribution. Ví dụ chỉ gồm 1 giọng đọc trong mỗi audio, chỉ gồm các giọng miền bắc và môi trường thu là không có tiếng ồn
- Dữ liệu thực tế: nhiều người trong 1 audio, gồm cả các giọng nói miền trung, miền nam, môi trường thu nhiều tiếng ồn.
Có hai loại Drift thường gặp là
- Concept Drift: Thay đổi cả và trong quá trình inference
- Data Drift: Thay đổi chỉ
Vấn đề về software engine
- Xử lý realtime khác xử lý trên batch
- Xử lý trên cloud khác xử lý trên edge device
- Vấn đề về tài nguyên tính toán
- Ván đề về latency, throughput (QPS, query per second)
- Vấn đề logging
- Ván đề về bảo mật và quyền riêng tư
TÚM LẠI
- Thử thách về software engine sẽ xuất hiện trong quá trình triển khai mô hình lên production
- Thử thác về Drift sẽ xuất hiện trong quá trình vận hành và bảo trì hệ thống sau khi đã deploy
Các deployment parterns
Các trường hợp deployment phổ biến
Đối với một bài toán AI chúng ta thường sẽ có các trường hợp sau:
- Hệ thống AI của chúng ta là một sản phẩm mới
- Hệ thống AI là một sản phẩm hỗ trợ con người (assistance) trong việc ra quyết định
- Hệ thống AI sử dụng để thay thế các hệ thống ML trước đó.
Chúng ta có một số ý tưởng cho việc deploy hệ thống này:
- Gradual ramp up with monitoring: Cải tiến dần dần độ chính xác và tiến hành deploy lại liên tục. Trong trường hợp thứ 3, chúng ta thay vì thay thế toàn bộ mô hình cũ với mô hình mới thì có thể gửi một lượng nhỏ request sang mô hình mới và đo lường độ chính xác trên đó. Sau đó cập nhật mô hình mới dần dần
- Rollback: Ý tưởng của nó là trong trường hợp mô hình hiện tại không hoạt động tốt thì chúng ta có thể quay lại phiên bản trước đó của nó.
Ví dụ về Visual inspection
Để kiếm tra thủ công hệ thống này, thông thường người ta sẽ có các inspectors để kiểm tra thủ công xem điện thoại có hỏng hay vỡ hay không. Một trong những cách deploy mô hình AI phổ biến cho trường hợp này là Shadow mode
Shallow mode
- Mô hình AI được ẩn so với con người và không sử dụng output của mô hình AI
- Con người và mô hình AI được chạy một cách song song.
- So sánh kết quả ra quyết định của con người và mô hình AI
Mục đích của shadow mode: là để thu thập dữ liệu về cách thức hoạt động của mô hình và so sánh mức độ hiệu quả của mô hình AI so với con người. Ví dụ như hình bên dưới sẽ có những trường hợp cả con người và AI đều đồng thuận về quyết định, có những trường hợp khác lại không.

Ngay cả trong trường hợp hệ thống của chúng ta không có human inspectors mà chỉ có các good predictor khác (như API thương mại của môt bên thứ 3 chẳng hạn) thì phương pháp shadown mode deployment cũng rất hiệu quả cho việc đánh giá độ chính xác của mô hình mới và đảm bảo xem mô hình mới đã đủ tốt để sử dụng trong thực tế hay chưa.
Canary deployment
Khi chúng ta đã có một mô hình bắt đầu đáp ứng được độ chính xác trên thực tế, một trong những deployment partern thường sử dụng là canary deployment. Cách triển khai này được thực hiện như sau:
- Forward một lượng nhỏ request (khoảng 5%) sang một hình AI khi nó bắt đầu đáp ứng được việc ra quyết định với các dữ liệu thực tế.
- Tăng dần lượng request đến mô hình khi độ chính xác được tăng lên
Blue green deployment
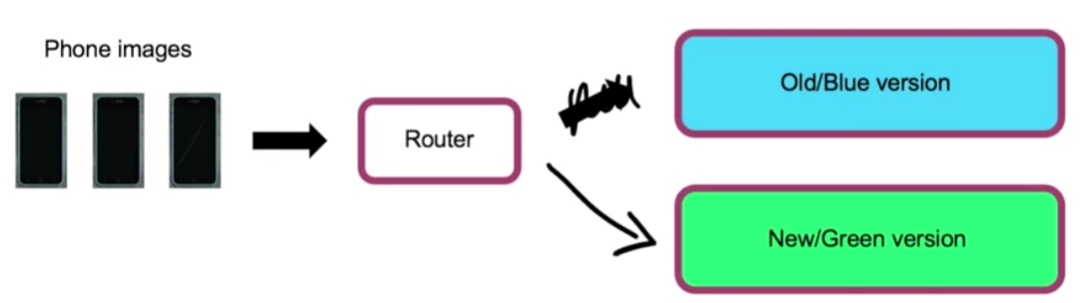
Trong quá trình dự đoán, ảnh đầu vào có thể được chuyển qua lại giữa các version của mô hình bằng router ngay lập tức. Trong đó chúng ta có:
- BLUE: version cũ
- GREEN: version mới
Ưu điểm của phương pháp này là rất dễ dàng roll-back khi chỉ cần config lại router và request sẽ được thực hiện ngay lập tức (với điều kiện chúng ta phải giữ phiên bản cũ và duy trì trạng thái hoạt động của nó).
Thông thường, chúng ta sẽ không chuyển toàn bộ request sang version mới của hệ thống - Green version mà sẽ chuyển dần dần sang
Các cấp độ automation
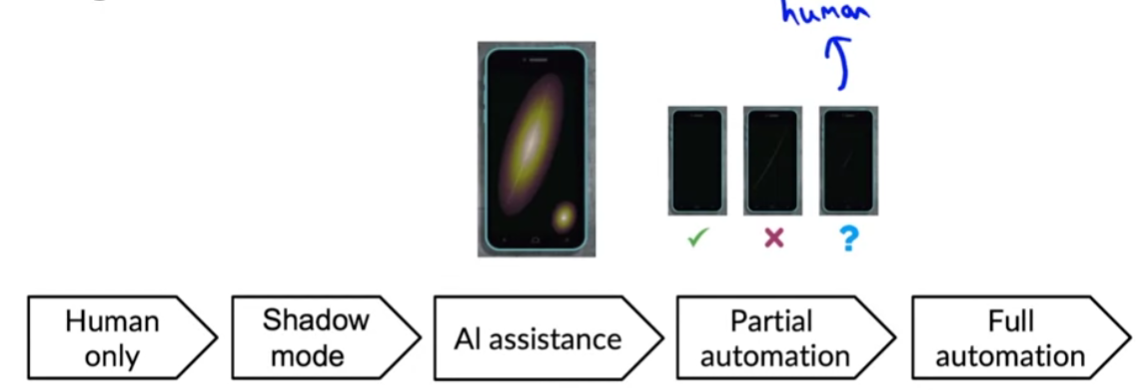
Từ trái sang phải chúng ta có cấp độ tăng dần của automation
- Human only: Hệ thống chỉ có con người ra quyết định
- Shadow mode Hệ thống chạy song song cả con người và AI. Sử dụng quyết định của con người để đánh giá mô hình AI
- AI Assistance: AI đưa ra các gợi ý cho con người để đưa ra quyết định
- Partial Automation: một phần request được thực hiện bởi con người, một phần khác được thực hiện bởi AI
- Full automation: Toàn bộ được thực hiện bởi hệ thống AI
Monitoring
Sử dụng dashboard
Tuỳ thuộc vào các ứng dụng khác nhau mà chúng ta sử dụng các metrics khác nhau trên dashboard để monitoring hệ thống. Ví dụ chúng ta có các dashboard để monitoring server load, hay tỉ lệ các request mà đầu ra không phải null (ví dụ như hệ thống speech to text không trả về giá trị text nào), hay tỉ lệ các input đầu vào bị thiếu
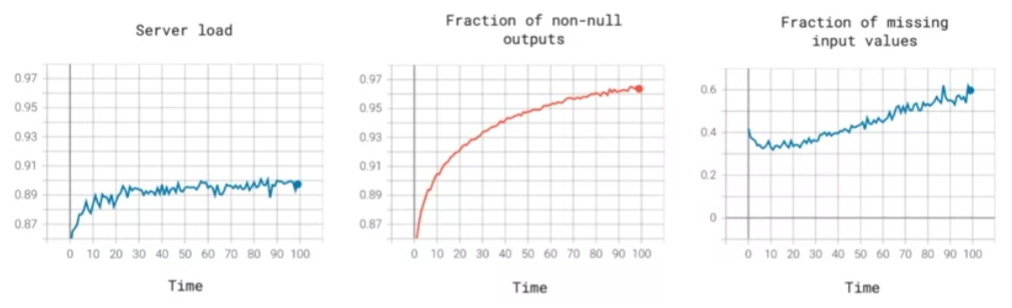
Dựa vào các metrics đo lường trên dashboard chúng ta có thể có những hành động cụ thể như sau:
- Brainstorm với đội ngũ phát triển để cùng thảo luận xem điều gì đang diễn ra với hệ thống.
- Xây dựng một số metrics đánh giá để tự động phát hiện ra vấn đề
Một số metrics đánh giá
- Software metrics: memory, compute, latency, throughput, server load..
- Input metrics: độ dài trung bình (ví dụ như trong bài toán speech recognition), volume trung bình, số lượng missing values...
- Output metrics: tần xuất trả về giá trị null, tần suất user thực hiện search lại, số lượng click trên mỗi sản phẩm được show ra....
Iterative procedure
ML Modeling và Deployment đều là các quá trình được thực hiện lặp đi lặp lại
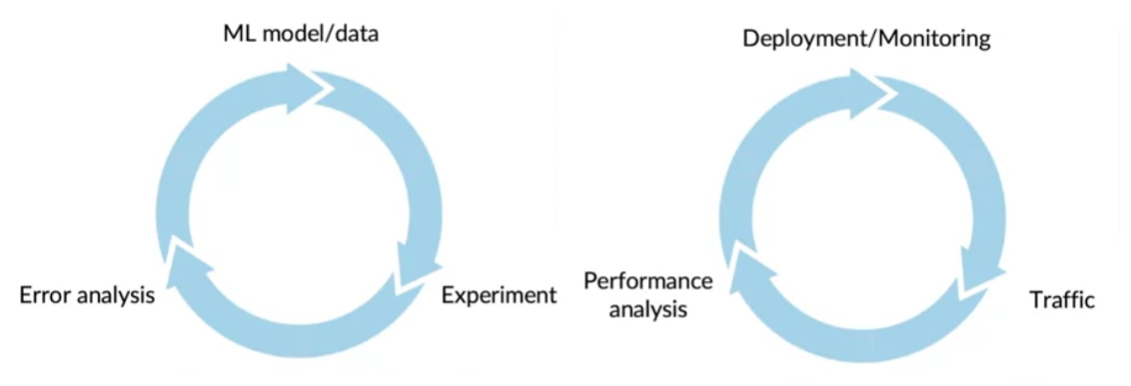
Model mantainance
Cũng giống như các phần mềm khác, mô hình AI cũng cần phải được bảo trì thường xuyên trong quá trình sử dụng. Khi mô hình cần được update thì nó sẽ có thể được thực hiện như sau:
- Huấn luyện thủ công: được thực hiện việc retrain bởi con người, thực hiện đo lường các lỗi và một phiên bản mới của mô hình sẽ được deployment
- Huán luyện tự động: thường ít phổ biến hơn huán luyện thủ công
Monitoring pipeline
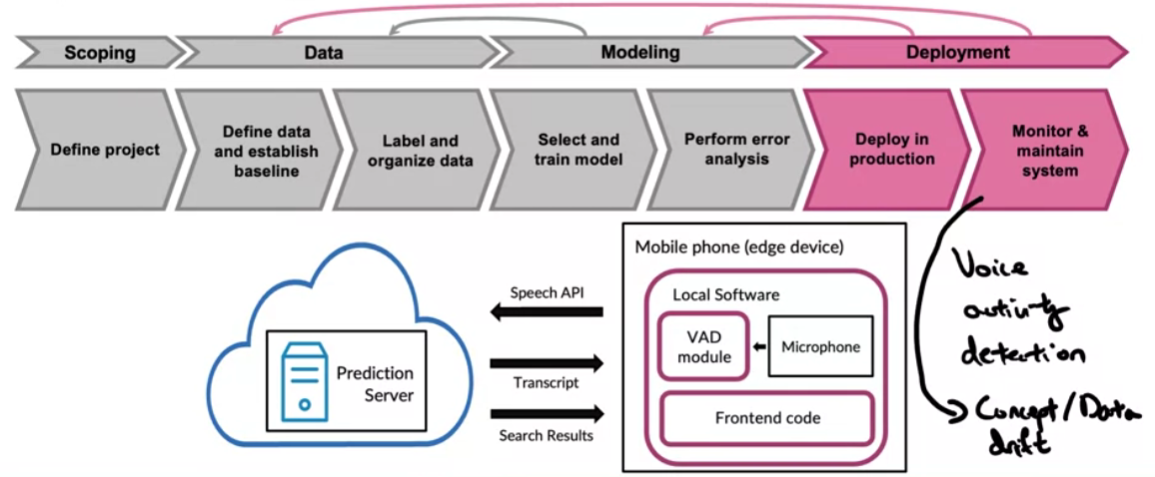
Hầu hết các hệ thống AI sẽ bao gồm nhiều bước khác nhau. Ví dụ như với ứng dụng Speech recognition chúng ta đã bàn luận trước đó thì pipeline cơ bản sẽ như sau

Tuy nhiên, có một vấn đề là nếu như triển khai như trên thì server speech recognition sẽ luôn luôn nhận đầu vào là luông stream audio ngay cả khi có người nói hay không có người nói. Điều này là lãng phí tài nguyên và không hiệu quả trong thực tế. Chúng ta có thể thực hiện một pipeline khác gồm nhiều bước như sau:

- Bước 1: Dữ liệu được đưa vào mô hình VAD (Voice Activity Detection) để thực hiện các công việc như:
- Check xem có người đang nói hay không
- Nhận dầu vào từ một long stream audio và chọn ra các phần nào chứa âm thanh của người nói sau đó mới đưa đoạn âm thanh đó vào mô hình speech recognition
- Bước 2: Thực hiện speech recognition trên server
Tuy nhiên sẽ có một vấn đề đó là thay đổi ở bước 1 có thể ảnh hưởng đến kết quả của toàn bộ pipeline. Nên chúng ta càn phải có những giải pháp theo dõi và đánh giá hiệu quả mô hình một cách chi tiết hơn.
Tổng kết
Trong bài này chúng ta đã cùng điểm qua một số điểm cần lưu ý trong quá trình deployment. Các phương pháp đánh giá mức độ hiệu quả là càn thiết trong quá trình monitoring mô hình giúp chúng ta phát hiện sớm các vấn đề để tìm ra giải pháp phù hợp.
All rights reserved
